【强化学习】Sara算法
Sara算法在不知道环境模型(状态转移矩阵,奖励函数)下通过在线学习的方式(从而推导出最优策略。其实,他就相当于在无环境模型下的策略迭代算法。
一、 Sara算法中用到的其他方法
(一)蒙特卡洛方法
蒙特卡洛方法也被称为统计模拟方法,是一种基于概率统计的数值计算方法。其使用重复随机抽样,然后对数据求期望来估算目标值。
举例:
我们要求一个策略下的状态价值函数,那么我们通过该策略采样若干条序列,对这些序列上的状态价值函数求期望来估算真实的状态价值函数。一条序列是指从初始状态,按照指定策略下执行动作进行状态转换,直到到达结束状态。
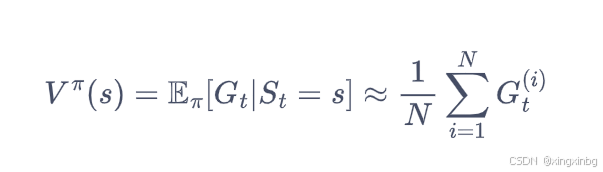
(二)时序差分法
蒙特卡洛法的优劣势:
优势:直接凭借采样到的数据进行推算,不需要直到环境(状态转移函数、奖励函数)
劣势:蒙特卡洛的数据估算是无偏的,他对任何一个序列一视同仁,这也会导致各个序列的数据值方差过大,不利于最终结果的估算。
时序差分法
利用后续一步的状态来更新当前状态的值,这是有偏的,方差较小。时序差分方法,每在当前状态下执行一个动作就会得到一个新的状态,利用新状态的价值函数来估计前面状态的价值函数。
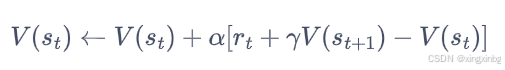
二、 Sara算法
算法目标:在不知道状态转移函数和奖励函数下,通过真实的数据序列来推导最优策略。
思路:在每一步采样中,使用时序差分法估算当前状态和动作下的动作价值函数,然后进行策略提升即采取当前状态下动作价值最高的动作,从而继续产生数据。如何循环,便可以在只有数据下做到策略提升。同时为了探索更多的状态-动作对下的动作价值,我们在每一步的策略上加入了一个惩罚因子。至此,每一个策略为,在当前状态下以大概率执行动作价值最大的动作,小概率随机选一个动作用于探索。
![]()

总结:Sara算法在不知道环境模型(状态转移矩阵,奖励函数)下通过在线学习的方式(从而推导出最优策略。其实,他就相当于在无环境模型下的策略迭代算法
三、 Q-learning算法
Q-learning算法借鉴了价值迭代的思想,其每一次训练中的目标策略都与行为策略不同,所以策略调整的步长会更快。而Sara算法的目标策略与行为策略相同,所以步长会更慢。
Q-learning算法在估算价值函数时,基于当前策略得到新的状态后,使用的是下一状态最大动作价值函数来更新当前动作价值状态函数。
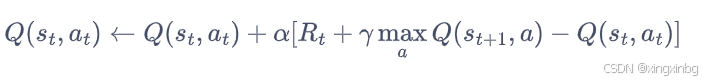
局限性
Sara和Q-learning算法通过遍历数据来计算Q值,这能够估算的前提条件是动作空间和状态空间是有限的,如果是无限的,那么无法遍历,所以就无法估算

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)