脉冲神经网络入门指南(四)Training Spiking Neural Networks-反向传播方式【文献精读】
Eshraghian J K, Ward M, Neftci E O, et al. Training spiking neural networks using lessons from deep learning[J]. Proceedings of the IEEE, 2023.
Training Spiking Neural Networks-反向传播方式
4.训练脉冲神经网络(Training Spiking Neural Networks)
脉冲神经网络 (SNN) 的丰富时间动态使得神经元的发放模式可以有多种解释方式。因此,训练 SNN 也有多种方法。通常可以分为以下几种方法:
- 影子训练 (Shadow Training):先训练一个非脉冲人工神经网络 (ANN),然后通过将激活值解释为发放率或发放时间,将其转换为 SNN。
- 使用脉冲进行反向传播 (Backpropagation using Spikes):SNN 原生地使用误差反向传播进行训练,通常通过时间反向传播,就像对序列模型进行训练一样。
- 局部学习规则 (Local Learning Rules):权重更新是权重空间和时间局部信号的函数,而不是像误差反向传播那样的全局信号。
每种方法都有其适用的时间和场景。在此,我们将重点讨论直接将反向传播应用于 SNN 的方法,但通过探索影子训练和各种局部学习规则,也可以获得有用的见解。
反向传播算法的目标是最小化损失。为了实现这一目标,通过从最后一层到每个权重应用 链式法则 ,计算损失相对于每个可学习参数的梯度。然后使用这个梯度来更新权重,以理想状态下总是减少误差。如果这个梯度为“0”,则不会更新权重。这也是由于脉冲的不可微性,导致使用误差反向传播训练 SNN 的主要障碍之一,这也被称为令人畏惧的 “死神经元”问题 。“梯度消失”和“死神经元”之间存在微妙但重要的区别,这将在第4.3节中解释。
为了更深入地理解脉冲不可微性背后的原因,回顾漏积分发放(Leaky Integrate-and-Fire,LIF)神经元的膜电位离散化解(见方程(4)): U [ t ] = β U [ t − 1 ] + W X [ t ] U[t] = \beta U[t − 1] + WX[t] U[t]=βU[t−1]+WX[t]。其中,第一项代表膜电位 U U U 的衰减,第二项是加权输入 W X WX WX 。为了简化,省略了重置项和下标。
现在,假设对权重 W W W 进行权重更新 Δ W \Delta W ΔW(见方程(4))。这个更新使膜电位发生变化 Δ U \Delta U ΔU ,但这种电位变化未能导致神经元发放行为的进一步变化(见方程(5) S o u t [ t ] = { 1 , if U [ t ] > θ 0 , otherwise ( 5 ) S_{out}[t] = \begin{cases} 1, & \text{if } U[t] > \theta \\ 0, & \text{otherwise} \end{cases} (5) Sout[t]={1,0,if U[t]>θotherwise(5)
也就是说,除了在阈值 θ \theta θ 处, d S / d U = 0 dS/dU = 0 dS/dU=0 对所有 U U U 而言, d S / d U → ∞ dS/dU \rightarrow \infty dS/dU→∞。这使得我们真正感兴趣的项,即损失在权重空间中的梯度 d L / d W dL/dW dL/dW ,要么为“0”要么为“∞”。无论哪种情况,通过脉冲神经元进行反向传播时都没有足够的学习信号(见图9(a))。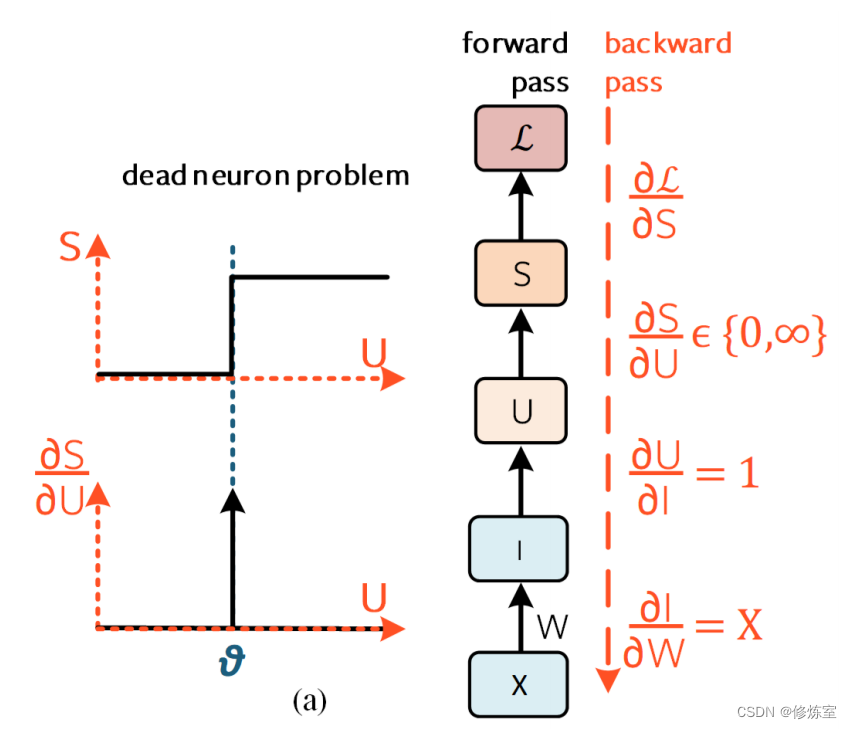
- 膜电位(Membrane Potential,U):神经元膜两侧的电位差。
- 权重更新(Weight Update,( \Delta W )):神经网络训练过程中对连接权重的调整。
- 阈值(Threshold,( \theta )):神经元发放脉冲的电位阈值。
- 梯度(Gradient,( dL/dW )):损失相对于权重的变化率,用于指导权重更新以减少损失。
4.1 影子训练(Shadow Training)
通过影子人工神经网络(Artificial Neural Network,ANN)进行训练并将其转换为脉冲神经网络(Spiking Neural Network,SNN),可以完全规避死神经元问题(见图9(b))。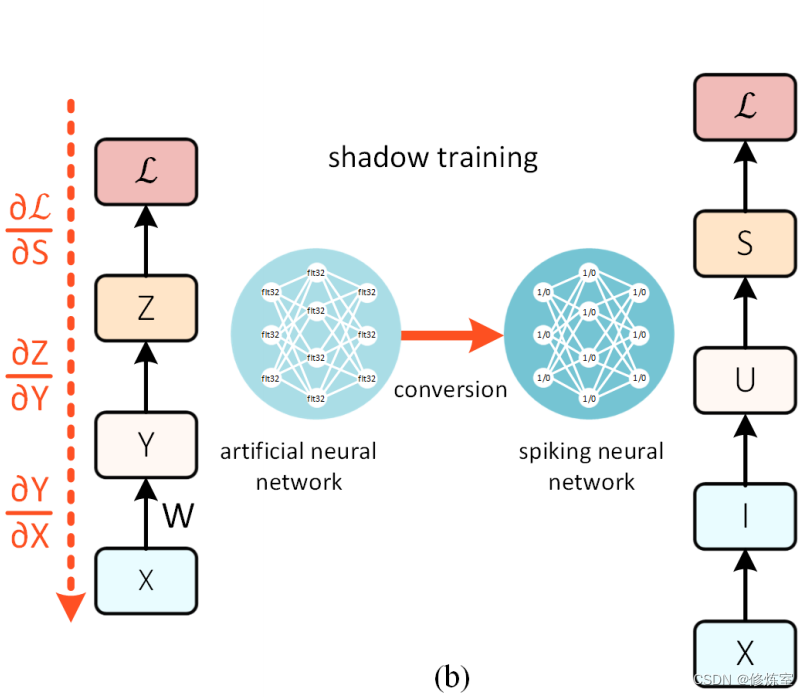
每个神经元的高精度激活函数可以转换为脉冲频率或潜伏期编码(latency code)。使用影子训练的最有力理由之一是,传统深度学习的进步可以直接应用于SNN。因此,对于复杂数据集(如CIFAR-10和ImageNet)的静态图像分类任务,ANN到SNN的转换目前处于领先地位。如果 推理效率 比训练效率更重要,并且输入数据 不是时间变化 的,那么影子训练可能是最优选择。
- 影子人工神经网络(Shadow ANN):在训练过程中使用的传统ANN,其激活函数最终转换为SNN的脉冲编码。
- 脉冲神经网络(SNN):一种神经网络模型,利用离散的脉冲信号(spikes)进行信息传递和处理。
- 死神经元问题(Dead Neuron Problem):在反向传播过程中,某些神经元因为无法发放脉冲而导致梯度为零,从而阻碍学习。
- 脉冲频率(Spike Rate):神经元在一段时间内发放脉冲的频率,用于编码信息。
- 潜伏期编码(Latency Code):根据神经元首次发放脉冲的时间来编码信息。
除了训练过程效率低下外,影子训练方法还有其他几个缺点。
首先,最常用于基准测试的任务类型并未利用SNN的时间动态特性,而将序列神经网络转换为SNN的领域研究还很少。
其次,将高精度激活转换为脉冲通常需要较长的仿真时间步骤,这可能抵消了最初从SNN中寻求的功率和延迟优势。
但真正促使人们放弃ANNs的是转换过程本质上是一种近似。因此,经过影子训练的SNN很难达到原始网络的性能。
- 影子训练方法(Shadow Training Method):通过训练传统人工神经网络(ANN),然后将其转换为脉冲神经网络(SNN)。
- 时间动态特性(Temporal Dynamics):指神经网络在时间维度上的变化和响应能力,SNN能够利用时间动态来处理信息。
- 仿真时间步骤(Simulation Time Steps):在SNN中进行仿真所需的离散时间步骤数量。
- 近似(Approximation):将高精度ANN激活转换为SNN脉冲编码时产生的误差。
对于长时间序列问题,可以通过使用混合方法部分解决:首先使用影子训练的SNN,然后对转换后的SNN进行反向传播。虽然这种方法在CIFAR-10和ImageNet上报告的结果显示精度有所下降,但它能够将所需的步骤数减少一个数量级。有关影子训练技术和挑战的更详细讨论,可以参考[164]。
[164] Michael Pfeiffer and Thomas Pfeil. Deep learning with spiking neurons: Opportunities and challenges. Frontiersin Neuroscience, 12:774, 2018.
- 混合方法(Hybrid Approach):结合影子训练和反向传播的方法,先训练ANN再转换为SNN,并进行进一步的优化训练。
- 反向传播(Backpropagation):通过计算损失函数相对于每个可学习参数的梯度来更新权重的算法。
- 精度(Accuracy):指模型在给定数据集上的预测准确性。
- 步骤数(Number of Steps):训练或仿真过程中所需的离散时间步骤数量。
4.2 反向传播中的脉冲时间(Backpropagation Using Spike Times)
另一种绕过“死神经元问题”的方法是 对脉冲时间求导 。实际上,这是第一个通过反向传播训练多层SNN的方法。SpikeProp的原始方法指出, 虽然脉冲是离散的,但时间是连续的 。因此,求脉冲时间相对于权重的导数可以达到功能性的结果。详细描述见附录C.1。
[124] Sander M Bohte, Joost N Kok, and Han La Poutre. Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing, 48(1-4):17–37, 2002.
- 脉冲时间(Spike Times):指神经元发出脉冲的时间点。
- SpikeProp:一种通过脉冲时间导数进行反向传播的方法。
- 连续时间(Continuous Time):尽管脉冲是离散事件,但时间是连续变化的。
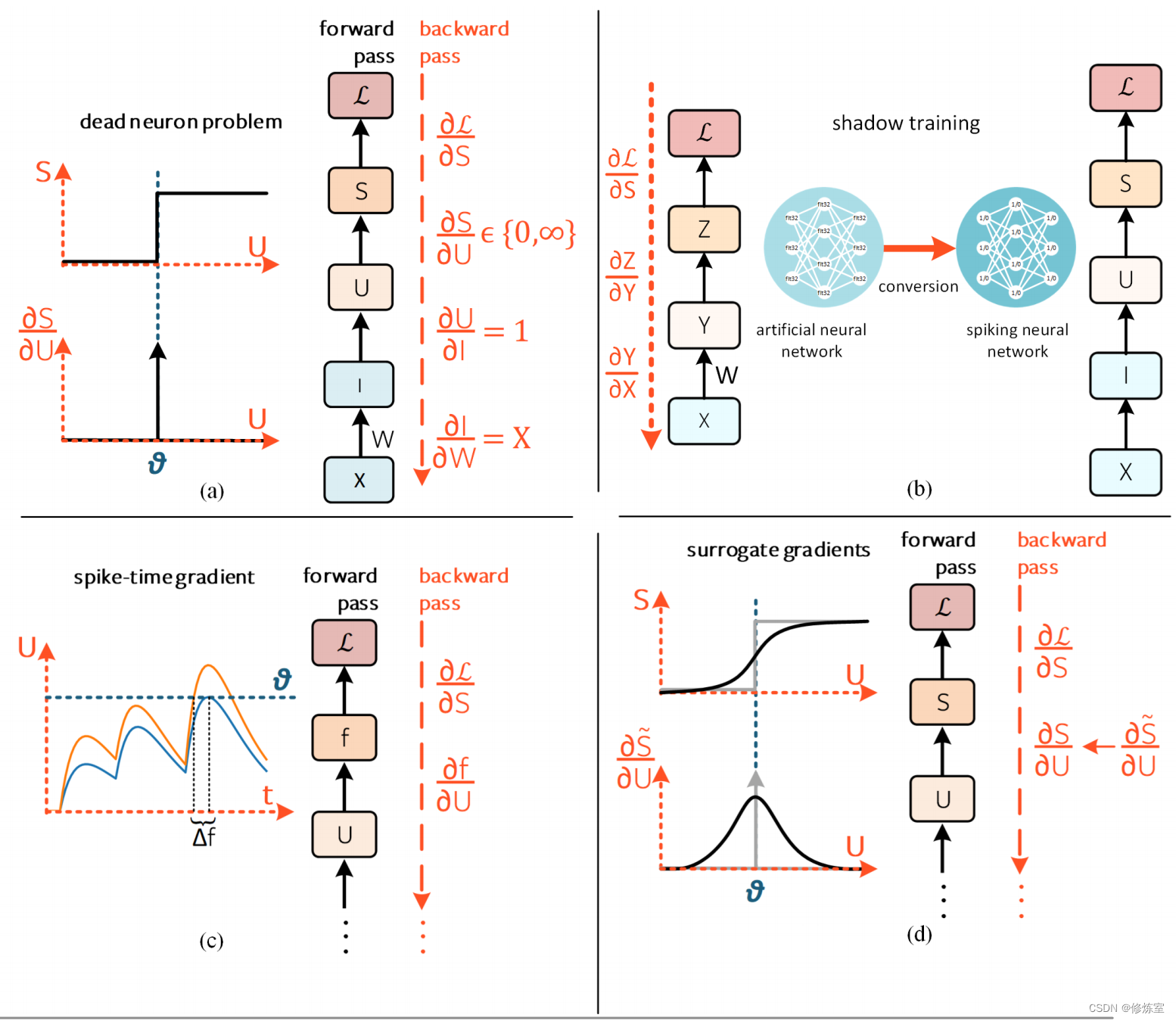
图9:解决死神经元问题
仅显示一个时间步,为简单起见,省略了图6中的时间连接和下标。
(a) 死神经元问题: ∂ S / ∂ U ∈ { 0 , ∞ } \partial S/\partial U \in \{0, ∞\} ∂S/∂U∈{0,∞} 的解析解导致梯度无法进行学习。
(b) 阴影训练:首先训练一个非脉冲神经网络,然后转换为SNN。
(c) 脉冲时间梯度:取脉冲时间 f f f 的梯度,而不是脉冲生成机制的梯度,只要脉冲必然发生,这就是一个连续函数。
(d) 代理梯度(Surrogate gradients):在反向传播过程中将脉冲生成函数近似为连续函数[123]。左箭头(←)表示函数替代。这是解决死神经元问题的最广泛采用的解决方案。
直觉上,SpikeProp 计算了误差相对于脉冲时间的梯度。对权重的变化 ∆ W ∆W ∆W 导致了膜电位的变化 ∆ U ∆U ∆U ,最终导致了脉冲时刻的变化 ∆ f ∆f ∆f,其中 f f f 是神经元的发放时刻。实质上,不可微分的项 ∂ S / ∂ U ∂S/∂U ∂S/∂U 已经被 ∂ f / ∂ U ∂f /∂U ∂f/∂U 替代。这也意味着 每个神经元必须发出一个脉冲才能计算出梯度 。这种方法在图 9© 中有所说明。SpikeProp 的扩展使其与多个脉冲兼容,在一些数据驱动任务上表现出色,其中一些任务已经超越了人类在 MNIST 和 N-MNIST 上的表现水平。
存在几个缺点。一旦神经元变得不活跃,它们的权重就会被冻结。在大多数情况下,如果没有发生脉冲,就不存在求解 梯度的闭式解 [169]。SpikeProp 通过修改参数初始化(即 增加权重直到触发脉冲 )来解决这个问题。但自从 SpikeProp 于 2002 年问世以来,深度学习社区对权重初始化的理解逐渐成熟。我们现在知道, 初始化的目标是在层之间设置恒定的激活方差 ,缺乏这一点会导致梯度在空间和时间上消失和爆炸。修改权重以促进发生脉冲可能会削弱(detract)这一点。相反,克服缺乏发放的更有效方法是降低神经元的发放阈值。人们可以考虑应用活动正则化来鼓励隐藏层中的发放,尽管这在脉冲时进行导数运算时会降低分类准确性。这个结果并不令人意外,因为正则化只能在脉冲时应用,而不能在神经元静默时应用。
另一个挑战是,它对网络施加了严格的先验条件(例如,每个神经元只能发放一次),这与动态变化的输入数据不兼容。可以通过使用周期性的时间编码来解决这个问题,在给定的间隔内刷新,类似于视觉扫视可能设置参考时间的方式。但这是唯一一种在多层脉冲神经网络中能够计算出无偏梯度的方法,而不需要任何近似。这种精度是否必要,需要在更广泛范围的任务上进一步探讨。
实用提示:脉冲时间的梯度(Gradients at Spike Times)
尽管这种方法仍在广泛研究中,但由于在优化损失函数方面表现不佳,已被反向传播通过时间使用替代梯度下降的方法所取代。为什么会这样呢?我们最好的猜测是性能较差是因为通过的边(edges)较少,使得学分(credit)分配更具挑战性。有关替代梯度下降的更多细节请参见下一节。
4.3 使用脉冲进行反向传播( Backpropagation Using Spikes)
过去几年中,最常采用的方法不是计算相对于脉冲时间的梯度,而是将广义反向传播算法应用于展开的计算图(图 6(b)),即通过时间的反向传播(BPTT)。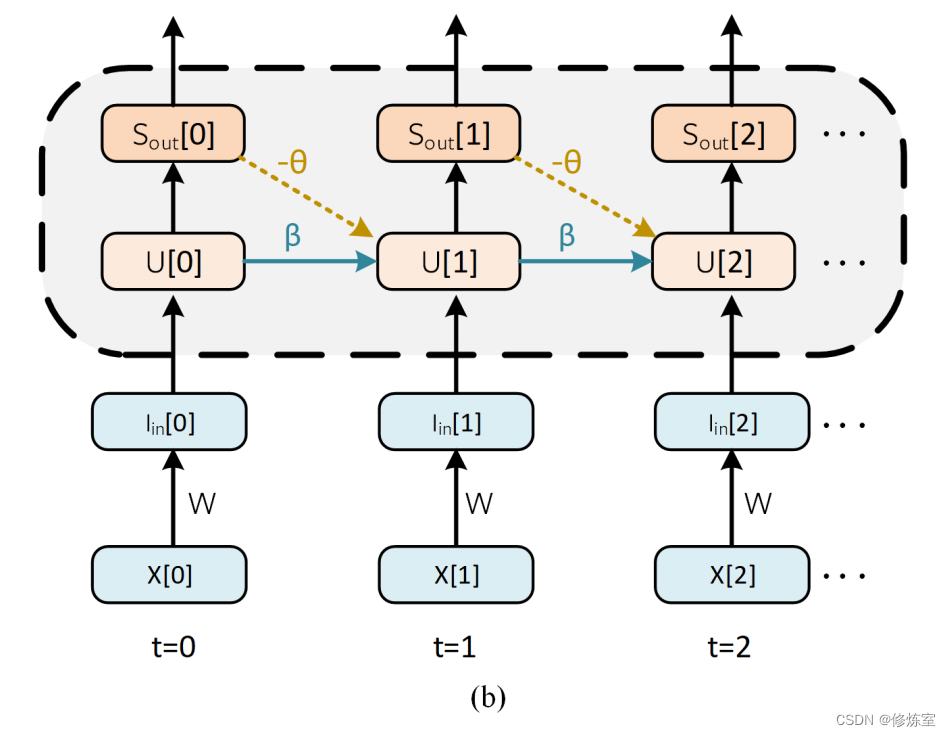
从网络的最终输出开始向后工作,梯度从损失传播到所有后代。通过这种方式,通过 SNN 计算梯度基本上与通过链式法则的迭代应用来计算 RNN 的梯度相同。图 10(a) 描述了梯度 ∂ L / ∂ W ∂L/∂W ∂L/∂W 从父节点 (L) 到其叶节点 (W) 的各个路径。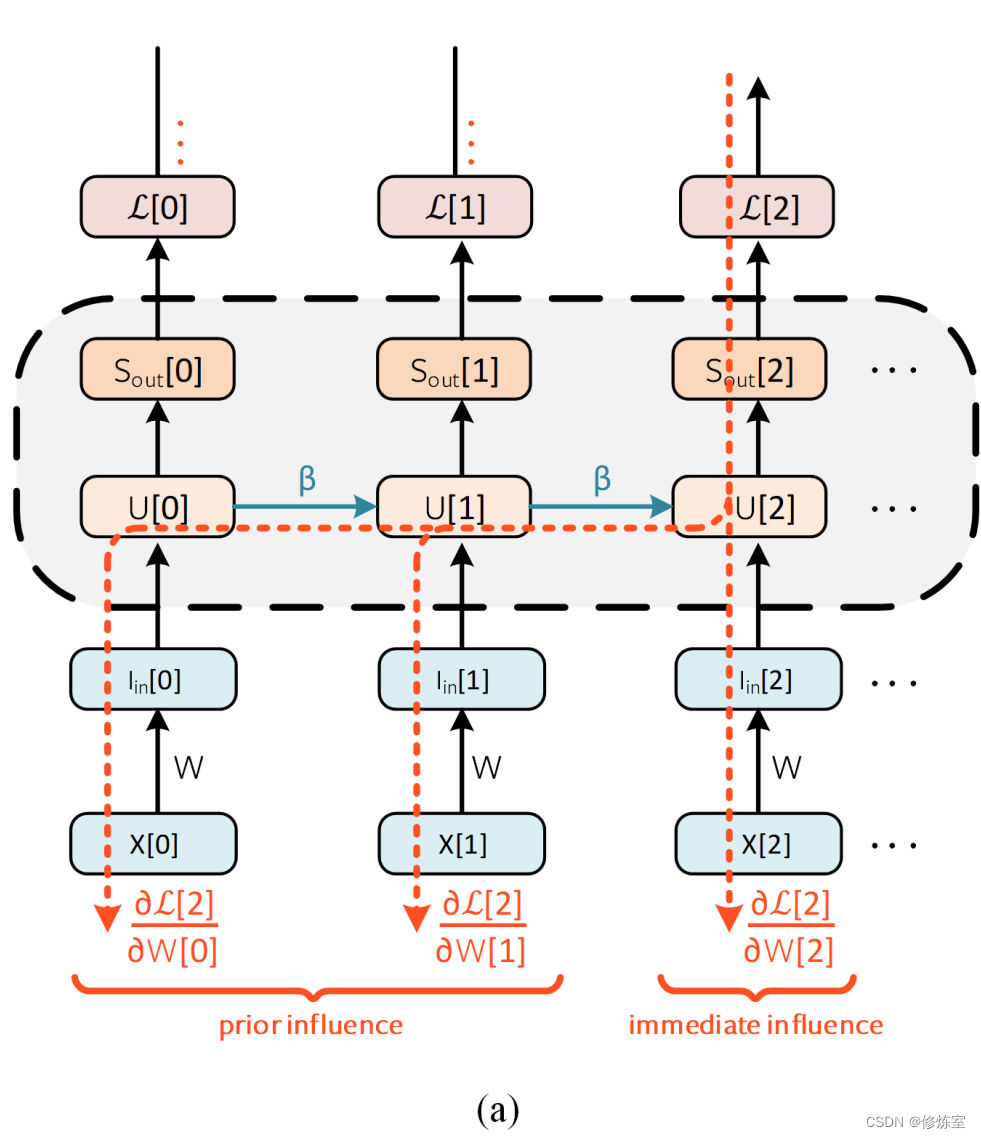
图10通过时间的反向传播。
(a) W W W 的当前时间应用称为即时影响, W W W 的历史应用称为先前影响。出于简洁起见,重置动态和显式循环已被省略。通过 L [ 0 ] L[0] L[0] 和 L [ 1 ] L[1] L[1] 的错误路径也被隐藏起来,但遵循与 L[2] 相同的思路。
相比之下,仅使用脉冲时间进行反向传播时,只有当神经元发放时才会遵循梯度路径,而这种方法则无论神经元是否发放都会遵循每条路径。最终损失是瞬时损失 ∑ t L [ t ] \sum_{t} \mathcal{L}[t] ∑tL[t] 的总和,尽管损失计算可以采用第 3.3 节中描述的各种其他形式。
找到总损失相对于参数的导数允许使用梯度下降来训练网络,因此目标是找到 ∂ L / ∂ W ∂L/∂W ∂L/∂W。参数 W W W 在每个时间步都被应用,特定步骤上的权重应用被表示为 W [ s ] W[s] W[s] 。假设可以在每个时间步计算瞬时损失 L [ t ] L[t] L[t](要注意的是,某些目标函数,如均方脉冲率损失(第 3.3.1 节),必须等到序列结束才能累积所有脉冲并生成损失)。由于前向传播需要通过有向无环图移动数据,每次权重的应用只会影响当前和未来的损失。
在图 10(a) 中, W [ s ] W[s] W[s] 对 L [ t ] L[t] L[t] 在 s = t s = t s=t 的影响被标记为即时影响。对于 s < t s < t s<t,我们将 W [ s ] W[s] W[s] 对 L [ t ] L[t] L[t] 的影响称为先前影响。所有参数应用对当前和未来损失的影响被总结在一起定义全局梯度:
∂ L ∂ W = ∑ t ∂ L [ t ] ∂ W = ∑ t ∑ s ≤ t ∂ L [ t ] ∂ W [ s ] ∂ W [ s ] ∂ W ( 6 ) \frac{\partial \mathcal{L}}{\partial W}=\sum_{t} \frac{\partial \mathcal{L}[t]}{\partial W}=\sum_{t} \sum_{s \leq t} \frac{\partial \mathcal{L}[t]}{\partial W[s]} \frac{\partial W[s]}{\partial W} (6) ∂W∂L=t∑∂W∂L[t]=t∑s≤t∑∂W[s]∂L[t]∂W∂W[s](6)
一个循环系统将会限制权重在所有步骤上是共享的: W [ 0 ] = W [ 1 ] = ⋅ ⋅ ⋅ = W W[0] = W[1] = · · · = W W[0]=W[1]=⋅⋅⋅=W。因此, W [ s ] W[s] W[s] 的变化将对所有其他 W W W 的值产生等效影响,这表明 ∂ W [ s ] / ∂ W = 1 ∂W[s]/∂W = 1 ∂W[s]/∂W=1,方程 (6) 简化为:
∂ L ∂ W = ∑ t ∑ s ≤ t ∂ L [ t ] ∂ W [ s ] ( 7 ) \frac{\partial \mathcal{L}}{\partial W}=\sum_{t} \sum_{s \leq t} \frac{\partial \mathcal{L}[t]}{\partial W[s]} (7) ∂W∂L=t∑s≤t∑∂W[s]∂L[t](7)
实用提示:我需要记住所有这些才能使用 SNN 吗?
幸运的是,梯度很少需要手动计算,因为大多数深度学习包都带有自动微分引擎。使用 SNN 并不需要对其内部结构有深入了解。但要推进 SNN 研究,当然需要这些知识!
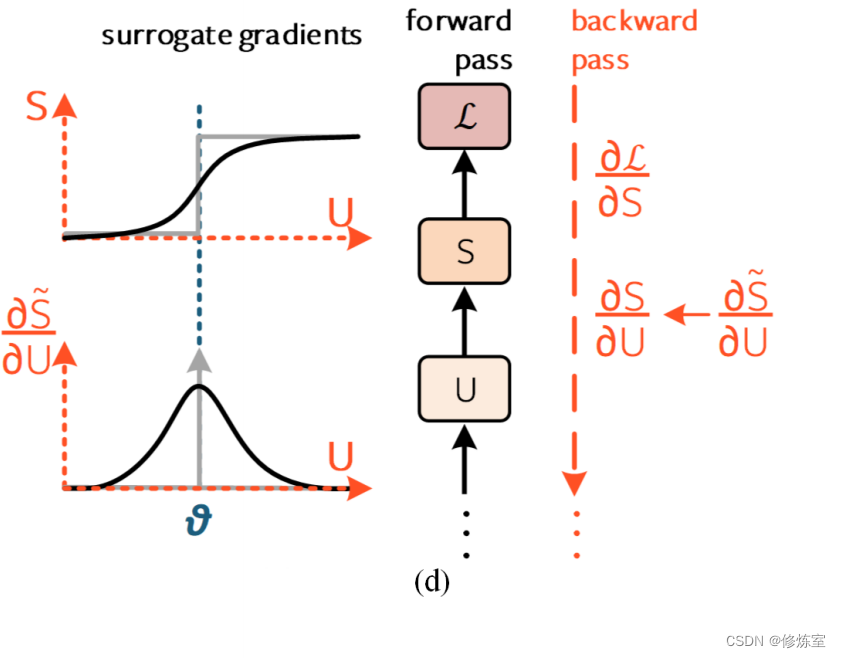
在图 9(d) 中隔离单个时间步的即时影响时,我们会发现 脉冲不可微性 问题出现在 ∂ S / ∂ U ∈ { 0 , ∞ } ∂S/∂U ∈ \{0, ∞ \} ∂S/∂U∈{0,∞} 项中。对膜电位进行阈值操作在功能上等同于应用一个移位的 Heaviside 算子,而这是不可微的。
解决方案其实很简单。在前向传播过程中,像往常一样对 U [ t ] U[t] U[t] 应用 Heaviside 算子以确定神经元是否发放脉冲。但在反向传播过程中,用连续函数 S ˜ S˜ S˜(例如 sigmoid)替换 Heaviside 算子。使用连续函数的导数作为替代 ∂ S / ∂ U ← ∂ S / ∂ U ˜ ∂S/∂U ← ∂S/∂U˜ ∂S/∂U←∂S/∂U˜,这被称为代理梯度方法(图 9(d))。
4.3.1 代理梯度
代理梯度的一个主要优点是它们有助于克服死神经元问题。为了更具体地说明死神经元问题,可以考虑一个具有阈值 θ 的神经元,并且以下情况之一发生:
- 膜电位低于阈值:U < θ
- 膜电位高于阈值:U > θ
- 膜电位正好达到阈值:U = θ
在案例 1 中,没有脉冲被引发,导数为 ∂ S / ∂ U U < θ = 0 \partial S / \partial U_{U < \theta} = 0 ∂S/∂UU<θ=0 。在案例 2 中,一个脉冲会发放,但导数仍为 ∂ S / ∂ U U > θ = 0 \partial S / \partial U_{U > \theta} = 0 ∂S/∂UU>θ=0 。将这两者中的任何一个应用到图 9(a) 中的方程链中都会使 ∂ L / ∂ W = 0 \partial L / \partial W = 0 ∂L/∂W=0 归零。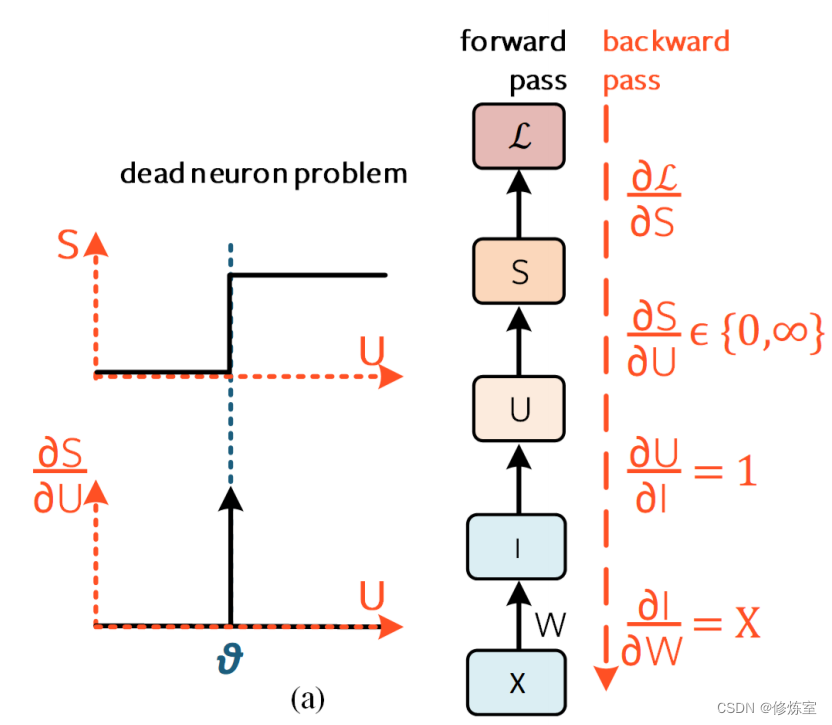
在案例 3 中极不可能发生的情况, ∂ S / ∂ U U = θ = ∞ \partial S / \partial U_{U = \theta} = \infty ∂S/∂UU=θ=∞ ,当应用链式法则时,这会淹没(swamps)任何有意义的梯度。但近似梯度, ∂ S ~ / ∂ U \partial \tilde{S} / \partial U ∂S~/∂U ,可以解决这个问题。
一种方法是用阈值移位的 sigmoid 函数替换不可微的项,但仅在反向传播过程中使用。这在图 9(d) 中有所展示。更正式地说:
σ ( ⋅ ) = 1 1 + e θ − U , ( 8 ) \sigma(\cdot) = \frac{1}{1 + e^{\theta - U}}, (8) σ(⋅)=1+eθ−U1,(8)
因此,
∂ S ∂ U ← ∂ S ~ ∂ U = σ ′ ( ⋅ ) = e θ − U ( e θ − U + 1 ) 2 . ( 9 ) \frac{\partial S}{\partial U} \leftarrow \frac{\partial \tilde{S}}{\partial U} = \sigma'(\cdot) = \frac{e^{\theta - U}}{(e^{\theta - U} + 1)^2}. (9) ∂U∂S←∂U∂S~=σ′(⋅)=(eθ−U+1)2eθ−U.(9)
要从第一个式子得到第二个式子,我们需要使用链式法则来计算导数。首先,我们有:
∂ S ~ ∂ U = ∂ ∂ U ( 1 1 + e θ − U ) = − 1 ( 1 + e θ − U ) 2 ⋅ ∂ ∂ U ( 1 + e θ − U ) = − 1 ( 1 + e θ − U ) 2 ⋅ e θ − U ⋅ ( − 1 ) = e θ − U ( 1 + e θ − U ) 2 . \begin{aligned} \frac{\partial \tilde{S}}{\partial U} &= \frac{\partial}{\partial U} \left( \frac{1}{1 + e^{\theta - U}} \right) \\ &= -\frac{1}{(1 + e^{\theta - U})^2} \cdot \frac{\partial}{\partial U} (1 + e^{\theta - U}) \\ &= -\frac{1}{(1 + e^{\theta - U})^2} \cdot e^{\theta - U} \cdot (-1) \\ &= \frac{e^{\theta - U}}{(1 + e^{\theta - U})^2}. \end{aligned} ∂U∂S~=∂U∂(1+eθ−U1)=−(1+eθ−U)21⋅∂U∂(1+eθ−U)=−(1+eθ−U)21⋅eθ−U⋅(−1)=(1+eθ−U)2eθ−U.
- e x e^x ex的导数是 e x e^x ex
- x − 1 x^{-1} x−1的导数是 − x − 2 -x^{-2} −x−2
这意味着只有在有脉冲活动时才会进行学习。考虑一个突触权重连接到发放脉冲的神经元的输入, W i n W_{in} Win ,以及在同一神经元的输出上的另一个权重, W o u t W_{out} Wout 。假设发生了以下事件序列:
- 一个输入脉冲, S i n S_{in} Sin 被 W i n W_{in} Win 放大。
- 被加权的脉冲作为输入电流注入到发放脉冲的神经元中(方程 (4))。
U [ t ] = β U [ t − 1 ] ⏟ decay + W X [ t ] ⏟ input − S out [ t − 1 ] θ ⏟ reset ( 4 ) U[t]=\underbrace{\beta U[t-1]}_{\text {decay }}+\underbrace{W X[t]}_{\text {input }}-\underbrace{S_{\text {out }}[t-1] \theta}_{\text {reset }} (4) U[t]=decay βU[t−1]+input WX[t]−reset Sout [t−1]θ(4)
- 这可能会导致神经元触发一个脉冲, S o u t S_{out} Sout 。
- 输出脉冲被输出权重 W o u t W_{out} Wout 加权。
- 这个加权的输出脉冲在某些任意损失函数 L \mathcal{L} L 中变化。
让损失函数为目标值 y y y 和加权脉冲之间的曼哈顿距离(Manhattan distance):
L = ∣ W o u t S o u t − y ∣ , \mathcal{L} = |W_{out} S_{out} - y|, L=∣WoutSout−y∣,
其中更新 W o u t W_{out} Wout 需要:
∂ L ∂ W o u t = S o u t \frac{\partial \mathcal{L}}{\partial W_{out}} = S_{out} ∂Wout∂L=Sout
更一般地说: 必须触发一个脉冲才能更新权重 。替代梯度不会改变这一点。
现在考虑更新 W i n W_{in} Win 的情况,其中必须计算以下导数:
∂ L ∂ W i n = ∂ L ∂ S o u t ⏟ A ∂ S o u t ∂ U ⏟ B ∂ U ∂ W i n ⏟ C \frac{\partial \mathcal{L}}{\partial W_{in}} = \underbrace{\frac{\partial \mathcal{L}}{\partial S_{out}}}_{\text{A}} \underbrace{\frac{\partial S_{out}}{\partial U}}_{\text{B}} \underbrace{\frac{\partial U}{\partial W_{in}}}_{\text{C}} ∂Win∂L=A ∂Sout∂LB ∂U∂SoutC ∂Win∂U
- 项 A 基于上述的 L \mathcal{L} L 方程只是 W o u t W_{out} Wout
- 项 B 几乎总是为 0,除非替换为替代梯度
- 项 C 是 S i n S_{in} Sin(参见方程 (4) 其中 X = S i n X = S_{in} X=Sin)
总结:替代梯度使得误差能够传播到更早的层,无论是否触发脉冲。 但仍然需要触发脉冲来更新权重。
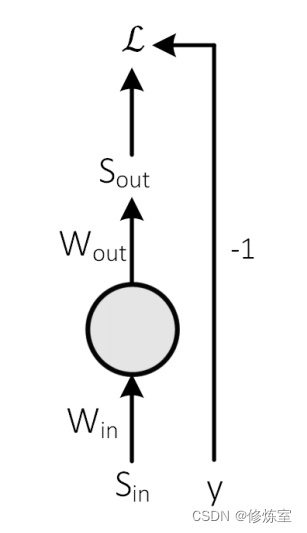
图 11:前向传播过程中的步骤序列。
实用笔记:最佳替代梯度?
各种工作经验性地探索了不同的替代梯度。这些包括三角函数、快速Sigmoid和Sigmoid函数、直通估计器(straight-through estimators),以及各种其他奇怪的形状。是否有最佳的替代梯度?根据我们的经验,我们发现以下函数是最佳的起始点:
∂ S ~ ∂ U = 1 π 1 1 + ( π U ) 2 \frac{\partial \tilde{S}}{\partial U} = \frac{1}{\pi} \frac{1}{1 + (\pi U)^2} ∂U∂S~=π11+(πU)21
你可能会看到这被称为“arctan”替代梯度,最初在Ref. [173]中提出。这是因为该函数的积分是:
[173] Wei Fang, Zhaofei Yu, Yanqi Chen, Tiejun Huang, Timothée Masquelier, and Yonghong Tian. Deep residual learning in spiking neural networks. Advances in Neural Information Processing Systems, 34:21056–21069,2021
S ~ = 1 π arctan ( π U ) \tilde{S} = \frac{1}{\pi} \arctan(\pi U) S~=π1arctan(πU)
截至2023年,这是snnTorch中默认的替代梯度。我们不知道为什么它效果如此好。
重申一下,替代梯度在没有脉冲的情况下无法实现学习。这引发了一个重要的区别,即死神经元问题和梯度消失问题。死神经元是指 不发放脉冲的神经元 ,因此不会对损失产生影响。这意味着连接到该神经元的权重在信用分配问题中没有“贡献”(‘credit’)。在训练过程中,相关的梯度项将保持为零。因此,神经元无法学习在以后发放脉冲,因此永远被困在不贡献于学习的状态中。
另一方面,梯度消失问题也会在人工神经网络(ANNs)和脉冲神经网络(SNNs)中出现。对于深度网络,由于多个常见激活函数(例如sigmoid单元)的值小于‘1’,损失函数的梯度可能会逐渐变小。类似地,循环神经网络(RNNs)非常容易受到梯度消失问题的影响,因为它们在每个时间步引入了一个额外的展开计算图层。每一层在计算梯度时都会增加另一个乘法因子,如果这个因子小于‘1’,则容易发生梯度消失,如果大于‘1’,则容易发生梯度爆炸。ReLU激活函数被广泛采用以减少梯度消失的影响,但在替代梯度实现中仍然被低估。
在snnTorch中,替代梯度不需要被显式地定义,因为默认情况下会应用arctan替代梯度。但以下代码片段展示了如何使用具有漏电积分-发放(Leaky Integrate-and-Fire)神经元的另一种替代梯度:
import snntorch as snn
from snntorch import surrogate
lif_1 = snn.Leaky(beta=0.9, spike_grad=surrogate.fast_sigmoid())
lif_2 = snn.Leaky(beta=0.9, spike_grad=surrogate.sigmoid())
lif_3 = snn.Leaky(beta=0.9, spike_grad=surrogate.straight_through_estimator())
lif_4 = snn.Leaky(beta=0.9, spike_grad=surrogate.triangular())
替代梯度已经被用于大多数原生训练SNN的最新实验中。已经使用了各种不同程度成功的替代梯度函数,选择哪种函数可以视为超参数。虽然有几项研究探讨了各种替代梯度对学习过程的影响,但我们对于偏置梯度估计器的了解往往是有限的。这里还有很多问题没有答案。例如,如果我们可以通过近似梯度来解决问题,那么也许替代梯度可以与随机反向传播相结合。这涉及在反向传播过程中用随机矩阵替换权重。也许可以进行局部逼近( local approximations ),以符合替代梯度的精神,而不是纯粹的随机性。
总结一下,仅在脉冲时计算梯度提供了梯度的无偏估计,但以失去训练死神经元的能力为代价。替代梯度下降将其颠倒过来,通过引入梯度的有偏估计使死神经元 能够反向传播错误信号 。在使死神经元复活和引入偏差之间存在一种拉锯战(tug-of-war)。鉴于替代梯度已经变得如此普遍,我们将在描述它们与模型量化的关系时稍作停留。理解梯度下降中的近似对学习的影响很可能会导致对替代梯度为何如此有效、如何改进它们以及如何通过进行减少训练成本而不损害目标的逼近来简化反向传播的更深入理解。
在传统的神经网络中,我们使用反向传播算法来计算损失函数相对于网络参数的梯度,以便通过梯度下降来更新参数。但是,在脉冲神经网络中,由于神经元的脉冲性质,传统的反向传播算法无法直接应用。因此,文章介绍了一种称为代理梯度的方法,以在脉冲神经网络中实现类似于反向传播的学习。
在脉冲神经网络中,神经元通过发放脉冲来传递信息。为了计算损失函数相对于参数的梯度,我们需要考虑脉冲发放对损失函数的影响。文章中提到了两种方法:
- 通过时间的反向传播(BPTT):这种方法类似于传统神经网络中的反向传播。它通过计算损失函数从输出到输入的路径,以确定参数对损失函数的影响。但是,这种方法在计算上可能会很昂贵,并且不适用于所有类型的损失函数。
- 替代梯度(Surrogate Gradients):替代梯度是一种简化的方法,它将非可微的脉冲函数替换为可微的函数。这样,在反向传播过程中,我们可以使用这些可微函数的导数来近似计算梯度。这种方法使得梯度的计算更加高效,但仍然需要脉冲发放来实际更新参数。
4.3.2 替代梯度与量化神经网络之间的联系
替代梯度已经存在了十多年,有几种不同的伪装方式。Hinton通过在反向传播过程中简单地忽略二值化神经网络中的激活和权重的阈值化挑战,创造性地克服了这一挑战。他创造了“直通估计器”(‘straight-through-estimator’)这一术语,因为梯度在不可微分操作符上“直通”。等效地,这就像将替代梯度设置为 ∂ S / ∂ U ˜ = 1 ∂S/∂U ˜ = 1 ∂S/∂U˜=1 。在训练量化神经网络时,采用了完全相同的方法。
替代梯度的简要历史
在Hinton引入直通估计器几年后,Hunsberger和Eliasmith使用了“软化”(‘softened’)的函数来描述漏电积分神经元(leaky integrator neuron)的发放率,使它们适合反向传播。随后,Lee、Delbruck和Pfeiffer在2016年首次演示了近似处理脉冲信号的反向路径[178]。这与我们今天所做的类似。但Shrestha和Orchard是首次发布与PyTorch兼容SLAYER的代码的人,他们在2018年在反向传播中使用了快速Sigmoid梯度[75]。2019年是“替代梯度”这一术语被Zenke、Mostafa和Neftci创造的时候[174],Zenke的代码库SpyTorch展示了如何在PyTorch中使用特性来非常容易地实现梯度近似[152]。这催生了各种应用、项目和库的迅速发展,包括snntorch,在这些技术上继续扩展。
[178] Jun Haeng Lee, Tobi Delbruck, and Michael Pfeiffer. Training deep spiking neural networks using backpropagation. Frontiers in neuroscience, 10:508, 2016
[75] Sumit Bam Shrestha and Garrick Orchard. SLAYER: Spike layer error reassignment in time. In Proc. of the 32nd Int. Conf. on Neural Inf. Process. Syst., pages 1419–1428, 2018.
[174] Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spiking neural networks:Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag.,36(6):51–63, 2019.
[152] Friedemann Zenke. Spytorch. Online: https://github.com/fzenke/spytorch. 2019
训练量化神经网络涉及调整权重和激活值,以使用低精度定点表示,同时保持可接受的性能和准确性。与浮点运算相比,量化定点算术需要更少的计算资源和更低的内存存储,并且通常在加速器中广泛使用,包括神经形态学和其他类型的加速器。已经提出了几种方法来构建量化神经网络,它们可以广泛分为以下几种方法:
-
后量化(Post-training quantization):神经网络首先使用标准浮点运算进行训练。一旦训练完成,权重和激活值将被量化为低精度定点表示。后量化方法实现简单、计算效率高,但对于某些模型或任务可能会导致 显著的精度损失 。
-
量化感知训练(Quantization-aware training):这种方法在训练过程中将量化内置到前向传播中。量化过程是不可微的,因此在梯度计算步骤中通过应用Hinton的直通估计器(straight-through-estimator)来忽略量化。权重更新应用于完整精度的权重,在前向传播过程中才进行量化。这使得模型能够学习如何在训练过程中补偿量化误差,从而比后量化方法具有更好的性能和准确性。然而,量化感知训练需要 更多的计算资源 ,并且可能需要修改训练算法。
-
混合精度训练(Mixed-precision training):神经网络的不同部分使用不同级别的数值精度。例如,前向传播可能使用低精度定点运算,而反向传播和权重更新则使用较高精度的浮点运算。这种方法可以帮助保持
减少计算复杂性和内存需求的好处,同时最大限度地减少对模型准确性的影响。 -
二值和三值神经网络(Binary and ternary neural networks):这些是量化神经网络的极端情况,其中权重和激活值被量化为二进制或三进制值,通常对于三值网络是{-1, 0, 1},对于二值网络是{-1, 1}。训练这样的网络通常涉及学习一个实值缩放因子,以改善模型的表达能力。这些超低精度网络可以显著减少计算需求和功耗,但可能会导致准确性降低或模型复杂性增加。
多项研究表明,当使用量化感知训练时,脉冲神经网络(SNNs)对量化(quantization)非常稳健。在极端情况下,二值化权重对一系列分类问题的影响似乎要比等效的非脉冲神经网络弱得多。我们的工作理论是因为近似和截断误差很可能被吸收在神经元的亚阈动态中。
下面的代码示例展示了如何使用Python库Brevitas构建量化SNNs。Brevitas在训练过程中已经考虑了直通估计器梯度,因此开发者在反向传播过程中不需要进行任何修改[183]。值得注意的是,这种方法模拟了一个降低精度的网络,但并不以降低精度格式表示变量。
import snntorch as snn
import torch.nn as nn
import brevitas.nn as qnn
# 全精度模型
net = nn.Sequential(nn.Linear(784, 10),
snn.Leaky(beta=0.9, init_hidden=True))
# 量化模型
num_bits = 8
quant_net = nn.Sequential(qnn.QuantLinear(784, 10, weight_bit_width=num_bits),
snn.Leaky(beta=0.9, init_hidden=True))
这段代码片段量化了权重和激活。通常会忽略膜电位和隐藏状态,并在训练过程之外进行后量化。还可以进行基于状态的量化感知训练,其中在前向传播过程中对膜电位进行离散化。在snnTorch中可以很容易地处理这种情况,方法是向神经元模型传递一个参数,在前向传播过程中触发膜电位的量化:
from snntorch.functional import quant
# 设置量化参数
q_lif = quant.state_quant(num_bits=4)
# 基于状态量化的模型
quant_net = nn.Sequential(
qnn.QuantLinear(784, 10, weight_bit_width=num_bits),
snn.Leaky(beta=0.9, init_hidden=True, state_quant=q_lif)
)
实用提示:量化范围
假设你有N位用于表示权重和状态。你如何确定这N位应该覆盖的范围?权重将使用最小和最大全精度权重值作为范围。状态在如何最好地表示方面尚未深入探讨,但我们早期的实验结果表明,对于归一化的静息电位为0伏特,负值可以安全地被截断。这使得正值状态具有更好的分辨率,而不会浪费在不触发脉冲的范围上。当然,在负阈值可以触发抑制性脉冲的情况下,这并不适用。
4.3.3 SNN中BPTT的一些技巧
深度学习的许多进展源于一系列增量技术,这些技术增强了模型的学习能力。这些技术结合应用,以提升模型性能。例如,何等人在《用卷积神经网络进行图像分类的技巧》(‘Bag
of tricks for image classification with convolutional neural networks’)中的工作不仅在标题中捕捉了深度学习的真实状态,还进行了一个消融研究,探讨了可以结合使用以改善训练过程中的优化的“技巧”。其中一些技术可以直接从深度学习转移到SNNs,而其他技术则是SNN特有的。本节提供了这些技术的非详尽列表。这些技术相当经验性,每个小点都会有自己的“实用提示”文本框,但这样本文将变成一堆文本框。
- 重置机制(The reset mechanism ) 在方程(4)中是一个关于脉冲的函数,也是不可微的。重要的是要确保在重置函数中不克隆代理梯度,因为经验证明这会降低网络性能。简单地说,在反向传播过程中我们忽略它。snnTorch通过调用“.detach()”函数自动将方程(4)中的重置项从计算图中分离出来。
- 残差连接(Residual connections ) 对非脉冲网络和脉冲模型都非常有效。它通过允许将较早层的输出添加到较后层的输出来创建层间的直接路径,有效地跳过中间的一个或多个层。它们用于解决
梯度消失问题,在正向和反向传播过程中改善信息流动,这使得神经网络社区能够构建更深层次的体系结构,从ResNet系列模型开始,现在在Transformer中普遍使用。毫不奇怪,它们对SNNs也非常有效。 - 可学习衰减(Learnable decay):与其将神经元的衰减率视为超参数,不如将其作为可学习参数。这使得SNNs更加类似于传统的RNNs。这样做已经显示在具有时变特征的数据集上提高了测试性能。
- 分级脉冲(Graded Spikes): pass dendritic性质可以衰减动作电位,axon的电缆状性质也可以。这个特性可以粗略地表示为分级脉冲。每个神经元有一个额外的可学习参数,确定如何缩放输出脉冲。神经元的激活不再受限于{1, 0}。这仍然可以被视为SNN吗?从工程的角度来看,如果一个脉冲必须广播到具有8位或16位目标地址的各种下游神经元,那么在有效载荷中再添加几位可能是值得的。英特尔实验室的第二代Loihi芯片以这样一种方式结合了分级脉冲,以保持稀疏性。此外,学习值的向量与网络中神经元的数量呈线性关系,而不是与权重呈二次关系。因此,与SNN的其他组件相比,它只是产生了较小的成本。
- 可学习阈值(Learnable Thresholds) 并没有显示出帮助训练过程。这可能是由于阈值的离散特性,在计算图中产生了不可微的运算符。另一方面,对传递给阈值的值进行归一化显著有助于。在卷积网络中采用批量归一化有助于提高性能,可学习的归一化方法可能作为可学习阈值的有效替代。
- 池化(Pooling) 对于在卷积网络中降低大空间维度和实现平移不变性非常有效。如果将最大池化应用于稀疏的、脉冲型张量,则在1和0之间进行决策并不合理。人们可能期望我们可以借鉴训练二值化神经网络的思想,其中池化应用于在被阈值化为二值数量之前的激活。这相当于将池化应用于膜电位,以一种类似于“局部侧抑制”(‘local lateral inhibition’)的方式。但这并不一定会导致SNNs的最佳性能。有趣的是,余等人将池化应用于脉冲。在池化窗口中发生多次脉冲时,将在它们之间随机进行决策。尽管没有给出这样做的理由,但它仍然在一系列计算机视觉问题上实现了当时的最新技术。我们最好的猜测是,这种随机性起到了一种正则化的作用。无论是使用最大池化还是平均池化,都可以视为超参数。作为一种替代方案,SynSense的神经形态硬件采用了求和池化,通过将感受野中的脉冲重新路由到一个共同的后突触神经元来减少空间维度。
- 优化器(Optimizer) :大多数脉冲神经网络默认使用Adam优化器,因为经典上已经显示它在用于顺序模型时具有稳健性[189]。随着脉冲神经网络变得更深入,带动量的随机梯度下降似乎比Adam优化器更加普遍。读者可以参考Godbole等人的《深度学习调参手册》(Deep Learning Tuning Playbook)获得一种系统的超参数优化方法,该方法通常适用。
4.3.4 反向传播和局部学习之间的交集
当比较穿越不同时间段的反向传播路径时,会产生一个有趣的结果。
U [ t ] = β U [ t − 1 ] ⏟ decay + W X [ t ] ⏟ input − S out [ t − 1 ] θ ⏟ reset ( 4 ) U[t]=\underbrace{\beta U[t-1]}_{\text {decay }}+\underbrace{W X[t]}_{\text {input }}-\underbrace{S_{\text {out }}[t-1] \theta}_{\text {reset }} (4) U[t]=decay βU[t−1]+input WX[t]−reset Sout [t−1]θ(4)
根据方程(4),隐状态随时间的导数为 ∂ U [ t ] / ∂ U [ t − 1 ] = β ∂U[t]/∂U[t − 1] = β ∂U[t]/∂U[t−1]=β 。通过n个时间步长反向传播的梯度按 β n β^n βn 缩放。对于一个漏性神经元(a leaky neuron),我们得到 β < 1 β < 1 β<1 ,这导致了在一对脉冲之间的时间内的权重更新的幅度会随时间呈指数级减小。这种比例关系如图10(b)所示。
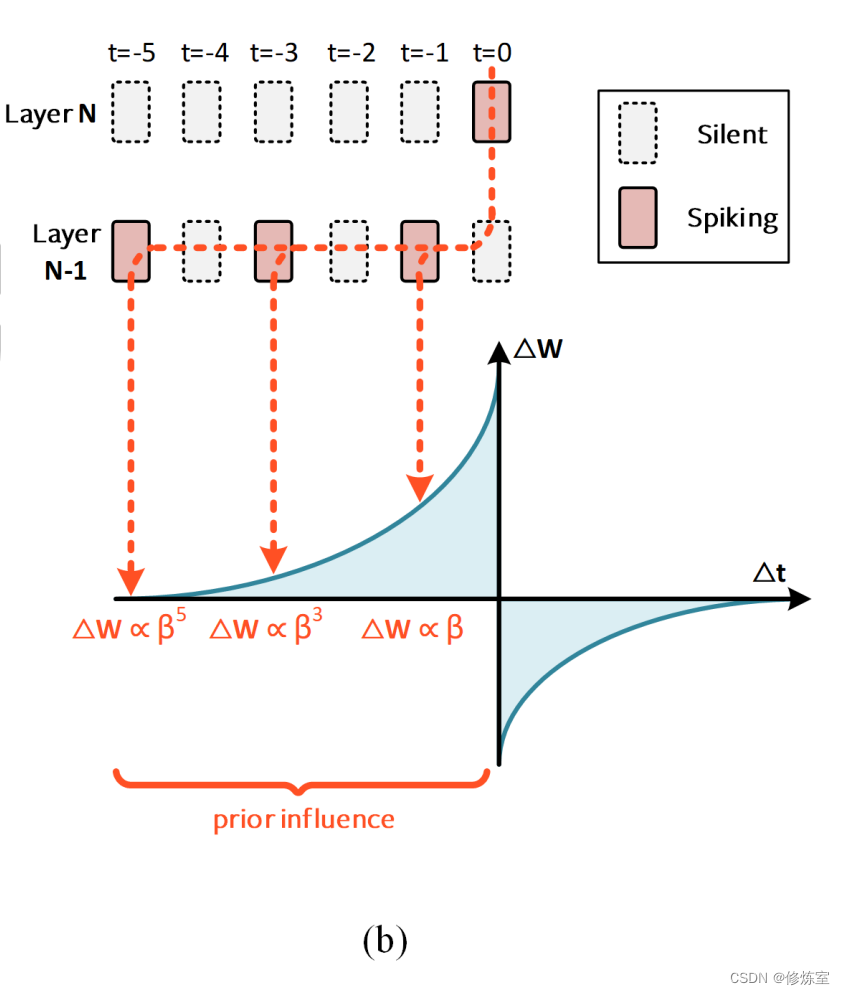
这个结果显示了突触更新的强度如何与一个神经元的突触前后脉冲之间的时间差呈指数比例关系。换句话说,来自BPTT的权重更新与突触时序相关可塑性(STDP)学习曲线的权重更新非常相似(附录C.2)。
这种联系只是巧合吗?BPTT是从函数优化中推导出来的。STDP是一个生物观察的模型。尽管是通过完全独立的方式发展起来的,它们却收敛于相同的结果。这可能会产生直接的实际影响,即训练模型的硬件加速器可以删除BPTT的一部分,并用成本更低、更局部的STDP规则替换。采用这种方法可以被认为是BPTT的在线变体,或者是梯度调制的STDP形式。
4.4 长期时间依赖性
神经元和突触的时间常数通常在1-100毫秒的时间尺度上。在这样的时间尺度下,解决需要超过最慢的神经元或突触时间常数的长程关联问题是困难的。这类问题在自然语言处理和强化学习中很常见,并且是理解人类行为和决策的关键。这一挑战对学习过程构成了巨大负担,消失梯度大大减慢了神经网络的收敛速度。LSTM和后来引入的GRU设计了慢动态,以克服RNN中的记忆和消失梯度问题。因此,对于脉冲神经网络来说,一个自然的解决方案是将神经动态的快速时间尺度与各种较慢的动态相结合。混合离散和连续的动态可能使脉冲神经网络能够学习发生在各种时间尺度上的特征。较慢的动态示例如下:
自适应阈值
-
自适应阈值(Adaptive thresholds):当一个神经元发放脉冲后,它进入一个难以再次发放脉冲的折返期。这可以通过每次神经元发放脉冲时增加其发放阈值 θ \theta θ 来建模。在神经元发放脉冲一段时间后,阈值会恢复到一个稳定状态。已知稳态阈值在相关学习规则(如STDP)中可以促进神经元的稳定性,这些规则在高频情况下有利于长期增强而不管脉冲时间。最近的研究发现,自适应阈值对脉冲神经网络中的梯度学习也有益。
-
递归注意力(Recurrent attention):自从在自然语言生成中大受欢迎以来,自注意力通过一次性向模型输入所有序列,找出长序列长度的token之间的相关性。这种数据表示方式与大脑处理数据的方式不完全相同。有几种方法将自注意力近似为一系列递归操作,其中SpikeGPT是脉冲领域的第一个应用,成功实现了语言生成。除了更复杂的基于状态的计算,SpikeGPT还采用了随时间变化的动态权重。
-
轴突延迟(Axonal delays):不同长度的轴突意味着存在广泛的脉冲传播延迟。一些神经元的轴突长度只有1毫米,而坐骨神经中的那些可以延伸到一米长。轴突延迟可以是一个跨越多个时间步长的可学习参数。一种较少探索的方法不仅考虑了轴突的不同延迟,还考虑了神经元树状突内的延迟变化。将轴突和树状突延迟结合起来,可以为每个突触设定一个固定的延迟。
-
膜动态(Membrane Dynamics):我们已经知道膜电位可以触发脉冲,但脉冲如何影响膜电位呢? 电压的快速变化会导致电场的累积 ,从而导致细胞温度的变化。焦耳热效应随着电压变化的平方增加,这会影响神经元的几何结构,并最终导致膜电容(以及时间常数)的变化。作为脉冲发放函数的衰减率调制可以作为生成特定神经元折返动力学(refractory dynamics)的二阶机制。
-
多稳定神经活动(Multistable Neural Activity):生物神经网络中的强递归连接可以支持多稳定动力学,这有助于信息在时间上的稳定存储。这种动力学,通常称为吸引子神经网络(attractor neural networks),被认为是大脑中工作记忆的基础,并且通常归因于前额皮质。使用梯度下降训练这种网络具有挑战性,目前还没有在脉冲神经网络中尝试过。
若干原始的慢时间尺度动力学已经在基于梯度的方法中被测试并成功应用于训练脉冲神经网络(SNN)。然而,还有许多神经元动力学尚未被探索。LSTM展示了信息时间调控的重要性,有效地解决了困扰RNN的短期记忆问题。将更细微的神经元特征转化为基于梯度的学习框架,毫无疑问可以增强SNN在高效表示动态数据方面的能力。
总结
问题一:Heaviside 算子是什么东西?
Heaviside 算子,也叫 Heaviside 阶跃函数,是一个数学函数,定义如下:
H ( x ) = { 0 if x < 0 1 if x ≥ 0 H(x) = \begin{cases} 0 & \text{if } x < 0 \\ 1 & \text{if } x \geq 0 \end{cases} H(x)={01if x<0if x≥0
它的作用是将输入信号根据某个阈值进行二值化处理。可以理解为一个开关,当输入信号达到或超过某个阈值时,开关“打开”,输出1;否则开关“关闭”,输出0。
在脉冲神经网络中,Heaviside 算子用于模拟神经元的发放行为。神经元在膜电位达到阈值时会发放脉冲,这种发放行为可以用 Heaviside 算子来表示:
S ( t ) = H ( U ( t ) − θ ) S(t) = H(U(t) - \theta) S(t)=H(U(t)−θ)
其中 U ( t ) U(t) U(t) 是膜电位, θ \theta θ 是发放阈值, S ( t ) S(t) S(t) 是脉冲信号。如果膜电位 U ( t ) U(t) U(t) 达到或超过阈值 θ \theta θ ,则 S ( t ) S(t) S(t) 为1(发放脉冲),否则为0(不发放脉冲)。
应用 Heaviside 算子以确定神经元是否发放脉冲
在脉冲神经网络的前向传播过程中,我们需要确定神经元在每个时间步是否发放脉冲。具体步骤如下:
- 计算膜电位:通过对输入信号和神经元权重进行加权求和得到膜电位 $U[t] $。
- 应用 Heaviside 算子:将膜电位 U [ t ] U[t] U[t] 代入 Heaviside 算子,得到脉冲信号 $S[t] )。
- 确定脉冲发放:根据 Heaviside 算子的输出,判断神经元在当前时间步是否发放脉冲。
代理梯度方法
Heaviside 算子虽然在前向传播中很好用,但它是不可微的,在反向传播中无法直接计算梯度。因此,我们使用代理梯度方法:
- 前向传播:正常使用 Heaviside 算子来确定神经元是否发放脉冲。
- 反向传播:用一个连续且可微的函数(例如 sigmoid 函数)来替代 Heaviside 算子,计算梯度。
通过这种方法,可以近似计算梯度,使得梯度下降算法能够正常工作,从而训练脉冲神经网络。
C.1 使用脉冲时间进行反向传播
在最初的 SpikeProp 描述中【124】,使用了脉冲响应模型:
U j ( t ) = ∑ i , k W i , j I i ( k ) ( t ) , U_j(t) = \sum_{i,k} W_{i,j} I_i^{(k)}(t), Uj(t)=i,k∑Wi,jIi(k)(t),
其中
I i ( k ) ( t ) = ϵ ( t − f i ( k ) ) , ( 43 ) I_i^{(k)}(t) = \epsilon(t - f_i^{(k)}), (43) Ii(k)(t)=ϵ(t−fi(k)),(43)
f i ( k ) f_i^{(k)} fi(k) 是第 k k k 个脉冲的发放时间, W i , j W_{i,j} Wi,j 是第 i i i 个突触前神经元和第 j j j 个突触后神经元之间的权重, U j ( t ) U_j(t) Uj(t) 是第 j j j 个神经元的膜电位。通常使用的 “alpha 函数” 核函数定义如下:
ϵ ( t ) = t τ e 1 − t τ Θ ( t ) , ( 44 ) \epsilon(t) = \frac{t}{\tau} e^{1-\frac{t}{\tau}} \Theta(t), (44) ϵ(t)=τte1−τtΘ(t),(44)
其中 τ \tau τ 和 Θ \Theta Θ 分别是核函数的时间常数和 Heaviside 阶跃函数。
考虑一个 SNN,其中每个目标指定了第 j j j 个输出神经元 y j y_j yj 的输出脉冲时间。这用于均方脉冲时间损失函数(公式 (37),附录 B.9),其中 f j f_j fj 是实际的脉冲时间。与其在整个仿真过程中进行反向传播,不如仅通过脉冲时间点的梯度路径进行传播。权重空间中损失的梯度为:
∂ L ∂ W i , j = ∂ L ∂ f j ∂ f j ∂ U j ∂ U j ∂ W i , j ∣ t = f j , ( 45 ) \frac{\partial L}{\partial W_{i,j}} = \frac{\partial L}{\partial f_j} \frac{\partial f_j}{\partial U_j} \frac{\partial U_j}{\partial W_{i,j}} \Big|_{t=f_j}, (45) ∂Wi,j∂L=∂fj∂L∂Uj∂fj∂Wi,j∂Uj t=fj,(45)
右侧的第一个项评估为:
∂ L ∂ f j = 2 ( y j − f j ) . ( 46 ) \frac{\partial L}{\partial f_j} = 2(y_j - f_j). (46) ∂fj∂L=2(yj−fj).(46)
第三项可以从公式 (43) 推导出:
∂ U j ∂ W i , j ∣ t = f j = ∑ k I i ( k ) ( f j ) = ∑ k ϵ ( f j − f i ( k ) ) . ( 47 ) \frac{\partial U_j}{\partial W_{i,j}} \Big|_{t=f_j} = \sum_k I_i^{(k)}(f_j) = \sum_k \epsilon(f_j - f_i^{(k)}). (47) ∂Wi,j∂Uj t=fj=k∑Ii(k)(fj)=k∑ϵ(fj−fi(k)).(47)
在公示(45)的第二项可以通过计算 − ∂ U j ∂ f j ∣ t = f j -\frac{\partial U_j}{\partial f_j} \Big|_{t=f_j} −∂fj∂Uj t=fj 然后取逆得到(公式 (45)):
在【124】中,可以通过公式 (43) 和 (44) 对 ( U_j(t) ) 的演化进行解析求解:
∂ f j ∂ U j ∣ t = f j ← ( − ∂ U j ∂ t ∣ t = f j ) − 1 = ( − ∑ i , k W i , j ∂ I i ( k ) ∂ t ∣ t = f j ) − 1 = ( ∑ i , k W i , j f j − f i ( k ) τ 2 e f j − f i ( k ) τ − 1 ) − 1 . \frac{\partial f_j}{\partial U_j} \Big|_{t=f_j} \leftarrow \left( - \frac{\partial U_j}{\partial t} \Big|_{t=f_j} \right)^{-1} = \left( - \sum_{i,k} W_{i,j} \frac{\partial I_i^{(k)}}{\partial t} \Big|_{t=f_j} \right)^{-1} = \left( \sum_{i,k} W_{i,j} \frac{f_j - f_i^{(k)}}{\tau^2} e^{\frac{f_j - f_i^{(k)}}{\tau} - 1} \right)^{-1}. ∂Uj∂fj t=fj←(−∂t∂Uj t=fj)−1= −i,k∑Wi,j∂t∂Ii(k) t=fj −1= i,k∑Wi,jτ2fj−fi(k)eτfj−fi(k)−1 −1.
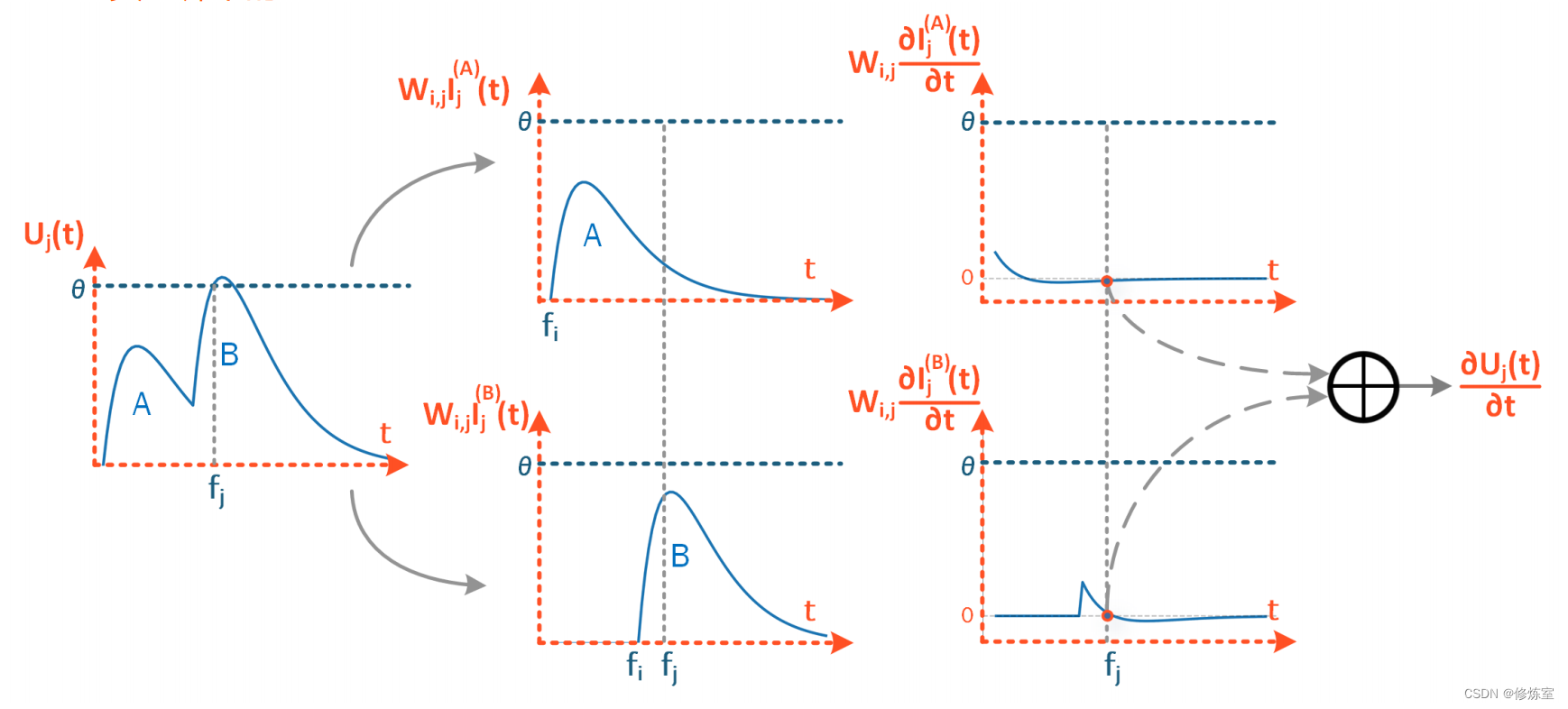
图 S.12:膜电位关于脉冲时间的导数计算。上标 (A) 和 (B) 表示核函数的每次应用的独立贡献。
注意,输入电流在突触前脉冲 t = f i t = f_i t=fi 的起点触发,但在突触后脉冲 t = f j t = f_j t=fj 处进行评估。结果可以组合为:
∂ L ∂ W i , j = 2 ( y j − f j ) ∑ k I i ( k ) ( f j ) ∑ i , k W i , j ( ∂ I i ( k ) ∂ t ) ∣ t = f j . \frac{\partial L}{\partial W_{i,j}} = \frac{2(y_j - f_j) \sum_k I_i^{(k)}(f_j)}{\sum_{i,k} W_{i,j} \left( \frac{\partial I_i^{(k)}}{\partial t} \right) \Big|_{t=f_j}}. ∂Wi,j∂L=∑i,kWi,j(∂t∂Ii(k)) t=fj2(yj−fj)∑kIi(k)(fj).
这种方法可以推广到处理更深层次,并且原始公式还包括未为简明起见而包括的延迟响应核。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 41
41 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)