【Python数据分析】大作业(自回归积分滑动平均模型) 2000+字 图文分析文档 疫情分析+完整python代码
资源地址:Python数据分析大作业 2000+字 图文分析文档 疫情分析+完整python代码
数据分析

时间序列是由四种因素组成的:长期趋势、季节变动、循环变动、随机波动。当我们对一个时间序列进行预测时,应该考虑将上述四种因素从时间序列中分解出来。
分解之后,能够克服其他因素的影响,仅仅考虑一种因素对时间序列的影响,也可以分析他们之间的相互作用,以及他们对时间序列的综合影响。当去掉这些因素后,就可以更好地进行时间序列之间的比较,从而更加客观的反映事物变化发展规律,序列可以用来建立回归模型,从而提高预测精度。时间序列的四种因素具有不同的特点:长期趋势反映了事物发展规律,是重点研究的对象;循环变动由于周期长,可以看作是长期趋势的反映,一般和长期趋势统称为趋势-周期因素;随机不规则变动由于不容易测量,通常也不单独分析(注:“S”型增长曲线是持续增长的,随机波动是一种与某个特殊事件相关的短期波动,具有一定的概率,可作为决策的辅助依据);季节变动有时会让预测模型误判其为不规则变动,从而降低模型的预测精度。当一个时间序列具有季节变动特征时,在预测之前会先将季节因素进行分解,也就是将季节变动因素从原时间序列中去除,并生成由剩余三种因素构成的序列来满足后续分析需求。
ARIMA 全称为自回归积分滑动平均模型(Autoregressive Integrated Movi ng Average Model,简记 ARIMA),ARIMA(p,d,q)模型是针对非平稳时间序列所 建立的模型。ARIMA 的含义包含 3 个部分,即 AR、I 、MA。
其中: AR 表示 auto regression,即自回归模型; I 表示 integration,即单整阶数,时间序列模型必须是平稳性序列才能建 立计量模型,ARIMA 模型作为时间序列模型也不例外,因此首先要对时间序列进 行单位根检验,如果是非平稳序列,就要通过差分来转化为平稳序列,经过几次 差分转化为平稳序列,就称为几阶单整; MA 表示 moving average,即移动平均模型。可见,ARIMA 模型实际上是 AR 模型和 MA 模型的组合。相应的,有三个参数:p,d,q。
其中:
p 代表预测模型中采用的时序数据本身的滞后数(lags) ,也叫做 AR/Auto Regressive 项。 d 代表时序数据需要进行几阶差分化,才是稳定的,也叫 Integrated 项。
q 代表预测模型中采用的预测误差的滞后数(lags),也叫做 MA/Moving Average
数据获取
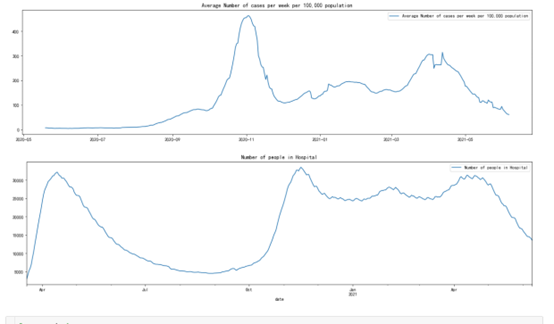
爬取法国新冠疫情2020-03-18到2021-06-09的患病人数和住院人数数据,法国新冠疫情患病人数和住院人数的图形如下所示,
ARIMA时间序列分析
数据预处理
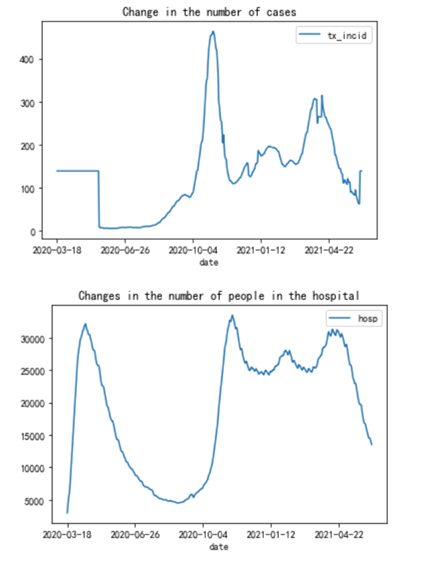
由于部分日期数据的缺失,需要对数据进行填充处理,本文选择使用均值来填充空值,得到的填充后的数据图如下所示
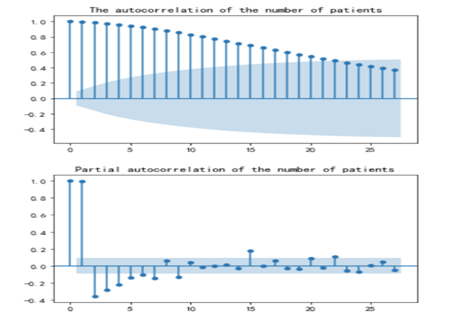
建立ARIMA模型需要将非平稳的时间序列转化成平稳的时间序列,通过时序图截取平稳部分数据和差分,然后对截取后的数据进行平稳性检验与白噪声检验,仅在数据为平稳非随机序列的条件下,才可利用ARIMA模型进行建模预测。本文中所有数据分析和处理均使用Python3.8版本进行。 故说明序列非白噪声,序列的自相关和偏相关图形如下
故说明序列非白噪声,序列的自相关和偏相关图形如下
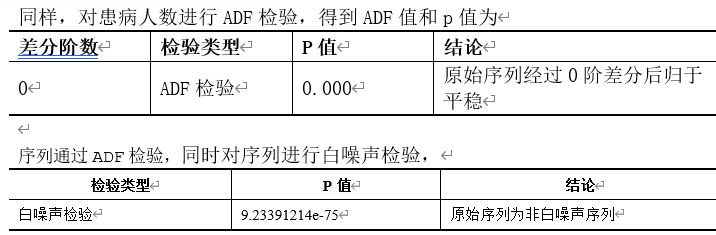
故说明序列非白噪声,同时住院人数通过了自相关检验,得到的自相关和偏相关图如下
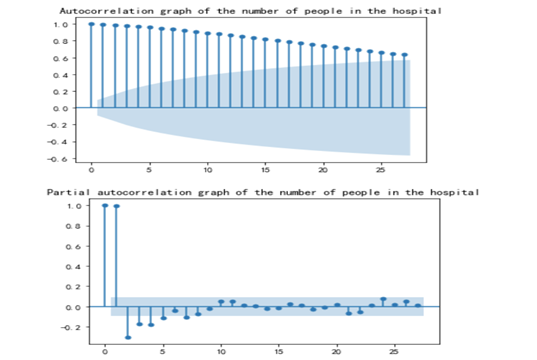
同时进行ARIMA模型的构造,对患病人数和住院人数进行模型定阶,得到患病人数的模型定阶参数p,q为2,1,故构建ARIMA(2,0,1)模型;住院人数的模型定阶参数p,q为4,3,故构建模型ARIMA(4,0,3)模型,同时为了查看模型的效果,使用2020-3-19到2021-5-9的数据作为训练集,使用2021-5-9到2021-6-9的数据作为测试集,得到模型对患病人数的预测图如下,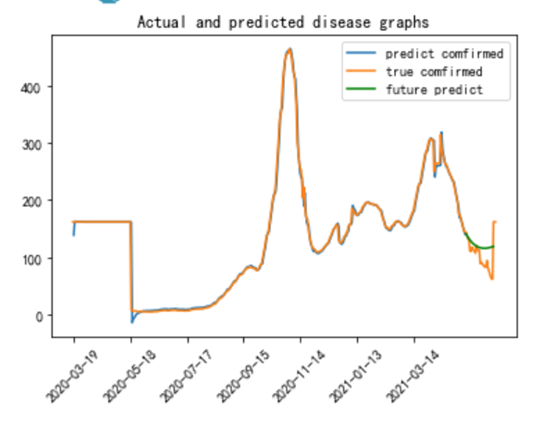
从图中可以发现训练集的数据拟合的比较好,而测试集的数据也就是future predict绿色标签,发现基本的趋势是正确的,而越来越后则预测的比较不符合数据,这也是因为arima时间序列不适合预测长远的未来数据,同时对2021-6-9号未来30天的数据进行预测,得到的预测值为
Predict= [169, 176, 182, 188, 193, 197, 201, 204, 207, 210, 212, 214, 215, 216, 216, 217, 217, 216, 216, 215, 214, 213, 212, 210, 209, 207, 205, 203, 201, 199]
同样对住院人数进行预测,使用2020-3-19到2021-5-9的数据作为训练集,使用2021-5-9到2021-6-9的数据作为测试集,得到模型对住院人数的预测图如下,
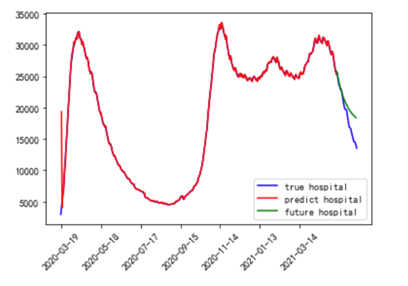
从图中可以发现模型在训练集中拟合的比较好,同时测试集中的数据大体趋势也是比较正确,在测试集前几天的预测中预测的比较准确,而测试集后十几天的预测的误差较大,这也是arima模型在预测完全未来数据的一个缺陷,同样对2021-6-9号未来30天的住院人数进行预测,得到预测值为,
Predict=[13137, 12847, 12627, 12416, 12169, 11887, 11603, 11359, 11172, 11030, 10904, 10771, 10629, 10491, 10380, 10305, 10260, 10232, 10209, 10188, 10175, 10182, 10211, 10263, 10330, 10405, 10486, 10576, 10680, 10800]
(1) ARIMA模型的优点是模型简单,容易构建。缺点是要求时序数据是稳定的,或者通过差分化之后是稳定的,同时要求原始数据和构建模型的残差不能是白噪声;本质上只能捕捉线性关系,不能捕捉非线性关系。同时arima模型对于预测未来数据效果不太好。 而ARIMA模型将无法尽快适应患病人数的突然上升或者下降。ARIMA倾向于在序列趋势明显的情况下,对数据预测更准确的结果,现如今新冠疫情愈演愈烈,虽然大多数国家的疫情都控制下来了,但新冠也在不断的变异,全球疫情随时有可能大爆发,面对可能会出现的疫情,政府需要紧急研制疫苗,让更多的民众接种疫苗,这样面对新冠病毒才有更多的抵抗力,其次政府要呼吁甚至强制人民不要随意出游,特定的人群密集场所保持关闭或者半开放状态。对于发现的每一个感染者,高度重视,及时隔离及时治疗;对于无症状感染者也保持隔离观察。个人出门要戴口罩,不去高风险地区,如果一定要外出一定要做核酸检测,确保不会发生传染。在国内加大对医疗卫生行业的投入,加大对医疗从业人员的培训,提升医疗行业人员待遇,鼓励更多人加入到医疗卫生行业,同时政府要减少税收,帮助民众度过难关。
资源地址:Python数据分析大作业 2000+字 图文分析文档 疫情分析+完整python代码
代码详解



主要是对时间序列数据进行分析和预测。让我们逐步解释每一部分:
-
导入必要的库:
from math import * import numpy as np import pandas as pd import matplotlib.pyplot as plt from statsmodels.graphics.tsaplots import plot_acf, plot_pacf from pylab import *math: 导入数学函数库,但实际上在后续的代码中没有用到。numpy、pandas、matplotlib.pyplot: 分别是用于数值计算、数据处理和可视化的常用库。statsmodels.graphics.tsaplots.plot_acf和statsmodels.graphics.tsaplots.plot_pacf:用于绘制自相关性和偏自相关性图。pylab: 导入了*,所以其下所有函数都可直接使用。
-
设置中文字体和负号显示:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体 plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题 -
读取数据:
cas_confirmes = pd.read_csv('cas_confirmes.csv', index_col=0) hospitalises = pd.read_csv('hospitalises.csv', index_col=0)从文件中读取了两个时间序列数据,分别是患病确诊人数和住院人数。
-
数据处理:
cas_confirmes.fillna(np.nanmean(cas_confirmes) + 30 * np.random.random(), inplace=True) hospitalises.fillna(np.nanmean(hospitalises), inplace=True)使用每列的均值填充缺失值。
-
数据可视化:
cas_confirmes.plot() plt.title('Change in the number of cases') plt.show() hospitalises.plot() plt.title('Changes in the number of people in the hospital') plt.show()绘制了患病确诊人数和住院人数的变化趋势图。
-
自相关性分析:
plot_acf(cas_confirmes) plt.title('The autocorrelation of the number of patients') plot_pacf(cas_confirmes) plt.title('Partial autocorrelation of the number of patients') plt.show() plot_acf(hospitalises) plt.title('Autocorrelation graph of the number of people in the hospital') plot_pacf(hospitalises) plt.title('Partial autocorrelation graph of the number of people in the hospital') plt.show()绘制了患病确诊人数和住院人数的自相关性和偏自相关性图。
-
ARIMA 模型定阶:
train_results = sm.tsa.arma_order_select_ic(cas_confirmes['2020-03-19':'2021-06-09'], ic=['bic'], trend='nc', max_ar=5, max_ma=5) print('BIC for the number of patients', train_results.bic_min_order)使用 BIC 准则确定 ARIMA 模型的阶数。
-
构建 ARIMA 模型:
model = ARIMA(cas_confirmes['2020-03-19':'2021-05-09'], order=(2,0,1)) results_comfirm = model.fit();使用确定的阶数构建 ARIMA 模型,并对患病确诊人数和住院人数分别进行建模。
-
模型诊断:
print('The white noise test result of the diseased difference sequence was:', acorr_ljungbox(resid1.values.squeeze(), lags=1)) print('The white noise test result of hospitalization difference sequence is:', acorr_ljungbox(resid2.values.squeeze(), lags=1))对模型的残差进行自相关性分析,检验残差序列是否为白噪声。
-
模型预测:
predict_comfirm=results_comfirm.forecast(30)使用训练好的 ARIMA 模型对未来一段时间内的患病确诊人数和住院人数进行预测。
-
可视化预测结果:
plt.plot(list(range(1,418)),predict_sunspots_comfirm,label='predict comfirmed') plt.plot(smooth_comfirm.loc['2020-03-18':'2021-06-09'],label='true comfirmed') plt.plot(list(range(417,447)),predict_comfirm[0],'g',label='future predict') plt.title('Actual and predicted disease graphs') plt.legend()绘制预测结果和真实数据的对比图。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 126
126 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)