工业大数据分析算法实战-day13
文章目录
day13
今天是第13天,昨日是针对时序分解、时序分割、时序再表征进行阐述,时序分解主要是提取单维度时序数据上的趋势、周期,而对其单独做下游任务比如单独预测等,时序分割多半则用于变点检测,分割不同工况,使其不同工况数据分布单独判断,时序再表征多半的用处是将其提取出主要特征,避免数据量过多,杂糅过多。今日主要是针对时间序列剩余的挖掘算法:序列模式挖掘、时序异常检测、时序聚类、时序分类、时序预测进行阐述
序列模式挖掘
序列模式主要是用来挖掘出时序中的频繁模式,在长序列中发现其常见的子序列,在业务分析上,可用来发现故障与之前的异常征兆的关系,辅助故障预警,或者可以用其发现同一故障引起的多点关联报警,消除告警风暴。频繁模式分为两类:数值型频繁模式(用来发现长时序中经常出现的模式,比如在一段平稳数据中不经常出现的异常模式)和符号型频繁模式(常用来分析事件间的时序关系或刻画不同事件的传播规律)。为了符合时序模式挖掘算法要求的事项序列格式,长时序过程可以通过滑动窗口和离散化变换除事项序列。
数值型频繁模式
数值型频繁模式用于从含有数值数据的序列中发现频繁模式。其主要目的是发现长时间序列中经常出现的模式,尤其是那些在某段时间内出现的异常模式。从连续的数值型数据中挖掘出规律。例如,可以帮助发现某些数值模式或趋势在长期数据中频繁出现,或者在某些条件下出现异常。这类模式通常用于分析长期数据中的特定行为,如金融市场、气象数据、健康监测等。
主要算法:
- SAX(Symbolic Aggregate approXimation)算法
- 核心功能:SAX算法的核心功能是将连续的数值时间序列转化为符号序列,从而降低数据的维度,方便后续的模式挖掘。通过将数值数据归一化并分段,用离散的符号表示这些数值,SAX能够有效压缩数据量并保持序列的主要趋势。
- 算法流程:
- 对时间序列进行归一化处理,确保所有数据在相同的尺度上。
- 将时间序列划分为多个等长的子序列。
- 每个子序列计算其平均值,并根据预定义的符号化规则(如分段阈值)将这些平均值映射为符号。
- 通过符号化后得到的符号序列来进行频繁模式的挖掘。
- 最后通过关联规则等方式识别频繁模式。
- Moen算法
- 核心功能:Moen算法针对数值型序列中的频繁模式进行了优化,特别适用于寻找在连续数值序列中出现的频繁趋势。该算法能够处理变化较大的数据并从中提取出稳定的模式。
- 算法流程:
- 对数值型数据进行平滑和去噪处理,消除数据中的噪音。
- 通过窗口滑动的方式对序列进行分段。
- 在每个窗口中识别出稳定的数值模式,并根据相似性度量筛选出频繁出现的模式。
- 最后,使用频繁模式挖掘算法(如Apriori或FP-Growth)对模式进行进一步提取和分析。
符号型频繁模式
符号型频繁模式侧重于发现离散事件或符号之间的时序关系。它主要用于分析事件间的时间顺序或刻画不同事件的传播规律。在实际应用中,这类模式常用于市场篮分析、网络流量分析、社交网络中的事件传播等。挖掘事件之间的关系和时间顺序,这些关系可以帮助分析事件的发生频率、关联性以及传播趋势。符号型数据通常表示为离散的事件序列(如“购买”、“浏览”、“点击”)。
主要算法
- 点序列模式(Point Sequence Patterns)
- 核心功能:点序列模式专注于发现时间序列中的频繁事件发生点,即特定事件发生的时刻或位置。其重点在于识别不同行为或事件的时序关系。
- 算法流程:
- 将时间序列中的事件转化为点序列,每个点表示一个事件发生的时间戳。
- 使用类似Apriori算法的频繁项集挖掘方法,识别出频繁的事件点组合。
- 对这些频繁点序列进行分析,提取出有意义的时序模式。
- 根据时序模式进一步分析事件的传播路径和规律。
- 区间序列模式(Interval Sequence Patterns)
- 核心功能:区间序列模式旨在识别事件在时间区间内的关系。这类模式不仅关注事件的发生时刻,还特别关注事件之间的时间间隔。
- 算法流程:
- 对事件序列进行预处理,标记事件的起始时间和结束时间,并计算事件之间的时间间隔。
- 将事件及其时间区间映射到符号序列中,转换为离散的时序数据。
- 利用频繁模式挖掘算法(如Apriori或FP-Growth),识别出在时间区间内频繁发生的模式。
- 对识别出的区间序列模式进行评估,挖掘出具有高关联性的事件及其传播规律。
时序异常检测
异常检测是为了识别除正常时序中不正常的事件/行为过程,从表现形式上分为3类:
- 点异常:单点与群体的偏离,一般称呼离群点/孤立点/异常值,通常会根据概率分布、密度、聚类等方式,这和一般数据集上的离群点检测没有区别
- 上下文异常:是指局部序列中的不一致(突然的上升/下降/毛刺),通常根据时序连续性/光滑时序模态、生成模型等方法研判
- 集合异常:是指子序列的模态在全局规律上的异常,通常基于子序列频繁模式等方法
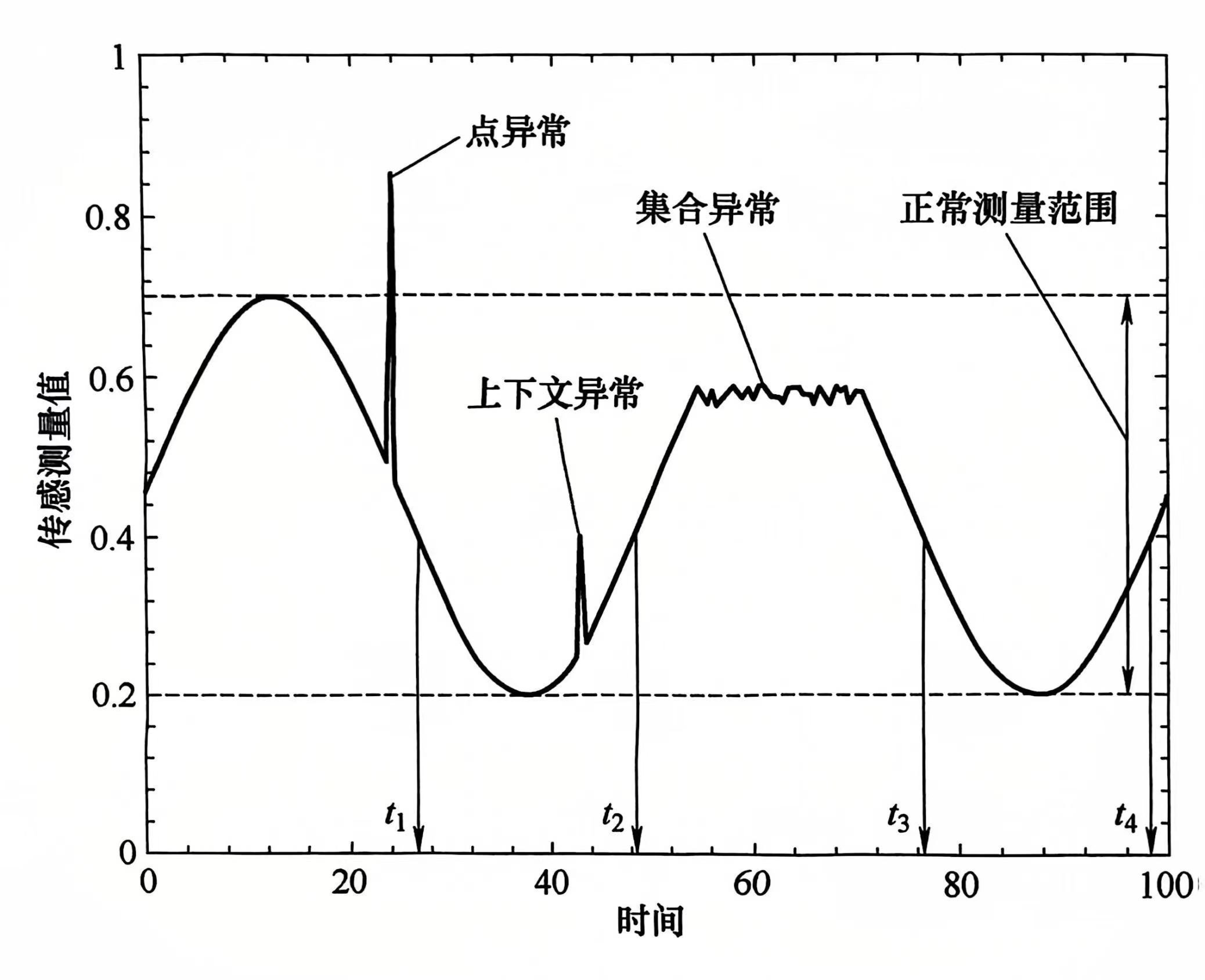
大部分时序异常检测都属于非监督问题,通常会采用:基于度量(统计量或者相似度)的方法、基于模型重构的方法、基于频繁模式挖掘的方法
基于度量的方法
基于度量的方法通常通过计算时间序列的统计特征、距离度量或密度评估,来判断是否存在异常。
- 基于统计量的方法: 这种方法主要是通过时间序列中的统计特性(如均值、方差、偏度、峰度等)来检测异常。如果某些时刻的统计量与历史序列的分布差异较大,就可以被视为异常。常见的统计检测方法包括基于滑动窗口的标准差判别、Z-score分析等。
- 基于距离的方法: 该方法通过度量不同时间点或时间窗口之间的距离来判断异常。常用的距离度量方法有欧几里得距离、曼哈顿距离、动态时间规整(DTW)等。如果某个点或时间窗口与其他时间段的距离远大于预设的阈值,就会被认为是异常点。此方法特别适用于具有局部相似性的时序数据。
- 基于密度的方法: 基于密度的异常检测方法认为,正常的时间序列数据点通常会出现在密度较高的区域,而异常点则会位于密度较低的区域。常用的密度方法有LOF(局部异常因子)和k-NN(k近邻)算法。通过评估数据点的局部密度,判断其是否为异常。
- 基于聚类的方法: 聚类方法将时间序列数据划分成多个簇,通常同一簇内的数据点具有相似性,而簇与簇之间的差异较大。常见的聚类算法有K-means、DBSCAN(基于密度的空间聚类算法)等。通过检查一个数据点是否属于某个较小的、密度较低的簇,来判断其是否为异常点。
基于模型重构的方法
基于模型重构的方法通过构建适当的模型(如自回归模型、神经网络等)对时序数据进行拟合和重构,异常通常表现为模型无法准确预测的点。
-
平稳序列的自回归模型(AR、ARMA、ARIMA): 对于平稳时间序列,常使用自回归(AR)模型、移动平均(MA)模型或自回归滑动平均(ARMA)模型。通过这些模型对时间序列进行建模,预测某时刻的值,并计算实际值与预测值之间的误差。如果误差超过某个阈值,则该点被判定为异常。
-
非平稳过程: 对于非平稳序列,首先需要对数据进行差分或其他转换(之前提到的时序分解),以使其平稳化。然后可以应用更复杂的模型进行异常检测。
- 隐马尔可夫模型(HMM): 隐马尔可夫模型特别适用于带有潜在状态变化的时间序列。通过HMM建模时间序列的状态转移过程,并利用最大似然估计方法对模型进行训练,检测与预期状态转移规律不符的点或段作为异常。
- 自编码器(Auto-Encoder,AE): 自编码器是一种神经网络结构,通常用于无监督学习中的数据压缩与特征提取。对于时间序列数据,通过自编码器重构输入数据,计算重构误差。如果某个时间点的重构误差显著高于其他点,则该点可以被认为是异常。
- 变分自编码器(VAE): 变分自编码器是一种生成模型,其主要目的是通过学习数据的潜在分布来生成数据。与自编码器相比,VAE通过引入变分推理,能够更好地处理复杂数据的生成。对于时序数据,VAE通过生成模型学习数据的潜在特征,利用重构误差进行异常检测。
基于频繁模式挖掘的方法
基于频繁模式挖掘的方法通过挖掘数据中常见的模式,并根据这些模式来识别异常。
- HOT-SAX算法: HOT-SAX(High Order Template Shapelets-based Algorithm for Time Series Anomaly Detection)是一种基于高阶模板的时序异常检测算法。通过挖掘时间序列中具有代表性的子序列(即形状模板),并评估其与整个序列的相似度来识别异常点。
- RRA算法(Recurrence-based Anomaly Detection Algorithm): RRA(基于重现性的异常检测算法)方法利用时间序列的重现性(即数据的周期性)来检测异常。通过对时间序列进行重现性矩阵的构建,分析时间序列中自相似的模式与不一致的模式,从而发现异常。
时序聚类
时序聚类的关键点在于时序相似度/距离,之后再用通用聚类算法进行聚类。本次仅阐述:DTW距离、SAX距离
DTW距离
核心功能:DTW 距离是一种衡量两个时间序列相似度的方法,特别适用于时间序列的对比,即使这两个序列的时间轴不同步、长度不同,DTW 也能够计算出它们之间的相似性。其核心思想是通过非线性地对齐(“拉伸”或“压缩”时间轴),让两个序列尽可能匹配,从而找到它们之间的最小差异。
算法流程:
- 构建距离矩阵:首先,计算两个时间序列(例如序列A和序列B)对应位置上的元素差异(通常是欧几里得距离)。假设序列A的长度是n,序列B的长度是m,那么就有一个大小为 n × m 的矩阵,其中每个元素表示 A 和 B 在对应位置上的差异。
- 动态规划:然后,利用动态规划(DP)算法计算从矩阵的左上角(A[1]和B[1])到右下角(A[n]和B[m])的最短路径。具体做法是,从矩阵的每个单元格开始,选择最小的路径(可以是上、左或斜着过来的),累积前面的最小值,最终到达矩阵的右下角。
- 计算DTW距离:路径上的每一步代表了从A和B中的某个元素匹配的一步。最终,矩阵的右下角的值就是两个时间序列的DTW距离,即它们的相似度。
举例:假设有两个时间序列:
- A: [1, 3, 4, 9, 8]
- B: [1, 2, 3, 4, 8]
DTW会将A和B按时间轴拉伸或压缩,使得它们之间的匹配误差最小化,从而计算出一个综合的距离值。
SAX距离
核心功能:SAX是一种将时间序列转化为符号序列的技术。它通过将时间序列的每个区间用符号表示来简化计算和比较,主要用于大规模时间序列数据的分析。SAX 先将时间序列转换成符号表示,然后通过比较符号序列之间的相似度来计算距离。
算法流程:
- 标准化时间序列:首先,对时间序列进行标准化处理(比如减去均值,除以标准差),使得数据范围保持一致,便于后续分析。
- 划分时间窗口:然后,将时间序列划分为多个小窗口,并计算每个窗口的平均值。每个窗口的平均值代表了该窗口内的时间序列行为。
- 映射到符号空间:接下来,通过将这些平均值映射到预定义的符号集。例如,如果将时间序列划分为5个符号(A, B, C, D, E),每个时间段的平均值可以被分配到这些符号中的一个。通常,这个映射是通过将均值与预定的分位数(如正态分布的分位数)进行比较来完成的。
- 计算SAX距离:一旦得到了符号化的时间序列,就可以通过比较这些符号序列之间的编辑距离、汉明距离等来计算它们之间的相似度(即SAX距离)。
举个例子:假设时间序列有如下数据:
- A: [1.1, 1.4, 1.2, 1.6, 1.9, 2.0, 2.1, 2.2]
- 标准化:假设标准化后得到的是:[0.1, 0.4, 0.2, 0.6, 0.9, 1.0, 1.1, 1.2]。
- 划分窗口:将其分成两个窗口:[0.1, 0.4, 0.2] 和 [0.6, 0.9, 1.0],每个窗口的平均值分别是 0.23 和 0.85。
- 映射符号:假设定义的符号为 5 个,均值小于 0.3的是符号 A,大于 0.8的是符号 E,中间的可以对应 B, C, D 等。因此 0.23 对应 A,0.85 对应 E,符号序列为 [A, E]。
- 计算距离:如果另一个时间序列的符号序列是 [B, E],那么它们的SAX距离可以通过计算符号之间的差异来获得。
时序分类
时序分类通常用于设备异常类型识别、工况状态识别等场景,一般会有2种技术路线去做:
- 用时序再表征提供特征,结合经典的分类算法
- 端到端的深度学习方法,都有相对成熟的技术。在工业实际应用中最大的挑战还是缺乏大量有标签的时序数据
经典分析算法
处理连续点的分类问题通过3个思路
- 滑动窗口提取长序列的特征,形成数据集,将连续序列点转换为经典的分类问题,就是通过滑动窗口进行特征加工,短序列需要特征加工
- 通过滑动窗口将长序列切分若干短序列,将连续点分类问题转换为短序列分类问题,直接灌入短序列
- 刻画时序结构模型,在时序模型的参数空间或预测结果空间上进行分类
处理短序列分类问题通常使用时序再表征、聚类、特征提取等方法将原始序列转换为特征向量,再应用通用的分类算法建模。在短序列分类上DTW距离+KNN分类器认为是一个较好的组合,有代表性的有COTE算法和改进的HIVE-COTE
- COTE(Combination of Transformation Ensembles)是一种集成方法,它通过组合多个变换算法(如DTW、傅里叶变换、PAA等)来处理时序数据的分类问题。HIVE-COTE是COTE的改进版本,通过多层次的组合和变换来提高分类准确度。
深度学习的方法
| 算法 | 核心功能 | 通俗易懂的解释 |
|---|---|---|
| 多层感知机 (MLP) | 使用多层全连接层学习数据中的模式。 | 就像是一个多层的“筛子”,它会把输入的每一段数据层层筛选、加工,最后给出一个分类结果。每一层处理的数据会越来越“抽象”,但不太能记住时间顺序。 |
| 全卷积网络 (FCN) | 使用卷积层自动提取特征,减少人工干预。 | 想象一下你在时间序列上滚动一块“滤镜”,它能自动抓取序列中的重要模式。无需手动提取特征,网络自己能从数据中学到哪些部分很重要。 |
| ResNet (残差网络) | 通过“跳跃连接”帮助深层网络学习更好的特征,避免信息丢失。 | 就像在学习时,直接跳过一些冗长或重复的部分,专注于关键内容。这样网络能学到更多信息,特别是在面对非常复杂的数据时,效果会更好。 |
| 编码器 (Encoder) | 将输入的数据压缩成更简洁的表示,用于提取关键信息。 | 想象你用一段时间序列做一个“摘要”,把长长的内容浓缩成几个关键词。通过这些关键词,网络能够抓住最重要的信息,而不必每次都处理所有细节。 |
| 多尺度卷积神经网络 (MCNN) | 在多个不同的尺度上提取时序特征,适合处理具有不同时间特征的数据。 | 就像用不同大小的镜头看一个物体,通过大镜头看到整体,通过小镜头看到细节。MCNN可以同时关注时序数据的长远趋势和短期波动,让它对不同的时间模式都有敏感性。 |
| Time Le-Net (t-LeNet) | 基于LeNet架构的卷积网络,专门处理时序数据。 | LeNet原本用于图像识别,t-LeNet改进后用于时序数据,就像把图像处理的技巧拿来专门用在时间序列数据上,快速找到时间序列中的重要部分,做分类。 |
| 多通道卷积网络 (MCDCNN) | 同时处理多个不同来源的时序数据,比如不同传感器的数据。 | 就像你同时看多个视频,分别展示不同的内容,MCDCNN能同时处理多个来源的时间序列数据,全面理解数据的全貌。它可以将来自不同渠道的数据合并起来,得出更准确的分类结果。 |
| 时间卷积神经网络 (Time-CNN) | 使用卷积操作从时间序列中提取局部特征,避免传统RNN中的梯度消失问题。 | 就像你在时间序列中滑动一块小窗口,逐步捕捉其中的信息,而不是一次性全部处理。这样可以避免在很长的时间序列中,信息丢失或变得模糊。 |
| 回声状态网络(TWIESN) | 通过引入时间扭曲不变性,适应复杂且变化多样的时序数据。 | 就像在面对一些扭曲或变形的时间数据时,网络能“识别”这些变化并依然正确理解它们。TWIESN帮助模型应对这些“扭曲”的变化,使它在处理不规则数据时也能表现出色。 |
时序预测
时序预测在工业上主要有3种场景
- 生产经营活动相关的预测,例如备件销售预测、价格预测,这些预测背后有很强的周期性和空间差异性,当然也存在外部驱动/指标因素
- 软测量,根据系统运行机理,用一些容易连续获取的指标去估算另外一些不易获取的关键指标。例如某个量和另外一个量有较强的相关性,当前量测量不到可以用另外一个量估算
- 基于复杂关系的预测,例如失效风险预测、质量水平检测,相当于第1类,目标变量本身不存在很强的周期性,需要根据预测变量子序列模式或特征拟合来预测
基于时序分解的预测算法
- Prophet算法: 是由 Facebook 开发的一个时间序列预测工具,它专为包含趋势变化和季节性成分的时序数据设计。Prophet 适合处理具有季节性、节假日效应、趋势变化等特点的数据,且能够适应较长的时间跨度。它通过一种基于加法模型的分解方法来处理时间序列数据。Prophet 通过将时间序列拆解成以下几部分来进行建模:
- 趋势(Trend):描述时间序列中长期变化的成分,可以是线性或逻辑斯蒂增长。趋势部分可以随时间变化,并且能够适应趋势的变化(如增长的加速或减缓)。
- 季节性(Seasonality):描述周期性波动的成分,通常是日、周、年等季节性波动。
- 假日效应(Holiday Effects):考虑特定节假日对时间序列的影响。
- 误差项(Error):即模型无法解释的随机波动。
- 时序预测特殊场景处理方法:
- 离群点影响:可以采用时序点异常识别并修正
- 事件的短期影响:1、采用正常的方法做中期预测;2、在短期上,采用子序列聚类/平均,按比例估算短期数值
- 事件的变迁性影响:需要根据实际的业务,看过去的模型或特征在多大程度可以复用
基于回归建模的预测算法
很多预测的问题可以转换为一般的回归建模问题,将待预测量作为目标量,将当前时刻和过去一段时间的相关量、驱动量作为预测量,构建回归模型。对于预测量构成的短序列,除了进行时序特征提取方式,还可以采用聚类、嵌入等降维手段,提高回归算法效率。在利用DL时,也可考虑时序的多尺度特征采用合适结构。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 45
45 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)