BPTT算法详解:深入探究循环神经网络(RNN)中的梯度计算【原理理解】
引言
在深度学习领域中,我们经常处理的是独立同分布(i.i.d)的数据,比如图像分类、文本生成等任务,其中每个样本之间相互独立。然而,在现实生活中,许多数据具有时序结构,例如语言模型中的单词序列、股票价格随时间的变化、视频中的帧等。对于这类具有时序关系的数据,传统的深度学习模型可能无法很好地捕捉到其内在的 时间相关性 。为了解决这一问题,循环神经网络(Recurrent Neural Network, RNN)被广泛应用于处理时序数据。
为什么说反向传播算法不能处理时序数据呢?
在传统的反向传播算法中,处理静态数据时,网络的输出 y^\hat{y}y^ 通常只依赖于当前时刻的隐藏状态 hhh,其更新规则可以表示为:
h=Wx+b h = Wx + b h=Wx+b
y^=Vh+c \hat{y} = Vh + c y^=Vh+c
其中,hhh 是隐藏状态,xxx 是输入,WWW 和 VVV 是网络的参数,bbb 和 ccc 是偏置项。
与传统反向传播算法不同,BPTT(Back-Propagation Through Time)算法引入了时间维度,并考虑了序列数据中的时序关系。在 BPTT 中,隐藏状态 hth_tht 的更新规则包含了当前时刻的输入 XtX_tXt 和上一个时刻的隐藏状态 ht−1h_{t-1}ht−1,从而能够更好地捕捉到序列数据中的时间相关性。
ht=f(UXt+Wht−1)h_t = f(UX_t + Wh_{t-1})ht=f(UXt+Wht−1)
yt^=f(Vht)\hat{y_t} = f(Vh_t) yt^=f(Vht)
RNN 结构与BPTT
首先,让我们来了解一下常见的循环神经网络结构。在 RNN 中,隐藏状态会随着时间步的推移而更新,并在每个时间步生成一个输出。这种结构允许网络捕捉到序列数据中的时间相关性,使得其在时序任务中表现出色。
一个常见的RNN结构如下所示: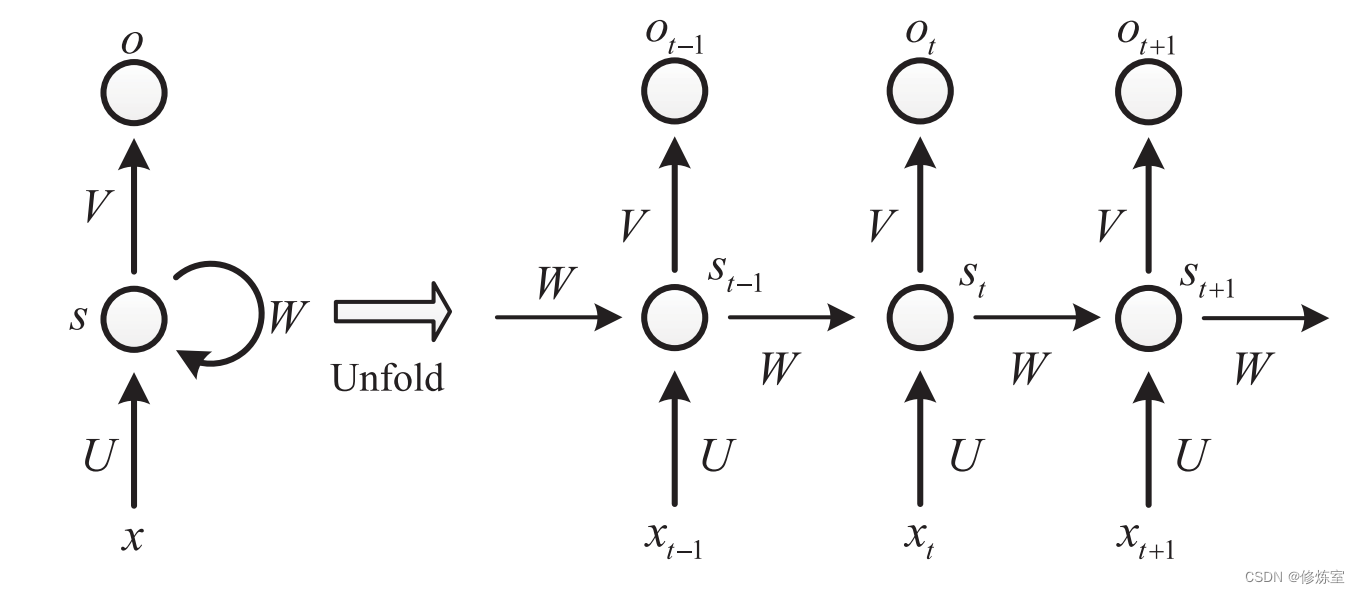
在RNN中,参数U、V和W是共享的,这意味着它们在每个时间步都保持不变。这意味着它们的值在整个模型运行过程中 始终保持一致 。
BPTT算法概述
前向传播
在 RNN 中,前向传播阶段通过计算隐藏状态和输出来生成预测结果。
ht=f(UXt+Wht−1)h_t = f(UX_t + Wh_{t-1})ht=f(UXt+Wht−1)
yt^=f(Vht)\hat{y_t} = f(Vh_t) yt^=f(Vht)
损失函数
这些结果与真实标签之间的差异通过损失函数来衡量,我们的目标是最小化这个损失函数。整个网络的损失值LLL是每个时刻损失值LtL_tLt的求和,其中LtL_tLt是关于预测值yt^\hat{y_t}yt^的函数。
Lt=f(yt^)L_t = f(\hat{y_t}) Lt=f(yt^)
L=∑i=1TLt L = \sum_{i=1}^{T} L_tL=i=1∑TLt
损失函数 LLL 可以表示为:
- 均方误差(MSE):
L=∑t=1T12(yt−y^t)2 L = \sum_{t=1}^T \frac{1}{2} (y_t - \hat{y}_t)^2 L=t=1∑T21(yt−y^t)2
这里,我们计算每个时间步的输出 yty_tyt 与真实输出 y^t\hat{y}_ty^t 之间的平方误差,并将所有时间步的误差求和。- 交叉熵损失:
L=−∑t=1T[y^tlog(yt)+(1−y^t)log(1−yt)] L = -\sum_{t=1}^T [\hat{y}_t \log(y_t) + (1 - \hat{y}_t) \log(1 - y_t)] L=−t=1∑T[y^tlog(yt)+(1−y^t)log(1−yt)]
这里,我们计算每个时间步的输出 yty_tyt 与真实输出 y^t\hat{y}_ty^t 之间的交叉熵损失,并将所有时间步的损失求和。
反向传播
接下来,我们使用BPTT算法(随时间反向传播,Back-Propagation Through Time,BPTT)进行反向传播。在这一步中,我们计算损失函数对参数U、V和W的偏导数,以便更新参数以最小化损失。
为什么要使用整个序列的损失函数L对参数U、V和W求导呢?
这是因为我们的目标是最小化整个序列的损失。在梯度下降算法中,梯度指向了损失函数增长最快的方向。因此,通过对整个序列的损失函数求导,我们可以找到在参数空间中使得损失函数逐步减小的方向,然后通过反向传播来更新参数。
由于RNN处理的是时序数据,因此需要基于时间进行反向传播,这也是BPTT名称的由来。尽管BPTT是在时序数据上进行反向传播,但本质上它仍然是反向传播算法,因此求解每个时间步的梯度是该算法的核心操作。
梯度计算
我们以一个长度为3的时间序列为例,展示对于参数U、V和W的偏导数的计算过程。
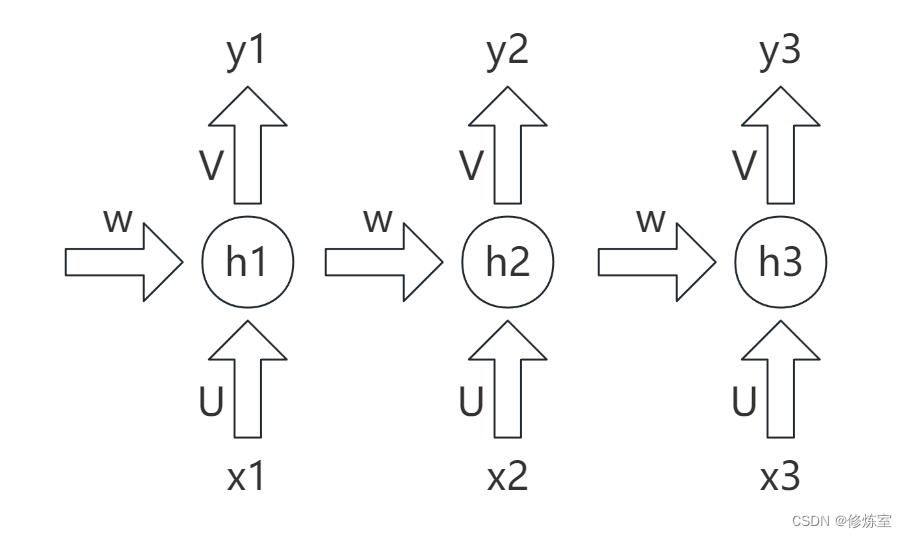
首先看看前向传播的计算
隐藏层输出:
ht=f(UXt+Wht−1)h_t = f(UX_t + Wh_{t-1})ht=f(UXt+Wht−1)
为什么“RNN的隐藏状态更新规则是 ht=f(UXt+Wht−1)h_t = f(UX_t + Wh_{t-1})ht=f(UXt+Wht−1)”?
从数学角度来看,这个更新规则是由RNN的结构决定的。在RNN中,隐藏状态
hth_tht 是
- 由当前时间步的输入 XtX_tXt
- 前一个时间步的隐藏状态 ht−1h_{t-1}ht−1
组合而成的。通过线性变换 UXt+Wht−1UX_t + Wh_{t-1}UXt+Wht−1,加上激活函数 fff 的作用,得到了新的隐藏状态 hth_tht。这个结构使得RNN能够记忆之前的信息并将其应用于当前的预测任务中。
输出层:
yt^=f(Vht)\hat{y_t} = f(Vh_t) yt^=f(Vht)
- hth_tht 是隐藏状态
- yt^\hat{y_t}yt^ 是输出值
- XtX_tXt 输入的序列
- fff是激活函数
将上面的RNN用数学表达式来表示就是
{h1=f(Ux1+Wh0)y^1=f(Vh1) \left\{\begin{array}{l}h_{1}=f\left(U x_{1}+W h_{0}\right) \\\hat{y}_{1}=f\left(V h_{1}\right)\end{array}\right. {h1=f(Ux1+Wh0)y^1=f(Vh1)
{h2=f(Ux2+Wh1)y^2=f(Vh2) \left\{\begin{array}{l}h_{2}=f\left(U x_{2}+W h_{1}\right) \\\hat{y}_{2}=f\left(V h_{2}\right)\end{array}\right. {h2=f(Ux2+Wh1)y^2=f(Vh2)
{h3=f(Ux3+Wh2)y^3=f(Vh3) \left\{\begin{array}{l}h_{3}=f\left(U x_{3}+W h_{2}\right) \\\hat{y}_{3}=f\left(V h_{3}\right)\end{array}\right. {h3=f(Ux3+Wh2)y^3=f(Vh3)
针对t=3t=3t=3时刻,求U,V,W的梯度(偏导),使用链式法则得到:
∂L3∂V=∂L3y^3×∂y^3∂V\frac{\partial L_3}{\partial V} = \frac{\partial L_3}{\hat{y}_{3}} \times \frac{\partial \hat{y}_{3}}{\partial V} ∂V∂L3=y^3∂L3×∂V∂y^3
∂L3∂W=∂L3∂y^3×∂y^3∂h3×∂h3∂W+∂L3∂y^3×∂y^3∂h3×∂h3∂h2×∂h2∂W+∂L3∂y^3×∂y^3∂h3×∂h3∂h2×∂h2∂h1×∂h1∂W \frac{\partial L_{3}}{\partial W}=\frac{\partial L_{3}}{\partial \hat{y}_{3}} \times \frac{\partial \hat{y}_{3}}{\partial h_{3}} \times \frac{\partial h_{3}}{\partial W}+\frac{\partial L_{3}}{\partial \hat{y}_{3}} \times \frac{\partial \hat{y}_{3}}{\partial h_{3}} \times \frac{\partial h_{3}}{\partial h_{2}} \times \frac{\partial h_{2}}{\partial W}+\frac{\partial L_{3}}{\partial \hat{y}_{3}} \times \frac{\partial \hat{y}_{3}}{\partial h_{3}} \times\frac{\partial h_{3}}{\partial h_{2}} \times \frac{\partial h_{2}}{\partial h_{1}} \times \frac{\partial h_{1}}{\partial W} ∂W∂L3=∂y^3∂L3×∂h3∂y^3×∂W∂h3+∂y^3∂L3×∂h3∂y^3×∂h2∂h3×∂W∂h2+∂y^3∂L3×∂h3∂y^3×∂h2∂h3×∂h1∂h2×∂W∂h1
∂L3∂U=∂L3∂y^3×∂y^3∂h3×∂h3∂U+∂L3∂y^3×∂y^3∂h3×∂h3∂h2×∂h2∂U+∂L3∂y^3×∂y^3∂h3×∂h3∂h2×∂h2∂h1×∂h1∂U \frac{\partial L_{3}}{\partial U}=\frac{\partial L_{3}}{\partial \hat{y}_{3}} \times \frac{\partial \hat{y}_{3}}{\partial h_{3}} \times \frac{\partial h_{3}}{\partial U}+\frac{\partial L_{3}}{\partial \hat{y}_{3}} \times \frac{\partial \hat{y}_{3}}{\partial h_{3}} \times \frac{\partial h_{3}}{\partial h_{2}} \times \frac{\partial h_{2}}{\partial U}+\frac{\partial L_{3}}{\partial \hat{y}_{3}} \times \frac{\partial \hat{y}_{3}}{\partial h_{3}} \times\frac{\partial h_{3}}{\partial h_{2}} \times \frac{\partial h_{2}}{\partial h_{1}} \times \frac{\partial h_{1}}{\partial U} ∂U∂L3=∂y^3∂L3×∂h3∂y^3×∂U∂h3+∂y^3∂L3×∂h3∂y^3×∂h2∂h3×∂U∂h2+∂y^3∂L3×∂h3∂y^3×∂h2∂h3×∂h1∂h2×∂U∂h1
其实这个时候我们就可以看出,W和U两个参数的需要追溯之前的历史数据,参数V只需关注目前
所以,我们可以根据t3时刻的偏导,来计算任意时刻对U,V,W的偏导
对于V的偏导
对于V的偏导,我们直接将3替换成t即可:
∂Lt∂V=∂Lty^t×∂y^t∂V\frac{\partial L_t}{\partial V} = \frac{\partial L_t}{\hat{y}_{t}} \times \frac{\partial \hat{y}_{t}}{\partial V} ∂V∂Lt=y^t∂Lt×∂V∂y^t
对于W的偏导
对于W的偏导,在t=3t=3t=3的时刻有三项,那么对应的在T时刻就有T项
∂Lt∂W=∑k=1t∂Lt∂yt^×∂yt^∂ht×∂ht∂hk×∂hkW \frac{\partial L_{t}}{\partial W}= \sum_{k=1}^{t} \frac{\partial L_t}{\partial \hat{y_t} } \times \frac{\partial \hat{y_t} }{\partial h_t} \times \frac{\partial h_t}{\partial h_k} \times \frac{\partial h_k}{W} ∂W∂Lt=k=1∑t∂yt^∂Lt×∂ht∂yt^×∂hk∂ht×W∂hk
其中的∂ht∂hk\frac{\partial h_t}{\partial h_k}∂hk∂ht,我们可以进行展开:
例如在k=1k=1k=1时,∂h3∂h1=∂h3∂h2×∂h2∂h1\frac{\partial h_3}{\partial h_1} = \frac{\partial h_3}{\partial h_2} \times \frac{\partial h_2}{\partial h_1}∂h1∂h3=∂h2∂h3×∂h1∂h2
所以我们推导得到以下式子:
∂ht∂hk=∂ht∂hk×∂ht−1∂ht−2×...×∂ht−k+1∂hk \frac{\partial h_t}{\partial h_k} = \frac{\partial h_t}{\partial h_k} \times \frac{\partial h_{t-1}}{\partial h_{t-2}} \times ... \times \frac{\partial h_{t-k+1}}{\partial h_{k}} ∂hk∂ht=∂hk∂ht×∂ht−2∂ht−1×...×∂hk∂ht−k+1
也就是等于:
∂ht∂hk=∏i=k+1t∂hi∂hi−1 \frac{\partial h_t}{\partial h_k} = \prod_{i = k+1}^{t} \frac{\partial h_i}{\partial h_{i-1}} ∂hk∂ht=i=k+1∏t∂hi−1∂hi
所以,
∂Lt∂W=∑k=1t∂Lt∂yt^×∂yt^∂ht×(∏i=k+1t∂hi∂hi−1)×∂hkW \frac{\partial L_{t}}{\partial W}= \sum_{k=1}^{t} \frac{\partial L_t}{\partial \hat{y_t} } \times \frac{\partial \hat{y_t} }{\partial h_t} \times (\prod_{i = k+1}^{t} \frac{\partial h_i}{\partial h_{i-1}} ) \times \frac{\partial h_k}{W} ∂W∂Lt=k=1∑t∂yt^∂Lt×∂ht∂yt^×(i=k+1∏t∂hi−1∂hi)×W∂hk
对于U的偏导
同样的,我们也可以得到对于U的偏导
∂Lt∂U=∑k=1t∂Lt∂yt^×∂yt^∂ht×(∏i=k+1t∂hi∂hi−1)×∂hkU \frac{\partial L_{t}}{\partial U}= \sum_{k=1}^{t} \frac{\partial L_t}{\partial \hat{y_t} } \times \frac{\partial \hat{y_t} }{\partial h_t} \times (\prod_{i = k+1}^{t} \frac{\partial h_i}{\partial h_{i-1}} ) \times \frac{\partial h_k}{U} ∂U∂Lt=k=1∑t∂yt^∂Lt×∂ht∂yt^×(i=k+1∏t∂hi−1∂hi)×U∂hk
为什么U也是这样的链式求导?
ht=f(UXt+Wht−1)h_t = f(UX_t + Wh_{t-1})ht=f(UXt+Wht−1)
U也是通过链式法则求导的,因为隐藏状态hth_tht是由UUU、XtX_tXt和ht−1h_{t-1}ht−1共同决定的。因此,当我们计算损失函数关于U的偏导数时,需要考虑hth_tht对UUU的影响,而hth_tht又依赖于ht−1h_{t-1}ht−1,因此需要使用链式法则进行求导。
当前我们得到了是t时刻的导数,现在我们需要推广到整个网络中的损失值对U,V,W的偏导
总的损失值
因为和的导数等于导数,所以我们可以直接将L=∑i=1TLtL = \sum_{i=1}^{T} L_tL=∑i=1TLt前面的求和符号提出来
所以有,
∂L∂W=∑i=1T∂Lt∂W \frac{\partial L}{\partial W}= \sum_{i=1}^{T} \frac{\partial L_t}{\partial W} ∂W∂L=i=1∑T∂W∂Lt
现在我们只需要将前面求得的t时刻的带入即可,
∂L∂W=∑i=1T∑k=1t∂Lt∂yt^×∂yt^∂ht×(∏i=k+1t∂hi∂hi−1)×∂hkW \frac{\partial L}{\partial W}= \sum_{i=1}^{T}\sum_{k=1}^{t} \frac{\partial L_t}{\partial \hat{y_t} } \times \frac{\partial \hat{y_t} }{\partial h_t} \times (\prod_{i = k+1}^{t} \frac{\partial h_i}{\partial h_{i-1}} ) \times \frac{\partial h_k}{W} ∂W∂L=i=1∑Tk=1∑t∂yt^∂Lt×∂ht∂yt^×(i=k+1∏t∂hi−1∂hi)×W∂hk
同样的,对于U,我们得到:
∂L∂U=∑i=1T∑k=1t∂Lt∂yt^×∂yt^∂ht×(∏i=k+1t∂hi∂hi−1)×∂hkU \frac{\partial L}{\partial U}= \sum_{i=1}^{T}\sum_{k=1}^{t} \frac{\partial L_t}{\partial \hat{y_t} } \times \frac{\partial \hat{y_t} }{\partial h_t} \times (\prod_{i = k+1}^{t} \frac{\partial h_i}{\partial h_{i-1}} ) \times \frac{\partial h_k}{U} ∂U∂L=i=1∑Tk=1∑t∂yt^∂Lt×∂ht∂yt^×(i=k+1∏t∂hi−1∂hi)×U∂hk
对于V,我们得到:
∂L∂V=∑i=1T∂Lty^t×∂y^t∂V \frac{\partial L}{\partial V}= \sum_{i=1}^{T}\frac{\partial L_t}{\hat{y}_{t}} \times \frac{\partial \hat{y}_{t}}{\partial V} ∂V∂L=i=1∑Ty^t∂Lt×∂V∂y^t
梯度爆炸和梯度消失问题
在W和U中,存在一个连乘 ∏i=k+1t∂hi∂hi−1\prod_{i = k+1}^{t} \frac{\partial h_i}{\partial h_{i-1}}∏i=k+1t∂hi−1∂hi;也就是说,会出现指数级别的问题;
如果∂hi∂hi−1>1\frac{\partial h_i}{\partial h_{i-1}} > 1∂hi−1∂hi>1的话,那么连乘的结果可能会快速增长,导致梯度爆炸。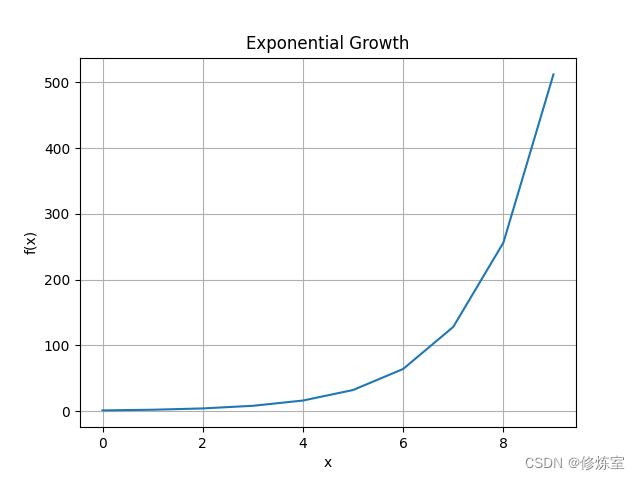
如果∂hi∂hi−1<1\frac{\partial h_i}{\partial h_{i-1}} < 1∂hi−1∂hi<1的话,连乘的结果会迅速衰减到零,导致梯度消失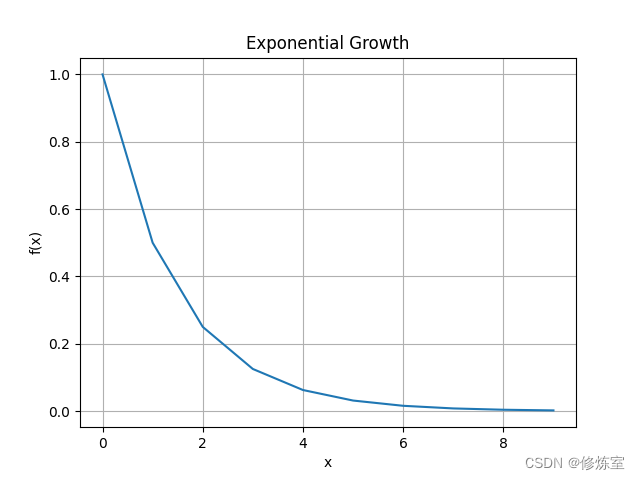
我们来求解一下关于∂hi∂hi−1\frac{\partial h_i}{\partial h_{i-1}}∂hi−1∂hi数学上的表示:
因为ht=f(UXt+Wht−1)h_t = f(UX_t + Wh_{t-1})ht=f(UXt+Wht−1),所以我们可以得到
∂hi∂hi−1=f′×W \frac{\partial h_i}{\partial h_{i-1}} = f'\times W ∂hi−1∂hi=f′×W
因为f′∈[0,0.25]f'∈[0,0.25]f′∈[0,0.25](假设为Sigmoid函数),所以说
- 如果 W<4W < 4W<4,那么连乘很多次后,导致梯度消失
- 如果 W>4W > 4W>4,那么连乘很多次后,导致梯度爆炸
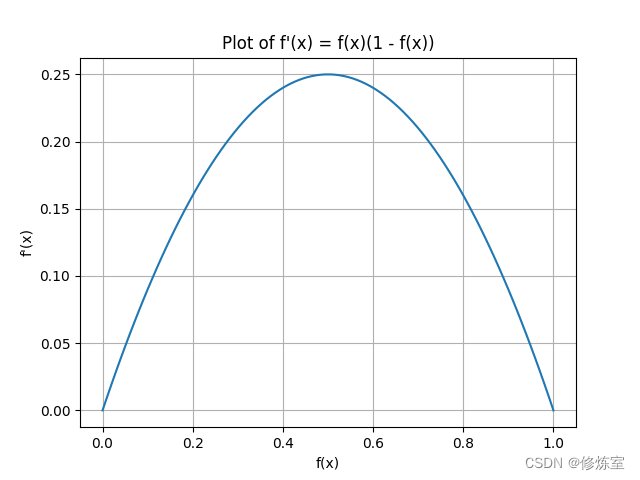
为什么 f′∈[0,0.25]f' \in [0, 0.25]f′∈[0,0.25]?
fff 是Sigmoid函数,其导数 f′f'f′ 的取值范围在0到0.25之间。
Sigmoid函数的导数表达式为 f′(x)=f(x)(1−f(x))f'(x) = f(x)(1-f(x))f′(x)=f(x)(1−f(x)),其中 f(x)f(x)f(x) 的取值范围在0到1之间。因此,f′(x)f'(x)f′(x) 的最大值为 0.250.250.25,在 x=0.5x = 0.5x=0.5 时取得。
如图所示
解决梯度消失和梯度爆炸的方法
为了缓解梯度消失和梯度爆炸问题,可以采用以下几种常见的方法:
-
梯度裁剪(Gradient Clipping):
- 将梯度的绝对值限制在某个阈值范围内,防止梯度爆炸。
- 例如,当梯度超过某个阈值时,将其裁剪到这个阈值。
-
正则化方法:
- 使用L2正则化(权重衰减)防止过度活跃的神经元。
- 增加权重更新时的惩罚项,控制权重值不至于过大。
-
批归一化(Batch Normalization):
- 对每个时间步的隐藏状态进行归一化,稳定训练过程。
- 通过归一化,控制每个时间步的输出范围,防止梯度过大或过小。
-
调整激活函数:
- 选择适当的激活函数(如ReLU、Leaky ReLU等),防止梯度消失和爆炸。
- 例如,Leaky ReLU 在负区间也有非零导数,避免了完全的梯度消失问题。
为什么很小的梯度无法更新权重并导致无法捕捉长期依赖关系?
当梯度非常小时,反向传播的权重更新公式:
ΔW=−η⋅∂L∂W \Delta W = -\eta \cdot \frac{\partial L}{\partial W} ΔW=−η⋅∂W∂L
梯度项 ∂L∂W\frac{\partial \mathcal{L}}{\partial W}∂W∂L 会非常小。这里,η\etaη 是学习率。当梯度接近零时,权重更新 ΔW\Delta WΔW 也会接近零。这意味着神经网络的权重几乎不会发生变化,导致模型无法从训练数据中学习到有用的信息,从而无法有效捕捉长期依赖关系。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 70
70 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)