【王木头·从感知机到神经网络】
根据身高体重判断胖瘦的感知机。1、根据已知样本训练出一条直线,用于对非训练样本进行分类,这条直线就是感知机模型。三维情况下感知机模型是一个平面。
目录
感知机
什么是感知机
公式、框图表示


直观举例
根据身高体重判断胖瘦的感知机。
1、根据已知样本训练出一条直线,用于对非训练样本进行分类,这条直线就是感知机模型。


三维情况下感知机模型是一个平面

感知机的缺陷
缺陷原因
不能处理异或问题,换句话说,感知机只能处理线性二分问题。
对于以下二分问题:

前三种情况都能用一条直线分类,第四种异或运算不能直线可分,单个感知机无法解决。
克服缺陷
如何解决异或问题呢?可以使用多个感知机进行叠加。


从线性变换角度理解感知机
将一组向量(样本)经模型的参数矩阵变换后变为另一组向量。
从感知机到神经网络
神经网络的组成
感知机模型

神经网络模型
对于非线性问题,单个感知机无法实现,从上面对感知机介绍可知,多个感知机的叠加可以解决非线性问题,所以神经网络模型可以有多个感知机叠加组成,从而解决非线性问题:(下图由6个感知机组成)

说明:
(1)每一个节点都和下一层的节点全部相连,叫做全连接网络。
(2)数据的传播是单向的,会朝着神经网络一直向前传播,叫做前馈神经网络
直观理解损失函数
本质:两个模型之间的差别。
神经网络训练的模型(机器的认知)与人心中的模型(人的认知)之间是有差别的,训练的目的是让这个差别减小,而神经网络的模型与人心中的模型是无法用同一种度量方式进行比较的,可以想象为在两个模型在两个空间,而这两个空间之间也有一个接口,这个接口是什么呢?即是让两个空间中的两个模型对同一批目标进行功能实现,通过某种方法得到两种实现之间的差距,进而调整机器空间中的模型。以下是三种通过这个接口比较两个模型的两种实现之间差别的三种方法。
最小二乘法
顾名思义:最小二乘即“最小”:min、“二乘”:平方。即
优点:(1)简洁易懂(2)全程可导
缺点:(1)计算麻烦,在复杂的神经网络中一般不用
最大似然估计
例子
举一个简单的例子,抛一枚质地均匀的硬币,正反面朝上的概率都是1/2,所以我们可以认为在现实世界抛硬币大概率就会有一半正面,一半反面。
那么抛一枚质地不均匀的硬币,抛了10次,7次正面,3次反面(记为事件 ),那么若要问抛掷这枚质地不均匀的硬币正面概率和反面概率分别为多少的可能性最大?
我们可能会毫不犹豫地回答,正面的概率是0.7,反面概率是0.3地可能性最大,即由这个结果可以估计正反面概率是7:3的可能性最大。
下面来定量计算不同正反面概率的情况下事件 发生的可能性:
先验概率0.1:0.9的概率为:
先验概率0.2:0.8的概率为:
先验概率0.3:0.7的概率为:
先验概率0.4:0.6的概率为:
先验概率0.5:0.5的概率为:
先验概率0.6:0.4的概率为:
先验概率0.7:0.3的概率为:
先验概率0.8:0.2的概率为:
先验概率0.9:0.1的概率为:
计算可得先验概率为0.7:0.3时事件A发生的概率最大。神经网络解决这个问题的时候正是为了寻找这个先验概率(W和b)。
真实世界已经发生,上面计算的值都是真实世界反推回来的,这样的值叫做“似然值”,先验概率0.7:0.3的“似然值”最大,所以“估计”先验概率为0.7:0.3,故而有“最大似然估计”。
“似然值”:在某个概率模型下事情发生的概率。
因此最大似然估计的目的是求最大似然值时的估计值,即似然值为:
把连乘变成连加,加log
目的是求这个似然值的极大值,但习惯于求最小值,所以在其前面加负号:
这就是需要最小化的损失函数:

交叉熵
“交叉熵”如何做损失函数?打包理解“信息量”、“比特”、“熵”、“KL散度”、“交叉熵”_哔哩哔哩_bilibili
本小节旨在通过交叉熵定量地来衡量两个模型的差距,在这里就是损失函数。
1、系统的熵
(1)定义:
在信息论中,熵(Entropy)是衡量随机变量不确定性的度量。对于离散随机变量 X 的熵定义为:
其中 是事件
发生的概率。熵越高,表明系统的不确定性(混乱程度)越大。
(2)推导:
熵的推导基于信息量的定义。单个事件的自信息量为 。熵则是所有可能事件的信息量的期望---系统的熵。
熵可以看作是信息空间中的一个点,反映了信息分布的广泛程度。若熵为零,说明系统完全确定,所有概率集中于一个事件上。
2、KL散度
(1)定义
KL 散度(Kullback-Leibler Divergence)用于衡量两个概率分布之间的差异。对于分布 P 和 Q 的 KL 散度定义为:
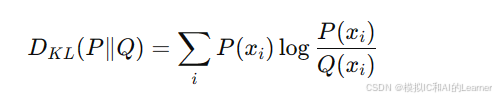
(2)推导
KL 散度可以看作是熵的扩展。它可以从系统的熵和交叉熵之间的关系导出。通过将系统的熵与交叉熵结合,可以得出 KL 散度的公式。
KL 散度是非对称的(上式是以P为基准),反映了从分布 Q 到分布 P 的信息损失。其值为零当且仅当 P 和 Q 完全相同,意味着两个分布在某种意义上是重合的。
3、交叉熵
(1)定义
交叉熵即是KL散度公式中的第一项。
交叉熵用于衡量一个概率分布(通常是预测分布)与真实分布之间的差异。对于真实分布 P 和预测分布 Q,交叉熵定义为:
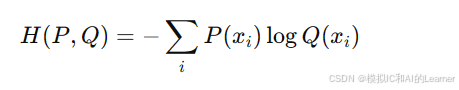
(2)推导
交叉熵可以看作是熵和 KL 散度的和:
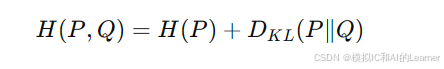
因此,最小化交叉熵等价于最小化 KL 散度。
交叉熵可以视为真实分布和预测分布之间的“距离”,即在多大程度上预测分布偏离真实分布。
4、损失函数
(1)定义
在机器学习中,损失函数用于评估模型预测与真实值之间的差距。对于分类任务,通常使用交叉熵作为损失函数。
所以损失函数为
上式将交叉熵公式中的求和符合打开变为两项。即为损失函数。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)