java计算文本相似度算法总结
计算两个字符串之间的最小单字符编辑(插入、删除、替换)次数。这是一种衡量字符串差异性的方法,常用于拼写检查和模糊匹配。:一种基于 Jaro 相似度的改进算法,特别适用于拼写检查和模糊匹配。:计算两个字符串之间的最长公共子序列长度,常用于文本差异比较。:通过计算两个字符串的 n-gram 向量的余弦夹角来评估它们的相似度。:基于子串的字符串相似度计算方法,计算它们共有的Q-gram(长度为Q的连续子
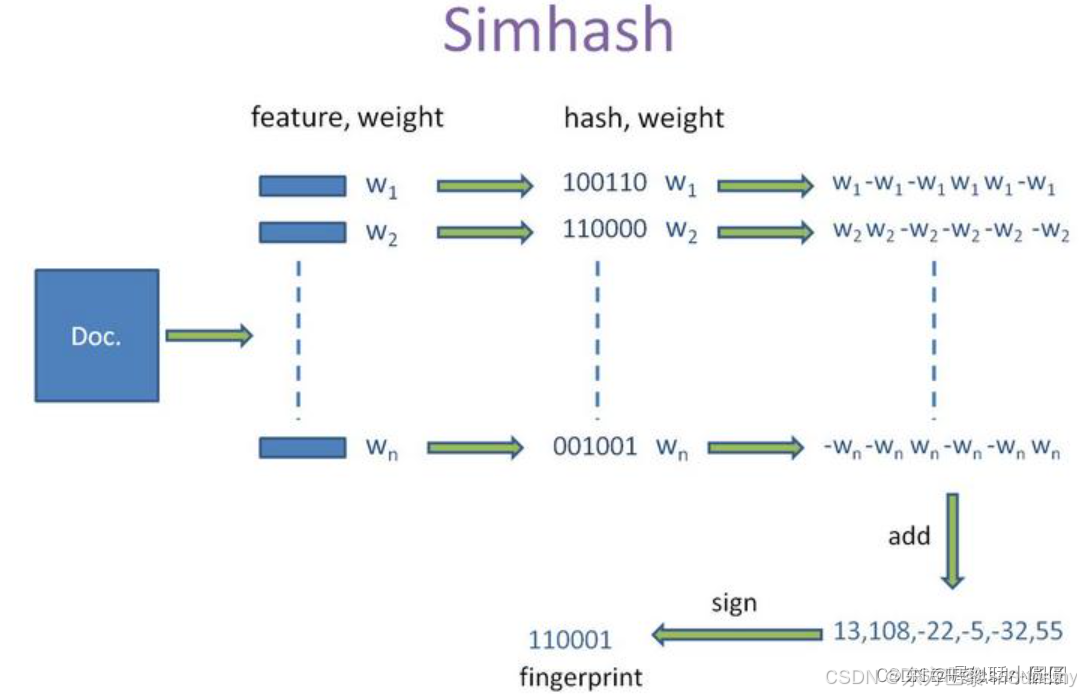
Java中计算文本之间相似度的算法有多种,以下是一些常见的算法及其案例:
-
Levenshtein 距离:计算两个字符串之间的最小单字符编辑(插入、删除、替换)次数。这是一种衡量字符串差异性的方法,常用于拼写检查和模糊匹配。
public class LevenshteinDistance { public static int calculate(String s, String t) { int[][] d = new int[s.length() + 1][t.length() + 1]; for (int i = 0; i <= s.length(); i++) d[i][0] = i; for (int j = 0; j <= t.length(); j++) d[0][j] = j; for (int i = 1; i <= s.length(); i++) { for (int j = 1; j <= t.length(); j++) { int cost = (s.charAt(i - 1) == t.charAt(j - 1)) ? 0 : 1; d[i][j] = Math.min(Math.min(d[i - 1][j] + 1, d[i][j - 1] + 1), d[i - 1][j - 1] + cost); } } return d[s.length()][t.length()]; } } -
Jaro-Winkler 相似度:一种基于 Jaro 相似度的改进算法,特别适用于拼写检查和模糊匹配。
public class JaroWinklerSimilarity { public static double similarity(String s1, String s2) { // Jaro-Winkler similarity calculation logic } } -
最长公共子序列(LCS):计算两个字符串之间的最长公共子序列长度,常用于文本差异比较。
public class LongestCommonSubsequence { public static int lcs(String s1, String s2) { int[][] dp = new int[s1.length() + 1][s2.length() + 1]; for (int i = 0; i <= s1.length(); i++) { for (int j = 0; j <= s2.length(); j++) { if (i == 0 || j == 0) { dp[i][j] = 0; } else if (s1.charAt(i - 1) == s2.charAt(j - 1)) { dp[i][j] = dp[i - 1][j - 1] + 1; } else { dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]); } } } return dp[s1.length()][s2.length()]; } } -
余弦相似度:通过计算两个字符串的 n-gram 向量的余弦夹角来评估它们的相似度。
public class CosineSimilarity { public static double cosineSimilarity(String s1, String s2) { // Convert strings to n-gram vectors // Calculate cosine similarity between vectors } } -
Q-gram Matching:基于子串的字符串相似度计算方法,计算它们共有的Q-gram(长度为Q的连续子串)的数量,然后将这个数量除以两个字符串中Q-gram数量较少的那个,得到相似度的比例。
public class QGramMatching { public static double qGramSimilarity(String s1, String s2, int q) { Set<String> qGrams1 = calculateQGrams(s1, q); Set<String> qGrams2 = calculateQGrams(s2, q); Set<String> intersection = new HashSet<>(qGrams1); intersection.retainAll(qGrams2); double similarity = intersection.size() / (double) Math.min(qGrams1.size(), qGrams2.size()); return similarity; } } -
Jaccard相似性系数:通过计算两个集合交集的大小除以并集的大小来评估它们的相似度。
public class JaccardSimilarity { public static double jaccardSimilarity(String s1, String s2) { Set<String> words1 = new HashSet<>(Arrays.asList(s1.split("\\s+"))); Set<String> words2 = new HashSet<>(Arrays.asList(s2.split("\\s+"))); Set<String> intersection = new HashSet<>(words1); intersection.retainAll(words2); Set<String> union = new HashSet<>(words1); union.addAll(words2); return intersection.size() / (double) union.size(); } }
这些算法各有特点和适用场景,开发者可以根据具体需求选择合适的算法。

📊 哪种算法最适合短文本相似度计算?
对于短文本相似度计算,根据搜索结果,以下是几种推荐的算法:
-
Jaccard相似度:基于集合的交集与并集的比值来计算相似度。在文本相似度中,可以将文本表示为词汇的集合,然后计算两个集合的Jaccard相似度。这种方法适用于短文本或关键词列表的比较。
-
编辑距离(Levenshtein Distance):衡量的是将一个字符串转换为另一个字符串所需的最少编辑操作(如插入、删除或替换)次数。编辑距离越小,两个字符串越相似。这种方法适用于字符级或词级的文本相似度比较。
-
余弦相似度(Cosine Similarity):通过计算两个向量的夹角余弦值来评估它们的相似度。在文本相似度计算中,首先将文本转换为向量表示(如TF-IDF向量),然后计算这些向量之间的余弦值。余弦值越接近1,表示文本越相似。
-
SimNet:百度的一个计算短文本相似度的框架,可以根据用户输入的两个文本,计算出相似度得分。这个模型可以作为预训练模型用自己的语料在它上面进行微调。
-
PEARL:一个轻量的表示模型,只有34M参数,可以计算各种短文本的相似度。PEARL的主要思想是使用对比学习框架来学习短文本表示。
-
基于Word2Vec计算词向量:使用训练好的模型或者使用准备的语料库训练word2vec模型,然后通过word2vec计算句子中词的词向量(word vector),获取句向量,可通过对词向量的加权平均等方法获取,最后计算余弦相似度。
-
Word Mover’s Distance (WMD):在词向量的基础上发展而来的用来衡量文档相似性的度量,是一种计算句子之间距离的方法,距离越小,相似度越高。
综合考虑,对于短文本相似度计算,Jaccard相似度、编辑距离和余弦相似度是比较直接和常用的方法,它们能够快速地处理短文本并给出相似度评分。而SimNet和PEARL作为预训练模型,能够提供更深层次的语义相似度计算,尤其适用于需要高精度相似度匹配的场景。Word2Vec和WMD则提供了基于词向量的方法,能够捕捉到文本的语义信息,适用于需要考虑词义相似度的场景。
🔍 余弦相似度在文本处理中有什么局限性?
余弦相似度在文本处理中的局限性主要包括以下几点:
-
不考虑词序:余弦相似度基于词袋模型,忽略了词序信息,这可能导致某些语义差异被忽视。例如,“我喜欢苹果”和“苹果喜欢我”在语义上是不同的,但余弦相似度可能无法区分这种差异。
-
对罕见词不敏感:在TF-IDF等加权方案中,罕见词可能被过度强调,这可能导致余弦相似度在处理文本时对这些词过于敏感,从而影响相似度的准确性。
-
计算复杂度:在大规模数据集上,计算所有文档对之间的余弦相似度可能计算量巨大,这在实际应用中可能是一个挑战。
-
语义理解局限:仅基于词频或简单词嵌入的余弦相似度可能无法捕捉复杂的语义关系。这意味着余弦相似度可能无法充分理解文本的深层含义,特别是在处理需要深层次语义理解的任务时。
-
不考虑词的权重:余弦相似度通常不考虑词的权重,而实际上在文本中,某些词可能比其他词更重要,这种权重信息在余弦相似度计算中被忽略了。
-
对向量长度不敏感:余弦相似度只关注向量之间的夹角,而不关注向量的长度。这可能导致在某些情况下,即使两个向量的长度差异很大,只要它们的方向相似,余弦相似度也会很高,这可能不是我们想要的结果。
-
无法处理需要考虑向量长度的问题:余弦相似度无法处理一些需要考虑向量长度的问题,例如,当两个向量的各分量之间存在较大差异时,即使它们的夹角很小,余弦相似度也可能较低。
这些局限性表明,虽然余弦相似度是一个简单而强大的相似度度量方法,但在某些特定的应用场景下,可能需要结合其他技术或方法来提高相似度计算的准确性和有效性。
📊 余弦相似度在哪些领域应用效果最好?
余弦相似度在多个领域都有出色的应用效果,特别是在以下领域:
-
文本分析:余弦相似度在自然语言处理中常用于计算两个文本片段的相似性,比如句子或文档之间的相似度。它能够有效捕捉不同文档之间的“角度”关系,突出内容的相似性。
-
推荐系统:在推荐系统中,余弦相似度用于比较用户偏好或项目特征向量,通过计算余弦相似度来提供个性化推荐。这种方法可以帮助系统根据用户的历史行为数据构建向量,并推荐相似的商品或内容。
-
信息检索:在搜索引擎中,余弦相似度用于评估用户查询与文档之间的相似性,从而返回最相关的结果。这对于优化搜索结果,提供准确和上下文相关的信息至关重要。
-
图嵌入分析:在知识图谱或其他嵌入式结构中,余弦相似度用于比较节点或关系的嵌入表示,以找到最相似的实体或关系。
-
图像处理:在图像处理领域,余弦相似度可以将图像表示为特征向量,然后比较图像之间的相似度,这在图像检索、相似图片搜索等应用中非常有用。
-
音频处理:在音频处理中,可以将音频片段表示为特征向量,并使用余弦相似度来识别相似的音频片段,如语音识别或音乐推荐。
综上所述,余弦相似度因其在处理高维数据时的高效性和对向量方向的敏感性,在文本分析、推荐系统、信息检索、图嵌入分析、图像处理和音频处理等领域都有广泛的应用和良好的效果。
🤔 余弦相似度在机器学习领域具体如何应用?
余弦相似度在机器学习领域的应用非常广泛,以下是一些具体的应用场景:
-
文本相似性判断:在文本处理领域,余弦相似度常用于判断两篇文档的相似性。通过将文档转化为向量形式,我们可以利用余弦相似度来评估它们之间的相似程度。
-
推荐系统:在推荐系统中,余弦相似度可以用于计算用户或物品之间的相似度。例如,我们可以根据用户对物品的评分来构建用户向量和物品向量,然后利用余弦相似度来找到相似的用户或物品,从而为用户提供个性化的推荐。
-
图像识别:在图像识别领域,余弦相似度可以用于衡量两张图像的相似性。通过将图像特征转化为向量形式,我们可以利用余弦相似度来评估它们之间的相似程度。
-
信息检索:余弦相似度可用于搜索引擎,以度量查询与文档之间的相似度,从而为用户提供相关性最高的搜索结果。
-
音频处理:在音频处理中,可以将音频片段表示为特征向量,并使用余弦相似度来识别相似的音频片段,如语音识别或音乐推荐。
-
画像匹配:可以将用户特征提取为向量,计算不同用户向量之间的余弦相似度,来找到兴趣相投的用户。
这些应用展示了余弦相似度在机器学习中的重要性,尤其是在处理高维数据和评估相似性方面。通过将数据转换为向量形式,余弦相似度提供了一种简单而有效的相似性度量方法。

📈 余弦相似度在图像识别中的准确率和计算时间如何平衡?
余弦相似度在图像识别中的应用需要在准确率和计算时间之间找到平衡。以下是一些关键点,它们可以帮助我们理解如何实现这种平衡:
-
实时监控与计算效率:在某些应用中,如动态液滴生成过程的监控,余弦相似度算法(CSA)被用作在线方法,以指定的时间间隔更新液滴生成频率的计算结果。为了实现实时监控,需要对CSA方法进行一些修改,包括设置两个特定大小的数据缓冲区来存储捕获的视频帧和与参考帧之间的余弦相似度。通过使用这些缓冲区,计算相似向量的时间复杂度从O(N帧R)降低到1/5000,显著减少了计算时间,同时保持了高准确率。
-
知识蒸馏中的余弦相似度:在知识蒸馏的背景下,余弦相似度被用来衡量低维和高维表示之间的相关性。这种方法有效地表示了在知识蒸馏过程中,低维和高维表示之间的相关性,而不需要额外的学习模块,这有助于在保持计算效率的同时提高准确率。
-
计算资源和时间:在某些情况下,使用余弦相似度作为损失函数可能会导致更多的内存资源和处理时间需求。这是因为计算余弦相似度和余弦相似度指导需要额外的计算。然而,这种方法通过优化网络结构和损失函数,避免了使用额外的可学习模块,从而在不牺牲准确率的情况下提高了计算效率。
综上所述,余弦相似度在图像识别中的应用可以通过以下方式实现准确率和计算时间的平衡:
- 使用数据缓冲区来减少重复计算,提高实时处理能力。
- 在知识蒸馏中利用余弦相似度来有效地传递知识,减少额外的计算负担。
- 优化网络结构和损失函数,以减少计算资源的需求,同时保持或提高准确率。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 32
32 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)