Python数据分析_Pandas_数据组合和缺失值处理_4
简介好多数据集都含缺失数据。缺失数据有多重表现形式数据库中,缺失数据表示为NULL在某些编程语言中用NA表示缺失值也可能是空字符串(’’)或数值在Pandas中使用NaN表示缺失值NaN,NAN,nan,他们都一样缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空串数据中出现缺失值是很常见的计算的过程中, 两个表join 可能会有缺失原始的数据中也有可能直接带着缺失值数据处理和模型
文章目录
-
-
-
- 今日内容大纲
- 1.DataFrame数据组合-concat连接
-
- 01_jupyter实现数据的concat连接操作.py
- 连接多个数据集&拼接_GIF
- 2.DataFrame数据组合-添加行和列
- 补充pymysql
- 02_pandas中操作mysql.py
- 补充sqlite
- 03_pandas中操作sqlite以及merge合并.py
- 3.df数据组合-merge方式-一对一
- 5.df数据组合-join方式
- 04_pandas中的join连接.py
- 6.缺失值简介和判断
- 7.加载缺失值
- 8.缺失值可视化
- 9.缺失值处理和非时序数据缺失值填充
- 05_缺失值详解.py
- 10.时序数据填充
- 井字棋.py
-
-
今日内容大纲
- 数据组合
- concat
- merge
- join(了解)
- 缺失值处理
- apply方法详解

1.DataFrame数据组合-concat连接
简单来说,DataFrame的concat连接就像是数据的“拼图游戏”,它允许我们将多个数据集沿着一条轴线无缝拼接,形成一个更完整的数据版图。
具体而言,concat函数在Pandas库中扮演着数据整合者的角色。无论是沿着行(axis=0)还是列(axis=1)进行拼接,它都能将不同DataFrame中的数据按照指定的轴线对齐合并。在实际操作中,我们可以通过设置参数如
ignore_index来重置索引,或者使用keys参数为原始数据集添加标识,以便于后续的数据分析和处理。总之,concat连接是数据预处理中的一把利器,它能够帮助我们在数据清洗、特征工程等环节中,灵活地整合来自不同源头的数据,为构建更加精准的模型打下坚实的基础。
- 概述
-
连接是指把某行或某列追加到数据中, 数据被分成了多份可以使用连接把数据拼接起来
-
把计算的结果追加到现有数据集,也可以使用连接
-
df对象与df对象拼接
行拼接参考: 列名, 列拼接参考: 行号
import pandas as pd # 1. 加载数据 df1 = pd.read_csv('data/concat_1.csv') df2 = pd.read_csv('data/concat_2.csv') df3 = pd.read_csv('data/concat_3.csv') # 2. 查看数据 df1 df2 df3 # 3. 通过concat()函数, 拼接上述的3个df对象. row_concat = pd.concat([df1, df2, df3]) # 默认是纵向拼接(行拼接), 结果为: 12行4列 row_concat = pd.concat([df1, df2, df3], axis='rows') # 效果同上 row_concat = pd.concat([df1, df2, df3], axis=0) # 效果同上, 0: 表示行, 1表示列. row_concat = pd.concat([df1, df2, df3], axis='columns') # 按列拼接, 4行12列 row_concat = pd.concat([df1, df2, df3], axis=1) # 效果同上, 0: 表示行, 1表示列. row_concat # 通过设置 ignore_case参数, 可以实现: 重置索引 # 行拼接, 重置索引, 结果为: 行索引变为 0 ~ n pd.concat([df1, df2, df3], ignore_index=True) # 列拼接, 重置索引, 结果为: 列名变为 0 ~ n pd.concat([df1, df2, df3], axis='columns', ignore_index=True) #
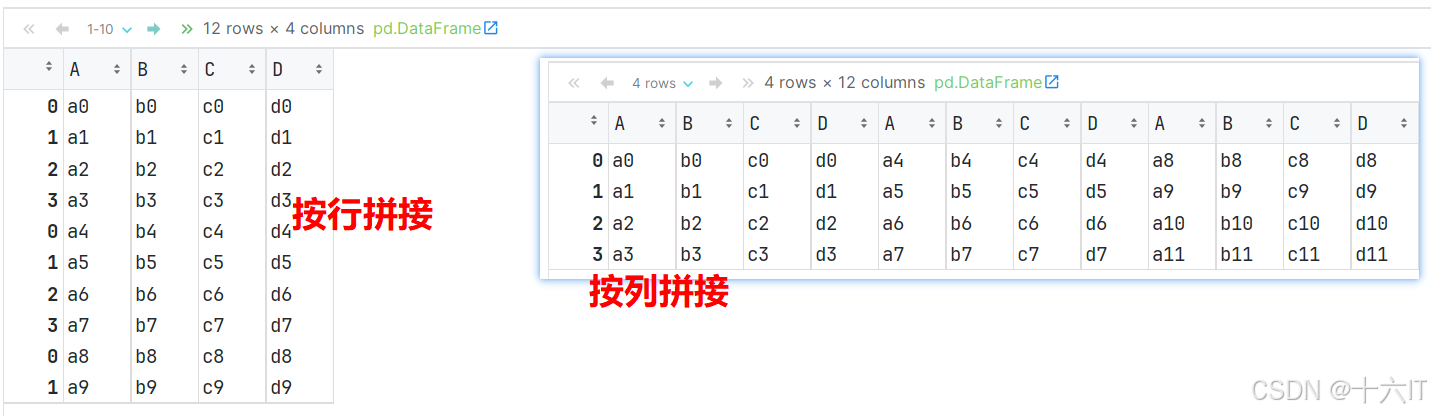
-
测试df按行拼接时, 参考: 列名
# 5. 自定义df对象, 设置列名, 然后拼接, 并观察结果. df4 = pd.DataFrame(['n1', 'n2', 'n3']) df4.columns = ['B'] # 加和不加该行, 观察效果. pd.concat([df1, df4], axis=0) # 按行拼接, axis=0 可省略不写.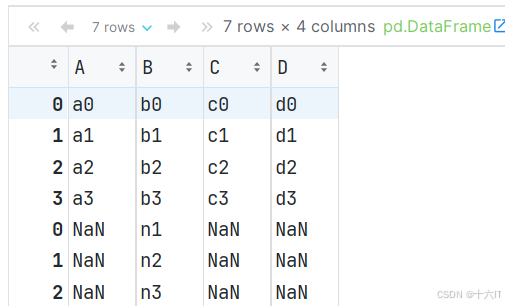
-
df对象和Series对象拼接
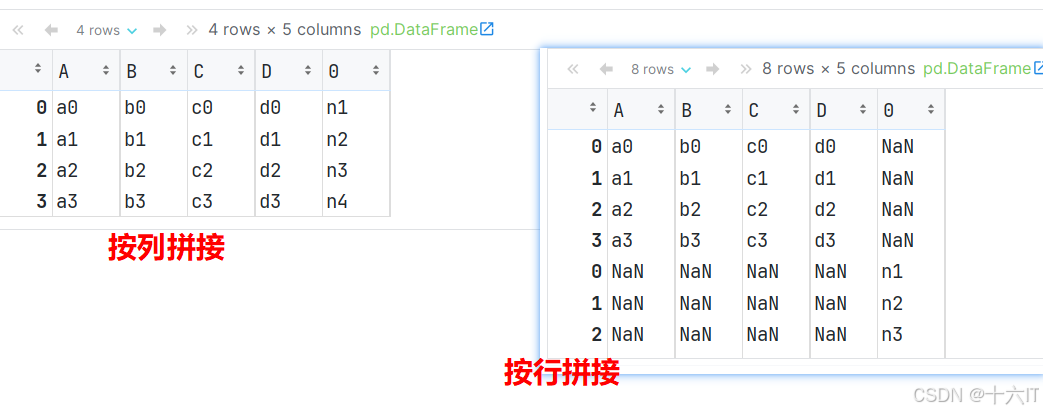
# 6. 使用concat连接 df 和 Series new_series = pd.Series(['n1', 'n2', 'n3', 'n4']) # 由于Series是列数据(没有行索引), concat()默认是添加行, 所以 它们拼接会新增一列. 缺值用NaN填充 pd.concat([df1, new_series], axis='rows') # 按行拼接 pd.concat([df1, new_series], axis=0) # 0: 行, 1: 列 pd.concat([df1, new_series], axis='columns') # 0: 行, 1: 列 pd.concat([df1, new_series], axis=1) # 0: 行, 1: 列
01_jupyter实现数据的concat连接操作.py
#%%
# 导包
import pandas as pd
#%%
# 加载数据
df1 = pd.read_csv('数据集/concat_1.csv',sep=',')
df2 = pd.read_csv('数据集/concat_2.csv',sep=',')
df3 = pd.read_csv('数据集/concat_3.csv',sep=',')
#%% md
# # concat()拼接
#%%
# concat(): 连接多个df数据集 默认 行拼接(上下拼接)
# 演示concat()连接多个df对象,默认索引重复ignore_index=False
row_concat1 = pd.concat([df1,df2,df3])
row_concat1
#%%
# 演示concat()连接多个df对象,使用ignore_index=True重置索引
row_concat2 = pd.concat([df1,df2,df3],ignore_index=True)
row_concat2
#%%
# concat(): 连接多个df数据集 指定坐标系按照列拼接(左右拼接)
# 演示concat()连接多个df对象,默认索引重复ignore_index=False
col_concat1 = pd.concat([df1,df2,df3],axis='columns')
col_concat1
#%%
# 演示concat()连接多个df对象,使用ignore_index=True重置索引
col_concat2 = pd.concat([df1,df2,df3],axis='columns',ignore_index=True)
col_concat2
#%%
# concat() 连接df对象和s对象
s1 = pd.Series(['n1','n2','n3','n4'],name='A')
# 默认行拼接, 索引没有重置
row_concat3 = pd.concat([df1,s1])
row_concat3
#%%
# 默认行拼接, 索引重置ignore_index=True
row_concat4 = pd.concat([df1,s1],ignore_index=True)
row_concat4
#%%
# axis=1或者axis='columns'修改成列拼接,索引没有重置
col_concat3 = pd.concat([df1,s1],axis='columns')
col_concat3
#%%
# axis=1或者axis='columns'修改成列拼接,索引重置ignore_index=True
col_concat4 = pd.concat([df1,s1],axis='columns',ignore_index=True)
col_concat4
#%%
# 特殊情况: df对象和s对象行拼接的时候,太多Nan值,且不是我想要的行拼接效果
# 想要的效果是,一维数组想直接拼接到df后面,先把一维数组转为二维数组df,再拼接
df_temp = pd.DataFrame([['a4','b4','c4','d4']],columns=['A','B','C','D'])
pd.concat([df1,df_temp])
#%%
# 假设s对象已经存在了,现在就想直接上下对应拼接到df后面
s2 = pd.Series(['a4','b4','c4','d4'])
s2_df1 = pd.DataFrame([s2.tolist()],columns=['A','B','C','D'])
pd.concat([df1,df2])
#%%
# 假设s对象已经存在了,现在就想直接上下对应拼接到df后面
s2 = pd.Series(['a4','b4','c4','d4'])
s2_df2 = s2.to_frame().T
s2_df2.columns=['A','B','C','D']
pd.concat([df1,df2])
#%% md
# # append()拼接
#%%
# append():功能是追加df所有行,默认索引重复ignore_index=False
df1.append(df2)
#%%
# append():功能是追加df所有行,索引重置ignore_index=True
df1.append(df2,ignore_index=True)
#%%
# append():追加字典,必须添加索引重置!!!
my_dict = {'A':'n1','B':'n2','C':'n3','D':'n4'}
df1.append(my_dict,ignore_index=True)
#%% md
# # 追加一列
#%%
# 追加一列方式1 : 直接追加数值
df1['测试'] = 666
df1
#%%
# 追加一列方式2: 追加s对象
# 注意: 如果 列名重复,会覆盖之前的列内容
s3 = pd.Series(['n1','n2','n3','n4'])
df1['测试'] = s3
df1
连接多个数据集&拼接_GIF
1
2
3
4
5
2.DataFrame数据组合-添加行和列
-
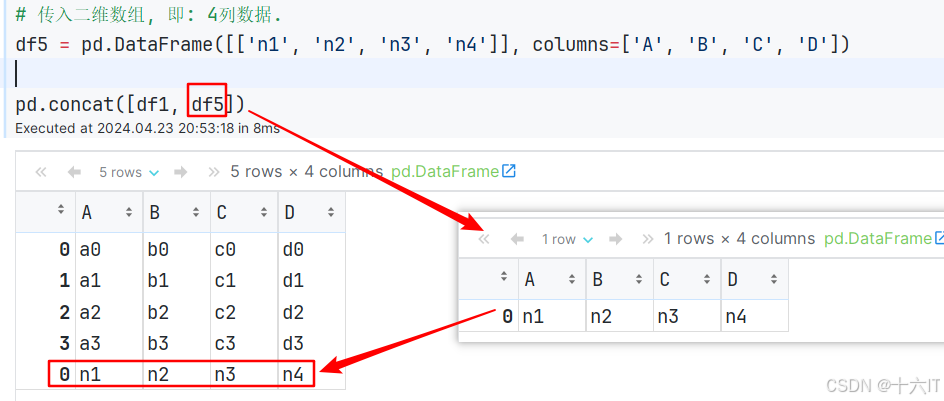
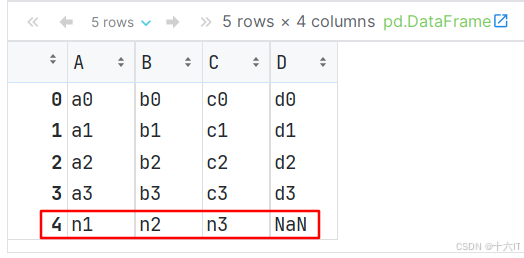
如果想将[‘n1’,‘n2’,‘n3’,‘n4’]作为行连接到df1后,可以创建DataFrame并指定列名.
# 传入二维数组, 即: 1行4列数据. df5 = pd.DataFrame([['n1', 'n2', 'n3', 'n4']], columns=['A', 'B', 'C', 'D']) pd.concat([df1, df5])
-
append函数演示
append()函数已过时, 它作用和concat()类似, 在新版的pandas中这个方法已经被删除了.
# concat可以连接多个对象, 例如: df1, df2, df3... # 但如果只需要像现有的df对象, 添加1个对象, 可以使用 append()函数实现. # 演示 append函数, 实现: 追加1个df对象 到 另1个df对象中. df1.append(df2) # 只能行拼接, 且没有axis参数 # ignore_index: 忽略索引, 即: 索引会重置. df1.append(df2, ignore_index=True) # df对象 使用append追加一个字典时, 必须传入 ignore_index=True 参数 data_dict = {'A': 'n1', 'B': 'n2', 'C': 'n3'} df1.append(data_dict, ignore_index=True)
-
向DataFrame添加一列
# 方式1: 通过 df[列名] = [列值1, 列值2...] 的方式, 可以给 df添加列. df1['new_col'] = ['n1', 'n2', 'n3', 'n4'] # 正确 # df1['new_col'] = ['n1', 'n2', 'n3', 'n4', 'n5'] # 报错, 值的个数 和 行数(4行)不匹配 # df1['new_col'] = ['n1', 'n2', 'n3'] # 报错, 值的个数 和 行数(4行)不匹配 df1 # 方式2: 通过 df[列名] = Series对象 的方式, 添加1列. # 值的个数和列的个数, 匹不匹配均可. df1['new_col2'] = pd.Series(['n1', 'n2', 'n3']) df1['new_col2'] = pd.Series(['n1', 'n2', 'n3', 'n4']) df1['new_col2'] = pd.Series(['n1', 'n2', 'n3', 'n4', 'n5']) df1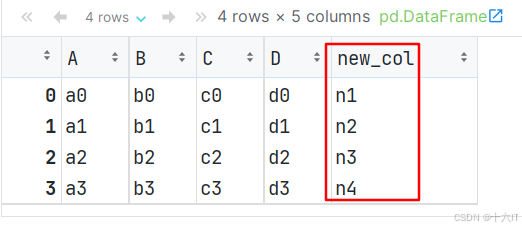
补充pymysql
以MySQL数据库为例,此时默认你已经在本地安装好了MySQL数据库。如果想利用pandas和MySQL数据库进行交互,需要先安装与数据库交互所需要的python包
pip install pymysql
pip install pymysql==1.0.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
# 如果后边的代码运行提示找不到sqlalchemy的包,和pymysql一样进行安装即可
pip install sqlalchemy
pip install sqlalchemy==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple/
- 准备要写入数据库的数据
import pandas as pd
df = pd.read_csv('./csv示例文件.csv', sep=',', index_col=[0])
df

-
创建数据库操作引擎对象并指定数据库
# 创建数据库 create database db_test; # 使用数据库 use db_test; # 创建表 create table student( id int, name varchar(20), age int ); # 插入数据 insert into student values(1,'张三',20),(2,'李四',28);
# 需要安装pymysql,部分版本需要额外安装sqlalchemy
# 导入sqlalchemy的数据库引擎
from sqlalchemy import create_engine
# 创建数据库引擎,传入uri规则的字符串
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
# mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8
# mysql 表示数据库类型
# pymysql 表示python操作数据库的包
# root:123456 表示数据库的账号和密码,用冒号连接
# 127.0.0.1:3306/test 表示数据库的ip和端口,以及名叫test的数据库
# charset=utf8 规定编码格式
- 将数据写入MySQL数据库
# df.to_sql()方法将df数据快速写入数据库
df.to_sql('test_pdtosql', engine, index=False, if_exists='append')
# 第一个参数为数据表的名称
# 第二个参数engine为数据库交互引擎
# index=False 表示不添加自增主键
# if_exists='append' 表示如果表存在就添加,表不存在就创建表并写入
-
此时我们就可以在本地test库的test_pdtosql表中看到写入的数据
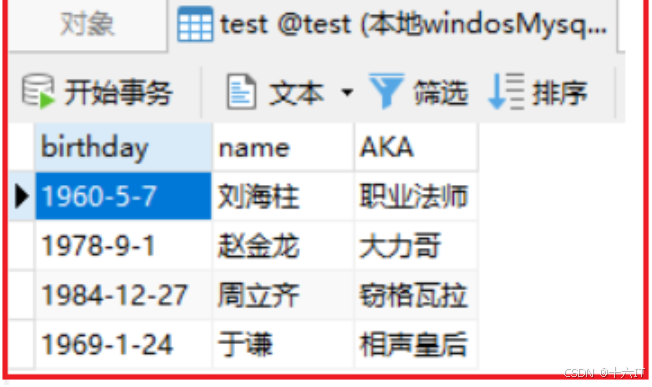
-
从数据库中加载数据:
- 读取整张表, 返回dataFrame
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/test?charset=utf8') # 指定表名,传入数据库连接引擎对象 pd.read_sql('test_pdtosql', engine)- 使用SQL语句获取数据,返回dataframe
# 传入sql语句,传入数据库连接引擎对象 pd.read_sql('select name,AKA from test_pdtosql', engine)
可能出现的问题:
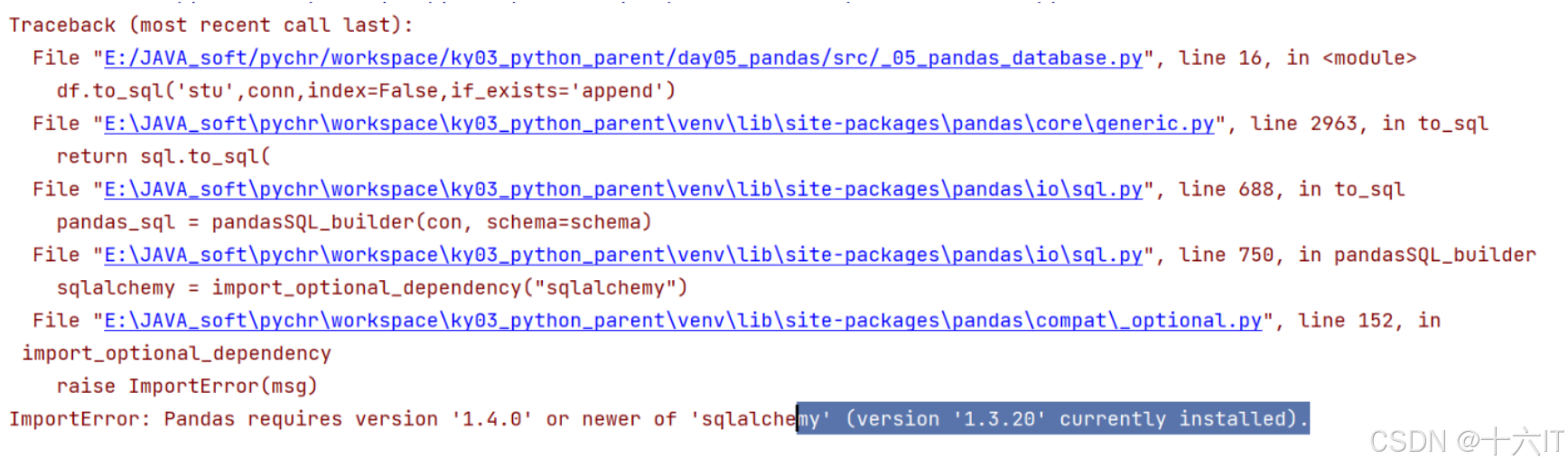
说明:
sqlalche 库版本过低导致的
解决方案:
先删除原有版本:
pip uninstall sqlalchemy
重新安装:
pip install sqlalchemy==1.4.31
02_pandas中操作mysql.py
#%% md
# # pymysql基础使用
#%%
# 1.导包
import pymysql
# 2.连接数据库
conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_test')
# 3.生成游标
cur = conn.cursor()
# 4.执行sql语句
r = cur.execute('select * from db_test.student')
# 5.处理结果
print(f"影响行数: {r}")
print(cur.fetchall())
# 6.关闭游标
cur.close()
# 7.关闭连接
conn.close()
#%% md
# # pymysql+pandas应用
#%%
# 需要安装pymysql,部分版本需要额外安装sqlalchemy
# 导入sqlalchemy的数据库引擎
from sqlalchemy import create_engine
# 创建数据库引擎,传入uri规则的字符串
# mysql+pymysql://用户名:密码@IP地址:端口号/数据库?charset=编码
engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/db_test?charset=utf8')
# mysql 表示数据库类型
# pymysql 表示python操作数据库的包
# root:123456 表示数据库的账号和密码,用冒号连接
# 127.0.0.1:3306/test 表示数据库的ip和端口,以及名叫test的数据库
# charset=utf8 规定编码格式
import pandas as pd
#%%
# 写数据到mysql数据库
# usecols: 读取csv文件时,只读取指定的列
df = pd.read_csv('数据集/csv示例文件.csv',encoding='gbk',usecols=['birthday','name','AKA'])
# to_sql(): 一定要指定数据库引擎,指定表名(不存在就会创建) if_exists:存在就追加数据
df.to_sql('users5', engine,index_label='id', if_exists='append')
#%%
# 从mysql数据读取sql表
# read_sql(): 一定要传入sql和数据库引擎
df = pd.read_sql('users5', engine)
df
补充sqlite
SQLite,是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它是D.RichardHipp建立的公有领域项目。它的设计目标是嵌入式的,而且已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
不像常见的客户->服务器范例,SQLite引擎不是个程序与之通信的独立进程,而是连接到程序中成为它的一个主要部分。所以主要的通信协议是在编程语言内的直接API调用。这在消耗总量、延迟时间和整体简单性上有积极的作用。整个数据库(定义、表、索引和数据本身)都在宿主主机上存储在一个单一的文件中。它的简单的设计是通过在开始一个事务的时候锁定整个数据文件而完成的。
简单来说,SQLite 是一个轻量级的嵌入式数据库,它不需要单独的服务器进程,允许直接读写普通的磁盘文件。
具体来说,SQLite
实现了自给自足的、无服务器的、零配置的、事务性的 SQL
数据库引擎。它的数据库就是一个文件,这使得它在部署和使用上极为方便,尤其适合用在移动应用、嵌入式系统和小型桌面应用中。
总之,SQLite
以其简洁的设计和易于集成的特性,成为了处理本地数据存储需求的理想选择,无论是在应用程序的初始开发阶段,还是在资源受限的环境中,它都能提供稳定可靠的数据管理解决方案。
03_pandas中操作sqlite以及merge合并.py
#%%
# 导包
import pandas as pd
import sqlite3
#%% md
# # pandas操作sqlite
#%%
# pandas操作sqlite
# 1.获取连接对象
conn = sqlite3.connect('数据集/chinook.db')
# 2.分别查询歌曲表和流派表数据
tracks = pd.read_sql_query('select * from tracks',conn)
genres = pd.read_sql_query('select * from genres',conn)
tracks
#%%
# 3.为了一会方便演示内连接,左外,右外,全外连接效果,获取部分数据
t1 = tracks.loc[[0, 62, 76, 98, 110, 193, 204, 281, 322, 359], ]
g1 = genres.head(5)
#%%
t1[['GenreId','TrackId','Milliseconds']]
#%%
g1
#%% md
# # 演示merge()函数
#%%
# merge注意1: 如果两个表关联字段同名可以使用on=字段名,不同名称可以使用left_on='字段名',right_on='字段名'
# 演示merge的内连接操作
g1.merge(t1[['GenreId','TrackId','Milliseconds']], on='GenreId',how='inner')
#%%
# 演示merge的左外连接操作
t1[['GenreId','TrackId','Milliseconds']].merge(g1, on='GenreId',how='left')
#%%
# 演示merge的右外连接操作
g1.merge(t1[['GenreId','TrackId','Milliseconds']], on='GenreId',how='right')
#%%
# 演示merge的全外连接操作
g1.merge(t1[['GenreId','TrackId','Milliseconds']], on='GenreId',how='outer')
#%%
t1[['GenreId','Name','TrackId','Milliseconds']]
#%%
# merge注意2: 如果两个表除了关联字段,有其他同名,结果中默认左右表分别加后缀_x,_y
g1.merge(t1[['GenreId','Name','TrackId','Milliseconds']], on='GenreId',how='outer')
#%%
# merge注意3: 如果咱们觉得同名时自动补充的_x和_y,不好,想要自己改可以用suffixes=('_左表后缀','_右表后缀')
data = g1.merge(t1[['GenreId','Name','TrackId','Milliseconds']], on='GenreId',how='outer',suffixes=('_genre','_track'))
#%%
#%%
# 需求: 计算每种音乐的平均时长
Name_genre_dt = data.groupby('Name_genre')['Milliseconds'].mean()
pd.to_timedelta(Name_genre_dt,unit='ms')
pd.to_timedelta(Name_genre_dt,unit='ms').dt.ceil('s')
pd.to_timedelta(Name_genre_dt,unit='ms').dt.ceil('s').sort_values(ascending=False)
#%%
#%%
# 一对多
genres.merge(tracks,on='GenreId')
# TODO 作业:计算每名用户的平均消费
#%%
#%% md
# # merge和concat对比
#%%
# 加载数据
df1 = pd.read_csv('数据集/concat_1.csv',sep=',')
df2 = pd.read_csv('数据集/concat_2.csv',sep=',')
df2
#%%
# merge合并
df1.merge(df2,on='A',how='inner')
df1.merge(df2,on='A',how='left')
df1.merge(df2,on='A',how='right')
df1.merge(df2,on=['A','B','C','D'],how='outer')
#%%
# concat合并
pd.concat([df1,df2])
3.df数据组合-merge方式-一对一
简单来说,merge方式就像是数据的“婚姻介绍所”,它根据共同的键(key)将两个数据集中的信息匹配并合并,形成一个新的、信息更丰富的数据家庭。
具体而言,merge操作在Pandas库中通过指定一个或多个键来执行,它支持多种类型的连接方式,如内连接(inner)、左连接(left)、右连接(right)和外连接(outer)。这就像是在不同的社交圈子中寻找共同的朋友,内连接只保留双方都有的朋友,而外连接则包容所有的朋友,不论他们是否来自同一个圈子。在实际生产场景中,merge常用于整合来自不同系统的数据,例如将客户信息表与订单记录表通过客户ID进行合并,以便进行更全面的业务分析。
总之,merge方式是数据整合的得力助手,它能够帮助我们在数据分析和业务决策中,将分散的数据信息通过关键字段有效地联结起来,为洞察业务动态和趋势提供了强有力的数据支持。
-
概述
-
在使用concat连接数据时,涉及到了参数join(join = ‘inner’,join = ‘outer’)
-
数据库中可以依据共有数据把两个或者多个数据表组合起来,即join操作
-
DataFrame 也可以实现类似数据库的join操作
-
Pandas可以通过pd.join命令组合数据,
-
也可以通过pd.merge命令组合数据
merge更灵活,如果想依据行索引来合并DataFrame可以考虑使用join函数
-
-
-
配置PyCharm 连接 Sqlite, 步骤类似于: PyCharm连接MySQL
-
代码演示
-
准备数据
import sqlite3 # 1. 创建连接对象, 关联: Sqlite文件. con = sqlite3.connect('data/chinook.db') # 2. 读取SQL表数据, 参1: SQL语句, 参2: 连接对象 tracks = pd.read_sql_query('select * from tracks', con) # track: 歌曲表 # 3. 查看数据. tracks.head() # 4. read_sql_query()函数, 从数据库中读取表, 参1: SQL语句, 参2: 连接对象. genres = pd.read_sql_query('select * from genres', con) #genre:(歌曲流派)歌曲类别表 genres.head() # 数据介绍, 列1: 风格id, 列2: 风格名(爵士乐, 金属...) -
从歌曲表中, 抽取部分数据
# 5. 从track表(歌曲表)提取部分数据, 使其不含重复的'GenreID'值 tracks_subset = tracks.loc[[0, 62, 76, 98, 110, 193, 204, 281, 322, 359], ] tracks_subset -
一对一合并
- 字段介绍

- 字段介绍
-
# 歌曲分类表.merge(歌曲表子集的 歌曲id, 分类id, 歌曲时长) on表示关联字段, how表示连接方式
# left 类似于SQL的 左外连接, 即: 左表的全集 + 交集.
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='left')
# right 类似于SQL的 右外连接, 即: 右表的全集 + 交集.
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='right')
# outer 类似于SQL的 满外连接, 即: 左表的全集 + 右表全集 + 交集.
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='outer')
# inner 类似于SQL的 内连接, 即: 交集.
genre_track = genres.merge(tracks_subset[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='inner')
# 如果两张表有相同的列名, 则会分别给其加上 _x, _y的后缀, 来源于: merge()函数自带参数: suffixes, 如下代码, 加入 Name字段, 然后观察显示结果.
genre_track = genres.merge(tracks_subset[['TrackId', 'Name', 'GenreId', 'Milliseconds']], on='GenreId', how='inner')
genre_track
> 细节: > > 1. on 连接的字段, 如果**左右两张表 连接的字段名字相同**直接使用 on='关联字段名' > > 2. 如果名字不同, left_on 写左表字段, right_on 写右表字段. > > 3. 连接之后, 两张表中如果有相同名字的字段, 默认会加上后缀 默认值 _x, _y_ > > _suffixes:("_ x", "_ y")
-
4.df数据组合-merge方式-多对一
-
需求1: 计算每种类型音乐的 平均时长.
# 1. 获取连接数据, 本次是: tracks(歌曲表) 所有的数据 genre_track = genres.merge(tracks[['TrackId', 'GenreId', 'Milliseconds']], on='GenreId', how='left') genre_track.head() # 2. 转换时间单位. # 需求1: 计算每种类型音乐的 平均时长. # 2.1 根据 类型名分组, 统计时长 平均值即可. genre_time = genre_track.groupby('Name')['Milliseconds'].mean() # 2.2 代码解释 # pd.to_timedelta(genre_time, unit='ms'): 把 genre_time 转成 timedelta 时间类型. # dt.floor('s') 日期类型数据, 按指定单位截断数据, s 表示: 秒 pd.to_timedelta(genre_time, unit='ms').dt.floor('s').sort_values()
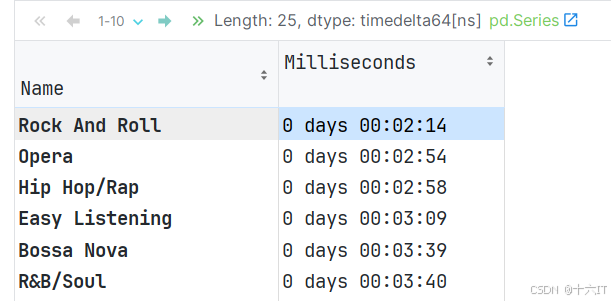
5.df数据组合-join方式
-
概述
- 使用join合并,可以是依据两个DataFrame的行索引,
- 或者一个DataFrame的行索引另一个DataFrame的列索引进行数据合并
-
代码演示
# 场景1: 依据两个DataFrame的行索引 # 如果合并的两个数据有相同的列名,需要通过lsuffix,和rsuffix,指定合并后的列名的后缀 stocks_2016.join(stocks_2017, lsuffix='_2016', rsuffix='_2017', how='outer') # 默认是: 左外连接. # 场景2: 将两个DataFrame的Symbol设置为行索引,再次join数据 stocks_2016.set_index('Symbol').join(stocks_2018.set_index('Symbol'),lsuffix='_2016', rsuffix='_2018') # 场景3: 将一个DataFrame的Symbol列设置为行索引,与另一个DataFrame的Symbol列进行join stocks_2016.join(stocks_2018.set_index('Symbol'),lsuffix='_2016', rsuffix='_2018',on='Symbol') # 回顾: merge(), concat() 也可以实现拼接. stocks_2016.merge(stocks_2018, on='Symbol', how='left') # 左外连接 stocks_2016.merge(stocks_2018, on='Symbol', how='outer') # 满外连接

04_pandas中的join连接.py
#%%
# 1.导包
import pandas as pd
#%%
# 2.加载数据
stocks_2016 = pd.read_csv('数据集/stocks_2016.csv',sep=',')
stocks_2017 = pd.read_csv('数据集/stocks_2017.csv',sep=',')
stocks_2018 = pd.read_csv('数据集/stocks_2018.csv',sep=',')
#%%
# 3.假设想要合并2016和2017的数据
# concat() 默认全外连接(也可以内连接)
pd.concat([stocks_2016,stocks_2017],join='outer',ignore_index=True)
#%%
# merge() 默认内连接(也可以左外,右外,全外连接) 注意: 如果有同名,自动添加后缀_x,_y
stocks_2016.merge(stocks_2017,on='Symbol',how='inner',suffixes=('_2016','_2017'))
#%%
# join() 默认左外连接(也可以内连接,右外,全外)
stocks_2016.join(stocks_2017,how='left',lsuffix='_2016',rsuffix='_2017')
#%%
# 注意:join 注意: 如果有同名字段 ,必须手动添加后缀_x,_y
stocks_2016.set_index('Symbol').join(stocks_2017.set_index('Symbol'),how='left',lsuffix='_2016',rsuffix='_2017')
#%%
stocks_2016.join(stocks_2017.set_index('Symbol'),how='left',lsuffix='_2016',rsuffix='_2017',on='Symbol')
#%%
6.缺失值简介和判断
-
简介
-
好多数据集都含缺失数据。缺失数据有多重表现形式
- 数据库中,缺失数据表示为NULL
- 在某些编程语言中用NA表示
- 缺失值也可能是空字符串(’’)或数值
- 在Pandas中使用NaN表示缺失值
-
Pandas中的NaN值来自NumPy库,NumPy中缺失值有几种表示形式:
- NaN,NAN,nan,他们都一样
- 缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空串
-
数据中出现缺失值是很常见的
-
计算的过程中, 两个表join 可能会有缺失
-
原始的数据中也有可能直接带着缺失值
-
数据处理和模型训练的时候, 有很多场景要求必须先把缺失值处理掉,
-
想处理缺失值先要在数据中找到缺失值
-
-
-
代码演示
# 导包 import numpy as np # 1. 缺失值不是 True, False, 空字符串, 0等, 它"毫无意义" print(np.NaN == False) print(np.NaN == True) print(np.NaN == 0) print(np.NaN == '') # 2. np.nan np.NAN np.NaN 都是缺失值, 这个类型比较特殊, 不同通过 == 方式判断, 只能通过API print(np.NaN == np.nan) print(np.NaN == np.NAN) print(np.nan == np.NAN) # 3. Pandas 提供了 isnull() / isna()方法, 用于测试某个值是否为缺失值 import pandas as pd print(pd.isnull(np.NaN)) # True print(pd.isnull(np.nan)) # True print(pd.isnull(np.NAN)) # True print(pd.isna(np.NaN)) # True print(pd.isna(np.nan)) # True print(pd.isna(np.NAN)) # True # isnull() / isna()方法 还可以判断数据. print(pd.isnull(20)) # False print(pd.isnull('abc')) # False # 4. Pandas的notnull() / notna() 方法可以用于判断某个值是否为缺失值 print(pd.notnull(np.NaN)) # False print(pd.notnull('abc')) # True
7.加载缺失值
-
读取包含缺失值的数据
# 加载数据时可以通过keep_default_na 与 na_values 指定加载数据时的缺失值 pd.read_csv('data/survey_visited.csv') # 加载数据,不包含默认缺失值, # 参数解释: keep_default_na = False 表示加载数据时, 不加载缺失值. pd.read_csv('data/survey_visited.csv', keep_default_na=False) # 加载数据,手动指定缺失值, 例如: 指定619, 734为缺失值 # 参数解释: na_values=[值1, 值2...] 表示加载数据时, 设定哪些值为缺失值. pd.read_csv('data/survey_visited.csv', na_values=['619', '734'], keep_default_na=False)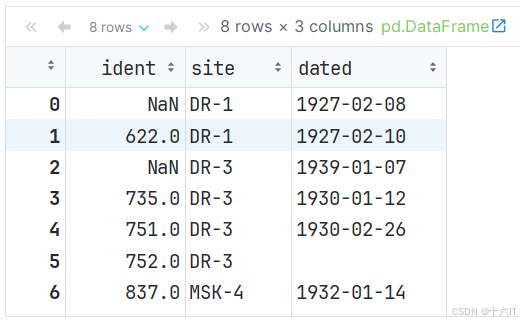
8.缺失值可视化
-
代码演示
# 1. 加载数据 train = pd.read_csv('data/titanic_train.csv') test = pd.read_csv('data/titanic_test.csv') train.shape train.head() # 2. 查看是否获救数据. train['Survived'].value_counts() # 0: 没获救. 1: 获救 # 3. 缺失值可视化(了解) # 如果没有安装这个包, 需要先装一下. # pip install missingnode # 导包 import missingno as msno # 柱状图, 展示: 每列的 非空值(即: 非缺失值)个数. msno.bar(train) # 绘制缺失值热力图, 发现缺失值之间是否有关联, 是不是A这一列缺失, B这一列也会缺失. msno.heatmap(train) -
表字段介绍

9.缺失值处理和非时序数据缺失值填充
-
删除缺失值
dropna()函数, 参数介绍如下:
-
subset=None 默认是: 删除有缺失值的行, 可以通过这个参数来指定, 哪些列有缺失值才会被删除
-
例如: subset = [‘Age’] 只有当年龄有缺失才会被删除
-
inplace=False 通用参数, 是否修改原始数据默认False
-
axis=0 通用参数 按行按列删除 默认行
-
how=‘any’ 只要有缺失就会删除 还可以传入’all’ 全部都是缺失值才会被删除
train.shape # 原始数据, 891行, 12列 # 方式1: 删除缺失值 # 删除缺失值会损失信息,并不推荐删除,当缺失数据占比较低的时候,可以尝试使用删除缺失值 # 按行删除: 删除包含缺失值的记录 # train.dropna().shape # 默认按行删(该行只要有空值, 就删除该行), 结果为: 183行, 12列 train.loc[:10].dropna() # 获取前11行数据, 删除包含空值的行. # any: 只要有空值就删除该行|列, all: 该行|列 全为空才删除 subset: 参考哪些列的空值. inplace=True 在原表修改 train.dropna(subset=['Age'], how='any') # 该列值只要有空, 就删除该列值. train.dropna(how='any', axis=1) # 0(默认): 行, 1: 列 train.isnull().sum() # 快速计算是否包含缺失值 -
-
非时序数据填充
# 方式2: 填充缺失值, 填充缺失值是指用一个估算的值来去替代缺失数 # 场景1: 非时间序列数据, 可以使用常量来替换(默认值) # 用 0 来填充 空值. train.fillna(0) # 查看填充后, 每列缺失值 情况. train.fillna(0).isnull().sum() # 需求: 用平均年龄, 来替换 年龄列的空值. train['Age'].fillna(train['Age'].mean())非时序数据的缺失值填充, 直接使用fillna(值, inplace=True)
- 可以使用统计量 众数 , 平均值, 中位数 …
- 也可以使用默认值来填充
05_缺失值详解.py
#%%
# 1.导包
import pandas as pd
#%%
# 2.加载数据
stocks_2016 = pd.read_csv('数据集/stocks_2016.csv',sep=',')
stocks_2017 = pd.read_csv('数据集/stocks_2017.csv',sep=',')
stocks_2018 = pd.read_csv('数据集/stocks_2018.csv',sep=',')
#%%
# 3.假设想要合并2016和2017的数据
# concat() 默认全外连接(也可以内连接)
pd.concat([stocks_2016,stocks_2017],join='outer',ignore_index=True)
#%%
# merge() 默认内连接(也可以左外,右外,全外连接) 注意: 如果有同名,自动添加后缀_x,_y
stocks_2016.merge(stocks_2017,on='Symbol',how='inner',suffixes=('_2016','_2017'))
#%%
# join() 默认左外连接(也可以内连接,右外,全外)
stocks_2016.join(stocks_2017,how='left',lsuffix='_2016',rsuffix='_2017')
#%%
# 注意:join 注意: 如果有同名字段 ,必须手动添加后缀_x,_y
stocks_2016.set_index('Symbol').join(stocks_2017.set_index('Symbol'),how='left',lsuffix='_2016',rsuffix='_2017')
#%%
stocks_2016.join(stocks_2017.set_index('Symbol'),how='left',lsuffix='_2016',rsuffix='_2017',on='Symbol')
#%%
10.时序数据填充
-
代码演示
# 1. 加载时间序列数据,数据集为印度城市空气质量数据(2015-2020) # parse_dates: 把某些列转成时间列. # index_col: 设置指定列为 索引列 city_day = pd.read_csv('data/city_day.csv', parse_dates=['Date'], index_col='Date') # 2. 查看缺失值情况. city_day.isnull().sum() # 3. 数据中有很多缺失值,比如 Xylene(二甲苯)和 PM10 有超过50%的缺失值 # 3.1 查看包含缺失数据的部分 city_day['Xylene'][50:64] # 3.2 用固定值填充, 例如: 该列的平均值. # 查看平均值. city_day['Xylene'].mean() # 3.0701278234985114 # 用平均值来填充. city_day.fillna(city_day['Xylene'].mean())[50:64]['Xylene'] # 3.3 使用ffill 填充,用时间序列中空值的上一个非空值填充 # NaN值的前一个非空值是0.81,可以看到所有的NaN都被填充为0.81 city_day.fillna(method='ffill')[50:64]['Xylene'] # 3.4 使用bfill填充,用时间序列中空值的下一个非空值填充 # NaN值的后一个非空值是209,可以看到所有的NaN都被填充为209 city_day.fillna(method='bfill')[50:64]['Xylene'] # 3.5 线性插值方法填充缺失值 # 时间序列数据,数据随着时间的变化可能会较大。使用bfill和ffill进行插补并不是解决缺失值问题的最优方案。 # 线性插值法是一种插补缺失值技术,它假定数据点之间存在线性关系,利用相邻数据点中的非缺失值来计算缺失数据点的值。 # 参数limit_direction: 表示线性填充时, 参考哪些值(forward: 向前, backward:向后, both:前后均参考) city_day.interpolate(limit_direction="both")[50:64]['Xylene'] -
缺失值处理的套路
- 能不删就不删 , 如果某列数据, 有大量的缺失值(50% 以上是缺失值, 具体情况具体分析)
- 如果是类别型的, 可以考虑使用 ‘缺失’ 来进行填充
- 如果是数值型 可以用一些统计量 (均值/中位数/众数) 或者业务的默认值来填充
井字棋.py
class Board:
"""表示井字棋棋盘."""
def __init__(self):
self.grid = [[' ' for _ in range(3)] for _ in range(3)]
def display(self):
"""显示棋盘."""
print(f" {self.grid[0][0]} | {self.grid[0][1]} | {self.grid[0][2]} ")
print("---+---+---")
print(f" {self.grid[1][0]} | {self.grid[1][1]} | {self.grid[1][2]} ")
print("---+---+---")
print(f" {self.grid[2][0]} | {self.grid[2][1]} | {self.grid[2][2]} ")
def is_valid_move(self, row, col):
"""检查移动是否有效."""
return 0 <= row <= 2 and 0 <= col <= 2 and self.grid[row][col] == ' '
def make_move(self, row, col, player):
"""在棋盘上落子."""
if self.is_valid_move(row, col):
self.grid[row][col] = player
return True
return False
def check_win(self, player):
"""检查是否有玩家获胜."""
# 检查行
for row in self.grid:
if all(cell == player for cell in row):
return True
# 检查列
for col in range(3):
if all(self.grid[row][col] == player for row in range(3)):
return True
# 检查对角线
if all(self.grid[i][i] == player for i in range(3)):
return True
if all(self.grid[i][2 - i] == player for i in range(3)):
return True
return False
def is_full(self):
"""检查棋盘是否已满."""
return all(cell != ' ' for row in self.grid for cell in row)
class Player:
"""表示井字棋玩家."""
def __init__(self, name, marker):
self.name = name
self.marker = marker
class Game:
"""表示井字棋游戏."""
def __init__(self):
self.board = Board()
self.player1 = Player("玩家1", "❌") # 你可以改成你喜欢的 emoji
self.player2 = Player("玩家2", "⭕") # 你可以改成你喜欢的 emoji
self.current_player = self.player1
def switch_player(self):
"""切换当前玩家."""
self.current_player = self.player2 if self.current_player == self.player1 else self.player1
def get_move(self):
"""获取当前玩家的移动."""
while True:
try:
row = int(input(f"{self.current_player.name},请输入行号 (0-2): "))
col = int(input(f"{self.current_player.name},请输入列号 (0-2): "))
if self.board.is_valid_move(row, col):
return row, col
else:
print("无效的输入,请重新输入。")
except ValueError:
print("请输入数字!")
def play(self):
"""开始游戏."""
print("欢迎来到井字棋游戏!")
print(f"{self.player1.name}: {self.player1.marker}")
print(f"{self.player2.name}: {self.player2.marker}")
while True:
self.board.display()
print(f"轮到 {self.current_player.name} ({self.current_player.marker}) 了。")
row, col = self.get_move()
self.board.make_move(row, col, self.current_player.marker)
if self.board.check_win(self.current_player.marker):
self.board.display()
print(f"恭喜!{self.current_player.name} ({self.current_player.marker}) 赢了!")
break
elif self.board.is_full():
self.board.display()
print("平局!")
break
else:
self.switch_player()
if __name__ == "__main__":
game = Game()
game.play()

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 52
52 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)