如何基于yolov8训练并使用——监控视角下 车辆识别检测数据集 20500 class_ car, van, others, bus; 5类道路车辆检测数据集
·
车辆识别数据集
图片数量20500,模型已训练200轮;
class: car, van, others, bus;
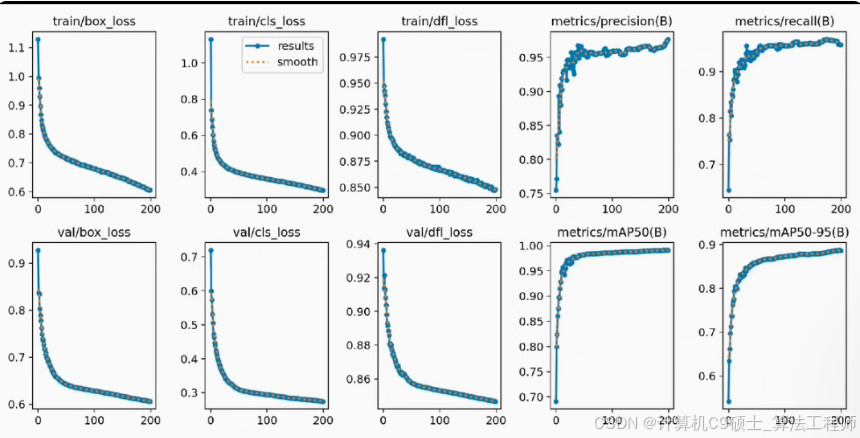
监控道路车辆识别数据集,并提供基于YOLOv8的训练代码。这个数据集包含20500张图像,标注了4类检测目标:car、van、others、bus。标注格式为YOLO格式,可以直接用于深度模型训练。
1. 数据集介绍
数据集目录结构
假设你的数据集已经准备好,并且分为训练集、验证集和测试集。数据集目录结构如下:
vehicle_detection_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
├── labels/
│ ├── train/
│ ├── val/
│ └── test/
└── data.yaml
数据集标注格式
YOLO格式的标注文件是TXT文件,每行表示一个目标,格式如下:
class_id center_x center_y width height
其中:
class_id是类别的索引(从0开始)。center_x和center_y是目标框中心点的归一化坐标。width和height是目标框宽度和高度的归一化值。
2. 数据集配置文件 (data.yaml)
创建一个data.yaml文件,配置数据集的路径和类别信息:
path: ./vehicle_detection_dataset # 数据集路径
train: images/train # 训练集图像路径
val: images/val # 验证集图像路径
test: images/test # 测试集图像路径
nc: 4 # 类别数
names:
- car
- van
- others
- bus
3. 训练脚本 (train.py)
由于模型已经训练了200轮,我们可以继续训练以进一步提升性能。
from ultralytics import YOLO
def train_model(data_yaml_path, model_path, epochs, batch_size, img_size, augment):
# 加载预训练模型
model = YOLO(model_path)
# 继续训练模型
results = model.train(
data=data_yaml_path,
epochs=epochs,
batch=batch_size,
imgsz=img_size,
augment=augment
)
# 保存模型
model.save("runs/train/vehicle_detection/best.pt")
if __name__ == "__main__":
data_yaml_path = 'vehicle_detection_dataset/data.yaml'
model_path = 'path_to_pretrained_model.pt' # 预训练模型路径
epochs = 100 # 继续训练的轮数
batch_size = 16
img_size = 640
augment = True
train_model(data_yaml_path, model_path, epochs, batch_size, img_size, augment)
4. 预测脚本 (predict.py)
import cv2
import torch
from ultralytics import YOLO
def predict_image(image_path, model_path, img_size=640):
# 加载模型
model = YOLO(model_path)
# 读取图像
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 进行预测
results = model(image_rgb, size=img_size)
# 处理预测结果
for result in results:
boxes = result.boxes.xyxy.cpu().numpy()
scores = result.boxes.conf.cpu().numpy()
labels = result.boxes.cls.cpu().numpy().astype(int)
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = map(int, box)
class_name = ['car', 'van', 'others', 'bus'][label]
color = (0, 255, 0) if label == 0 else (0, 0, 255)
cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)
cv2.putText(image, f'{class_name} {score:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, 2)
# 显示图像
cv2.imshow('Prediction', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
image_path = 'path_to_your_image.jpg'
model_path = 'runs/train/vehicle_detection/best.pt'
predict_image(image_path, model_path)
5. 运行脚本
-
继续训练模型:
python train.py -
进行预测:
python predict.py
6. 详细解释
数据集配置文件 (data.yaml)
path: 数据集的根目录路径。train: 训练集图像的路径。val: 验证集图像的路径。test: 测试集图像的路径。nc: 类别数。names: 类别名称列表。
训练脚本 (train.py)
-
导入依赖项:
from ultralytics import YOLO:导入YOLOv8模型。
-
定义训练函数:
train_model:加载预训练模型,设置训练参数,继续训练模型,并保存最佳模型。
-
主函数:
- 设置数据集路径、预训练模型路径、训练参数等。
- 调用
train_model函数进行训练。
预测脚本 (predict.py)
-
导入依赖项:
import cv2:导入OpenCV库。import torch:导入PyTorch库。from ultralytics import YOLO:导入YOLOv8模型。
-
定义预测函数:
predict_image:加载模型,读取图像,进行预测,处理预测结果,并显示带有标注的图像。
-
主函数:
- 设置图像路径和模型路径。
- 调用
predict_image函数进行预测。
7. 注意事项
- 数据集路径:确保数据集路径正确,特别是
data.yaml文件中的路径。 - 模型路径:确保预训练模型路径正确。
- 图像大小:
img_size可以根据实际需求调整,通常使用640或1280。 - 数据增强:
augment参数控制是否启用数据增强,可以在训练过程中提高模型的泛化能力。
8. 数据增强
为了增加数据集的多样性,可以使用数据增强技术。YOLOv8在训练过程中默认支持多种数据增强方法,如随机裁剪、翻转、颜色抖动等。如果需要自定义数据增强,可以参考YOLOv8的文档进行配置。
总结
通过以上步骤,你可以继续训练一个基于YOLOv8模型的车辆识别系统,并进行预测。train.py用于继续训练模型,predict.py用于加载训练好的模型并进行预测

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)