使用python解析大疆的.srt文件
python解析.SRT文件
·
使用python脚本对.SRT文件进行解析,获取对应的POS信息,无需安装DJI Assistant。
from datetime import datetime
import re
def clean_datetime_string(date_time_str):
# 使用正则表达式去除非时间字符(例如:HTML 标签)
cleaned_str = re.sub(r'<.*?>', '', date_time_str) # 去掉所有HTML标签
return cleaned_str.strip() # 去除两端空格
def convert_to_record_time(date_time_str):
# 清理时间字符串
date_time_str = clean_datetime_string(date_time_str)
# 将清理后的时间字符串转换为datetime对象
try:
dt = datetime.strptime(date_time_str, "%Y-%m-%d %H:%M:%S.%f")
# 格式化为RecordTime=YYYY-MM-DD-HH-MM-SS-SSS
record_time = dt.strftime("%Y-%m-%d-%H-%M-%S-%f")[:-3] # 去除微秒的后三位,保留毫秒
return f"RecordTime={record_time}"
except ValueError as e:
print(f"Error parsing datetime string: {e}")
return None
def write_record_time_to_txt(relative_time_ms,date_time_str, output_file):
record_time = convert_to_record_time(date_time_str)
with open(output_file, 'w') as file:
file.write(f"RecordRelativeTimeMS={relative_time_ms}\n")
file.write(f"{record_time}")
# 读取SRT文件
def read_srt_file(file_path):
with open(file_path, 'r') as file:
return file.readlines()
'''遍历每组数据'''
# 读取SRT数据并提取每5行一组的所需字段
def process_srt_data(srt_lines):
extracted_data = []
'''这里为相对时间,可以自由设定'''
relative_time_ms = 1527169.273
info_txt_path = r"your path.info.txt"
initial_time_str = srt_lines[3]
print(srt_lines[0])
print(srt_lines[1])
print(srt_lines[2])
print(srt_lines[3])
print(srt_lines[4])
write_record_time_to_txt(relative_time_ms,srt_lines[3],info_txt_path)
# 遍历每6行数据作为一组
for i in range(0, len(srt_lines), 6):
group = srt_lines[i:i + 6]
# 确保当前组包含完整的6行数据(前5行为内容,第6行为空格)
if len(group) == 6:
group_data = parse_srt_group(relative_time_ms,initial_time_str,group)
extracted_data.append(group_data)
return extracted_data
def calculate_time_diff(relative_time_ms,initial_time_str, current_time_str):
"""
计算两个时间字符串之间的时间差(毫秒)
:param initial_time_str: 初始时间字符串,格式为 "YYYY-MM-DD HH:MM:SS.sss"
:param current_time_str: 当前时间字符串,格式为 "YYYY-MM-DD HH:MM:SS.sss"
:return: 返回时间差(以毫秒为单位)
"""
# 确保时间字符串没有额外的字符
initial_time_str = initial_time_str.split()[0] + ' ' + initial_time_str.split()[1]
current_time_str = current_time_str.split()[0] + ' ' + current_time_str.split()[1]
# print(initial_time_str,current_time_str)
# 时间字符串转换为datetime对象
initial_time = datetime.strptime(initial_time_str, "%Y-%m-%d %H:%M:%S.%f")
current_time = datetime.strptime(current_time_str, "%Y-%m-%d %H:%M:%S.%f")
# 计算时间差
time_diff = current_time - initial_time
# 将时间差转换为毫秒
time_diff_ms = time_diff.total_seconds() * 1000
relative_time_diff_ms = relative_time_ms + time_diff_ms
return relative_time_diff_ms
def clean_html_tags(text):
# 使用正则表达式去除HTML标签
return re.sub(r'<.*?>', '', text).strip()
# 从每组数据提取所需的信息
def parse_srt_group(relative_time_ms,initial_time_str,group_lines):
output_file = r'your path.pos.txt'
# 提取时间戳
timestamp = clean_datetime_string(group_lines[3]) # 第四行包含时间
# print(timestamp)
relative_time_diff_ms = calculate_time_diff(relative_time_ms,initial_time_str,timestamp)
# print(relative_time_diff_ms)
# 清理HTML标签
clean_line = clean_html_tags(group_lines[4])
# 提取位置信息
# 提取位置信息
location_info = re.search(r"\[latitude:\s*([-\d.]+)\]\s*\[longitude:\s*([-\d.]+)\]", clean_line)
# print(location_info)
latitude = location_info.group(1) if location_info else "N/A"
longitude = location_info.group(2) if location_info else "N/A"
# print(clean_line)
# 提取高度信息(考虑到可能的 abs_alt 字段)
# 提取高度信息(包含rel_alt和abs_alt)
# rel_alt_match = re.search(r"\[rel_alt:\s*([-\d.]+)\]\s*abs_alt:\s*([-\d.]+)", clean_line)
rel_alt_match = re.search(r"\[rel_alt:\s*([-\d.]+)\s*abs_alt:\s*([-\d.]+)\]", clean_line)
rel_alt = rel_alt_match.group(1) if rel_alt_match else "N/A"
# print(rel_alt)
abs_alt = rel_alt_match.group(2) if rel_alt_match else "N/A"
# 提取姿态信息
gb_yaw_pitch_roll_match = re.search(r"\[gb_yaw:\s*([-\d.]+)\s*gb_pitch:\s*([-\d.]+)\s*gb_roll:\s*([-\d.]+)\]",
clean_line)
# print("gb_yaw_pitch_roll_match",gb_yaw_pitch_roll_match)
# 如果找到匹配项,提取每个值
if gb_yaw_pitch_roll_match:
gb_yaw = gb_yaw_pitch_roll_match.group(1)
gb_pitch = gb_yaw_pitch_roll_match.group(2)
gb_roll = gb_yaw_pitch_roll_match.group(3)
else:
gb_yaw = gb_pitch = gb_roll = "N/A"
last_data = 1
# 写入TXT文件,每组数据写一行
with open(output_file, 'a') as file:
file.write(f"{relative_time_diff_ms} {latitude} {longitude} {rel_alt} {gb_roll} {gb_yaw} {gb_pitch} {last_data}\n")
# 主函数:读取文件、解析数据,保存为txt
def main():
# 设置SRT文件路径
srt_file_path = r'your path.SRT' # 请替换为实际的SRT文件路径
# 读取SRT文件内容
srt_lines = read_srt_file(srt_file_path)
# 解析文件中的时间戳、飞行姿态、经纬度坐标等信息
# timestamps, gps_coordinates = parse_srt_lines(srt_lines)
exp_data = process_srt_data(srt_lines)
if __name__ == '__main__':
main()
因为工作的需求,我将.srt内容解析为txt文件:
1).info.txt文件的内容:
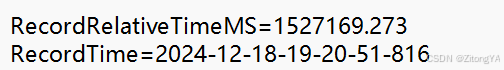
2).pos.txt文件的内容:
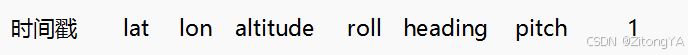

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)