Python数据可视化分析(电商平台农产品数据分析·)
·
1.前言:
分享一款Python针对电商平台的农产品数据可视化分析的项目,项目流程也很简单,使用Python爬虫技术(selenium库)爬取电商平台的农产品(产品类型,销量,价格,发货地,商家,产品名字等一系列字段),将数据清洗后存储在Excle数据文件中,然后利用Python的pandas数据分析库对数据集做处理,然后结合Echarts坐可视化呈现。
2.项目简介:
☀ 项目简介:
1⃣ 项目名称:基于Python的农产品数据可视化分析.
2⃣ 项目实现功能:1、用户登录注册,2、个人信息编辑以及个人密码修改,3、数据分页总览和全局搜索以及实现了用户可以对喜欢的产品进行收藏和删除,4、首页大屏展示了用户的注册数据以及Excle数据文件中所有农产品数据的基本属性数据,5、针对爬取的农产品数据的各个字段做详细多维度的可视化图表分析处理.
3⃣ 项目涉及技术:Python、Django、Excle、Echarts,Pandas、爬虫.
3.项目核心代码:
3.1 爬虫代码:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import csv
import random
import pymysql
# 启动爬虫前的准备工作: (0)安装谷歌浏览器和对应的驱动 (1)修改MySQL配置 (2)第52行设置MySQL表的起始id,例如 id = 5001 (3)第42行输入采集关键词
# 打开数据库
coon = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
password='123456', #
db='taobao_goods'
)
cursor = coon.cursor()
# 不关闭浏览器
option = webdriver.ChromeOptions()
option.add_experimental_option("detach", True)
#
# s = Service(executable_path=r'chromedriver.exe')
# driver = webdriver.Chrome(service=s, options=option)
chromedriver_path = 'chromedriver.exe'
driver = webdriver.Chrome(executable_path=chromedriver_path, options=option)
#
header = ['title', 'location', 'sale', 'price', 'shopName', 'pic_url', 'detail_url']
with open('data.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=header)
writer.writeheader()
# driver.get('https://www.taobao.com/')
driver.get('https://login.taobao.com/member/login.jhtml?spm=a21bo.jianhua.754894437.1.5af92a89CP6IL6&f=top&redirectURL=https%3A%2F%2Fwww.taobao.com%2F')
driver.implicitly_wait(20)
driver.find_element(By.XPATH, '//*[@id="login"]/div[1]/i').click()
driver.find_element(By.ID, 'q').send_keys('农村农产品') # 输入关键词
driver.find_element(By.XPATH, '//div[@class="search-button"]/button').click()
# 跳过这步
# driver.find_element(By.XPATH, '//div[@class="corner-icon-view view-type-qrcode"]/i[@class="iconfont icon-qrcode"]').click()
time.sleep(5)
# time.sleep(10)
j = 1
# 设置数据表的自增id ,从1200开始
id = 1100
while j < 60: # # 采集5页
for i in range(1, 10): # 调用js下拉滚动条
# for i in range(1, 10):
# for i in range(1, 10):
time.sleep(1)
driver.execute_script(f'window.scrollBy(0,{i * 100})')
items = driver.find_elements(By.XPATH, '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[3]/div/div')
for item in items:
title = item.find_element(By.XPATH, './a/div/div[1]/div[2]/div/span').text
location = item.find_element(By.XPATH, './a/div/div[1]/div[3]/div').text
sale = item.find_element(By.XPATH, './a/div/div[1]/div[3]/span[4]').text
if '+' in sale:
sale = sale.replace('+', '')
if '人付款' in sale:
sale = sale.replace('人付款', '')
price = item.find_element(By.XPATH, './a/div/div[1]/div[3]/span[2]').text
shopName = item.find_element(By.XPATH, './a/div/div[3]/div[1]/a').text
pic_url = item.find_element(By.XPATH, './a/div/div[1]/div[1]/img').get_property('src')
detail_url = item.find_element(By.XPATH, './a').get_property('href')
print(title, location, sale, price, shopName, pic_url, detail_url)
item = {
'title': title,
'location': location,
'sale': sale,
'price': price,
'shopName': shopName,
'pic_url': pic_url,
'detail_url': detail_url
}
# print(item)
header = ['title', 'location', 'sale', 'price', 'shopName', 'pic_url', 'detail_url']
with open('data.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=header) # 提前预览列名,当下面代码写入数据时,会将其一一对应。
writer.writerow(item) # 写入数据
print(f'第{j}页抓取完毕')
# 这个是翻页
next = driver.find_element(By.XPATH, '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/button[2]')
next.click()
time_out = random.uniform(4, 6)
time.sleep(time_out)
j += 1
coon.close()
cursor.close()
3.2 爬取的数据展示:
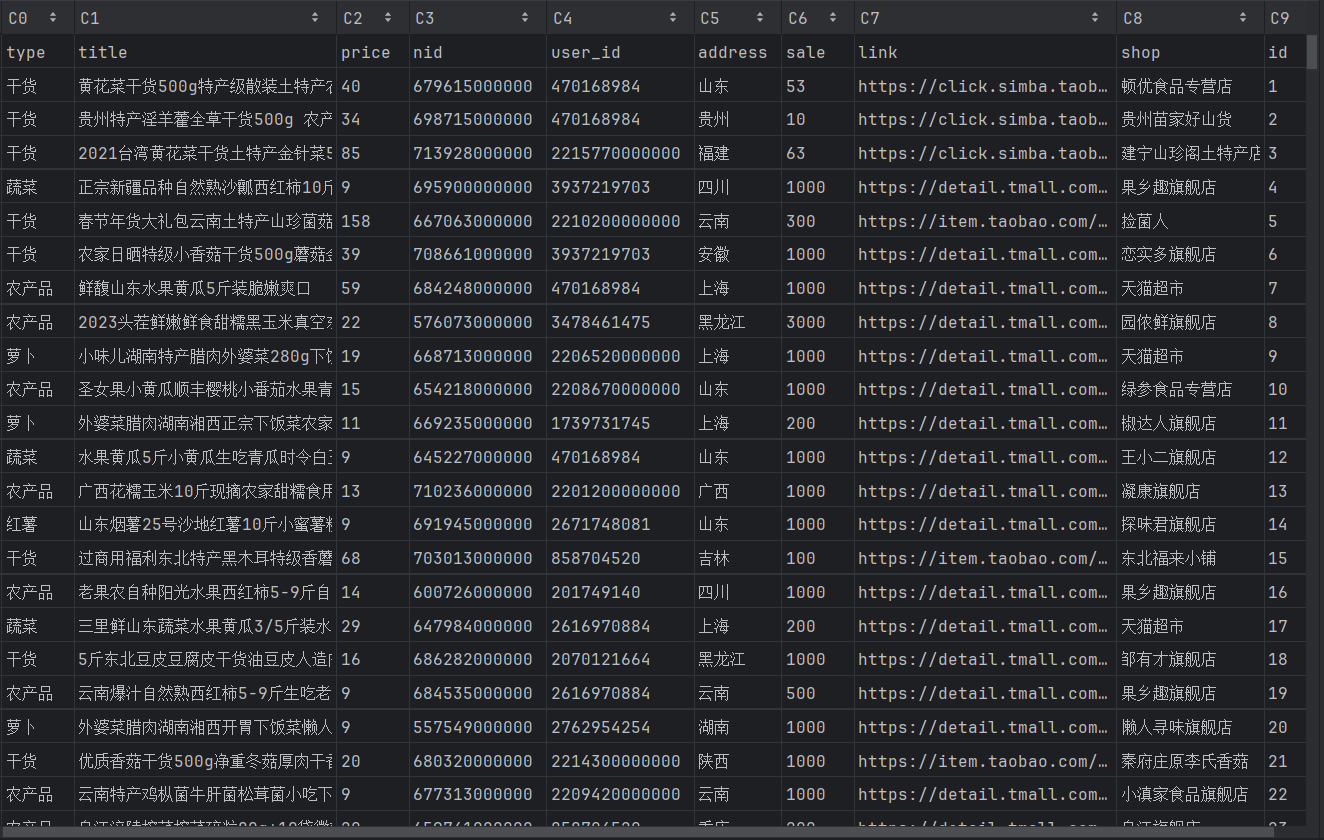
3.3 后端业务代码:
import random
import time
from django.shortcuts import render, redirect
import pandas as pd # Import pandas to read Excel files
from wordcloud import WordCloud
from myApp.models import User
excel_file_path = r'D:\PycharmProjects\Python农业产品数据可视化分析\spider\data.xlsx'
data = pd.read_excel(excel_file_path) # Load the data from the Excel file
# Create your views here.
# 01用户登录
def login(request):
if request.method == 'GET':
return render(request, 'login.html')
if request.method == 'POST':
name = request.POST.get('name')
password = request.POST.get('password')
if User.objects.filter(username=name, password=password):
user=User.objects.get(username=name, password=password)
username=request.session['username'] = {'username':user.username,'avatar':str(user.avatar)}
return redirect('Address_Distribute')
else:
msg = '信息错误!'
return render(request, 'login.html', {"msg": msg})
# 02用户注册
def register(request):
if request.method == 'POST':
name = request.POST.get('name')
password = request.POST.get('password')
phone = request.POST.get('phone')
email = request.POST.get('email')
avatar = request.FILES.get('avatar')
stu = User.objects.filter(username=name)
if stu:
msg = '用户已存在!'
return render(request, 'register.html', {"msg": msg})
else:
User.objects.create(username=name,password=password,phone=phone,email=email,avatar=avatar)
msg = "注册成功!"
return render(request, 'login.html', {"msg": msg})
if request.method == 'GET':
return render(request,'register.html')
# 退出登录
def logOut(request):
request.session.clear()
return redirect('login')
# 首页
def index(request):
users = User.objects.all()
data_user = {}
for u in users:
if data_user.get(str(u.time),-1) == -1:
data_user[str(u.time)] = 1
else:
data_user[str(u.time)] += 1
result = []
for k,v in data_user.items():
result.append({
'name':k,
'value':v
})
username = request.session['username'].get('username')
useravatar = request.session['username'].get('avatar')
userLength = len(User.objects.all())
# 右侧标签数据
# 计算总数据数量
total_data_count = len(data)
# 计算销量最高的 type
total_sales_by_type = data.groupby('type')['sale'].sum().reset_index()
highest_sales_type = total_sales_by_type.loc[total_sales_by_type['sale'].idxmax()]
# 计算销量最多的三个城市
total_sales_by_city = data.groupby('address')['sale'].sum().reset_index()
top_cities = total_sales_by_city.nlargest(3, 'sale')['address'].tolist()
top_cities_joined = '~'.join(top_cities)
# 计算总销量最多的店铺
top_shop = data.loc[data['sale'].idxmax()]
# 遍历数据
# 遍历每一条数据并输出
data_all = data.iterrows()
data_all = data.to_dict(orient='records') # 将 DataFrame 转换为字典列表
context={'username':username,'useravatar':useravatar,'userTime':result,
'userlength':userLength,'total_data_count': total_data_count,
'highest_sales_type': highest_sales_type['type'],
'top_cities': top_cities_joined,
'top_shop': top_shop['shop'],
'data_all': data_all,}
return render(request, 'index.html',context)
# 个人信息
def selfInfo(request):
username = request.session['username'].get('username')
useravatar = request.session['username'].get('avatar')
if request.method == 'POST':
phone=request.POST.get("phone")
email=request.POST.get("email")
password=request.POST.get("password")
selfmes=User.objects.get(username=username)
selfmes.phone=phone
selfmes.email=email
selfmes.password=password
# selfmes.avatar = request.FILES['avatar']
selfmes.save()
userInfo = User.objects.get(username=username)
context = {'username': username, 'useravatar': useravatar, 'userInfo': userInfo}
return render(request, 'selfInfo.html', context)
userInfo=User.objects.get(username=username)
context={'username':username,'useravatar':useravatar,'userInfo':userInfo}
return render(request,'selfInfo.html',context)
def Address_Distribute(request):
username = request.session.get("username").get('username')
useravatar = request.session.get("username").get('avatar')
# Read the Excel file
excel_file_path = r'D:\PycharmProjects\Python农业产品数据可视化分析\spider\data.xlsx'
data = pd.read_excel(excel_file_path) # Load the data from the Excel file
# Extract the 'address' column
places = data['address'].tolist() # Convert the 'address' column to a list
dict1 = {};result1 = [];dict2 = {};result2 = []
for i in places:
if dict1.get(i, -1) == -1:
dict1[i] = 1
else:
dict1[i] += 1
for k, v in dict1.items():
result1.append({
'value': v,
"name": k
})
for i in places:
if i in ['北京', '上海', '广州', '深圳']:
if dict2.get('老一线', -1) == -1:
dict2['老一线'] = 1
else:
dict2['老一线'] += 1
elif i in ['成都', '重庆', '杭州', '武汉', '苏州', '西安', '南京', '长沙', '天津', '郑州', '东莞', '青岛', '昆明', '宁波', '合肥']:
if dict2.get('新一线', -1) == -1:
dict2['新一线'] = 1
else:
dict2['新一线'] += 1
else:
if dict2.get('其他城市', -1) == -1:
dict2['其他城市'] = 1
else:
dict2['其他城市'] += 1
for k, v in dict2.items():
result2.append({
'value': v,
"name": k
})
context = {'result1': result1, 'result2': result2, 'username': username, 'useravatar': useravatar}
return render(request, 'Address_Distribute.html', context)
def Address_And_Title_Wordcloud(request):
username = request.session.get("username").get('username')
useravatar = request.session.get("username").get('avatar')
def MainCode():
import pandas as pd
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from matplotlib import rcParams
import jieba
# 读取 Excel 文件
data = pd.read_excel(r'D:\PycharmProjects\Python农业产品数据可视化分析\spider\data.xlsx')
# 设置中文字体路径
font_path = r'C:\Windows\Fonts\SimHei.ttf' # 请根据实际路径修改
# 生成词云函数
def generate_wordcloud(text, filename):
wordcloud = WordCloud(font_path=font_path, width=400, height=400, background_color='white').generate(text)
plt.figure(figsize=(5, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.savefig(filename)
plt.close()
# 针对 address 字段生成词云
address_text = ' '.join(data['address'].dropna())
generate_wordcloud(address_text, 'address_wordcloud.png')
# 针对 title 字段生成词云
title_text = ' '.join(data['title'].dropna())
# 使用 jieba 分词
title_tokens = jieba.cut(title_text)
filtered_title = ' '.join(title_tokens)
generate_wordcloud(filtered_title, 'title_wordcloud.png')
context = {'username': username, 'useravatar': useravatar}
return render(request, 'Address_And_Title_Wordcloud.html', context)
def get_average_price_by_address(request):
username = request.session.get("username").get('username')
useravatar = request.session.get("username").get('avatar')
unique_addresses = list(set(data['address'].dropna()))
city_name = request.GET.get('cityname')
print(city_name)
# 筛选出指定 address 的数据
filtered_data = data[data['address'] == city_name]
# 计算每个 type 的平均价格
average_prices = filtered_data.groupby('type')['price'].mean().reset_index()
# 计算每个 type 的平均销量
average_sales = filtered_data.groupby('type')['sale'].mean().reset_index()
# 生成结果格式
result1 = {
'source': [
['score', 'amount', 'product']
]
}
# 生成结果格式
result2 = {
'source': [
['score', 'amount', 'product']
]
}
# 添加随机分数和平均价格到结果中
for index, row in average_prices.iterrows():
score = random.uniform(0, 100) # 生成 0-100 的随机值
result1['source'].append([round(score, 1), round(row['price'], 2), row['type']])
# 添加随机分数和平均销量到结果中
for index, row in average_sales.iterrows():
score = random.uniform(0, 100) # 生成 0-100 的随机值
result2['source'].append([round(score, 1), round(row['sale'], 2), row['type']])
context = {'unique_addresses':unique_addresses,'result1': result1,'result2':result2,'username': username, 'useravatar': useravatar}
return render(request,'Average_Price_By_Address.html',context)
def Type_In_Address(request):
username = request.session.get("username").get('username')
useravatar = request.session.get("username").get('avatar')
# 假设数据框包含 'type', 'address', 'price', 'sale' 列
# 计算均价和销量走势
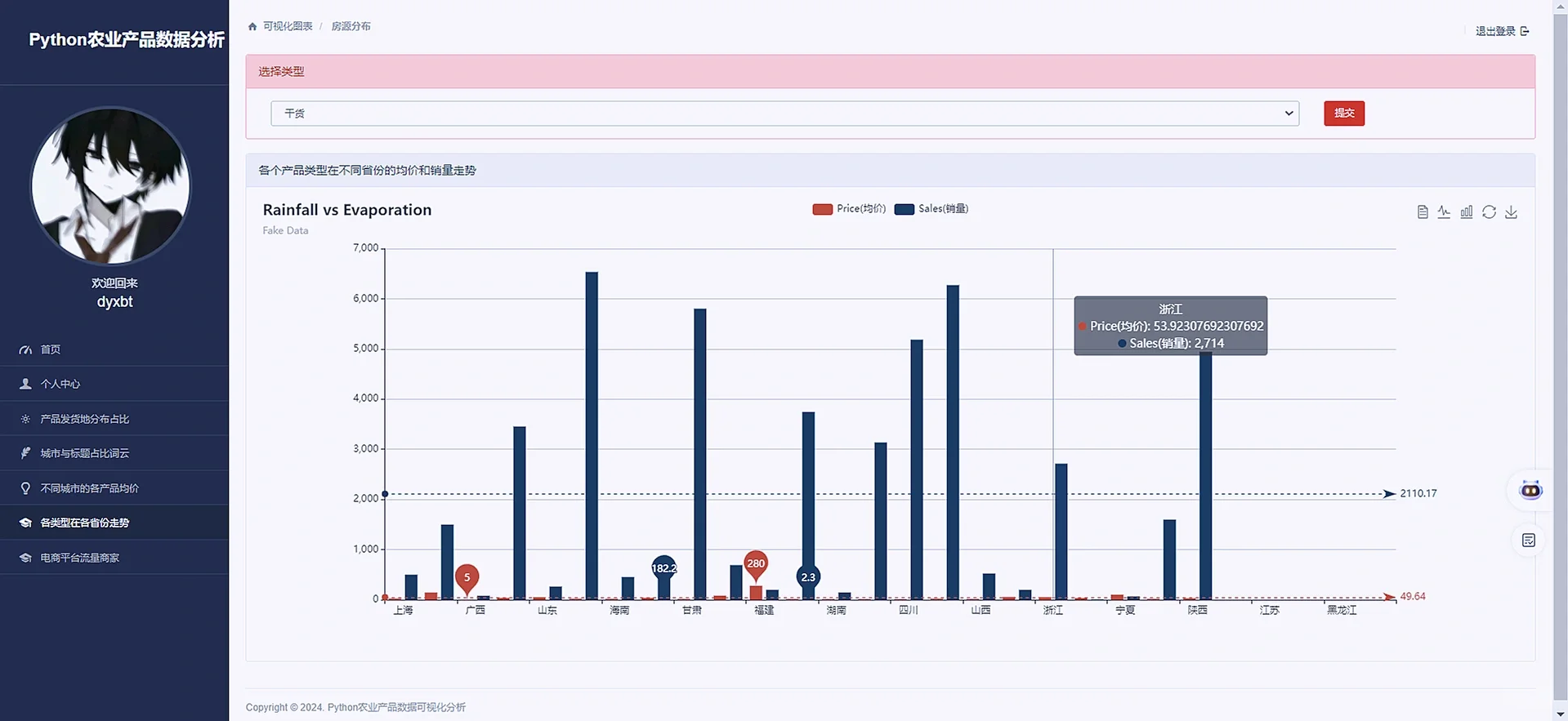
result = data.groupby(['type', 'address']).agg({'price': 'mean', 'sale': 'sum'}).reset_index()
unique_types = list(set(data['type'].dropna()))
# 将没有该类型商品的省份标记为 0
types = data['type'].unique()
provinces = data['address'].unique()
# 新增函数:获取指定类型的平均价格和销量
item_type = request.GET.get('type_goods')
filtered_data = result[result['type'] == item_type]
unique_addresses = list(set(data['address'].dropna()))
average_price = filtered_data['price'].tolist()
average_sales = filtered_data['sale'].tolist()
context = {'username': username, 'useravatar': useravatar,'unique_types': unique_types,'unique_addresses':unique_addresses,'average_price': average_price,'average_sales': average_sales}
return render(request,'Type_In_Address.html',context)
def Hot_Shop(request):
defaultType = '不限'
username = request.session.get("username").get('username')
useravatar = request.session.get("username").get('avatar')
# 假设数据框包含 'type', 'address', 'shop', 'sale' 列
# 计算均价和销量走势
result = data.groupby(['type', 'address']).agg({'price': 'mean', 'sale': 'sum'}).reset_index()
unique_types = list(set(data['type'].dropna()))
unique_addresses = list(set(data['address'].dropna()))
# 新增函数:获取指定类型和地址的销量最高的前5个商店
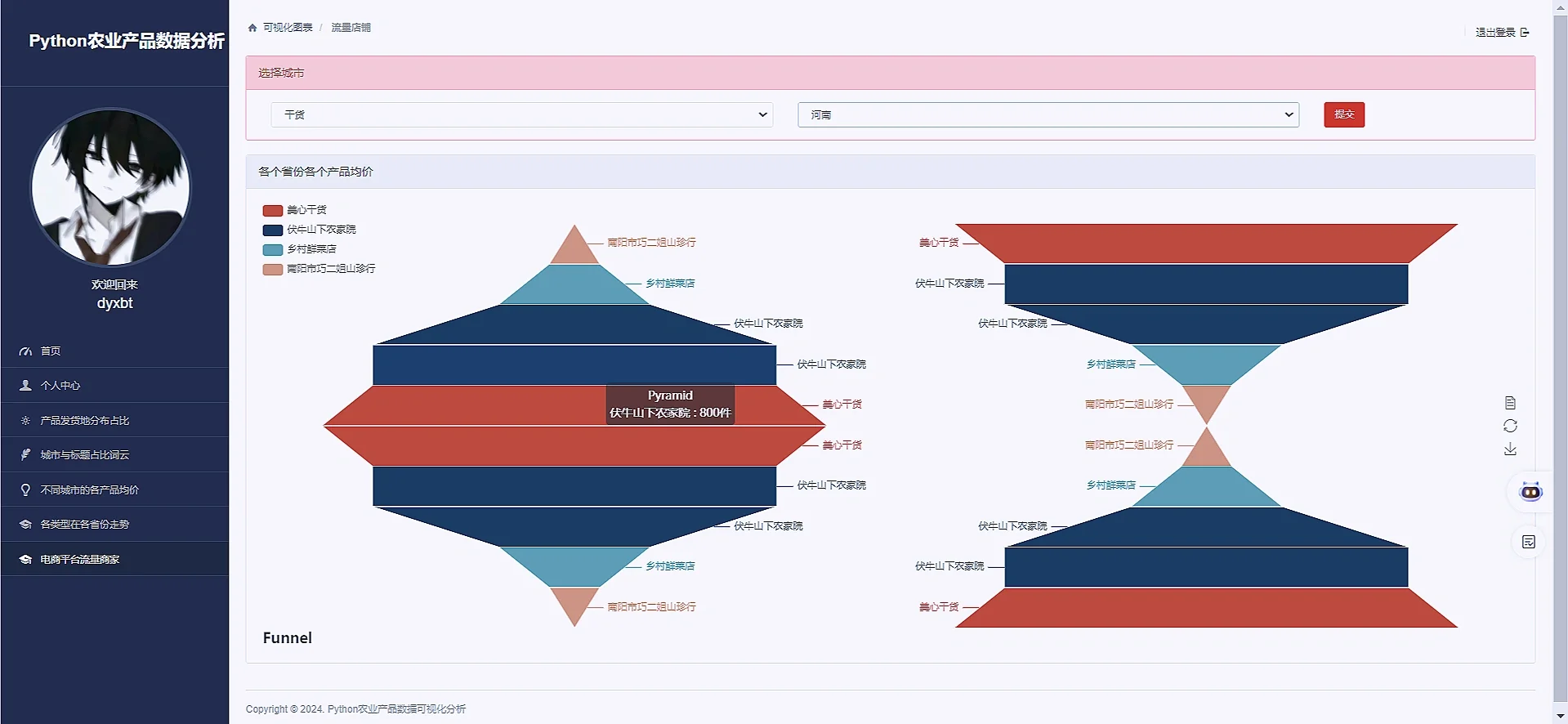
item_type = request.GET.get('typename')
item_address = request.GET.get('cityname')
filtered_data = data[(data['type'] == item_type) & (data['address'] == item_address)]
top_shops = filtered_data.nlargest(5, 'sale')[['shop', 'sale']]
# 转换为指定的数据结构
result_list = [{'value': row['sale'], 'name': row['shop']} for index, row in top_shops.iterrows()]
result_shop = [row['shop'] for index,row in top_shops.iterrows()]
context = {'username': username, 'useravatar': useravatar,'unique_types':unique_types,'unique_addresses':unique_addresses,'result_list': result_list,'result_shop': result_shop,'defaultType': defaultType}
return render(request,'Hot_Shop.html',context)
3.4 项目截图:
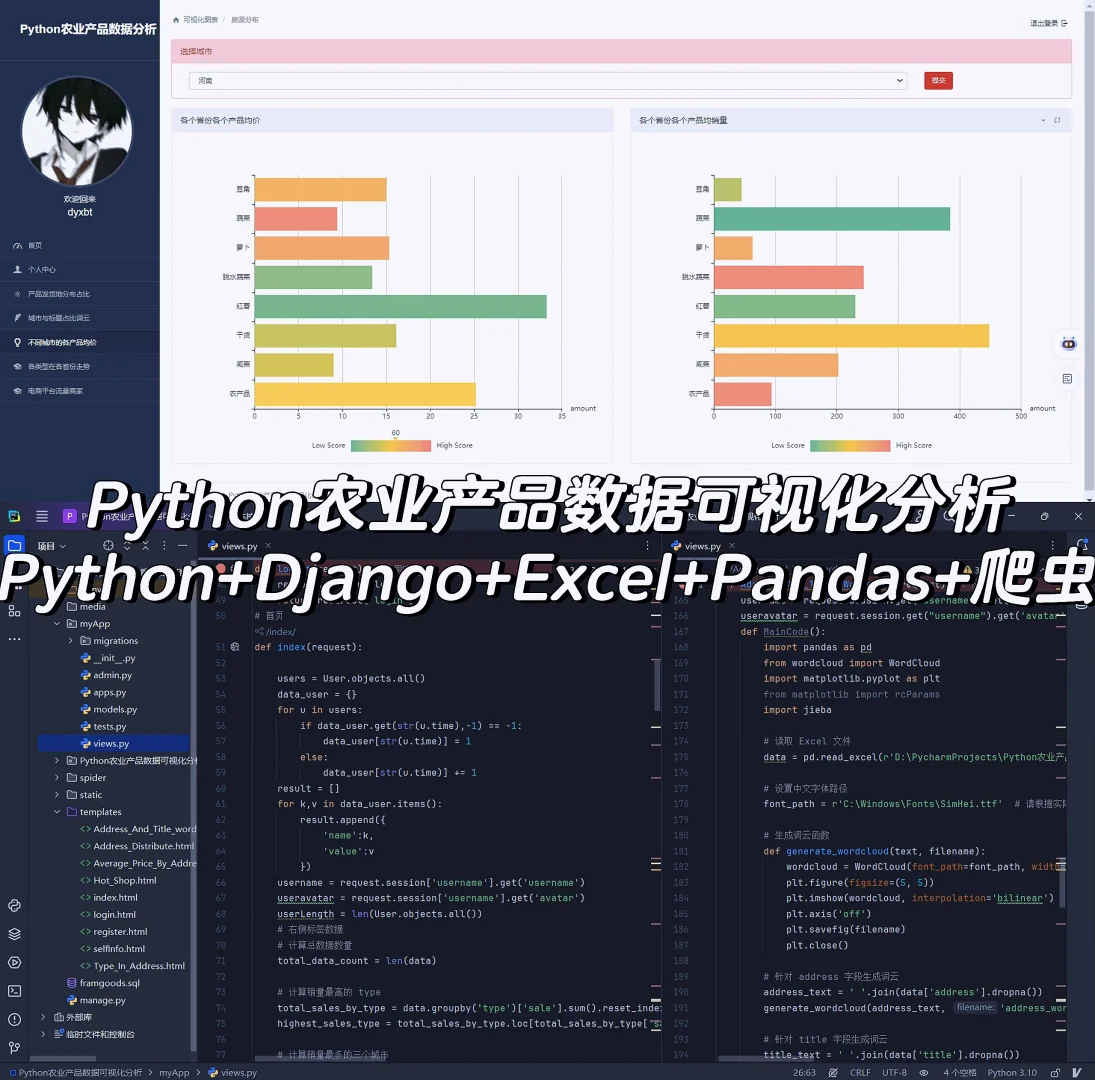
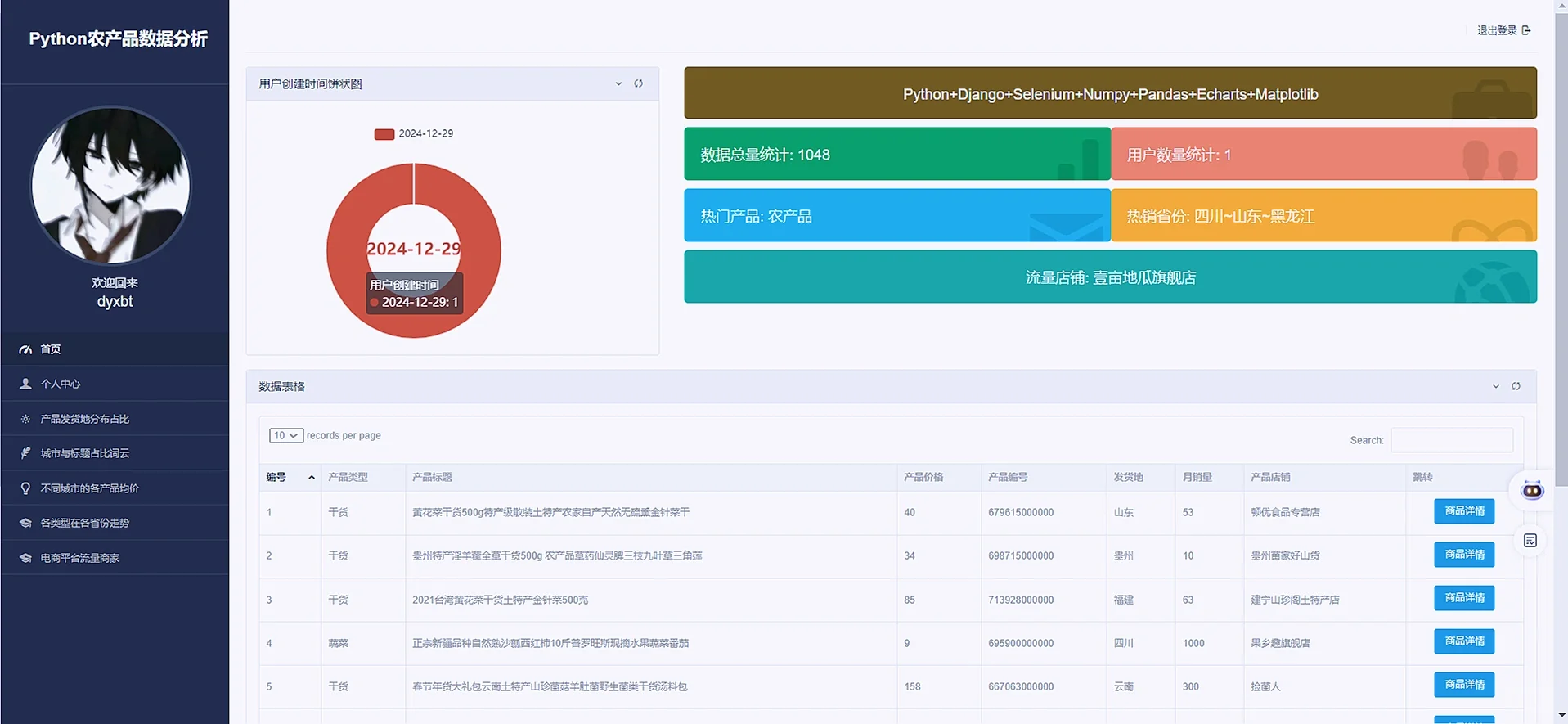
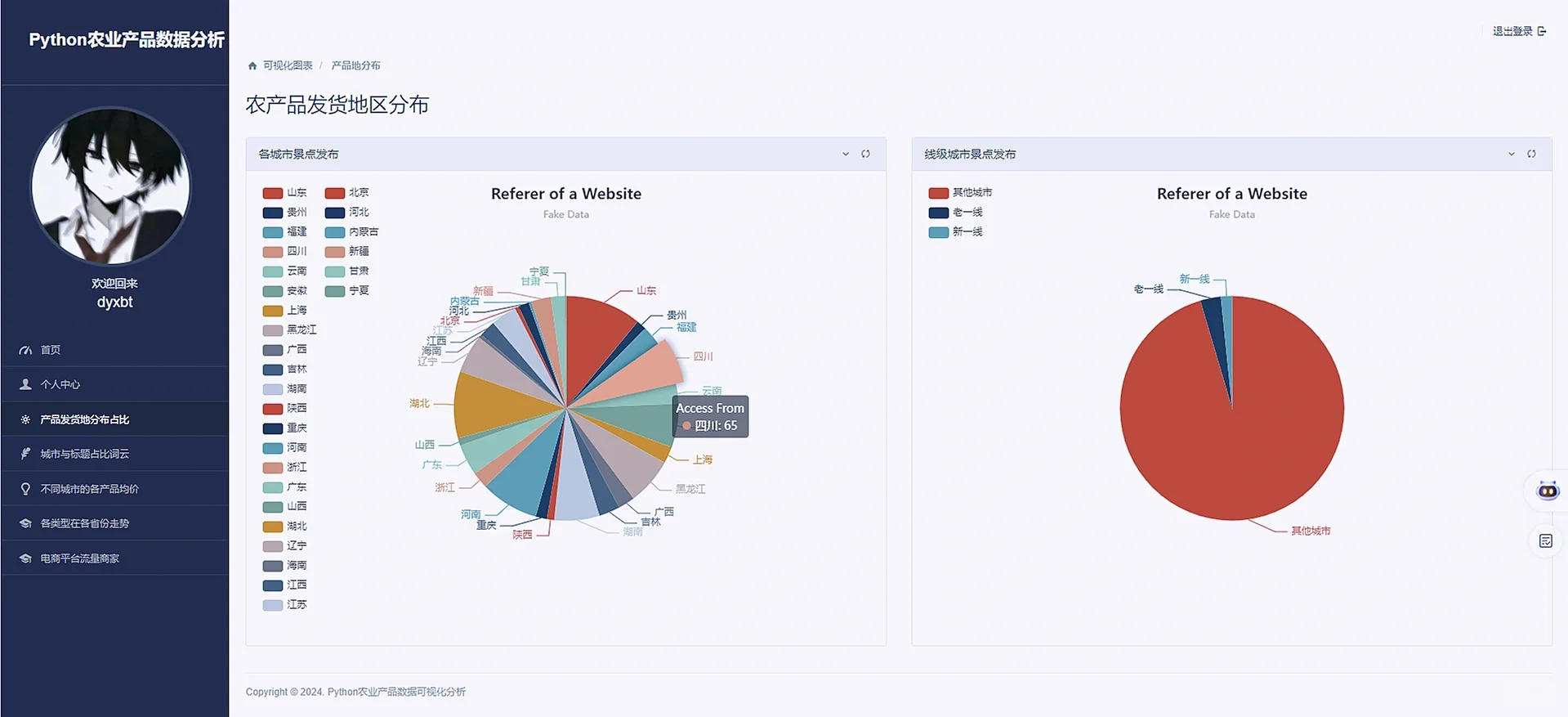

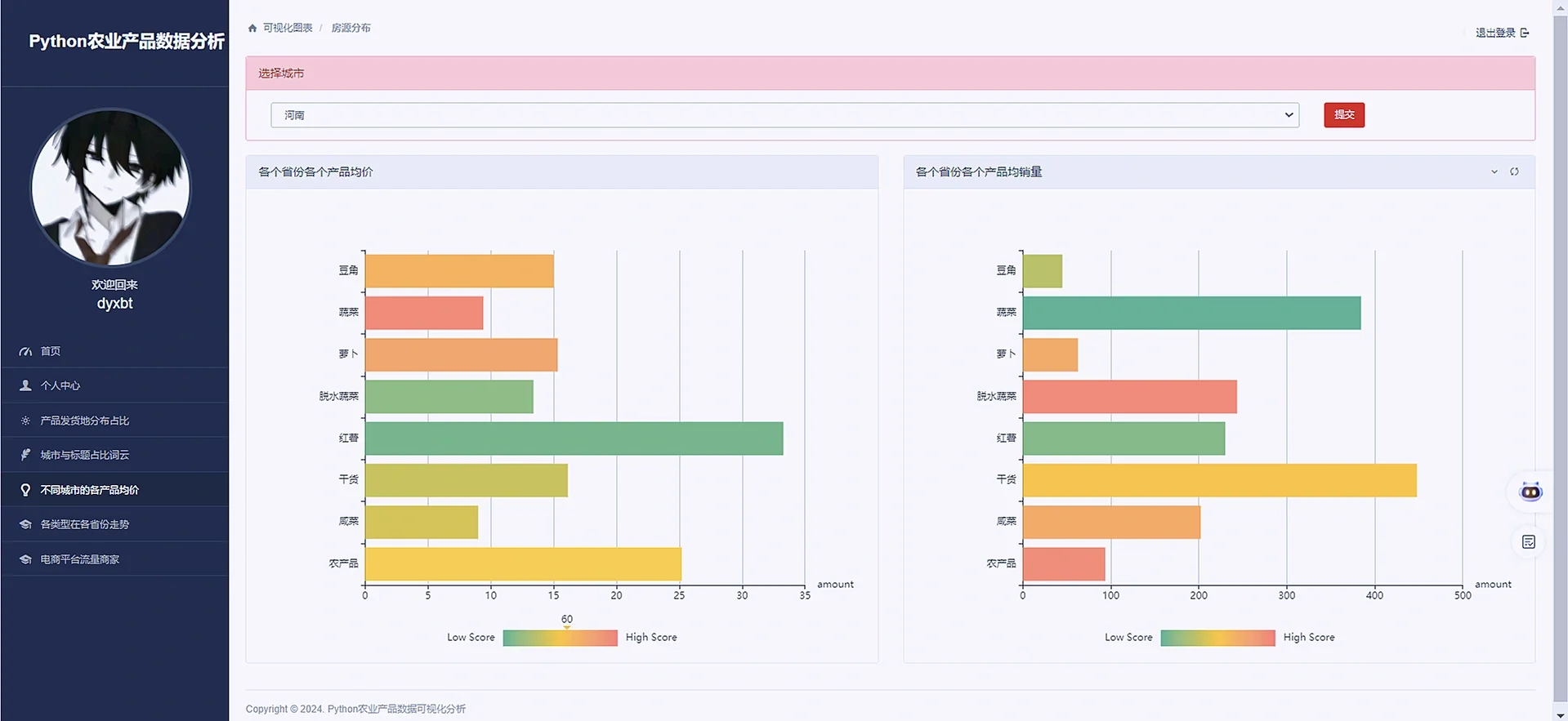
4.最后:
该项目比较简单,对于需要学习数据分析的同学具有很强的学习借鉴意义,数据处理使用的Pandas模块,并且可视化呈现也是大众熟悉的echarts工具,同时基于Python的Web框架进行呈现,项目结构清晰,注释全面,易于理解~

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)