OrangePi AIpro使用yolov8n在安防领域的深思和实战
香橙派Aipro提供的案例完美的执行成功了,学习起来很适合企业开发者用户。往外继续延伸,如果单纯的使用香橙派Aipro做模型的测试也是很可以的,可惜了我这边内存不太够,没办法做太多太消耗内存的东西。需要自己扩展下存储空间就很完美了,运行大模型肯定也不在话下。跑这个yolov8模型时,从拉下来代码,到搭建环境,再到运行结果,都比较顺利。延迟感觉还是稍慢满打满算一张图需要800ms。不知道跑上多路流然
一、前言
公司最近有个项目是安防领域的,主要用在边缘结点,虽然已做成形,但是还是存在一些缺陷,例如:算力问题,开发板的成熟问题,已经各种技术的解决方案落地问题。目前我们集成了很多功能,主要是拉取rtsp等流媒体协议的实时视频流,例如:可以拉取海康相机的rtsp,然后针对这个相机做AI识别以及分析。
Orange Pi AI Pro 开发板是香橙派联合华为精心打造的高性能 AI 开发板,其搭载了昇腾 AI 处理器,可提供 8TOPS INT8 的计算能力,内存提供了 8GB 和 16GB 两种版本。可以实现图像、视频等多种数据分析与推理计算,可广泛用于教育、机器人、无人机等场景。
今天香橙派AIpro这块板子终于到了,先来探索下在安防领域的应用。
二、搭建开发环境
梳理这篇文章之前整理了很多篇,这里直接写总结吧,太冗余的废话就不多说了。总结下来,香橙派AIpro的开发环境并没有太复杂的地方,主要是下载好交叉编译工具,配置好环境变量就OK了。
官网提供了多个下载的资源,在官方工具这个地址中可以下载到交叉编译工具
还提供了一些额外的辅助工具,远程工具,图片查看工具等:
下载好,配置环境变量:
export PATH=$PATH:/你的位置/toolchain/bin/
如果你是windows就加到自己的PATH环境变量中即可,这个就不需要多说了吧。
如何验证安装成功了呢:
1.使用which命令
which aarch64-target-linux-gnu-g++
2.如果能查到说明成功了
/位置/toolchain/bin//aarch64-target-linux-gnu-g++
通过putty的串口连接:
登录成功:
三、识别案例
咱们可以参考samples:
(base) HwHiAiUser@orangepiaipro:~$
(base) HwHiAiUser@orangepiaipro:~$ cd samples/
(base) HwHiAiUser@orangepiaipro:~/samples$ ls
01-SSD 02-CNNCTC 03-ResNet50 04-HDR 05-CycleGAN 06-Shufflenet 07-FCN 08-Pix2Pix start_notebook.sh
(base) HwHiAiUser@orangepiaipro:~/samples$
可以看到有个启动脚本:
(base) HwHiAiUser@orangepiaipro:~/samples$ cat start_notebook.sh
. /usr/local/Ascend/ascend-toolkit/set_env.sh
export PYTHONPATH=/usr/local/Ascend/thirdpart/aarch64/acllite:$PYTHONPATH
if [ $# -eq 1 ];then
jupyter lab --ip $1 --allow-root --no-browser
else
jupyter lab --ip 127.0.0.1 --allow-root --no-browser
fi
(base) HwHiAiUser@orangepiaipro:~/samples$
通过if [ $# -eq 1 ]可以知道,这个脚本可以接收一个IP参数: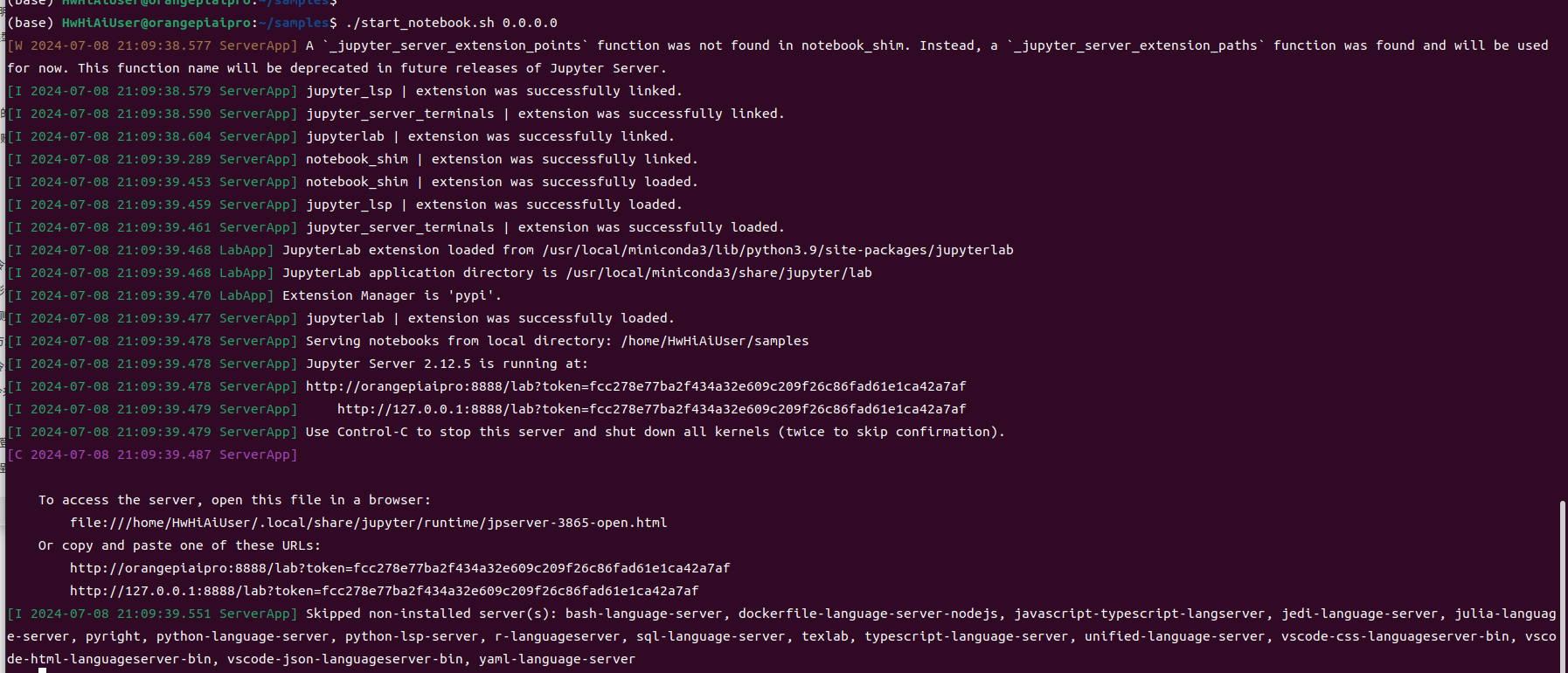
然后把这一串URL复制到浏览器地址栏把127.0.0.1改成自己的IP即可访问:
访问效果: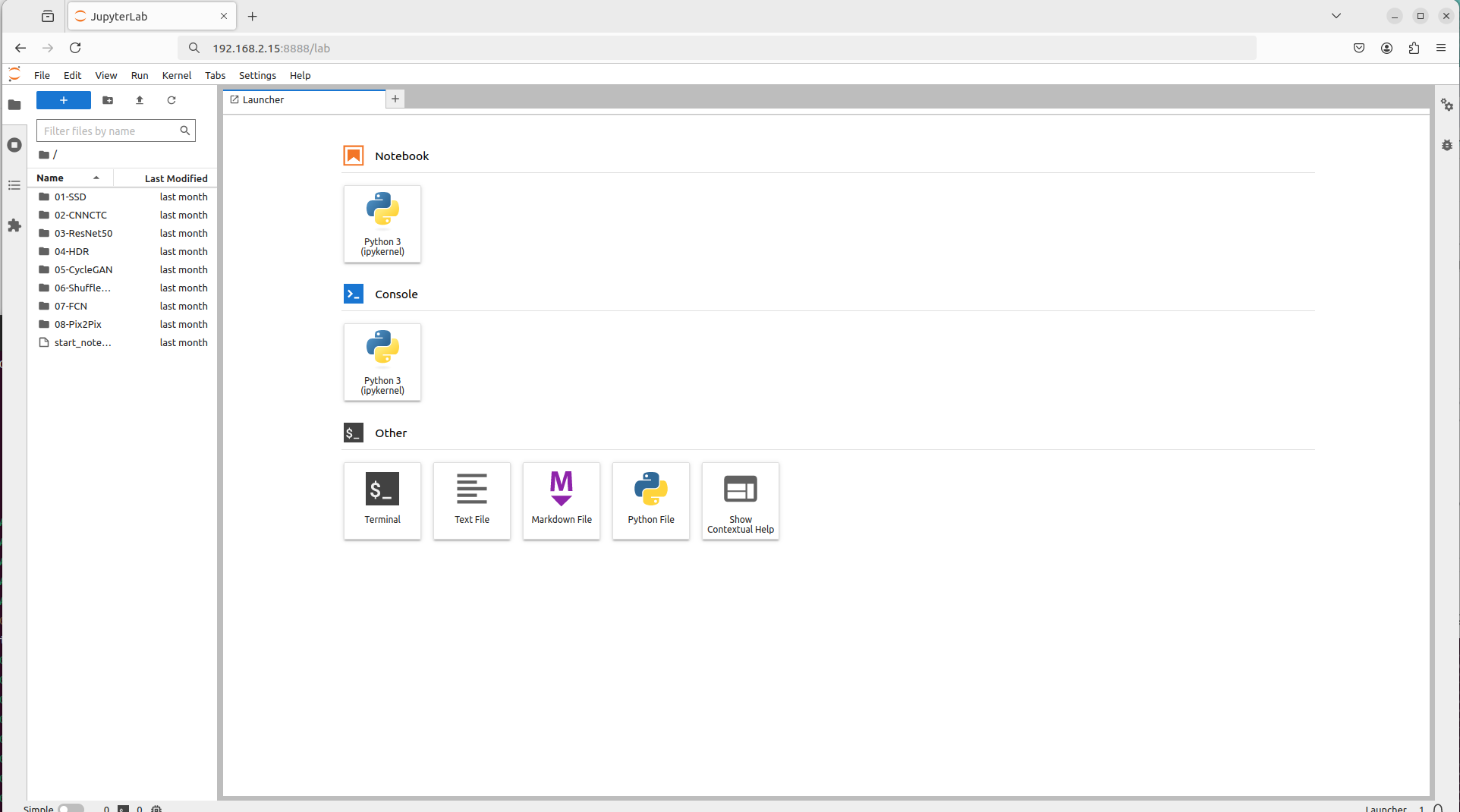
ShuffleNet v1 是由国产旷视科技团队在 2018 年提出的一种计算高效的CNN模型,其和 MobileNet、SqueezeNet 等一样主要是想应用在移动端。
ShuffleNet 的设计目标也是如何利用有限的计算资源来达到最好的模型精度,这需要很好地在速度和精度之间做平衡。目前移动端CNN模型主要设计思路主要是两个方面:模型结构设计和模型压缩。ShuffleNet 和MobileNet 一样属于前者,都是通过设计更高效和轻量化的网络结构来实现模型变小和变快,而不是对一个训练好的大模型做压缩或者迁移。
ShuffleNet 的核心是采用了两种操作:pointwise group convolution 和 channel shuffle,这在保持精度的同时大大降低了模型的计算量。ShuffleNet 的核心设计理念是对不同的 channels 进行 shuffle 来解决 group convolution 带来的弊端。
对这个比较感兴趣,看到有这个案例就研究下跑个试试:
进入到相应的目06-Shufflenet目录:
打开main_shufflenet.ipynb文件,可以打开在线编辑。
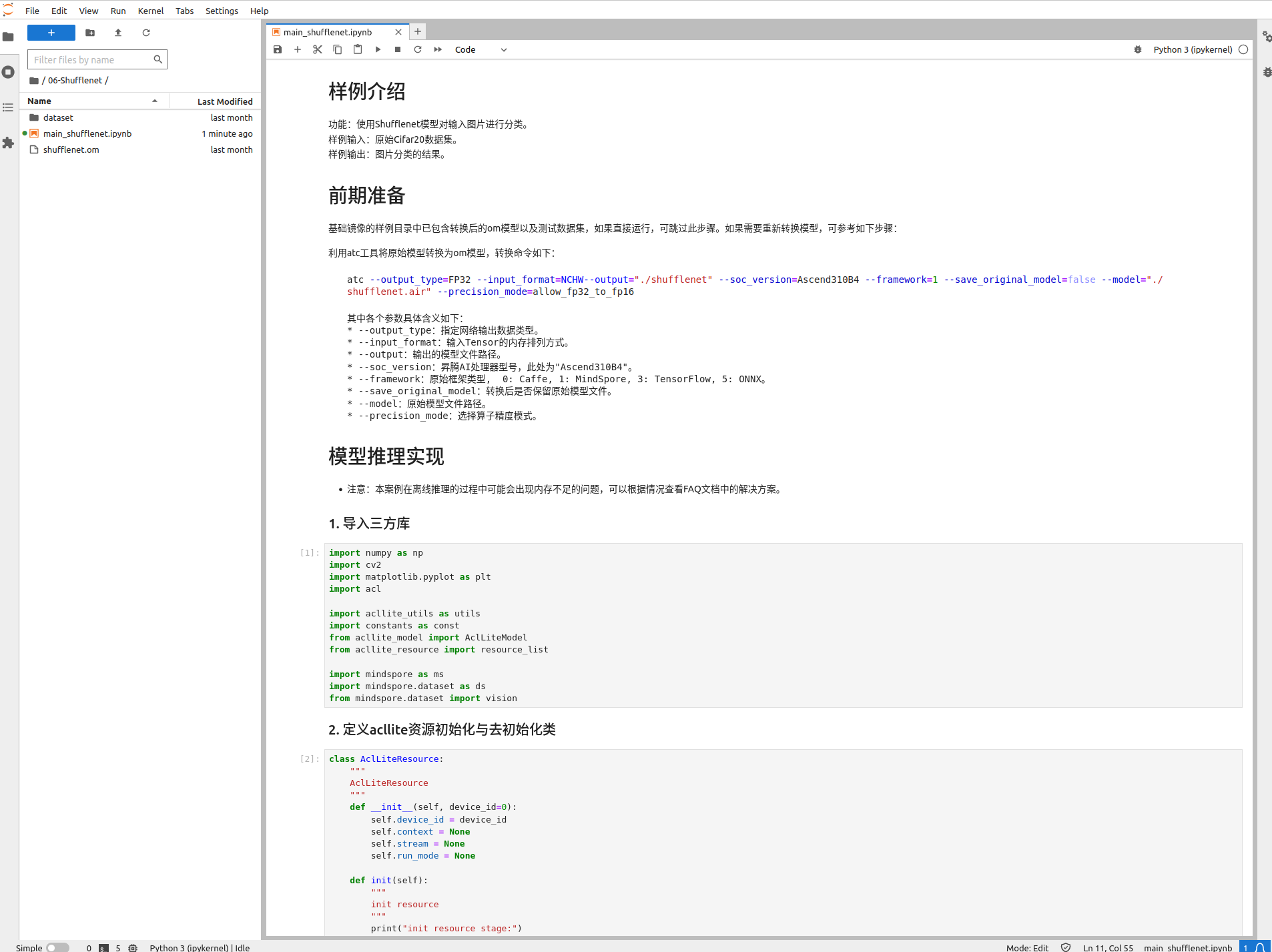
跑自己的模型的话,可以使用香橙派提供的模型转换工具把模型转换一下:
atc --output_type=FP32 --input_format=NCHW--output="./shufflenet" --soc_version=Ascend310B4 --framework=1 --save_original_model=false --model="./shufflenet.air" --precision_mode=allow_fp32_to_fp16
参数含义:
* --output_type:指定网络输出数据类型。
* --input_format:输入Tensor的内存排列方式。
* --output:输出的模型文件路径。
* --soc_version:昇腾AI处理器型号,此处为"Ascend310B4"。
* --framework:原始框架类型, 0: Caffe, 1: MindSpore, 3: TensorFlow, 5: ONNX。
* --save_original_model:转换后是否保留原始模型文件。
* --model:原始模型文件路径。
* --precision_mode:选择算子精度模式。
官方的案例中使用python写了4部分的代码:
运行后就可以得到该模型跑后的结果: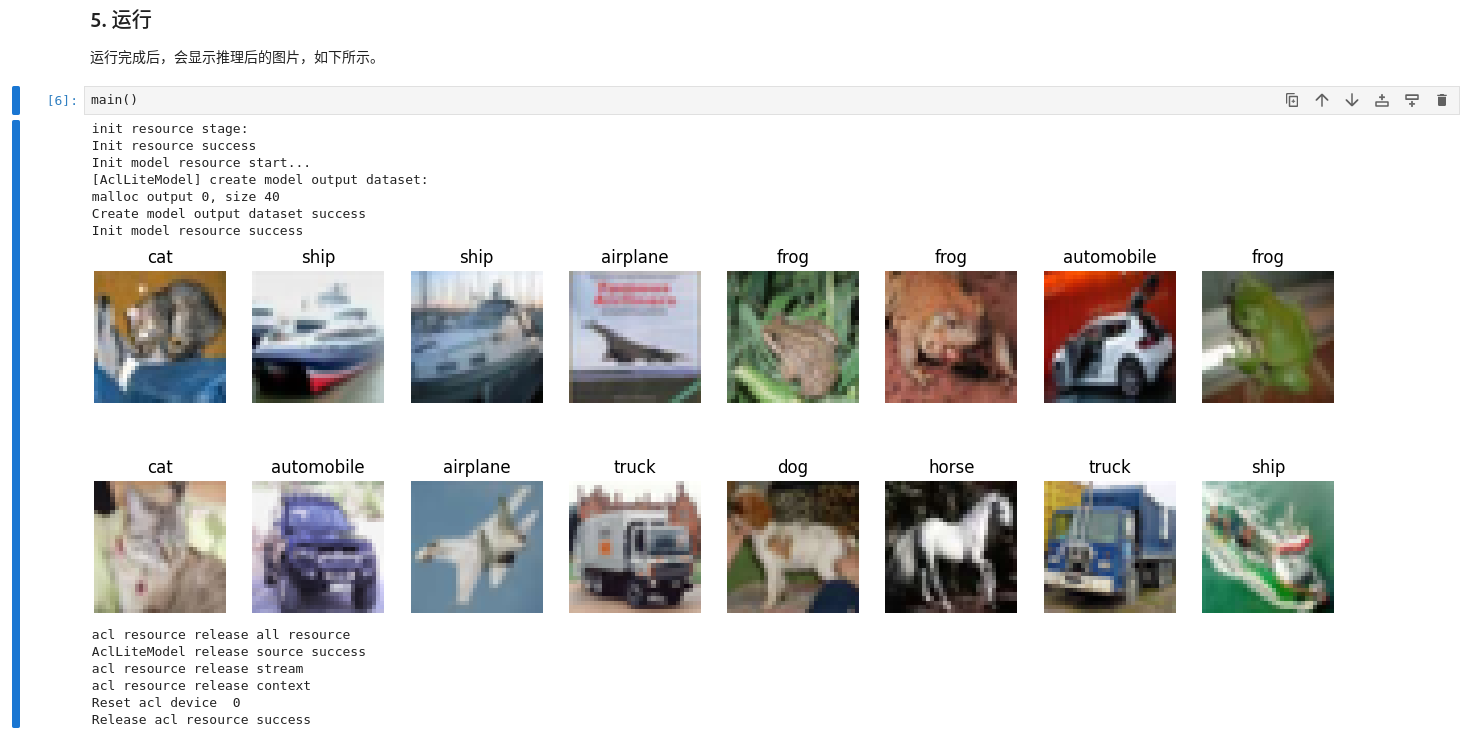
从提供的日志中可以看到,整个流程涉及初始化、资源释放和模型加载阶段的日志记录。以下是各个阶段的分析:
初始化资源阶段 (init resource stage)
- Init resource success: 表示初始化资源阶段成功完成。
- Init model resource start…: 开始初始化模型资源。
初始化模型资源阶段 (Init model resource start…)
- [AclLiteModel] create model output dataset:
- malloc output 0, size 40: 为模型输出分配了大小为40的内存。
- Create model output dataset success: 成功创建了模型输出数据集。
- Init model resource success: 模型资源初始化成功。
释放资源阶段 (acl resource release all resource)
- AclLiteModel release source success: 释放模型资源成功。
- acl resource release stream: 释放ACL流资源。
- acl resource release context: 释放ACL上下文资源。
- Reset acl device 0: 重置ACL设备0。
- Release acl resource success: 成功释放ACL资源。
该算法逻辑梳理:
- 初始化资源:
- 成功完成基础资源的初始化。
- 初始化模型资源:
- 成功开始并完成模型资源的初始化。
- 为模型输出分配内存并成功创建输出数据集。
- 释放资源:
- 成功释放了所有模型相关资源、ACL流资源和ACL上下文资源。
- 重置了设备并确认所有ACL资源释放成功。
这些日志信息表明整个流程从初始化到释放资源均顺利完成,没有出现错误或警告。
四、安防领域使用yolov8
yolo Github地址:https://github.com/ultralytics/ultralytics
可以直接git clone
git clone https://github.com/ultralytics/ultralytics.git
也可以通过其他手段下载下来zip包,然后到开发板中解压出来。
可以通过Jupyte打开:
打开tutorial.ipynb运行。
1、现在安装:
%pip install ultralytics
import ultralytics
ultralytics.checks()
如果安装比较慢,可以先加速安装,加速pip:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
加速安装之后就很快了:
然后不出意外的话,就可以直接跑一下yolo predict model=yolov8n.pt source='https://ultralytics.com/images/zidane.jpg’ 看看: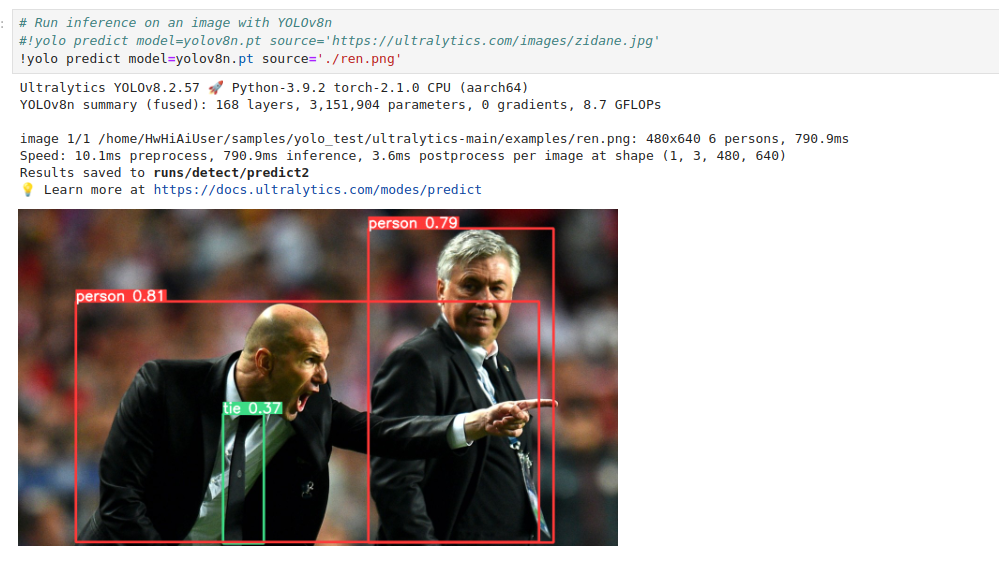
结果:
image 1/1 /home/HwHiAiUser/samples/yolo_test/ultralytics-main/examples/ren.png: 480x640 6 persons, 790.9ms
Speed: 10.1ms preprocess, 790.9ms inference, 3.6ms postprocess per image at shape (1, 3, 480, 640)
Results saved to runs/detect/predict2
我先解释下:
- Image Information:
- image 1/1: 这是处理的第一张图片(也是唯一一张图片)。
- /home/HwHiAiUser/samples/yolo_test/ultralytics-main/examples/ren.png: 图片的文件路径。
- 480x640: 图片的分辨率(高度480像素,宽度640像素)。
- 6 persons: 模型在图片中检测到6个人。
- Speed:
- 10.1ms preprocess: 图像预处理时间是10.1毫秒。
- 790.9ms inference: 模型推理时间是790.9毫秒。
- 3.6ms postprocess: 结果后处理时间是3.6毫秒。
- per image at shape (1, 3, 480, 640): 每张图片的处理时间,这里图片的形状是(1张图片,3个通道(RGB),高度480像素,宽度640像素)。
- Results Saved:
- Results saved to runs/detect/predict2: 检测结果保存到
runs/detect/predict2目录中。
这是检测的结果,yolov8n推理时间耗时790.9毫秒,预处理10.1毫秒,后处理3.6毫秒: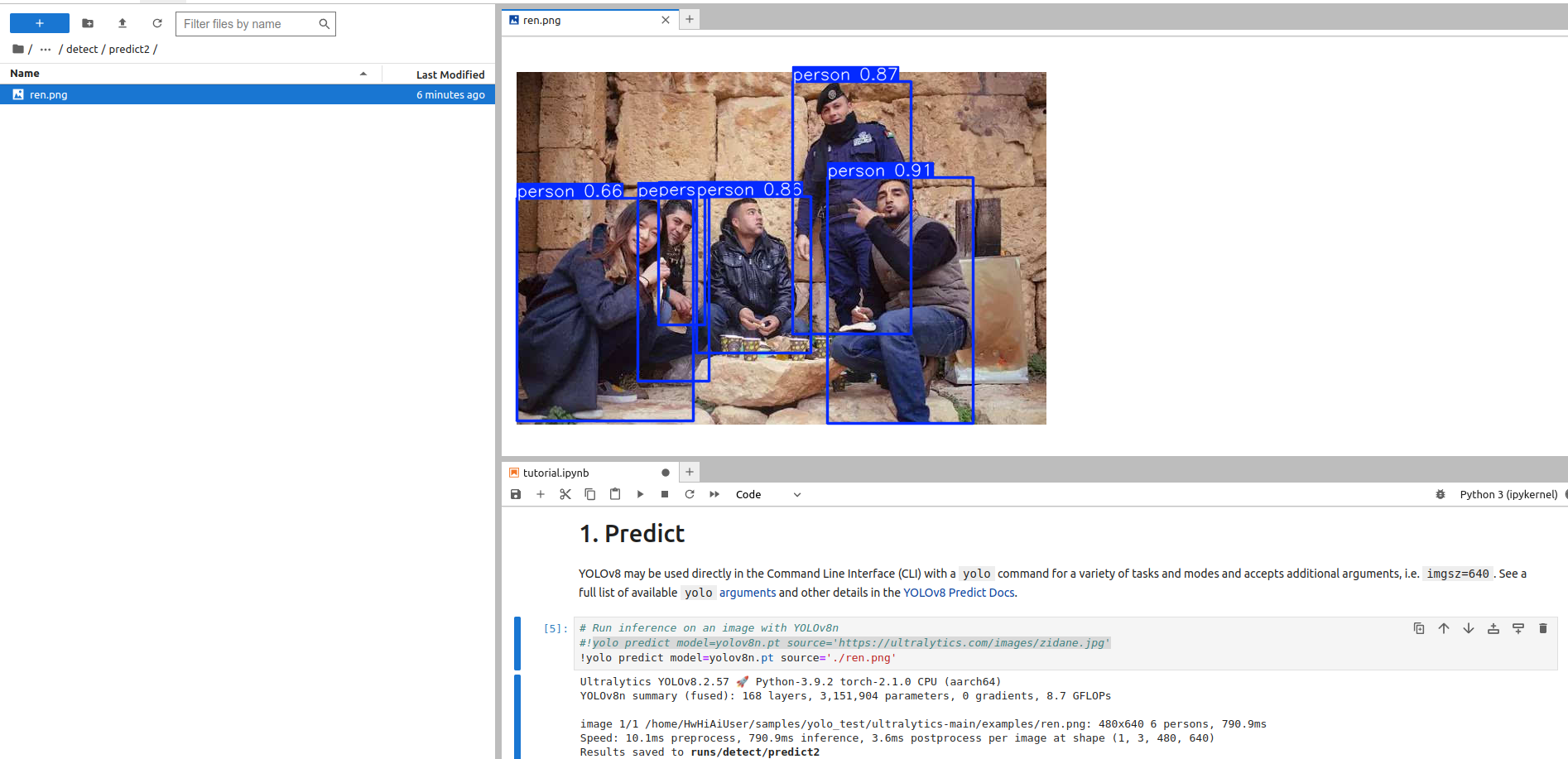
五、总结
香橙派Aipro提供的案例完美的执行成功了,学习起来很适合企业开发者用户。往外继续延伸,如果单纯的使用香橙派Aipro做模型的测试也是很可以的,可惜了我这边内存不太够,没办法做太多太消耗内存的东西。需要自己扩展下存储空间就很完美了,运行大模型肯定也不在话下。
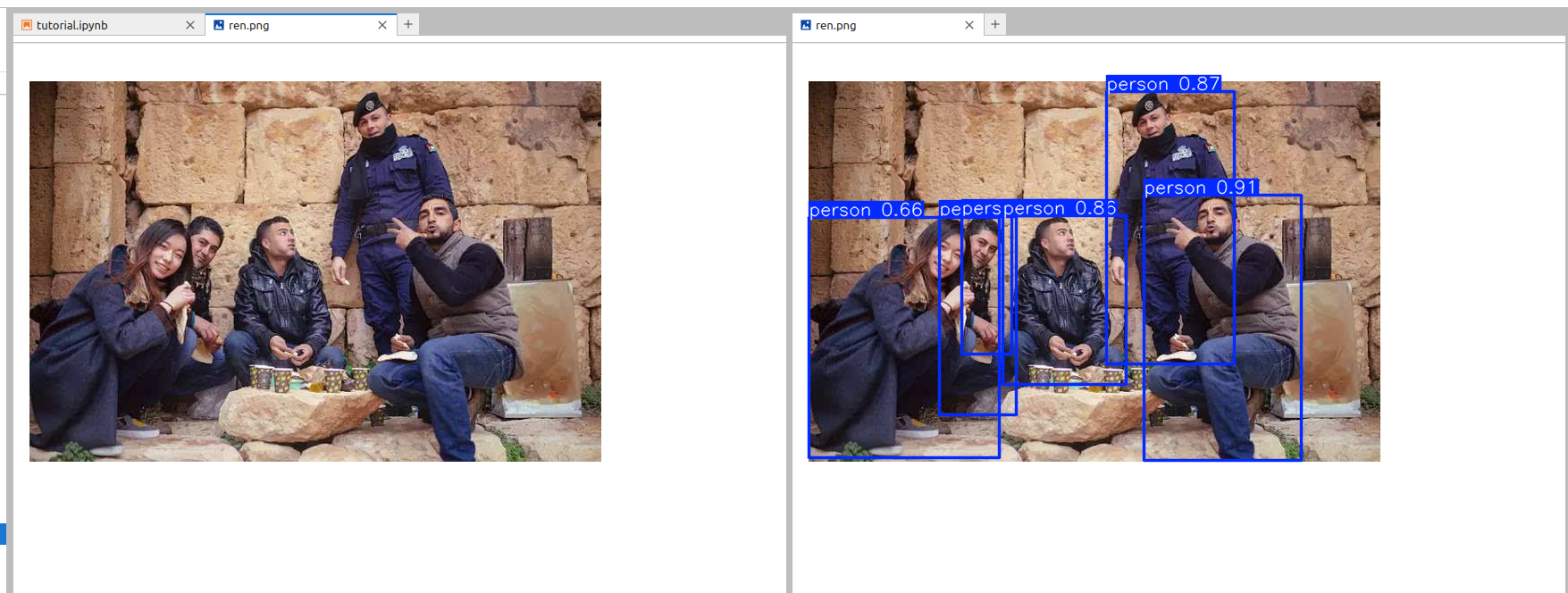
跑这个yolov8模型时,从拉下来代码,到搭建环境,再到运行结果,都比较顺利。延迟感觉还是稍慢满打满算一张图需要800ms。不知道跑上多路流然后实时检测的情况如何,还有待验证!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

{kind=link}
所有评论(0)