VINS_Fusion_gpu运行时间测量
VINS_Fusion_gpu运行时间测量
最近在研究Vins_Fusion_gpu版本部署到Jetson Orin NX之后的加速效果,但网上搜了半天都是只有代码,没有任何的加速结果说明,没办法只能自己想办法来测量了。
有关VINS_Mono加速的相关资料,可以查看我的另一篇博客:VINS_MONO视觉导航算法【二】论文讲解+GPU实现调研。
有关ROS的相关知识,可以查看我的另一篇博客:VINS_MONO视觉导航算法【三】ROS基础知识介绍。
代码讲解
main()
在rosNodeTest.cpp的main函数中有这样两行代码:
std::thread sync_thread{sync_process};
ros::spin();
首先需要了解一些基础知识:
std::thread
解释
std::thread sync_thread{sync_process}; 这行代码的作用是创建一个新的线程,并在该线程上执行 sync_process 函数。以下是详细的解释:
-
std::thread:std::thread是 C++ 标准库中的一个类,用于创建和管理线程。- 它允许你在程序中并发地执行代码。
-
sync_process:sync_process是一个函数名,表示要在新线程中执行的函数。- 该函数必须是一个可调用对象(如普通函数、lambda 表达式、函数对象等),并且不能有返回值(除非你使用
std::async或其他机制来处理返回值)。
-
花括号初始化
{sync_process}:- 使用花括号初始化
std::thread对象是一种推荐的方式,可以避免最常见的一些编译器歧义问题(即“最 vexing parse”问题)。 - 确保传递给
std::thread的参数列表正确匹配目标函数的签名。
- 使用花括号初始化
示例场景
假设你有一个主线程负责其他任务,而希望在一个单独的线程中持续处理图像同步和特征提取。你可以这样做:
#include <iostream>
#include <thread>
// 假设 sync_process 是你要在线程中运行的函数
void sync_process()
{
while (1)
{
// 处理图像同步和特征提取的逻辑
std::cout << "Processing images..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟处理时间
}
}
int main()
{
// 创建一个新线程并在线程中运行 sync_process 函数
std::thread sync_thread{sync_process};
// 主线程继续执行其他任务
for (int i = 0; i < 5; ++i)
{
std::cout << "Main thread working..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟主任务时间
}
// 等待 sync_thread 结束(实际上 sync_thread 是无限循环)
sync_thread.join();
return 0;
}
-
创建线程:
std::thread sync_thread{sync_process};创建了一个新线程,并立即开始执行sync_process函数。
-
多线程执行:
- 主线程和
sync_thread可以并发执行不同的任务。 - 在这个示例中,主线程和
sync_thread分别打印不同的消息。
- 主线程和
-
等待线程结束:
sync_thread.join();用于等待sync_thread结束。如果没有这一步,主线程可能会在sync_thread仍在运行时提前退出,导致程序异常终止。- 注意:在这个示例中,
sync_process是一个无限循环,所以sync_thread.join()实际上不会被执行到。在实际应用中,你需要确保线程能够正常结束或提供适当的终止条件。
-
线程安全:
- 如果
sync_process和主线程共享资源,需要确保这些资源访问是线程安全的,通常通过互斥锁 (std::mutex) 或其他同步机制来实现。
- 如果
总结
std::thread sync_thread{sync_process}; 这行代码的作用是创建一个新的线程,并在该线程上执行 sync_process 函数。这种方式使得你可以在多线程环境中并发地执行不同的任务,从而提高程序的效率和响应性。
ros::spin() 函数
在ROS(Robot Operating System)中,ros::spin() 函数和回调函数是核心组件,用于处理消息订阅、服务请求等异步事件。下面详细解释这两个概念的工作原理以及它们如何与主线程交互。ros::spin() 是 ROS 提供的一个阻塞调用,用于进入一个循环,不断检查是否有新的消息到达,并调用相应的回调函数来处理这些消息。它的主要作用是保持节点活跃并响应来自其他节点的消息。
工作原理
-
初始化:
- 当你创建一个 ROS 节点并订阅了某些话题时,ROS 会在内部维护一个消息队列和回调队列。
- 每当有新消息到达某个订阅的话题时,消息会被放入相应的消息队列中。
-
进入循环:
- 调用
ros::spin()后,程序会进入一个无限循环,不断检查消息队列。 - 如果消息队列中有消息,则从队列中取出消息,并将其传递给相应的回调函数进行处理。
- 调用
-
回调函数调用:
- 回调函数是在订阅话题时注册的函数,负责处理接收到的消息。
ros::spin()会按照消息到达的顺序依次调用这些回调函数。
-
阻塞行为:
ros::spin()是一个阻塞调用,意味着它会一直运行,直到显式地调用ros::shutdown()或者程序被外部中断。
回调函数
在 ROS 2 中,回调函数是用于处理订阅的消息、服务请求等事件的函数。当你订阅一个话题时,ROS 会将该话题上的每条消息传递给指定的回调函数。回调函数的签名通常如下:
void callback(const std_msgs::msg::String::SharedPtr msg)
{
RCLCPP_INFO(this->get_logger(), "Received message: '%s'", msg->data.c_str());
}
每当有新的消息发布到你订阅的话题上时,ROS 会自动调用这个回调函数,并将消息作为参数传递给它。
示例代码
#include "ros/ros.h"
#include "std_msgs/String.h"
// 定义回调函数
void chatterCallback(const std_msgs::String::ConstPtr& msg)
{
ROS_INFO("I heard: [%s]", msg->data.c_str());
}
int main(int argc, char **argv)
{
// 初始化 ROS 系统
ros::init(argc, argv, "listener");
// 创建节点句柄
ros::NodeHandle n;
// 订阅名为 "chatter" 的话题,使用回调函数 chatterCallback 处理消息
ros::Subscriber sub = n.subscribe("chatter", 1000, chatterCallback);
// 进入循环,处理消息
ros::spin();
return 0;
}
多个回调函数
如果你订阅了多个话题,每个话题都有自己的回调函数,这些回调函数会在 ros::spin() 循环中按顺序调用。
当有多个订阅者(即多个回调函数)时,ROS 会根据消息的到达顺序来调用相应的回调函数。默认情况下,所有的回调函数都是在同一个线程中执行的(即主线程)。这意味着如果一个回调函数正在处理消息,其他回调函数必须等待它完成才能开始处理自己的消息。
回调函数的执行特点:
-
串行执行:默认情况下,所有回调函数都在主线程中排队执行。即使有多个消息同时到达,ROS 也会按照消息到达的顺序依次调用对应的回调函数。因此,如果某个回调函数执行时间较长,可能会导致其他回调函数被延迟。
-
单线程模型:默认使用单线程模型,这意味着所有回调函数都在同一个线程中执行。如果你希望多个回调函数能够并发执行,可以考虑使用多线程或多进程模型。
示例代码
#include "ros/ros.h"
#include "std_msgs/String.h"
void callback1(const std_msgs::String::ConstPtr& msg)
{
ROS_INFO("Callback 1: [%s]", msg->data.c_str());
}
void callback2(const std_msgs::String::ConstPtr& msg)
{
ROS_INFO("Callback 2: [%s]", msg->data.c_str());
}
int main(int argc, char **argv)
{
ros::init(argc, argv, "multi_listener");
ros::NodeHandle n;
ros::Subscriber sub1 = n.subscribe("topic1", 1000, callback1);
ros::Subscriber sub2 = n.subscribe("topic2", 1000, callback2);
ros::spin();
return 0;
}
并发多个回调函数
默认情况下,ROS 使用单线程模型来处理所有回调函数。这意味着所有的回调函数都在同一个线程中按顺序执行。如果需要并发处理多个回调函数,可以使用多线程模式。上文提到的std::thread就是其中的一种基于C++基本库的方式。
多线程模式
ROS 提供了几种多线程模式,可以通过 ros::MultiThreadedSpinner 来实现并发处理。
使用 ros::AsyncSpinner
ros::AsyncSpinner 允许你在后台线程中处理消息,从而避免阻塞主线程。
#include "ros/ros.h"
#include "std_msgs/String.h"
void callback1(const std_msgs::String::ConstPtr& msg)
{
ROS_INFO("Callback 1: [%s]", msg->data.c_str());
}
void callback2(const std_msgs::String::ConstPtr& msg)
{
ROS_INFO("Callback 2: [%s]", msg->data.c_str());
}
int main(int argc, char **argv)
{
ros::init(argc, argv, "multi_listener_async");
ros::NodeHandle n;
ros::Subscriber sub1 = n.subscribe("topic1", 1000, callback1);
ros::Subscriber sub2 = n.subscribe("topic2", 1000, callback2);
// 创建一个 AsyncSpinner,指定使用的线程数
ros::AsyncSpinner spinner(4); // 使用 4 个线程
// 开始处理消息
spinner.start();
// 主线程可以继续执行其他任务
while (ros::ok())
{
ROS_INFO("Main thread is doing other work...");
std::this_thread::sleep_for(std::chrono::seconds(1));
}
// 停止 spinner
spinner.stop();
return 0;
}
使用 ros::MultiThreadedSpinner
ros::MultiThreadedSpinner 类似于 ros::AsyncSpinner,但提供了更多的控制选项。
#include "ros/ros.h"
#include "std_msgs/String.h"
void callback1(const std_msgs::String::ConstPtr& msg)
{
ROS_INFO("Callback 1: [%s]", msg->data.c_str());
}
void callback2(const std_msgs::String::ConstPtr& msg)
{
ROS_INFO("Callback 2: [%s]", msg->data.c_str());
}
int main(int argc, char **argv)
{
ros::init(argc, argv, "multi_listener_multithreaded");
ros::NodeHandle n;
ros::Subscriber sub1 = n.subscribe("topic1", 1000, callback1);
ros::Subscriber sub2 = n.subscribe("topic2", 1000, callback2);
// 创建一个 MultiThreadedSpinner,指定使用的线程数
ros::MultiThreadedSpinner spinner(4); // 使用 4 个线程
// 开始处理消息
spinner.spin();
return 0;
}
总结
ros::spin():是一个阻塞调用,进入一个循环不断检查消息队列并调用相应的回调函数。- 回调函数:在订阅话题时注册的函数,由
ros::spin()自动调用来处理接收到的消息。 - 多个回调函数:在
ros::spin()中按顺序调用。 - 并发多个回调函数:通过使用
ros::AsyncSpinner或ros::MultiThreadedSpinner或std::thread可以实现多线程处理,允许多个回调函数并发执行。
通过这些机制,ROS 能够高效地处理多个消息流,并提供灵活的方式来管理并发任务。
main函数操作流程
首先通过std::thread创建一个新的线程,使其与主线程并行操作,运行sync_process()函数。而主线程则运行ros::spin()处理回调函数。
sync_process()
了解了main函数操作流程之后,就比较好加速了,sync_process()函数中主要是检测是否有图像,然后运行estimator.inputImage(time, image);。这是sync_process()函数的代码:
// extract images with same timestamp from two topics
void sync_process()
{
/**************************DZH TEST****************************/
#include <chrono>
std::chrono::duration<double> total_duration(0.0);
int loop_count = 0;
std::chrono::steady_clock::time_point current_loop_start;
std::chrono::steady_clock::time_point current_loop_end;
/**************************DZH TEST****************************/
while(1)
{
if(STEREO)
{
cv::Mat image0, image1;
std_msgs::Header header;
double time = 0;
m_buf.lock();
if (!img0_buf.empty() && !img1_buf.empty())
{
double time0 = img0_buf.front()->header.stamp.toSec();
double time1 = img1_buf.front()->header.stamp.toSec();
if(time0 < time1)
{
img0_buf.pop();
printf("throw img0\n");
}
else if(time0 > time1)
{
img1_buf.pop();
printf("throw img1\n");
}
else
{
time = img0_buf.front()->header.stamp.toSec();
header = img0_buf.front()->header;
image0 = getImageFromMsg(img0_buf.front());
img0_buf.pop();
image1 = getImageFromMsg(img1_buf.front());
img1_buf.pop();
//printf("find img0 and img1\n");
}
}
m_buf.unlock();
if(!image0.empty())
estimator.inputImage(time, image0, image1);
}
else
{
cv::Mat image;
std_msgs::Header header;
double time = 0;
m_buf.lock();
if(!img0_buf.empty())
{
time = img0_buf.front()->header.stamp.toSec();
header = img0_buf.front()->header;
image = getImageFromMsg(img0_buf.front());
img0_buf.pop();
}
m_buf.unlock();
if(!image.empty())
estimator.inputImage(time, image);
}
std::chrono::milliseconds dura(2);
std::this_thread::sleep_for(dura);
}
}
estimator.inputImage();
estimator.inputImage(time, image);函数中主要是进行特征点追踪和检测。这是estimator.inputImage();的代码:
void Estimator::inputImage(double t, const cv::Mat &_img, const cv::Mat &_img1)
{
// if(begin_time_count<=0)
inputImageCnt++;
map<int, vector<pair<int, Eigen::Matrix<double, 7, 1>>>> featureFrame;
// TicToc featureTrackerTime;
if(_img1.empty())
featureFrame = featureTracker.trackImage(t, _img);
else
featureFrame = featureTracker.trackImage(t, _img, _img1);
// if(begin_time_count--<=0)
// {
// sum_t_feature += featureTrackerTime.toc();
// printf("featureTracker time: %f\n", sum_t_feature/(float)inputImageCnt);
// }
if(MULTIPLE_THREAD)
{
if(inputImageCnt % 2 == 0)
{
mBuf.lock();
featureBuf.push(make_pair(t, featureFrame));
mBuf.unlock();
}
}
else
{
mBuf.lock();
featureBuf.push(make_pair(t, featureFrame));
mBuf.unlock();
TicToc processTime;
processMeasurements();
printf("process time: %f\n", processTime.toc());
}
}
其中featureTracker.trackImage()就是用来进行特征点追踪和检测的,打开feature_tracker.cpp105行就可以看到CUDA加速的代码了,就是在trackImage()函数里面。太长了这里就不贴出来了。
因此,VINS_Fusion_gpu中主要加速的部分实际上就是trackImage()函数,而trackImage()函数在estimator.inputImage();函数中。因此看GPU加速效果实际上就是统计estimator.inputImage();函数中trackImage()函数的加速效果。
加速代码
estimator.inputImage();
这是修改后的增加了测试时间的estimator.inputImage();函数代码,其中修改的部分都通过/**************************DZH TEST****************************/包括起来了:
/**************************DZH TEST****************************/
#include <chrono>
std::chrono::duration<double> total_duration(0.0);
int loop_count = 0;
/**************************DZH TEST****************************/
void Estimator::inputImage(double t, const cv::Mat &_img, const cv::Mat &_img1)
{
/**************************DZH TEST****************************/
std::chrono::steady_clock::time_point current_loop_start;
std::chrono::steady_clock::time_point current_loop_end;
/**************************DZH TEST****************************/
// if(begin_time_count<=0)
inputImageCnt++;
map<int, vector<pair<int, Eigen::Matrix<double, 7, 1>>>> featureFrame;
// // TicToc featureTrackerTime;
// if(_img1.empty())
// featureFrame = featureTracker.trackImage(t, _img);
// else
// featureFrame = featureTracker.trackImage(t, _img, _img1);
// // if(begin_time_count--<=0)
// // {
// // sum_t_feature += featureTrackerTime.toc();
// // printf("featureTracker time: %f\n", sum_t_feature/(float)inputImageCnt);
// // }
/**************************DZH TEST****************************/
current_loop_start = std::chrono::steady_clock::now();
if(_img1.empty())
featureFrame = featureTracker.trackImage(t, _img);
else
featureFrame = featureTracker.trackImage(t, _img, _img1);
current_loop_end = std::chrono::steady_clock::now();
// 计算当前循环的时间间隔
std::chrono::duration<double> elapsed_time = current_loop_end - current_loop_start;
// printf("================DZH_INFO: Loop interval: %f ms\n", elapsed_time.count() * 1000);
// 累加总时间间隔
total_duration += elapsed_time;
loop_count++;
// 打印平均时间间隔
if (loop_count % 50 == 0) // 每50次循环打印一次平均时间间隔
{
double average_time = total_duration.count() / loop_count * 1000;
printf("\n================DZH_INFO: Average trackImage loop interval over %d loops: %f ms\n\n", loop_count, average_time);
}
/**************************DZH TEST****************************/
if(MULTIPLE_THREAD)
{
if(inputImageCnt % 2 == 0)
{
mBuf.lock();
featureBuf.push(make_pair(t, featureFrame));
mBuf.unlock();
}
}
else
{
mBuf.lock();
featureBuf.push(make_pair(t, featureFrame));
mBuf.unlock();
TicToc processTime;
processMeasurements();
printf("process time: %f\n", processTime.toc());
}
}
该代码主要是基于C++ std::chrono库来实现计时的。修改完代码之后记得重新编译代码:
cd ~/catkin_ws/
catkin_make
另外,事实上,在VINS_Fusion代码中,原作者提供了TicToc类,也可以用于计时,其代码如下:
#pragma once
#include <ctime>
#include <cstdlib>
#include <chrono>
class TicToc
{
public:
TicToc()
{
tic();
}
void tic()
{
start = std::chrono::system_clock::now();
}
double toc()
{
end = std::chrono::system_clock::now();
std::chrono::duration<double> elapsed_seconds = end - start;
return elapsed_seconds.count() * 1000;
}
private:
std::chrono::time_point<std::chrono::system_clock> start, end;
};
可以看到,该类本质上也是基于std::chrono方式来计时的。没有实质上的差别,而且我们还需要统计一个总时间,这个类中并没有提供相应的功能,因此,在我的计时代码中是直接通过std::chrono方式来计时的,没有使用TicToc类。
Estimator::processMeasurements
为了统计Estimator::processMeasurements函数的平均运行时间,也为其添加了时间测量代码,同上。测量Estimator::processMeasurements函数是因为:在测试EuROC数据集时,作者让Estimator::processMeasurements和estimator.inputImage();这两个函数并行执行的,因此,算法最终的时间取决于运行时间最长的函数,其实也就是Estimator::processMeasurements函数,因此单独统计一下该函数的运行时间就可以知道总函数在多线程情况下的总运行时间了。
/**************************DZH TEST****************************/
std::chrono::duration<double> total_duration2(0.0);
int loop_count2 = 0;
/**************************DZH TEST****************************/
void Estimator::processMeasurements()
{
/**************************DZH TEST****************************/
std::chrono::steady_clock::time_point current_loop_start;
std::chrono::steady_clock::time_point current_loop_end;
/**************************DZH TEST****************************/
while (1)
{
//printf("process measurments\n");
TicToc t_process;
pair<double, map<int, vector<pair<int, Eigen::Matrix<double, 7, 1> > > > > feature;
vector<pair<double, Eigen::Vector3d>> accVector, gyrVector;
if(!featureBuf.empty())
{
/**************************DZH TEST****************************/
current_loop_start = std::chrono::steady_clock::now();
/**************************DZH TEST****************************/
feature = featureBuf.front();
curTime = feature.first + td;
while(1)
{
if ((!USE_IMU || IMUAvailable(feature.first + td)))
break;
else
{
printf("wait for imu ... \n");
if (! MULTIPLE_THREAD)
return;
std::chrono::milliseconds dura(5);
std::this_thread::sleep_for(dura);
}
}
mBuf.lock();
if(USE_IMU)
getIMUInterval(prevTime, curTime, accVector, gyrVector);
featureBuf.pop();
mBuf.unlock();
if(USE_IMU)
{
if(!initFirstPoseFlag)
initFirstIMUPose(accVector);
for(size_t i = 0; i < accVector.size(); i++)
{
double dt;
if(i == 0)
dt = accVector[i].first - prevTime;
else if (i == accVector.size() - 1)
dt = curTime - accVector[i - 1].first;
else
dt = accVector[i].first - accVector[i - 1].first;
processIMU(accVector[i].first, dt, accVector[i].second, gyrVector[i].second);
}
}
processImage(feature.second, feature.first);
prevTime = curTime;
printStatistics(*this, 0);
std_msgs::Header header;
header.frame_id = "world";
header.stamp = ros::Time(feature.first);
pubOdometry(*this, header);
pubKeyPoses(*this, header);
pubCameraPose(*this, header);
pubPointCloud(*this, header);
pubKeyframe(*this);
pubTF(*this, header);
printf("process measurement time: %f\n", t_process.toc());
/**************************DZH TEST****************************/
current_loop_end = std::chrono::steady_clock::now();
// 计算当前循环的时间间隔
std::chrono::duration<double> elapsed_time = current_loop_end - current_loop_start;
// printf("================DZH_INFO: Loop interval: %f ms\n", elapsed_time.count() * 1000);
// 累加总时间间隔
total_duration2 += elapsed_time;
loop_count2++;
// 打印平均时间间隔
if (loop_count2 % 50 == 0) // 每50次循环打印一次平均时间间隔
{
double average_time = total_duration2.count() / loop_count2 * 1000;
printf("\n================DZH_INFO: Average processMeasurements loop interval over %d loops: %f ms\n\n", loop_count2, average_time);
}
/**************************DZH TEST****************************/
}
if (! MULTIPLE_THREAD)
break;
std::chrono::milliseconds dura(2);
std::this_thread::sleep_for(dura);
}
}
加速结果
我在Jetson Orin NX 16G上运行了VINS_Fusion_gpu的加速代码,测试了EuROC MH_02_easy.bag数据集,并统计了开启GPU和不开启GPU的运行时间。
EuRoC数据集是微型飞行器(MAV)上收集的视觉惯性数据集,硬件设备如下:
- 飞行器机体:AscTec Firefly
- 双目VIO相机:全局快门,单色,相机频率20Hz,IMU频率200Hz,具备相机和IMU的硬件(hw)同步,双目相机型号MT9V034,IMU型号ADIS16448,图像分辨率为750 * 480
- VICON0:维肯动作捕捉系统的配套反射标志,叫做marker
- LEICA0:是激光追踪器配套的传感器棱镜,叫做prism
- Leica Nova MS50: 激光追踪器,测量棱镜prism的位置,毫米精度,帧率20Hz
- Vicon motion capture system: 维肯动作捕捉系统,提供在单一坐标系下的6D位姿测量,测量方式是通过在MAV上贴上一组反射标志,帧率100Hz,毫米精度
运行命令:
# 先测试通过GPU加速的代码,并将结果输出到log/time_gpu_euroc_02.log
roslaunch vins euroc.launch > log/time_gpu_euroc_02.log
rosbag play ~/catkin_ws/datasets/euroc/MH_02_easy.bag
# 修改euroc_stereo_imu_config.yaml
vim euroc_stereo_imu_config.yaml
# 修改不使用GPU
use_gpu: 0
use_gpu_acc_flow: 0
# 重新测试不通过GPU加速的代码,并将结果输出到log/time_nogpu_euroc_02.log
roslaunch vins euroc.launch > log/time_nogpu_euroc_02.log
rosbag play ~/catkin_ws/datasets/euroc/MH_02_easy.bag
结果如下,这是两种对比:
# 未开启GPU加速时的平均时长:
================DZH_INFO: Average trackIamge loop interval over 3000 loops: 30.851508 ms
# 开启GPU加速时的平均时长:
================DZH_INFO: Average trackIamge loop interval over 3000 loops: 21.232463 ms
可以看到特征追踪和提取的平均运行时间从30.85ms减少到了21.23ms。
性能提升
要计算开启 GPU 加速后相对于未开启 GPU 加速的速度提升,我们可以使用以下公式来计算加速比(Speedup Ratio)和性能提升的百分比。
1. 加速比 (Speedup Ratio)
加速比是指在相同任务下,未优化版本与优化版本(即开启 GPU 加速)的执行时间之比。公式如下:
加速比 = 未开启 GPU 加速的平均时长 开启 GPU 加速的平均时长 \text{加速比} = \frac{\text{未开启 GPU 加速的平均时长}}{\text{开启 GPU 加速的平均时长}} 加速比=开启 GPU 加速的平均时长未开启 GPU 加速的平均时长
根据你提供的数据:
- 未开启 GPU 加速时的平均时长:30.851508 ms
- 开启 GPU 加速时的平均时长:21.232463 ms
代入公式:
加速比 = 30.851508 21.232463 ≈ 1.45 \text{加速比} = \frac{30.851508}{21.232463} \approx 1.45 加速比=21.23246330.851508≈1.45
这意味着开启 GPU 加速后,程序的运行速度大约是未开启时的 1.45 倍。
2. 性能提升的百分比
性能提升的百分比可以通过以下公式计算:
性能提升百分比 = ( 1 − 开启 GPU 加速的平均时长 未开启 GPU 加速的平均时长 ) × 100 % \text{性能提升百分比} = \left(1 - \frac{\text{开启 GPU 加速的平均时长}}{\text{未开启 GPU 加速的平均时长}}\right) \times 100\% 性能提升百分比=(1−未开启 GPU 加速的平均时长开启 GPU 加速的平均时长)×100%
代入数据:
性能提升百分比 = ( 1 − 21.232463 30.851508 ) × 100 % ≈ 31.17 % \text{性能提升百分比} = \left(1 - \frac{21.232463}{30.851508}\right) \times 100\% \approx 31.17\% 性能提升百分比=(1−30.85150821.232463)×100%≈31.17%
这意味着开启 GPU 加速后,程序的性能提升了大约 31.17%。
3. 总结
- 加速比:1.45
- 性能提升百分比:31.17%
因此,开启 GPU 加速后,程序的运行速度提高了约 31.17%,或者说,程序的执行时间缩短了约 31.17%。
其他数据总结
trackImage函数加速结果对比
为了验证trackImage函数的加速效果,对EuROC的其他数据进行了对比,结果如下:
| MH_01_easy.bag | MH_02_easy.bag | MH_03_medium.bag | MH_04_difficult.bag | MH_05_difficult.bag | |
|---|---|---|---|---|---|
| GPU | 21.59 ms | 21.09 ms | 21.28 ms | 19.14 ms | 19.59 ms |
| NOGPU | 31.42 ms | 31.12 ms | 27.69 ms | 21.44 ms | 21.75 ms |
| MH_01_easy.bag | MH_02_easy.bag | MH_03_medium.bag | MH_04_difficult.bag | MH_05_difficult.bag | |
| 加速比 | 1.46 | 1.48 | 1.30 | 1.12 | 1.11 |
| 性能提升百分比 | 31.3% | 32.2% | 23.1% | 10.7% | 9.9% |
注:这里的数据是重新测量了的,所以和上文提到的数据有微小差异,但不影响。
总函数加速结果对比
此外,还对VINS_Fusion_gpu整个函数的加速效果进行了对比,注意,这里为了体现GPU的效果,将euroc_stereo_imu_config.yaml中的multiple_thread: 0设置为了0,使其串行计算。当multiple_thread: 1的时候,算法运行时长取决于Estimator::processMeasurements函数,该函数在VINS_Fusion_gpu代码中并没有进行GPU加速设计。
multiple_thread: 0
| MH_01_easy.bag | MH_02_easy.bag | MH_03_medium.bag | MH_04_difficult.bag | MH_05_difficult.bag | Average | |
|---|---|---|---|---|---|---|
| GPU | 90.70 ms | 86.01 ms | 83.81 ms | 63.56 ms | 65.45 ms | 77.9 ms |
| FPS | 11.0 | 11.6 | 11.9 | 15.7 | 15.3 | 13.1 |
| NOGPU | 98.64 ms | 98.12 ms | 93.41 ms | 71.71 ms | 70.44 ms | 86.5 ms |
| FPS | 10.1 | 10.2 | 10.7 | 13.9 | 14.2 | 11.8 |
| MH_01_easy.bag | MH_02_easy.bag | MH_03_medium.bag | MH_04_difficult.bag | MH_05_difficult.bag | Average | |
| 加速比 | 1.09 | 1.14 | 1.11 | 1.13 | 1.08 | 1.11 |
| 性能提升百分比 | 8.0% | 12.3% | 10.3% | 11.4% | 7.0% | 9.94% |
这里需要注意,当multiple_thread: 0设置为0的时候,算法得到的轨迹结果有些不太对劲,不太懂为什么,大概看一下运行时长即可。
这是不开并行线程时的结果:
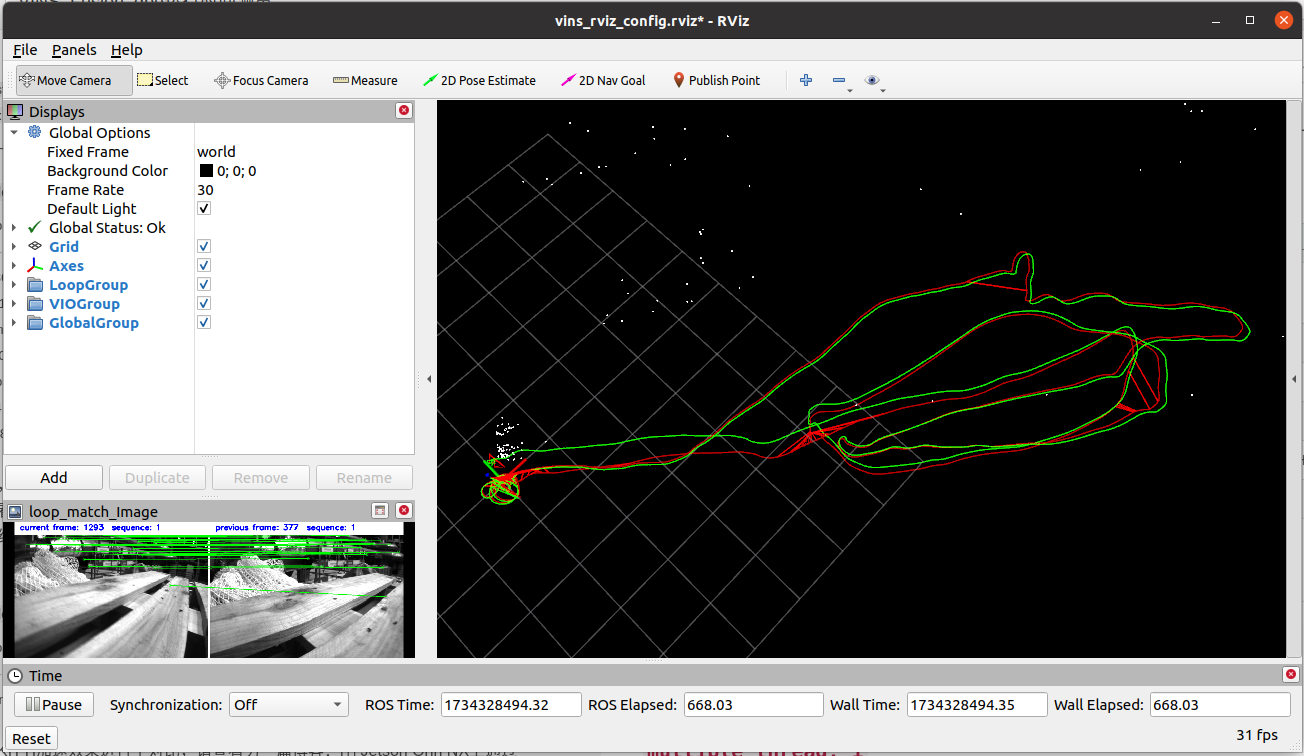
multiple_thread: 1
| MH_01_easy.bag | MH_02_easy.bag | MH_03_medium.bag | MH_04_difficult.bag | MH_05_difficult.bag | Average | |
|---|---|---|---|---|---|---|
| Multi-Thread Run Time (processMeasurements) | 68.68 ms | 64.54 ms | 62.19 ms | 44.17 ms | 45.60 ms | 57.0 ms |
| FPS | 14.6 | 15.5 | 16.1 | 22.6 | 21.9 | 18.1 |
这是开了并行线程时的结果: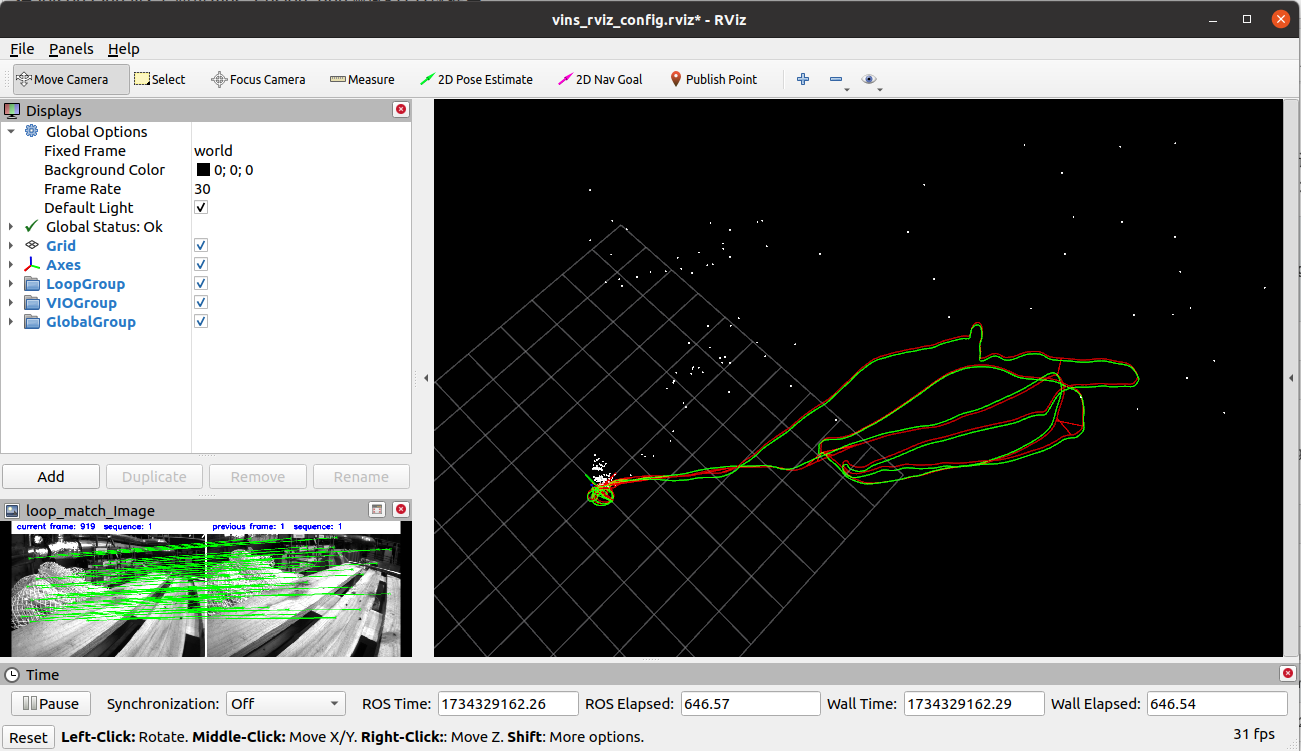 可以看到两者还是有些差别的。
可以看到两者还是有些差别的。
KITTI
另外,我还对KITTI加速效果进行了对比,请查看另一篇博客:在Jetson Orin NX上通过Vins_Fusion_gpu测试KITTI数据集。
GPU占用率
GPU占用率通过jtop工具来粗略查看,在terminal中输入jtop查看程序运行时的GPU占用率,有关jtop按键2闪退问题,请查看我的另一篇博客:Jetson Orin NX部署Vins_Fusion_gpu遇到的问题记录。
以下是不使用GPU加速程序时的GPU利用率:
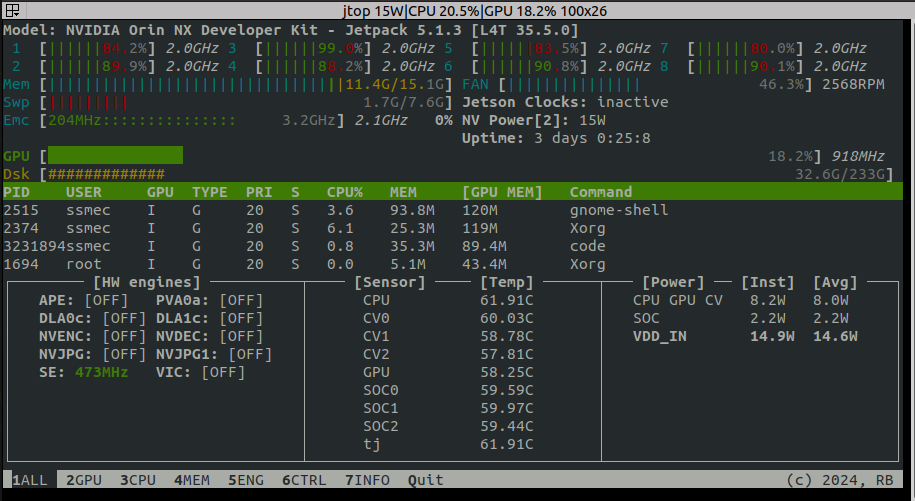
可以看到程序运行时GPU利用率和平时利用率差不多,这里利用率达到了18%是因为GNOME和Xorg图形界面在使用。
使用GPU加速程序时的GPU利用率:
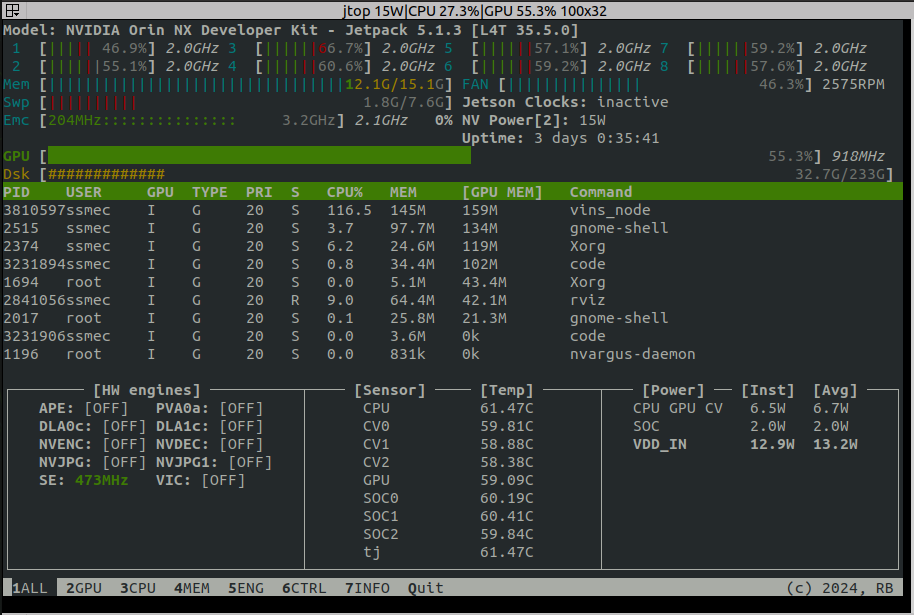
可以看到开启GPU加速算法后GPU利用率达到了55%,从下面的进程使用也可以看到vins_node占用了159M的GPU MEM。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)