排序算法c++
排序算法给定 n 个正整数 a1,a2,…,an,请将它们从大到小排序,然后输出。输入格式第一行一个整数 n,表示数字个数。接下来一行包含 n个整数 a1,a2,…,an。输出格式一行 n个整数,表示排完序之后的结果。样例输入53 9 5 3 2样例输出9 5 3 3 2数据规模对于 100%的数据,保证 1 ≤ n ≤ 105,1≤ ai ≤ 100。
前言
排序算法
给定 n 个正整数 a1,a2,…,an,请将它们从大到小排序,然后输出。
输入格式
第一行一个整数 n,表示数字个数。
接下来一行包含 n个整数 a1,a2,…,an。
输出格式
一行 n个整数,表示排完序之后的结果。
样例输入
5
3 9 5 3 2
样例输出
9 5 3 3 2
数据规模
对于 100%的数据,保证 1 ≤ n ≤ 105,1≤ ai ≤ 100。
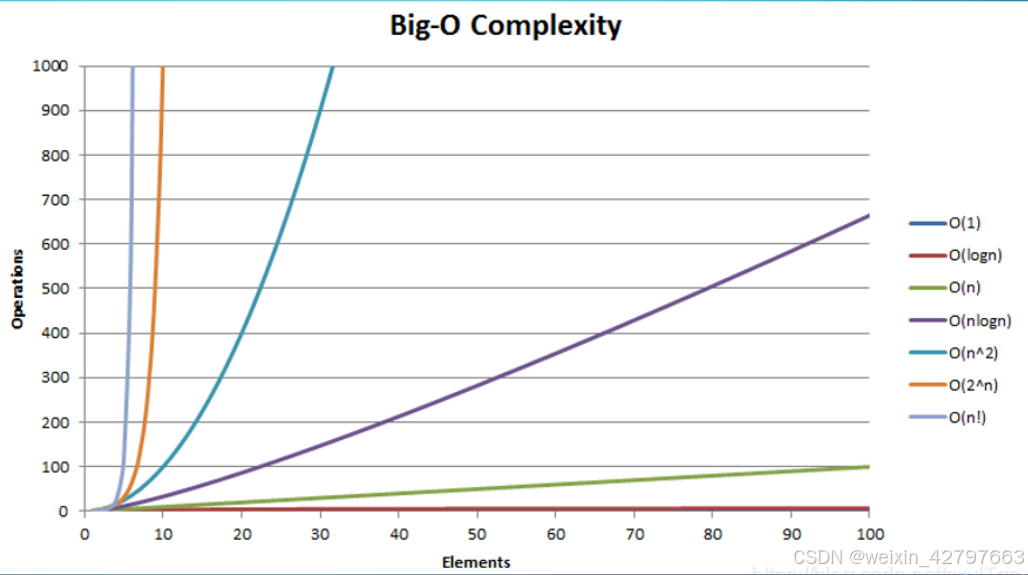
一、冒泡排序
时间复杂度:O(n²),其中n是待排序数组的长度
#include <iostream>
using namespace std;
int arr[114514], num;
void bubbleSort(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
for (int j = 0; j < n - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
// 交换 arr[j] 和 arr[j + 1]
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
void printArray(int arr[], int size) {
for (int i = 1; i < size; i++) {
cout << arr[i] << " ";
}
cout << endl;
}
int main() {
cin >> num;
for (int i = 1; i <= num; i++) {
cin >> arr[i];
}
int n = num;
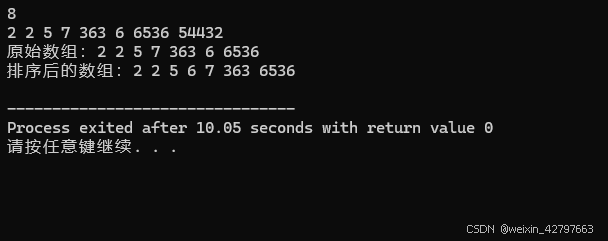
cout << "原始数组:";
printArray(arr, n);
bubbleSort(arr, n);
cout << "排序后的数组:";
printArray(arr, n);
return 0;
}
冒泡排序的基本步骤:
从列表的第一个元素开始,比较当前元素与下一个相邻的元素。
如果当前元素大于下一个元素(对于升序排列),就交换这两个元素的位置。
向前移动一个位置,继续比较和交换,直到到达列表的最后一个元素。
此时,最后一个元素已经是最大值了,所以不需要再考虑它。
对剩下的元素重复上述过程,但每次迭代都会减少一个已经排好序的元素。
当没有更多的元素可以比较或整个列表已经有序时,排序结束。
二、快速排序
快速排序是一种高效的排序算法,平均时间复杂度为O(nlogn),其中是待排序数组的长度。但在最坏情况下,时间复杂度会退化为O(n²)。
#include <iostream>
using namespace std;
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = low - 1;
for (int j = low; j < high; j++) {
if (arr[j] < pivot) {
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i + 1], arr[high]);
return i + 1;
}
void quickSort(int arr[], int low, int high) {
if (low < high) {
int pivotIndex = partition(arr, low, high);
quickSort(arr, low, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, high);
}
}
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++) {
cout << arr[i] << " ";
}
cout << endl;
}
int main() {
int n;
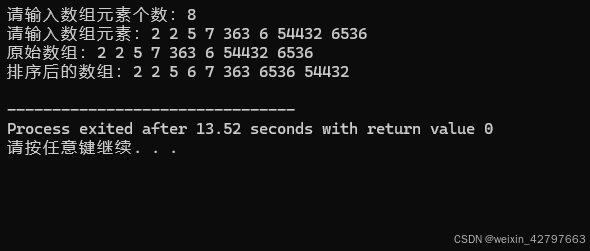
cout << "请输入数组元素个数:";
cin >> n;
int* arr = new int[n];
cout << "请输入数组元素:";
for (int i = 0; i < n; i++) {
cin >> arr[i];
}
cout << "原始数组:";
printArray(arr, n);
quickSort(arr, 0, n - 1);
cout << "排序后的数组:";
printArray(arr, n);
delete[] arr;
return 0;
}
快速排序采用分治策略来把一个序列分为较小的两部分,然后递归地排序这两部分。它的基本思想是选择一个“基准”元素,通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
三、计数排序
#include<bits/stdc++.h>
using namespace std;
int a[114514],b[114514],maxx = 1,minn = 1,flag,biaoji = 0;
void sortt(int t){
for(int i = 1;i<=t;i++){
int b1 = 0;
cin >> b1;
if(biaoji == 0){
minn=b1;
biaoji=1;
}
a[i] = b1;
b[b1]+=1;
a[i]>=maxx?maxx=a[i]:maxx=maxx;
a[i]<=minn?minn=a[i]:minn=minn;
}
printf("\nmax=%d min=%d\n",maxx,minn);
for(int i = minn;i<=maxx;i++){
printf("\nID=%d MUN=%d",i,b[i]);
}
printf("\n");
for(int i = minn;i <= maxx;i++){
if(b[i]>0){
printf("%d ",i);
b[i]--;
if(b[i]>0){
flag=1;
}
else{
flag=0;
}
}
if(flag == 1){
i--;
}
}
}
int main(){
int t;
cin >> t;
sortt(t);
return 0;
}
输入数据:
10
5 7 8 7 4 5 114513 99 75 7543
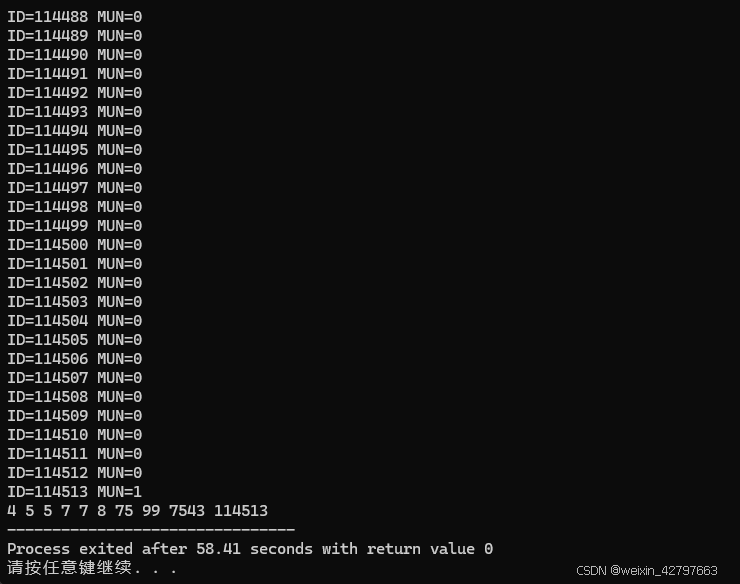
整体功能:
这段代码的作用是接收一系列整数,找出其中的最大值和最小值,统计每个整数出现的次数,然后按照从小到大的顺序输出这些整数,每个整数只输出一次。
工作方法及复杂度分析:
1.首先输入整数个数t。
2.在sortt函数中:
第一个循环遍历输入的t个整数:
每次读取一个整数b1,并将其存入数组a中。同时,更新最小值minn和最大值maxx,并统计每个整数出现的次数存入数组b中。这个循环的时间复杂度为O(t)。
接着输出最大值和最小值,然后遍历从最小值到最大值的范围,输出每个整数的编号(即整数本身)和出现次数。这个循环的时间复杂度为O(maxx-minn),在整数取值范围较大而输入个数较小时,这个时间复杂度可能较大,但如果输入的整数分布比较集中,这个值会比较接近t。
最后一个循环用于输出排序后的整数序列:
遍历从最小值到最大值的范围,对于出现次数大于 0 的整数进行输出,并减少其出现次数的计数。如果该整数还有剩余次数,就将当前索引减一,以便下一次循环继续处理这个整数。这个循环的时间复杂度也为O(maxx-minn),类似上面的分析。
总体来说,如果输入的整数取值范围相对输入个数不是特别大,那么整个代码的时间复杂度可以近似看作O(t)。但如果整数取值范围很大,那么时间复杂度可能会更高。
综上所述,在一般情况下,这段代码的工作方法的时间复杂度接近O(t)
总结
这段代码实现了一种基于计数的方法来处理整数序列,并非传统意义上的排序算法。它对于特定的数据集(整数且范围有限)可能是高效的,但对于更广泛的应用场景,传统的比较排序算法如快速排序、归并排序等可能更为合适。如果你的需求只是对整数进行计数和输出,那么这个方法是有效的;但如果你的目标是对任何类型的元素进行排序,那么应该考虑使用更通用的排序算法。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)