【机器学习】任务八:神经网络-- Keras(使用神经网络识别手写数字、使用 scikit-learn 中的 MLPClassifier,对 Wine 数据集进行分类)
Keras 是一个高级神经网络 API,用 Python 编写,能够在 TensorFlow、Theano 等深度学习框架上运行。Keras 以简洁性和用户友好性著称,允许快速构建、训练和部署深度学习模型。
目录
3.使用 scikit-learn 中的 MLPClassifier(多层感知机模型),对 Wine 数据集进行分类
3.1 使用 Pandas 将 Wine 数据集转换为 DataFrame
3.2 为 Wine 数据集设置 DataFrame 列名并预览数据
1.Keras
1.1 什么是 Keras?
Keras 是一个高级神经网络 API,用 Python 编写,能够在 TensorFlow、Theano 等深度学习框架上运行。Keras 以简洁性和用户友好性著称,允许快速构建、训练和部署深度学习模型。
特点:
- 模块化:网络模型由多个独立模块组成,支持灵活组合。
- 用户友好:对新手友好,语法简单,适合原型开发。
- 可扩展性:支持自定义层、损失函数、评估指标等。
1.2 Keras 的作用
Keras 是为构建和训练深度学习模型而设计的工具,简化了复杂的神经网络搭建过程。它封装了底层计算细节,帮助用户专注于模型设计和实验。
基本功能:
- 构建神经网络(全连接网络、卷积神经网络、递归神经网络等)。
- 训练与评估模型(支持各种损失函数与优化器)。
- 进行模型可视化和性能分析。
1.3 Keras 的应用场景
Keras 广泛用于以下深度学习领域:
1.计算机视觉(CV)
- 图像分类:手写数字识别(MNIST)、物体分类(CIFAR-10)
- 物体检测与分割:如自动驾驶中的道路检测
- 人脸识别与表情分析
2.自然语言处理(NLP)
- 语音识别与转录(Speech-to-Text)
- 情感分析、文本分类与机器翻译(如 LSTM、GRU 模型)
- 聊天机器人与对话系统
3.时间序列分析
- 股票价格预测
- IoT 数据分析,如传感器数据趋势预测
- 医疗监控中的生理信号处理(如 ECG 信号检测)
4.推荐系统
- 视频、音乐、商品推荐系统(如基于用户行为数据的深度学习模型)
- 个性化广告推荐
5.医疗应用
- 疾病预测与医学图像分析(如 X 光、CT 分析)
- 基于基因组数据的药物发现
1.4 小结
Keras 是一个快速构建神经网络模型的工具,它降低了深度学习的技术门槛,在学术研究与工业应用中都得到了广泛使用。无论是原型开发还是大规模部署,Keras 都能胜任,并通过其简明的 API 提供了强大的灵活性和性能。
2.使用神经网络识别手写数字
2.1 加载 MNIST 手写数字数据集并进行归一化处理
2.1.1 目的
加载 MNIST 手写数字数据集并进行归一化处理。将像素值缩放到 [0,1] 区间,确保数据在同一尺度上,方便神经网络模型的训练。
2.1.2 代码
# 步骤一:导入包,加载数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
mnist = tf.keras.datasets.mnist
# (x_train, y_train), (x_test, y_test) = mnist.load_data()
# x_train, y_train = x_train / 255.0, x_test / 255.0
# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 正确归一化训练集和测试集
x_train, x_test = x_train / 255.0, x_test / 255.0
2.1.3 代码解释
1.导入包
tensorflow: 用于加载数据和构建模型。numpy: 用于数组操作。matplotlib: 用于数据可视化。
2.加载 MNIST 数据集
mnist.load_data():加载 MNIST 数据集,返回训练集(x_train, y_train)和测试集(x_test, y_test)。- 数据包含 28×28 的灰度图片,标签为 0~9 的数字。
3.数据归一化
- 将图片的像素值从 [0, 255] 缩放到 [0, 1] 范围,这有助于加快模型训练并提升性能。
2.2 构建顺序神经网络模型
2.1 目的
构建一个顺序神经网络模型,以处理 MNIST 数据集中的手写数字分类任务。通过堆叠网络层,将输入图像展开并依次通过隐藏层和输出层,以实现对图像的准确分类。
2.2.1 代码与结果
# 构建顺序网络模型
model = tf.keras.models.Sequential()
# 使用Input层显式定义输入形状,并使用Flatten()函数将数据平展为一维数组
model.add(tf.keras.layers.Input(shape=(28, 28)))
model.add(tf.keras.layers.Flatten())
# 为网络模型添加隐藏层和输出层
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
# 输出模型结构
model.summary()
2.2.3 代码解释
1.构建顺序网络模型:
- 使用
Sequential()逐层构建神经网络,适合简单的层次结构模型。
2.输入层和 Flatten 层:
Input(shape=(28, 28)):定义输入数据的形状为 28×28 的图像。Flatten():将二维的图像数据展开为一维数组(784维),以便传入全连接层。
3.隐藏层和输出层:
- 隐藏层:128 个神经元,激活函数为
relu,用于学习非线性特征。 - 输出层:10 个神经元,使用
softmax激活函数,输出 10 个类别的概率(对应数字 0-9)。
4.模型结构输出:
model.summary():打印模型结构及各层的参数信息。
2.2.4 结果分析
模型的结构如图所示:
1.Flatten 层:
- 输入为 28×28 的图像,展开为一维向量 (784,)。
- 参数数量:0(Flatten 层不含可训练参数)。
2.Dense 隐藏层:
- 输入维度 784,输出维度 128。
- 参数数量:
784 × 128 + 128 = 100,480(权重和偏置)。
3.Dense 输出层:
- 输入维度 128,输出维度 10(对应 10 个类别)。
- 参数数量:
128 × 10 + 10 = 1,290。
4.总参数量:
- 总计 101,770 个参数,其中所有参数都可训练。
该模型结构简单但有效,适合处理 MNIST 数据集的分类任务。通过 ReLU 和 Softmax 激活函数,模型可以学习到数据中的非线性特征,并输出各类别的概率。
2.3 代码:编译、训练和评估顺序神经网络模型
2.3.1 目的
编译模型、训练神经网络,并在测试集上评估其性能,确保模型能够正确分类手写数字数据集中的图片,并具有良好的泛化能力。
2.3.2 代码与结果
# 步骤三,编译、训练和评估顺序网络模型
# 编译网络模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 训练网络模型
model.fit(x_train, y_train, batch_size=32, epochs=5)
# 评估网络模型
model.evaluate(x_test, y_test, batch_size=32, verbose=2)

2.3.3 代码解释
1.编译模型:
optimizer='adam':使用 Adam 优化器,以加速模型训练和收敛。loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False):用于多分类任务的损失函数,适合标签为整数的情况。metrics=['sparse_categorical_accuracy']:采用稀疏分类准确率来评估模型性能。
2.训练模型:
fit():训练模型。batch_size=32:每次使用 32 个样本进行参数更新。epochs=5:训练 5 轮,每一轮都会遍历整个训练集一次。- 输出日志:每轮显示损失和准确率。
3.评估模型:
evaluate():在测试集上评估模型性能。- 打印测试集的损失和准确率,验证模型的泛化能力。
2.3.4 结果分析
1.训练过程表现:
- 在 5 轮训练中,损失从 0.4504 降到 0.0433,准确率从 87.08% 提升到 98.68%,表明模型在逐步收敛。
2.测试集结果:
- 测试集损失:0.0763
- 测试集准确率:97.71%
3.分析:
- 模型在测试集上的准确率为 97.71%,表明模型在未见过的数据上也表现良好,具有很好的泛化能力。
- 训练过程中的准确率逐步提升,损失逐步减少,表明模型学习效果良好,没有出现明显的过拟合问题。
2.4 使用顺序网络模型进行预测与可视化
2.4.1 目的
使用训练好的顺序神经网络模型对 MNIST 数据集中的样本进行预测,并通过可视化展示实际标签与模型的预测结果,以检验模型的效果。
2.4.2 代码与结果:应用顺序网络模型
# 步骤四,应用顺序网络模型
# 应用顺序网络模型
for i in range(5):
# 生成随机整数 t
t = np.random.randint(1, 10000)
# 选择测试集中的第 t 个样本,并重塑为 (1, 28, 28)
x = tf.reshape(x_test[t], (1, 28, 28))
# 应用模型进行预测
y_pred = np.argmax(model.predict(x), axis=1)
# 创建子图
plt.subplot(1, 5, i + 1)
# 设置字体为 SimHei 以显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置不显示坐标轴
plt.axis('off')
# 显示图片(灰度图)
plt.imshow(x_test[t], cmap='gray')
# 设置子图标题为实际标签和预测值
title = "标签值:" + str(y_test[t]) + "\n预测值:" + str(y_pred[0])
plt.title(title)
# 显示图形
plt.show()
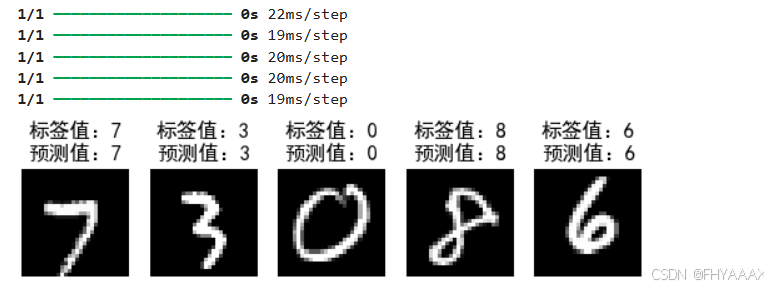
2.4.3 代码解释
1.随机选择样本:
- 使用
np.random.randint()生成 1 到 10000 之间的随机整数t,用于选择测试集中的样本。
2.数据重塑:
- 使用
tf.reshape()将样本重塑为 (1, 28, 28),符合模型的输入格式。
3.模型预测:
- 使用
model.predict()对重塑后的样本进行预测,并通过np.argmax()获取预测的类别。
4.可视化预测结果:
- 创建 1×5 的子图布局,展示 5 张随机选取的测试图片。
- 使用
plt.rcParams['font.sans-serif']设置字体为 SimHei,以支持中文显示。 - 设置
plt.axis('off')隐藏坐标轴,并在子图标题中显示标签与预测结果。
2.4.4 结果分析
如结果所示,模型对 5 张手写数字图片的预测与真实标签完全一致,显示出较高的准确性。每张图像的预测时间较快(大约 20 毫秒/步),表明模型的计算效率较高。这验证了模型在处理手写数字分类任务中的良好性能。
2.5 总体代码
# 步骤一:导入包,加载数据
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
mnist = tf.keras.datasets.mnist
# (x_train, y_train), (x_test, y_test) = mnist.load_data()
# x_train, y_train = x_train / 255.0, x_test / 255.0
# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 正确归一化训练集和测试集
x_train, x_test = x_train / 255.0, x_test / 255.0
# 构建顺序网络模型
model = tf.keras.models.Sequential()
# 使用Input层显式定义输入形状,并使用Flatten()函数将数据平展为一维数组
model.add(tf.keras.layers.Input(shape=(28, 28)))
model.add(tf.keras.layers.Flatten())
# 为网络模型添加隐藏层和输出层
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
# 输出模型结构
model.summary()
# 步骤三,编译、训练和评估顺序网络模型
# 编译网络模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 训练网络模型
model.fit(x_train, y_train, batch_size=32, epochs=5)
# 评估网络模型
model.evaluate(x_test, y_test, batch_size=32, verbose=2)
# 步骤四,应用顺序网络模型
# 应用顺序网络模型
for i in range(5):
# 生成随机整数 t
t = np.random.randint(1, 10000)
# 选择测试集中的第 t 个样本,并重塑为 (1, 28, 28)
x = tf.reshape(x_test[t], (1, 28, 28))
# 应用模型进行预测
y_pred = np.argmax(model.predict(x), axis=1)
# 创建子图
plt.subplot(1, 5, i + 1)
# 设置字体为 SimHei 以显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
# 设置不显示坐标轴
plt.axis('off')
# 显示图片(灰度图)
plt.imshow(x_test[t], cmap='gray')
# 设置子图标题为实际标签和预测值
title = "标签值:" + str(y_test[t]) + "\n预测值:" + str(y_pred[0])
plt.title(title)
# 显示图形
plt.show()
3.使用 scikit-learn 中的 MLPClassifier(多层感知机模型),对 Wine 数据集进行分类
3.1 使用 Pandas 将 Wine 数据集转换为 DataFrame
3.1.1 目的
使用 Pandas 将 wine 数据集转换为 DataFrame 格式,便于数据的查看和分析。
3.1.2 代码与结果
# 1.导入 Pandas 包并转换数据集为 DataFrame
import pandas as pd
# 将 wine 数据集转换为 DataFrame
df_wine = pd.DataFrame(wine.data)
# 查看前 5 行数据
df_wine.head()
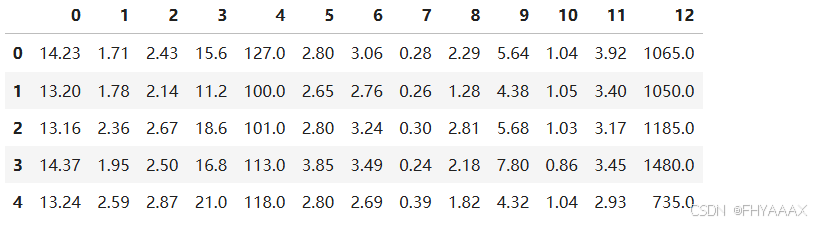
3.1.3 代码解释
1.导入 Pandas 包:
- 使用 Pandas 进行数据的处理与分析。
2.转换数据集为 DataFrame:
- 将
wine数据集转换为 DataFrame 格式,方便使用 Pandas 的功能来查看和操作数据。
3.查看前 5 行数据:
- 使用
head()方法显示数据集的前 5 行,帮助检查数据加载是否成功,并初步了解数据结构。
3.1.4 结果分析
head() 方法展示了 wine 数据集的前 5 行,每一行代表一个样本的数据记录。可以根据这些数据进行进一步的数据探索和预处理。
3.2 为 Wine 数据集设置 DataFrame 列名并预览数据
3.2.1 目的
为 Pandas DataFrame 添加列名,使数据结构更加清晰,并通过查看前 5 行数据确认列名设置是否成功。
3.2.2 代码与结果
# 2.设置 DataFrame 的列名
# 为 DataFrame 添加特征列名
df_wine.columns = wine.feature_names
# 再次查看前 5 行数据,验证设置是否成功
df_wine.head()

3.2.3 代码解释
-
为 DataFrame 添加特征列名:
wine.feature_names:提供了 Wine 数据集中每一列的特征名。df_wine.columns = wine.feature_names:将这些列名赋值给 DataFrame 的列属性,确保数据结构更加清晰易读。
-
预览数据:
- 使用
df_wine.head()查看 DataFrame 的前 5 行数据,以验证列名设置是否正确。
- 使用
3.2.4 结果分析
成功为 Wine 数据集添加了清晰的列名,如 alcohol、malic_acid 等,帮助我们快速理解数据的结构。每一列代表不同的葡萄酒化学特征,这些数据将用于后续的分析和建模。通过预览数据,我们可以确认列名已经成功添加,并初步检查了数据的内容和格式。
3.3 为 Wine 数据集添加标签列并查看数据
3.3.1 目的
为 Wine 数据集添加标签列,用于标识每个样本的类别,并检查数据的完整性。
3.3.2 代码与结果
# 3.将标签添加为新列
# 添加标签列 'wine_class'
df_wine['wine_class'] = wine.target
# 查看 DataFrame 的最后 5 行
df_wine.tail()

3.3.3 代码解释
1.为 DataFrame 添加标签列:
df_wine['wine_class'] = wine.target:将wine.target中的标签数据作为新的列'wine_class'添加到 DataFrame 中,用于标识每个样本所属的类别。
2.查看数据的最后 5 行:
- 使用
df_wine.tail()查看 DataFrame 的最后 5 行,确保标签列添加成功,并检查数据的完整性。
3.3.4 结果分析
通过添加 'wine_class' 列,我们将每个样本的类别标识添加到了 DataFrame 中。查看最后 5 行的数据可以确认标签列已成功添加。wine_class 列的值为 0、1、2,代表不同类别的葡萄酒。这为后续的分类建模和分析奠定了基础。
3.4 特征与标签分离、数据集划分及 MLP 模型构建
3.4.1 目的
对 Wine 数据集进行特征与标签分离,并划分训练集和测试集。最后,使用 MLP(多层感知机) 模型进行分类任务的构建。
3.4.2 代码与结果
# 4. 划分特征与标签,并准备其与训练数据的分离
# 删除标签列,保留特征数据
X = df_wine.drop('wine_class', axis=1)
# 将标签列单独赋值给 y
y = df_wine['wine_class']
# 5. 使用 scikit-learn 进行训练集和测试集的拆分
from sklearn.model_selection import train_test_split
# 拆分训练集和测试集,测试集占 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 6. 构建多层感知机模型(MLP)
from sklearn.neural_network import MLPClassifier
# 创建 MLP 分类器,隐藏层有 500 个神经元,使用 lbfgs 作为优化器
model = MLPClassifier(hidden_layer_sizes=(500,), solver='lbfgs', max_iter=1000)
3.4.3 代码解释
1.特征与标签分离:
X = df_wine.drop('wine_class', axis=1):删除 DataFrame 中的'wine_class'列,将剩余的特征数据赋给X。y = df_wine['wine_class']:将标签列赋给变量y,用于存储每个样本的类别。
2.训练集和测试集划分:
train_test_split():使用 scikit-learn 将数据集划分为训练集和测试集。test_size=0.3:测试集占 30%。random_state=0:固定随机种子,确保结果的可复现性。
3.构建 MLP 模型:
MLPClassifier():使用 MLP 多层感知机模型进行分类。hidden_layer_sizes=(500,):设置隐藏层大小为 500 个神经元。solver='lbfgs':选择 lbfgs 作为优化器,适用于较小的数据集。max_iter=1000:设置最大迭代次数为 1000,确保模型能充分训练。
3.4.4 结果分析
- 特征与标签的分离:成功将 Wine 数据集拆分为特征数据和标签数据,为训练模型做好准备。
- 训练集和测试集的划分:训练集占 70%,测试集占 30%,确保模型在训练后可以进行有效的测试和验证。
- MLP 模型构建:MLP 模型采用了 500 个神经元的隐藏层和 lbfgs 作为优化器,适合对小规模数据集进行分类任务。模型已经准备好用于后续的训练与评估。
3.5 模型训练、预测及性能评估
3.5.1 目的
使用 MLP 多层感知机模型 在训练集和测试集上进行预测,并评估模型的分类性能。
3.5.2 代码与结果
# 7. 训练模型
# 在训练集上训练模型
model.fit(X_train, y_train)
# 8. 在训练集和测试集上进行预测
# 在训练集上进行预测
y_predict_on_train = model.predict(X_train)
# 在测试集上进行预测
y_predict_on_test = model.predict(X_test)
# 9. 评估模型性能
from sklearn.metrics import accuracy_score
# 计算训练集和测试集的准确率
print("训练集的准确率为: {:.2f}%".format(100 * accuracy_score(y_train, y_predict_on_train)))
print("测试集的准确率为: {:.2f}%".format(100 * accuracy_score(y_test, y_predict_on_test)))
训练集的准确率为: 99.19%
测试集的准确率为: 94.44%
3.5.3 代码解释
1.模型训练:
- 使用
model.fit()在训练集上训练 MLP 模型,优化模型参数以拟合数据。
2.模型预测:
- 训练集预测:使用
model.predict(X_train)在训练集上进行预测。 - 测试集预测:使用
model.predict(X_test)在测试集上进行预测。
3.性能评估:
accuracy_score():计算训练集和测试集的分类准确率。- 输出准确率:格式化打印训练集和测试集的预测准确率,评估模型的性能。
3.5.4 结果分析
- 训练集准确率:99.19%
- 测试集准确率:94.44%
分析:
- 训练集的高准确率(99.19%)表明模型在训练数据上的拟合效果非常好。
- 测试集的准确率为 94.44%,表明模型在未见过的数据上也具有良好的泛化能力。
- 差异分析:训练集和测试集准确率之间的轻微差异表明模型没有出现明显的过拟合,具备良好的分类性能。
3.6 数据标准化、模型训练与性能评估
3.6.1 目的
对训练数据和测试数据进行标准化处理,提升 MLP 模型的训练效果,确保不同特征的数值范围一致,并验证模型在标准化数据上的性能。
2.2 代码与结果
# 10. 数据标准化处理
from sklearn.preprocessing import StandardScaler
# 创建 StandardScaler 对象
scaler = StandardScaler()
# 在训练集上拟合并转换数据
X_train = scaler.fit_transform(X_train)
# 在测试集上进行转换
X_test = scaler.transform(X_test)
# 11. 使用标准化数据重新训练模型
# 使用相同的参数创建新的 MLP 分类器
model = MLPClassifier(solver='lbfgs', hidden_layer_sizes=(100,))
# 训练模型
model.fit(X_train, y_train)
# 在训练集和测试集上进行预测
y_predict_on_train = model.predict(X_train)
y_predict_on_test = model.predict(X_test)
# 评估模型性能
print("训练集的准确率为: {:.2f}%".format(100 * accuracy_score(y_train, y_predict_on_train)))
print("测试集的准确率为: {:.2f}%".format(100 * accuracy_score(y_test, y_predict_on_test)))
训练集的准确率为: 100.00%
测试集的准确率为: 100.00%
2.3 代码解释
1.数据标准化处理:
StandardScaler:对数据进行标准化,使每个特征的均值为 0,标准差为 1,消除不同特征量纲之间的差异。fit_transform():在训练集上拟合并转换数据。transform():使用在训练集上拟合的标准化参数,对测试集进行转换。
2.模型训练与预测:
- MLPClassifier:使用 MLP 模型进行分类,设置隐藏层神经元数量为 100,优化器为
'lbfgs'。 fit():在标准化后的训练集上训练模型。predict():分别在训练集和测试集上进行预测。
3.性能评估:
accuracy_score():计算训练集和测试集的分类准确率。- 打印训练集和测试集的准确率,观察模型的性能。
2.4 结果分析
- 训练集准确率:100.00%
- 测试集准确率:100.00%
分析:
- 标准化处理显著提升了模型的性能,在训练集和测试集上均达到了 100.00% 的准确率。
- 这种表现表明模型对数据的学习和泛化能力非常出色,没有过拟合的迹象。
- 使用 StandardScaler 进行数据标准化,有效提升了 MLP 模型的分类效果。这也说明在特征数值范围差异较大的数据上,标准化是非常重要的一步。
3.7查看模型权重参数
3.7.1 目的
查看并分析 MLP(多层感知机)模型的权重参数,了解模型训练过程中各层神经元之间的连接权重。
3.7.2 代码与结果
# 12. 查看模型参数
# 查看模型的权重参数和权重矩阵
print(model.coefs_[0]) # 第一层的参数
print(model.coefs_[1]) # 第二层的参数
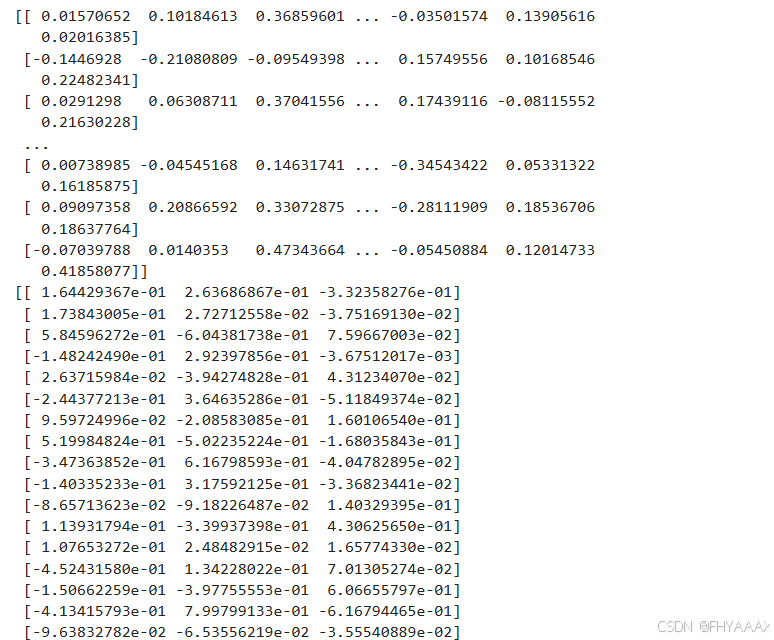
3.7.3 代码解释
1.model.coefs_:
- 这是一个包含每一层神经网络权重矩阵的列表。
model.coefs_[0]:表示输入层与隐藏层之间的权重矩阵。model.coefs_[1]:表示隐藏层与输出层之间的权重矩阵。
2.权重矩阵的结构:
- 每一行代表前一层的神经元,每一列代表后一层的神经元。
- 每个元素的值是连接对应神经元之间的权重,表示其连接的强度和方向。
- 正值表示正相关,负值表示负相关。
3.7.4 结果分析
-
第一层的权重:显示输入层到隐藏层之间的连接。每行代表输入特征,每列代表隐藏层的神经元,反映特征对隐藏层的贡献。
-
第二层的权重:显示隐藏层到输出层的连接。每行代表隐藏层的神经元,每列代表输出层的神经元。
分析:
通过查看这些权重,我们可以分析哪些输入特征和隐藏层神经元对模型的决策影响最大。权重较大的数值表示该连接对结果的贡献较大,而负值表示该连接抑制了特定的输出。这些权重的可视化和理解有助于进一步优化和调试模型。
2.8 总体代码
# 1.导入 Pandas 包并转换数据集为 DataFrame
import pandas as pd
# 将 wine 数据集转换为 DataFrame
df_wine = pd.DataFrame(wine.data)
# 查看前 5 行数据
df_wine.head()
# 2. 设置 DataFrame 列列名
# 为 DataFrame 添加特征列名
df_wine.columns = wine.feature_names
# 预览查看前 5 行数据,验证设置是否成功
df_wine.head()
# 3. 将标签添加为新列
# 添加标签列 'wine_class'
df_wine['wine_class'] = wine.target
# 查看 DataFrame 的最后 5 行
df_wine.tail()
# 4. 划分特征与标签,并准备其与训练数据的分离
# 删除标签列,保留特征数据
X = df_wine.drop('wine_class', axis=1)
# 将标签列单独赋值给 y
y = df_wine['wine_class']
# 5. 使用 scikit-learn 进行训练集和测试集的拆分
from sklearn.model_selection import train_test_split
# 拆分训练集和测试集,测试集占 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 6. 构建多层感知机模型(MLP)
from sklearn.neural_network import MLPClassifier
# 创建 MLP 分类器,隐藏层有 500 个神经元,使用 lbfgs 作为优化器
model = MLPClassifier(hidden_layer_sizes=(500,), solver='lbfgs', max_iter=1000)
# 7. 训练模型
# 在训练集上训练模型
model.fit(X_train, y_train)
# 8. 在训练集和测试集上进行预测
# 在训练集上进行预测
y_predict_on_train = model.predict(X_train)
# 在测试集上进行预测
y_predict_on_test = model.predict(X_test)
# 9. 评估模型性能
from sklearn.metrics import accuracy_score
# 计算训练集和测试集的准确率
print("训练集的准确率为: {:.2f}%".format(100 * accuracy_score(y_train, y_predict_on_train)))
print("测试集的准确率为: {:.2f}%".format(100 * accuracy_score(y_test, y_predict_on_test)))
# 10. 数据标准化处理
from sklearn.preprocessing import StandardScaler
# 创建 StandardScaler 对象
scaler = StandardScaler()
# 在训练集上拟合并转换数据
X_train = scaler.fit_transform(X_train)
# 在测试集上进行转换
X_test = scaler.transform(X_test)
# 11. 使用标准化数据重新训练模型
# 使用相同的参数创建新的 MLP 分类器
model = MLPClassifier(solver='lbfgs', hidden_layer_sizes=(100,))
# 训练模型
model.fit(X_train, y_train)
# 在训练集和测试集上进行预测
y_predict_on_train = model.predict(X_train)
y_predict_on_test = model.predict(X_test)
# 评估模型性能
print("训练集的准确率为: {:.2f}%".format(100 * accuracy_score(y_train, y_predict_on_train)))
print("测试集的准确率为: {:.2f}%".format(100 * accuracy_score(y_test, y_predict_on_test)))
# 12. 查看模型参数
# 查看模型的权重参数和权重矩阵
print(model.coefs_[0]) # 第一层的参数
print(model.coefs_[1]) # 第二层的参数

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 31
31 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)