强化学习(一)模型基础
上面的大脑代表我们的算法执行个体,我们可以操作个体来做决策,即选择一个合适的动作(Action)AtAt。下面的地球代表我们要研究的环境,它有自己的状态模型,我们选择了动作AtAt后,环境的状态(State)会变,我们会发现环境状态已经变为St+1St+1,同时我们得到了我们采取动作AtAt的延时奖励(Reward)Rt+1Rt+1。然后个体可以继续选择下一个合适的动作,然后环境的状态又会变,又有
强化学习(一)模型基础
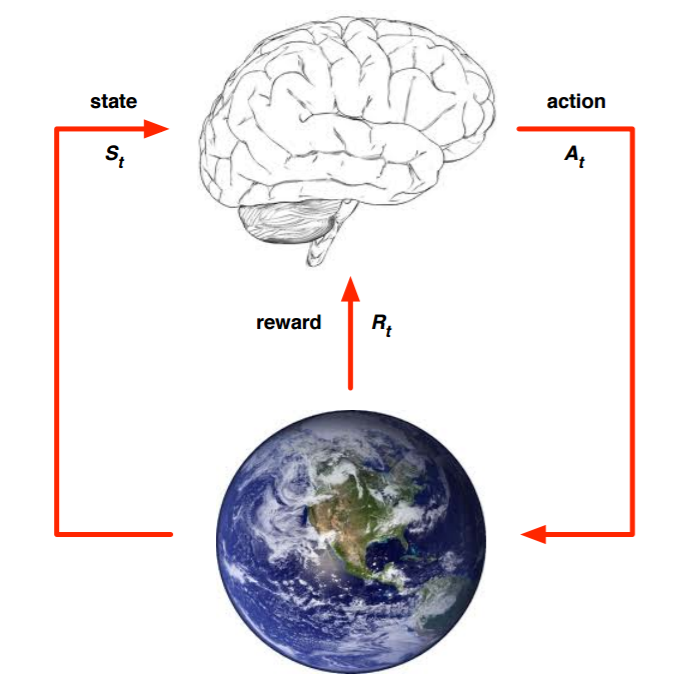
上面的大脑代表我们的算法执行个体,我们可以操作个体来做决策,即选择一个合适的动作(Action)AtAt。下面的地球代表我们要研究的环境,它有自己的状态模型,我们选择了动作AtAt后,环境的状态(State)会变,我们会发现环境状态已经变为St+1St+1,同时我们得到了我们采取动作AtAt的延时奖励(Reward)Rt+1Rt+1。然后个体可以继续选择下一个合适的动作,然后环境的状态又会变,又有新的奖励值。。。这就是强化学习的思路。
那么我们可以整理下这个思路里面出现的强化学习要素。
第一个是环境的状态S, t时刻环境的状态StSt是它的环境状态集中某一个状态。
第二个是个体的动作A, t时刻个体采取的动作AtAt是它的动作集中某一个动作。
第三个是环境的奖励R,t时刻个体在状态StSt采取的动作AtAt对应的奖励Rt+1Rt+1会在t+1时刻得到。
下面是稍复杂一些的模型要素。
第四个是个体的策略(policy)ππ,它代表个体采取动作的依据,即个体会依据策略ππ来选择动作。最常见的策略表达方式是一个条件概率分布π(a|s)π(a|s), 即在状态ss时采取动作aa的概率。即π(a|s)=P(At=a|St=s)π(a|s)=P(At=a|St=s).此时概率大的动作被个体选择的概率较高。
第五个是个体在策略ππ和状态ss时,采取行动后的价值(value),一般用vπ(s)vπ(s)表示。这个价值一般是一个期望函数。虽然当前动作会给一个延时奖励Rt+1Rt+1,但是光看这个延时奖励是不行的,因为当前的延时奖励高,不代表到了t+1,t+2,…时刻的后续奖励也高。比如下象棋,我们可以某个动作可以吃掉对方的车,这个延时奖励是很高,但是接着后面我们输棋了。此时吃车的动作奖励值高但是价值并不高。因此我们的价值要综合考虑当前的延时奖励和后续的延时奖励。价值函数vπ(s)vπ(s)一般可以表示为下式,不同的算法会有对应的一些价值函数变种,但思路相同。:
vπ(s)=Eπ(Rt+1+γRt+2+γ2Rt+3+…|St=s)vπ(s)=Eπ(Rt+1+γRt+2+γ2Rt+3+…|St=s)
其中γγ是第六个模型要素,即奖励衰减因子,在[0,1]之间。如果为0,则是贪婪法,即价值只由当前延时奖励决定,如果是1,则所有的后续状态奖励和当前奖励一视同仁。大多数时候,我们会取一个0到1之间的数字,即当前延时奖励的权重比后续奖励的权重大。
第七个是环境的状态转化模型,可以理解为一个概率状态机,它可以表示为一个概率模型,即在状态ss下采取动作aa,转到下一个状态s′s′的概率,表示为Pass′Pss′a。
第八个是探索率ϵϵ,这个比率主要用在强化学习训练迭代过程中,由于我们一般会选择使当前轮迭代价值最大的动作,但是这会导致一些较好的但我们没有执行过的动作被错过。因此我们在训练选择最优动作时,会有一定的概率ϵϵ不选择使当前轮迭代价值最大的动作,而选择其他的动作。
以上8个就是强化学习模型的基本要素了。当然,在不同的强化学习模型中,会考虑一些其他的模型要素,或者不考虑上述要素的某几个,但是这8个是大多数强化学习模型的基本要素。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践
L4级别:大模型微调与私有化部署
一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)