如何构建交通识别系统——并使用yolov8训练使用 交通道路识别数据集 红绿灯 数据集 汽车 行人自行车目标检测数据集 15000,xml和txt标签都有 9类 道路目标检测数据集

Udacity/交通识别数据集,图片数量15000,xml和txt标签都有;
YOL0交通识别
图片数量15000,xml 和txt标签都有;
class: biker, car, pedestrian, trafficLight, trafficLi ght-Green, traff i cLi ght -Gr eenLef
t,trafficLi ght -Red, trafficLi ght -RedLeft, trafficL ight -Yellow,trafficLight -Yel lowLeft
truck (也可按需求除去其中- -些类别)

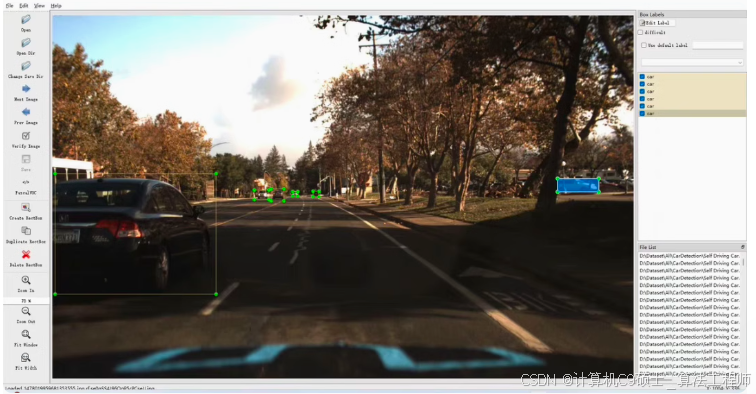

Udacity交通识别数据集,并提供基于YOLOv8的训练代码。这个数据集包含15000张图像,标注了10类检测目标。标注格式为YOLO格式和XML格式,可以直接用于深度模型训练。
1. 数据集介绍
数据集目录结构
假设你的数据集已经准备好,并且分为训练集、验证集和测试集。数据集目录结构如下:
udacity_traffic_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
├── labels_voc/
│ ├── train/
│ ├── val/
│ └── test/
├── labels_yolo/
│ ├── train/
│ ├── val/
│ └── test/
└── data.yaml
数据集标注格式
YOLO格式的标注文件是TXT文件,每行表示一个目标,格式如下:
class_id center_x center_y width height
其中:
class_id是类别的索引(从0开始)。center_x和center_y是目标框中心点的归一化坐标。width和height是目标框宽度和高度的归一化值。
2. 数据集配置文件 (data.yaml)
创建一个data.yaml文件,配置数据集的路径和类别信息:
path: ./udacity_traffic_dataset # 数据集路径
train: images/train # 训练集图像路径
val: images/val # 验证集图像路径
test: images/test # 测试集图像路径
nc: 10 # 类别数
names:
- biker
- car
- pedestrian
- trafficLight
- trafficLight-Green
- trafficLight-GreenLeft
- trafficLight-Red
- trafficLight-RedLeft
- trafficLight-Yellow
- trafficLight-YellowLeft
- truck # 如果需要去除某些类别,可以在这里删除相应的条目
3. 转换标注格式
假设标注文件是VOC格式的XML文件,我们需要将它们转换为YOLO格式的TXT文件。
转换脚本
import xml.etree.ElementTree as ET
import os
def convert_voc_to_yolo(voc_file, yolo_file, class_names):
tree = ET.parse(voc_file)
root = tree.getroot()
width = int(root.find('size/width').text)
height = int(root.find('size/height').text)
with open(yolo_file, 'w') as f:
for obj in root.findall('object'):
class_name = obj.find('name').text
if class_name not in class_names:
continue
class_id = class_names.index(class_name)
bbox = obj.find('bndbox')
x_min = float(bbox.find('xmin').text)
y_min = float(bbox.find('ymin').text)
x_max = float(bbox.find('xmax').text)
y_max = float(bbox.find('ymax').text)
x_center = (x_min + x_max) / 2.0 / width
y_center = (y_min + y_max) / 2.0 / height
w = (x_max - x_min) / width
h = (y_max - y_min) / height
f.write(f"{class_id} {x_center} {y_center} {w} {h}\n")
def convert_all_voc_to_yolo(voc_dir, yolo_dir, class_names):
os.makedirs(yolo_dir, exist_ok=True)
for filename in os.listdir(voc_dir):
if filename.endswith('.xml'):
voc_file = os.path.join(voc_dir, filename)
yolo_file = os.path.join(yolo_dir, filename.replace('.xml', '.txt'))
convert_voc_to_yolo(voc_file, yolo_file, class_names)
if __name__ == "__main__":
class_names = [
'biker',
'car',
'pedestrian',
'trafficLight',
'trafficLight-Green',
'trafficLight-GreenLeft',
'trafficLight-Red',
'trafficLight-RedLeft',
'trafficLight-Yellow',
'trafficLight-YellowLeft',
'truck' # 如果需要去除某些类别,可以在这里删除相应的条目
]
voc_train_dir = 'udacity_traffic_dataset/labels_voc/train'
yolo_train_dir = 'udacity_traffic_dataset/labels_yolo/train'
convert_all_voc_to_yolo(voc_train_dir, yolo_train_dir, class_names)
voc_val_dir = 'udacity_traffic_dataset/labels_voc/val'
yolo_val_dir = 'udacity_traffic_dataset/labels_yolo/val'
convert_all_voc_to_yolo(voc_val_dir, yolo_val_dir, class_names)
voc_test_dir = 'udacity_traffic_dataset/labels_voc/test'
yolo_test_dir = 'udacity_traffic_dataset/labels_yolo/test'
convert_all_voc_to_yolo(voc_test_dir, yolo_test_dir, class_names)
4. 训练脚本 (train.py)
from ultralytics import YOLO
def train_model(data_yaml_path, model_config, epochs, batch_size, img_size, augment):
# 加载模型
model = YOLO(model_config)
# 训练模型
results = model.train(
data=data_yaml_path,
epochs=epochs,
batch=batch_size,
imgsz=img_size,
augment=augment
)
# 保存模型
model.save("runs/train/udacity_traffic/best.pt")
if __name__ == "__main__":
data_yaml_path = 'udacity_traffic_dataset/data.yaml'
model_config = 'yolov8n.yaml' # 你可以选择不同的YOLOv8模型配置,如yolov8s.yaml, yolov8m.yaml等
epochs = 100
batch_size = 16
img_size = 640
augment = True
train_model(data_yaml_path, model_config, epochs, batch_size, img_size, augment)
5. 预测脚本 (predict.py)
import cv2
import torch
from ultralytics import YOLO
def predict_image(image_path, model_path, img_size=640):
# 加载模型
model = YOLO(model_path)
# 读取图像
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 进行预测
results = model(image_rgb, size=img_size)
# 处理预测结果
for result in results:
boxes = result.boxes.xyxy.cpu().numpy()
scores = result.boxes.conf.cpu().numpy()
labels = result.boxes.cls.cpu().numpy().astype(int)
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = map(int, box)
class_name = [
'biker',
'car',
'pedestrian',
'trafficLight',
'trafficLight-Green',
'trafficLight-GreenLeft',
'trafficLight-Red',
'trafficLight-RedLeft',
'trafficLight-Yellow',
'trafficLight-YellowLeft',
'truck'
][label]
color = (0, 255, 0) if label == 2 else (0, 0, 255)
cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)
cv2.putText(image, f'{class_name} {score:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, 2)
# 显示图像
cv2.imshow('Prediction', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == "__main__":
image_path = 'path_to_your_image.jpg'
model_path = 'runs/train/udacity_traffic/best.pt'
predict_image(image_path, model_path)
6. 运行脚本
-
转换标注格式:
python convert_voc_to_yolo.py -
训练模型:
python train.py -
进行预测:
python predict.py
7. 详细解释
转换标注格式脚本 (convert_voc_to_yolo.py)
-
导入依赖项:
import xml.etree.ElementTree as ET:导入XML解析库。import os:导入操作系统接口库。
-
定义转换函数:
convert_voc_to_yolo:将单个VOC格式的XML文件转换为YOLO格式的TXT文件。convert_all_voc_to_yolo:将指定目录下的所有VOC格式的XML文件转换为YOLO格式的TXT文件。
-
主函数:
- 设置类别名称和各个子集的路径。
- 调用
convert_all_voc_to_yolo函数进行转换。
训练脚本 (train.py)
-
导入依赖项:
from ultralytics import YOLO:导入YOLOv8模型。
-
定义训练函数:
train_model:加载模型,设置训练参数,训练模型,并保存最佳模型。
-
主函数:
- 设置数据集路径、模型配置、训练参数等。
- 调用
train_model函数进行训练。
预测脚本 (predict.py)
-
导入依赖项:
import cv2:导入OpenCV库。import torch:导入PyTorch库。from ultralytics import YOLO:导入YOLOv8模型。
-
定义预测函数:
predict_image:加载模型,读取图像,进行预测,处理预测结果,并显示带有标注的图像。
-
主函数:
- 设置图像路径和模型路径。
- 调用
predict_image函数进行预测。
8. 注意事项
- 数据集路径:确保数据集路径正确,特别是
data.yaml文件中的路径。 - 模型配置:可以选择不同的YOLOv8模型配置,如
yolov8s.yaml,yolov8m.yaml等,根据你的计算资源和需求选择合适的模型。 - 图像大小:
img_size可以根据实际需求调整,通常使用640或1280。 - 数据增强:
augment参数控制是否启用数据增强,可以在训练过程中提高模型的泛化能力。
9. 数据增强
为了增加数据集的多样性,可以使用数据增强技术。YOLOv8在训练过程中默认支持多种数据增强方法,如随机裁剪、翻转、颜色抖动等。如果需要自定义数据增强,可以参考YOLOv8的文档进行配置。
总结
通过以上步骤,你可以构建一个基于YOLOv8模型的Udacity交通识别系统。convert_voc_to_yolo.py用于将VOC格式的标注文件转换为YOLO格式,train.py用于训练模型,predict.py用于加载训练好的模型并进行预测。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)