基于python的二手车销售数据分析系统
系列文章目录
项目介绍
随着社会经济的快速发展,人们的生活水平得到了显著提高,对汽车的需求量也越来越多。为此,二手车销售数据分析也变得越来越为重要。但是在大量的二手车信息中,人们在提取自己最想要的信息时变得不那么容易。本系统通过对网络爬虫的分析,研究人人车网站数据,尝试使用Python技术进行开发,将人人车网二手车信息尽可能的爬取出来,并对结果进行检测判断,最后可视化分析出来,为用户提供精确的查询结果。基于python的二手车销售数据分析系统旨在提高数据挖掘的效率,便于科学的管理和分析二手车数据。
本文先分析基于python的二手车销售数据分析系统的背景和意义;对常见的爬虫原理,获取策略,信息提取等技术进行分析;本系统使用python进行开发,MySQL数据库进行搭建,实现了二手车的数据爬取;对数据库的查询结果进行检测并可视化分析,对系统的前台界面进行管理,分析爬取的结果,并对二手车数据结果进行大屏显示;最后通过测试实现了数据爬取,存储过滤和数据可视化分析,以及系统管理等功能。
开发环境
编程语言:Python
数据库 :Mysql
系统架构:B/S
后端框架:Django
编译工具:Pycharm,Navicat
支持定做:java/php/python/android/小程序/vue/爬虫/c#/asp.net
系统实现
5.1数据采集的实现
启动项目,运行爬虫程序,首先通过指定的URL进行过滤,然后将待抓取的URL放入抓取队列中。接着读取URL,解析DNS,下载网页内容,将文本内容通过BeautifulSoup进行存储。
其中爬取到的数据如5.1所示。
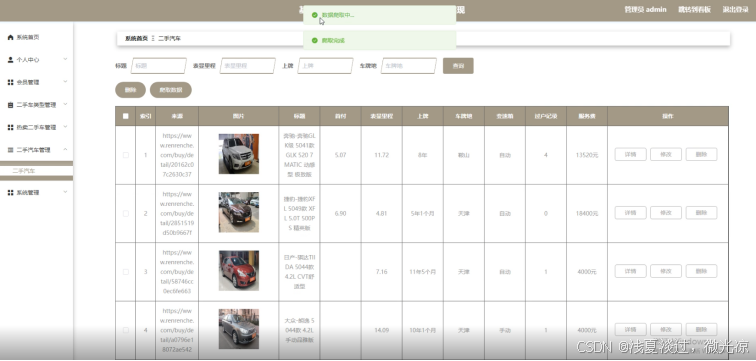
图5.1 采集的数据列表
分析HTML,获取对方文本,通过BeautifulSoup. find_all方法查找a链接下的信息,样式为post-item-title。于是得到代码:
soup.find_all("a", class_="post-item-title")
可以读取到所有a链接,并且样式名称为post-item-title的内容。该内容就是本系统需要的爬取内容,包括了二手车数据的标题、URL地址和内容。再通过for语句循环爬取到的对象结果,使用MySQL的cursor.execute方法进行数据保存,最后commit提交方法把数据插入到数据库。本爬虫用到的类库如下:
import requests
import json
from bs4 import BeautifulSoup
import re
import pymysql
5.3系统首页的实现
前台使用VUE技术进行数据查询,在首页中,先建立和服务器端连接请求,然后发送方法调用,接收返回值。首页主要包括了用户注册登录、所有的二手车数据信息、推荐二手车信息。其中首页的界面如5.4所示。
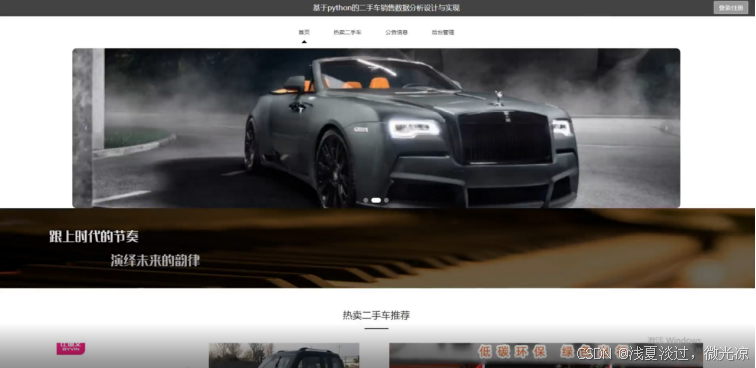
图5.4 系统首页界面
5.4二手车数据大屏显示
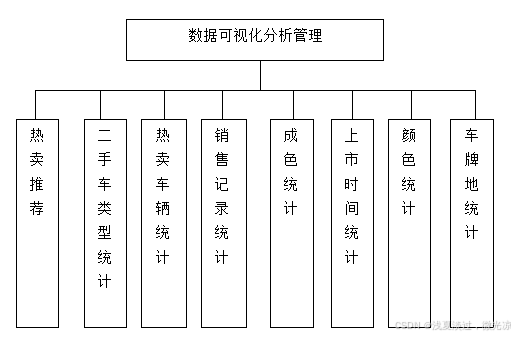
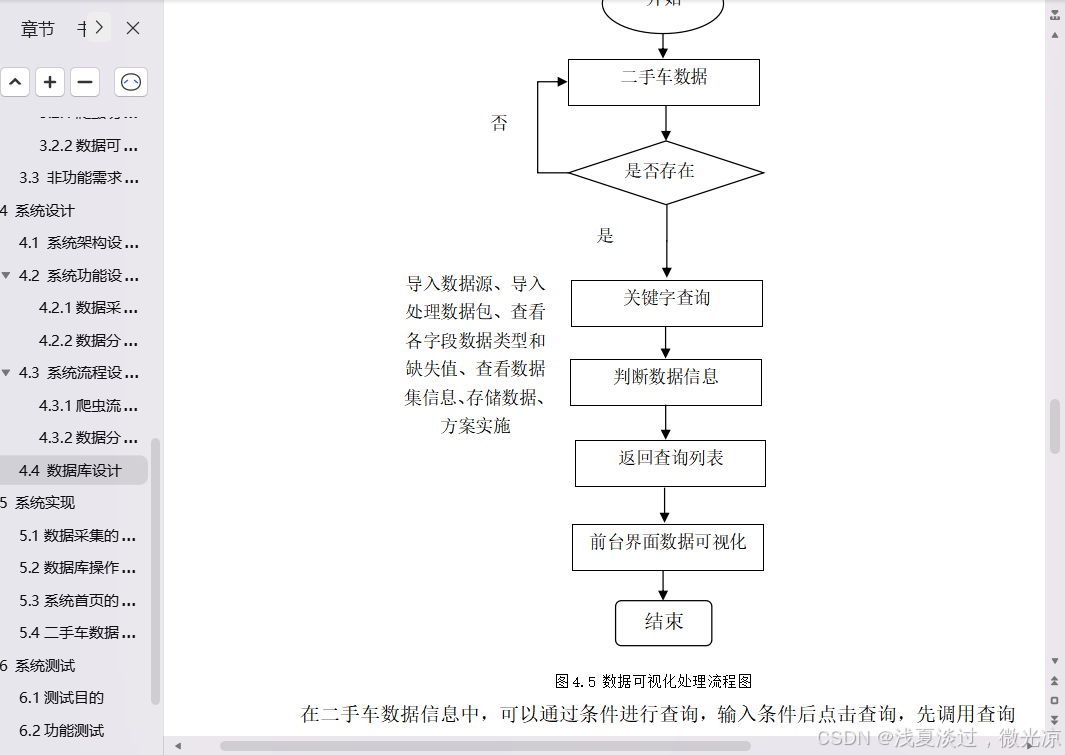
大屏板块信息包括了车牌地统计、二手车类型、热卖车辆统计、销售记录统计、成色统计、上市时间统计、颜色统计。最终显示的界面如5.5所示。
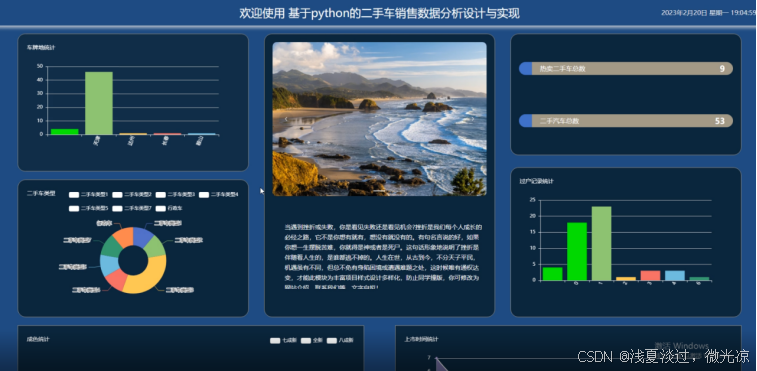
图5.5 二手车数据大屏查看
论文参考
源码获取
感谢大家的阅读,有不懂的问题可以评论区交流或私聊!喜欢文章可以点赞、收藏、关注、评论!
如需源码请私信

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)