Pytorch框架与经典卷积神经网络与实战第三天|CNN卷积神经网络算法原理2
如果直接用得到的预测值与真实值的差去计算平均误差,可能最后得到的平均误差刚好是0,与真实情况不符,所以引入了回归算法模型。卷积核的通道数跟输入特征图的通道数一定相同,最后输出特征图的通道数为1。步幅和填充操作,都可以控制输出图的大小。计算经过池化层后输出特征图的大小,计算公式与卷积层公式一样,其中FH为感受野。在有监督学习的条件下,每输入一个x,都会得到一个label,即真实值。同时,与卷积层不同
1.跟着《Python从0到1》敲代码
import torch
import pandas as pd
from ply.yacc import resultlimit
#打开 文件 在 {这个路径}
# test = 读取 {内容}
with open('data/scifi.txt','r',encoding='utf-8')as file: #read #encoding编码
text = file.read()
# 1)基本语法
#运算符
# + 加法
print(1+2)
# - 减法
# * 乘法
# / 除法
# % 取模
print(3%2)
# ** 幂
print(2 ** 3)
# // 取整除
print(3 // 2)
#比较运算符
a=1
b=3
print(a == b) #false 不相等 #true 相等
if(a == b):
print("a等于b")
else:
print("a不等于b")
if(a != b):
print("a不等于b")
if(a == 2 and b ==3):
print("a等于2且b等于3")
if(not a == 2):
print("hahaha")
c=3
d=1
c += d #c=c+d
print(c)
#数据类型:number、string、list、tuple、dictionary
aa = 123 #数字
aaa = 123.5 #数字、浮点数 float poit (fp32)
bb = "hello" #字符串
cc = [1,2,5,6] #cc={"hahah","2","哈哈哈"} #列表
dd = (1,2,3,4) #元组
ee = {1,2,3,4} #集合
ff = {"name":"tome","age":18} #字典
# control+/ 加注释的快捷键
# [1,2,5,6]
# [1,2,5,6]
# [1,2,5,6] (3*4)矩阵
# 1)语法细节
# 变量 类
# 常用函数 print打印输出, import, len计算长度 ,type, range范围, enumerate编号, zip, sorted排序, reversed, map, set,list
print(len(cc)) #嵌套,打印cc列表长度
range(10) #0,1,2,3,4,5,6,7,8,9
print(range(10))
#for... in...循环
for x in enumerate(bb): #0:h,1:e,2:l,3:l.4:o
print(x)
print(sorted(cc)) #数字、汉字都可以排列
text = "北京天安门今天天气很好"
print(sorted(set(text)))
voca_size = len(list(sorted(set(text))))
while (a >= b):
print("hello")
break
#自定义方法
def printMyNumber(myElement):
for x in enumerate(myElement):
print(x)
myelem1 = "hello word"
printMyNumber(myelem1)
def getBatch(my_batch):
resulet = torch.tensor(my_batch,dtype=torch.long)
return resultlimit
myBatch = [1,2,3,4,5,6,7,8,9,10]
print(getBatch(cc))
d_model = 512
num_heads = 8
#类
import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads): #第一个参数永远是self,
self.d_model = d_model
self.num_heads = num_heads
def getDModel(self):
return self.d_model
def forward(self):
pass
tf = TransformerBlock(d_model,num_heads)
result = tf.getDMode()
print(result)
#调用第三方的“方法”(通过类,方法名)
import numpy as np
pd.DataFram({"a":[1,2,3],"b":[4,5,6]})
data = np.array()
# #openAI库举例子
# from openai import OpenAI
# client = OpenAI()
#
# completion = client.chat.completions.createl
# model="gpt-3.5-turbo",
# messages=[
# {"role": "system", "content": "你是一个数学助手"},
# {"role": "user", "content":"3的平方根是多少?"}
# ]
#
# print(completion.choices[0].message)
#列表推导式
my_list=[1,2,3,4,5,6,7,8,9,10]
def getSqt(my_list):
result = []
for x in my_list:
if(x <5):
result.append(x**2)
return result
print(getSqt(my_list))
my_r2 = [x**2 for x in my_list if x<5]
print(my_r2)
#特殊print print(f"Input text: {prompt}")
city = "北京"
population = 20000000
print(f"{city}市有{population}人口")
2.复刻跨年烟花
原博客链接Python跨年烟花
1)创建环境

2)进入环境

3)安装工具



4)复制粘贴代码
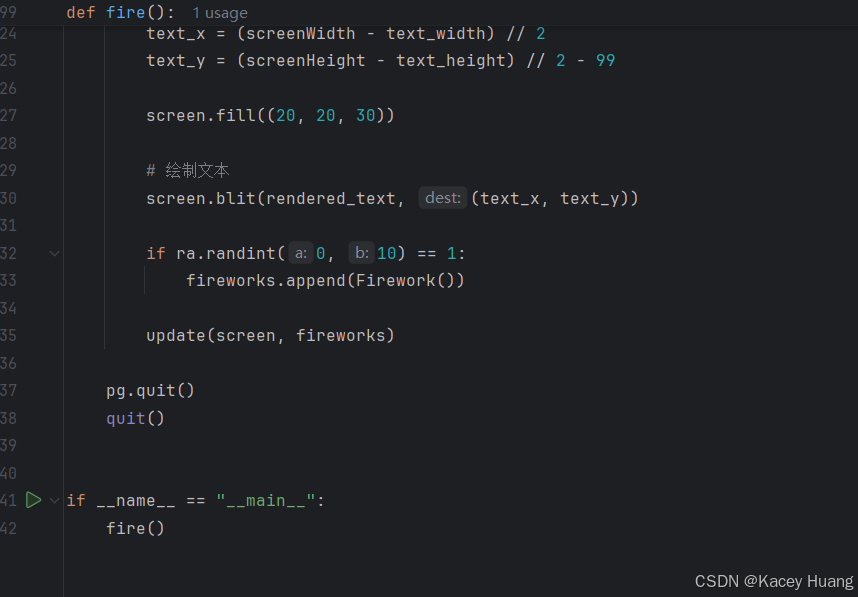
5)跑代码
Python烟花复刻
3.学习哔哩哔哩《PyTorch框架与经典卷积神经网络与实战》
第2章 CNN卷积神经网络算法原理
视频学习链接炮哥带你学
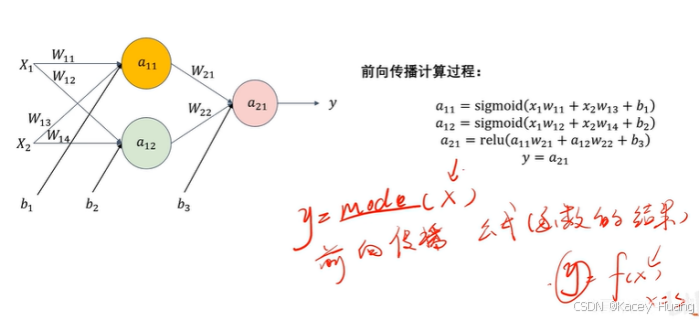
2.8 神经网络的前向传播
前向传播,其实就是模型model的计算过程。
无论是训练、推理、验证还是测试都有前向传播的一个过程。
最后希望模型得出的y与label值的误差越小越好,所以预测值y和真实值label存在误差函数
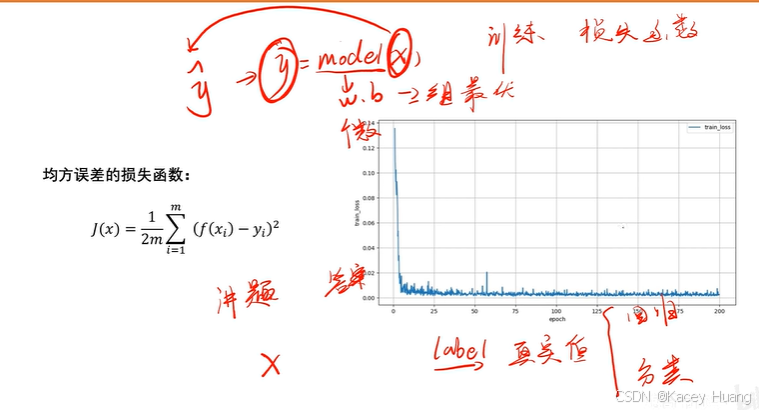
2.9 神经网络的损失函数
在有监督学习的条件下,每输入一个x,都会得到一个label,即真实值。
分类:输出的值是有限的、离散的。
回归:输出的值是连续的。如果直接用得到的预测值与真实值的差去计算平均误差,可能最后得到的平均误差刚好是0,与真实情况不符,所以引入了回归算法模型。
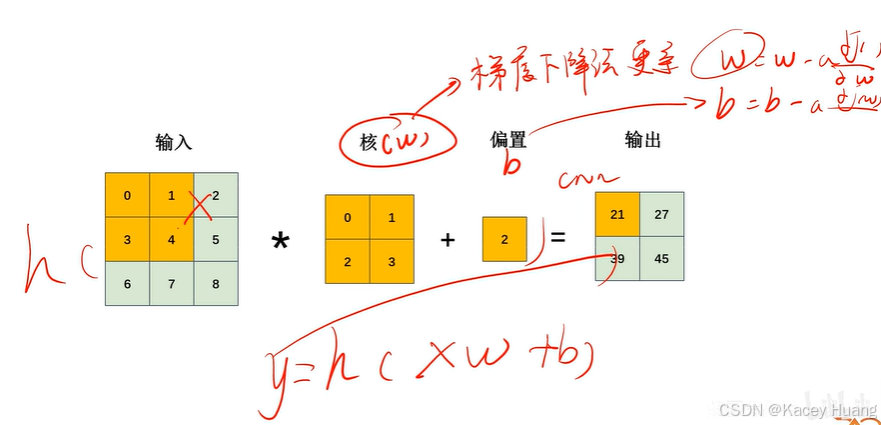
训练的过程就是:前向传播→计算误差→反向传播(更新w、b,梯度下降)
2.10 梯度下降法
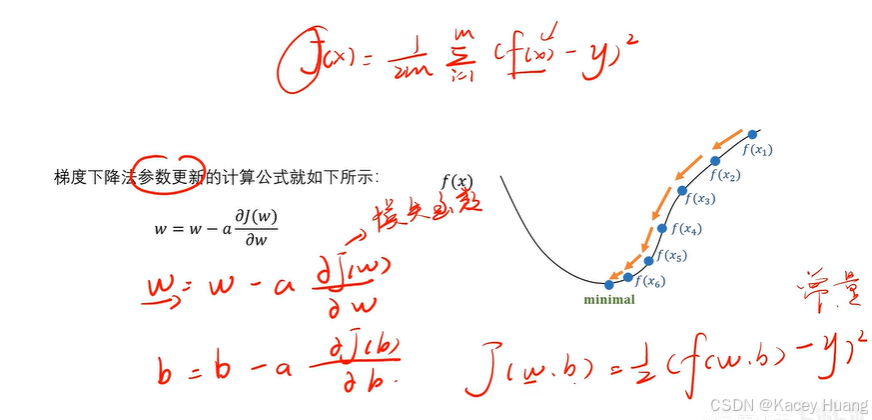
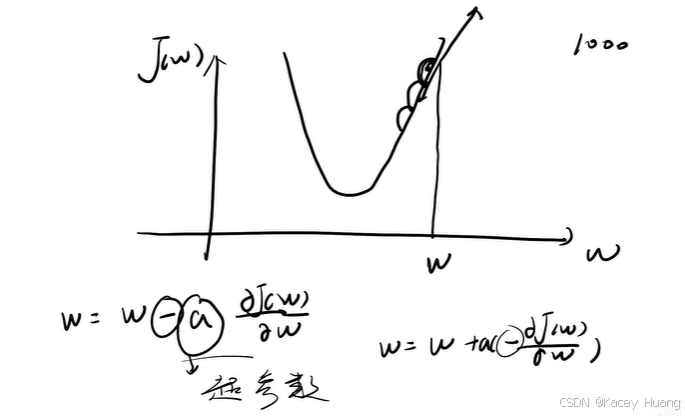
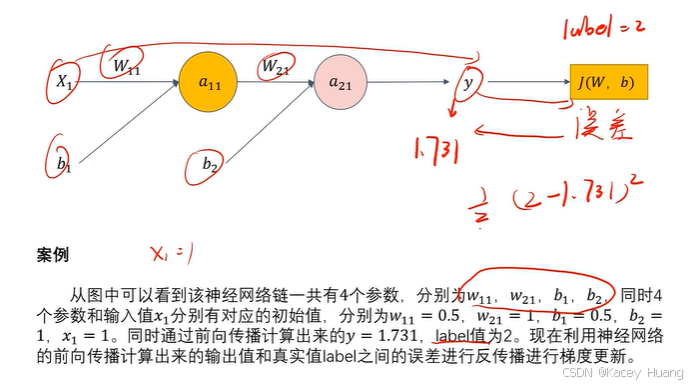
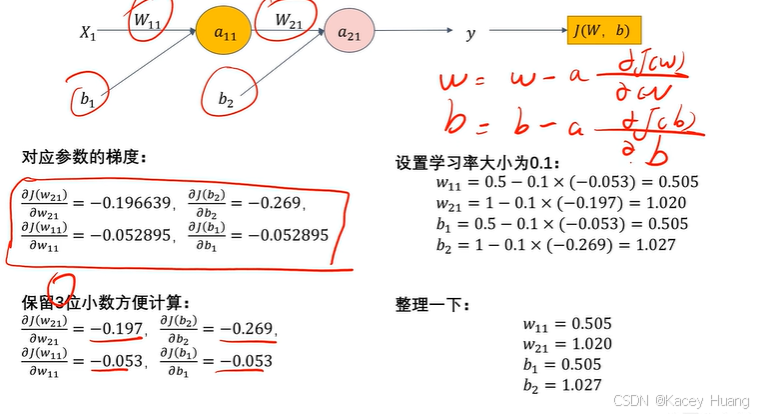
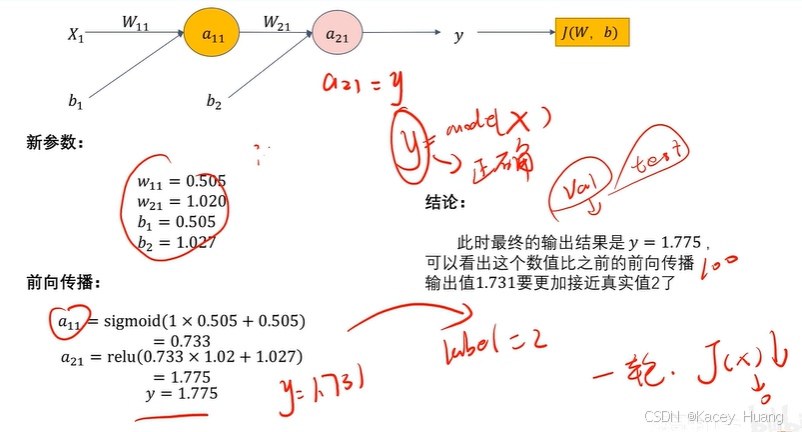
2.11 反向传播计算案例
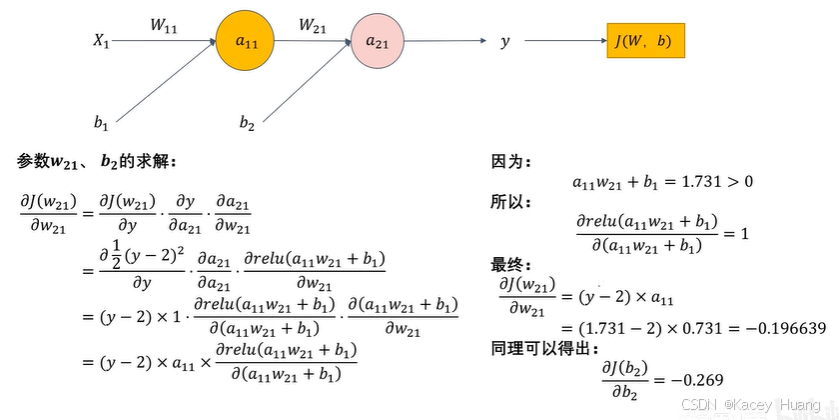
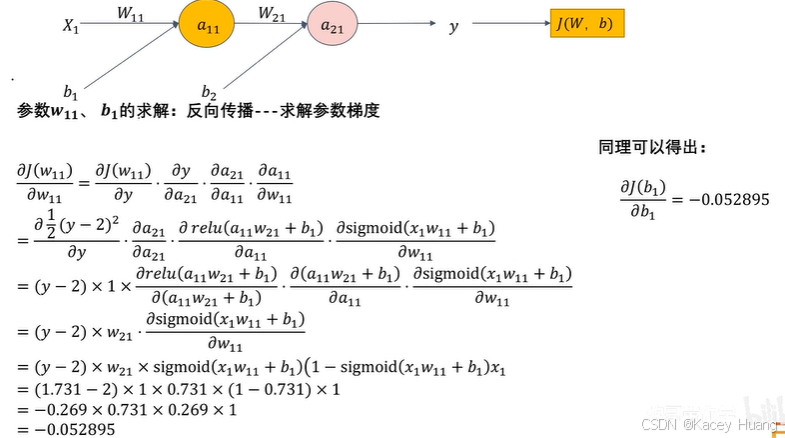
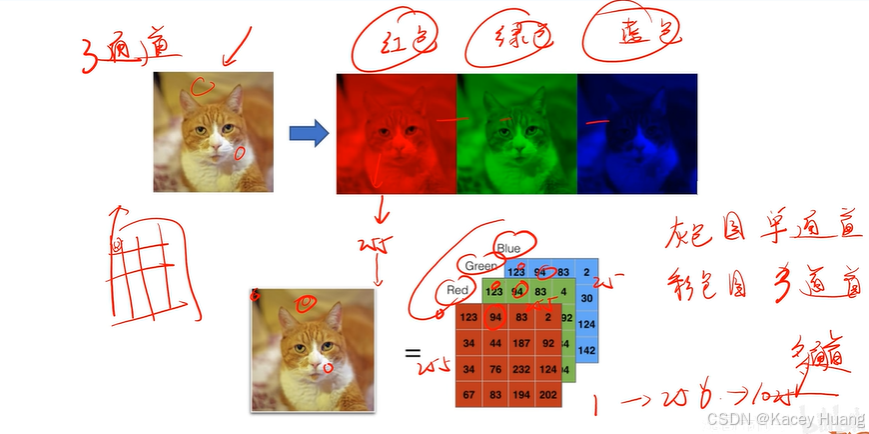
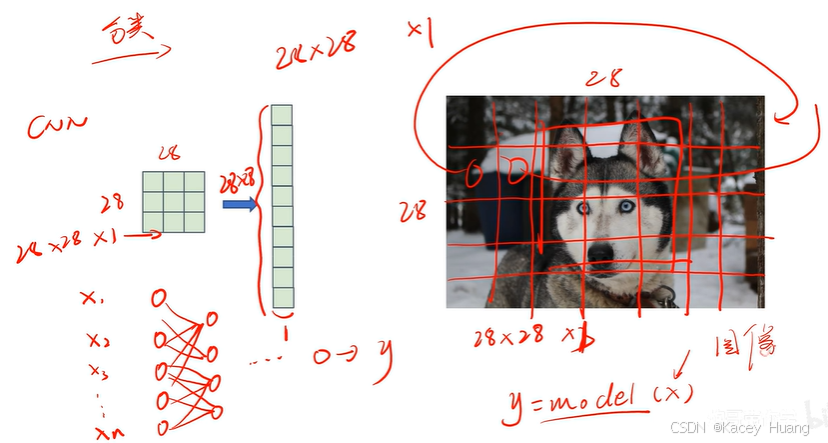
2.12 图像在计算机中的本质
无论是图像分类(resnet)、目标检测(YOLOv5)、分割(VNet)都是以CNN为基础的网络模型算法。
CNN模型的输入一般是图像或者视频流
从0到255,数字越大,颜色越浅,;数字越小,颜色越深。
图像在计算机里就是代表颜色的数字矩阵
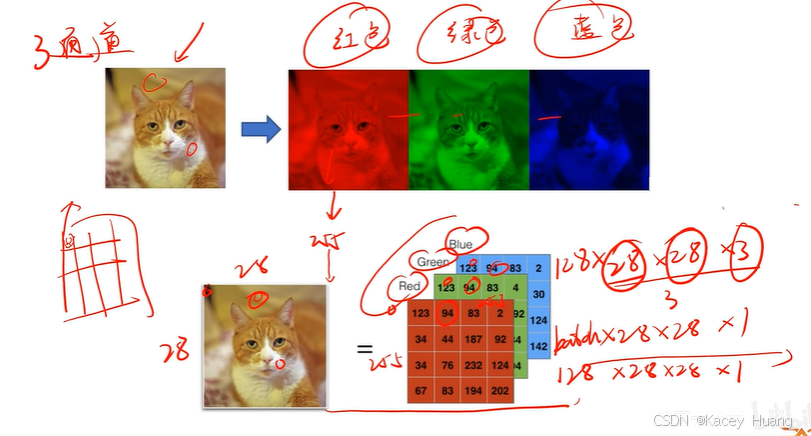
2.13 全连接神经网络存在的问题
如果用全连接神经网络,图像可能被打乱破坏
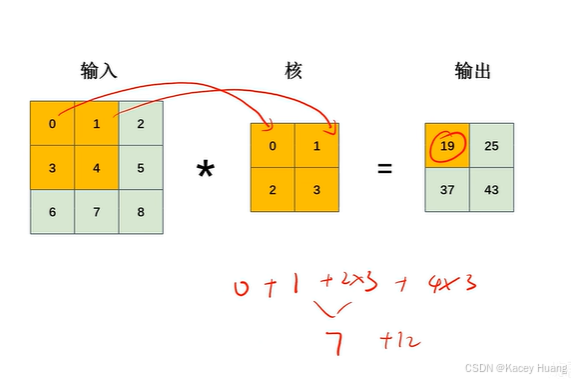
2.14 卷积运算过程
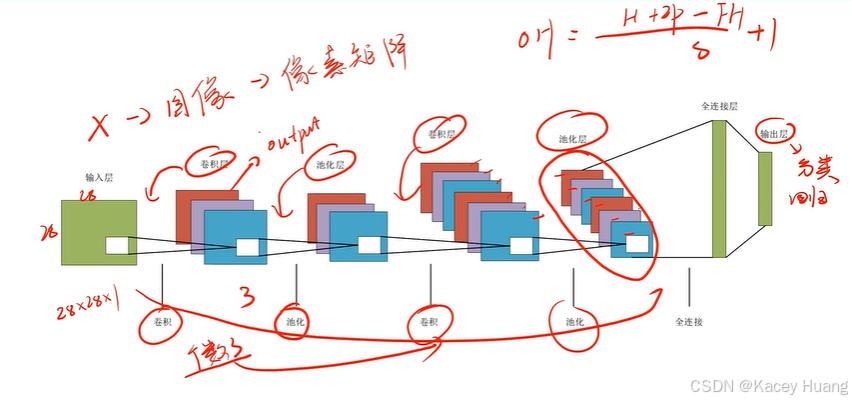
卷积是一种运算。卷积神经网络泛指含有卷积运算的网络,包括Alex、ResNet、YOLOv5。卷积神经网络除了卷积运算,可能还有池化运算
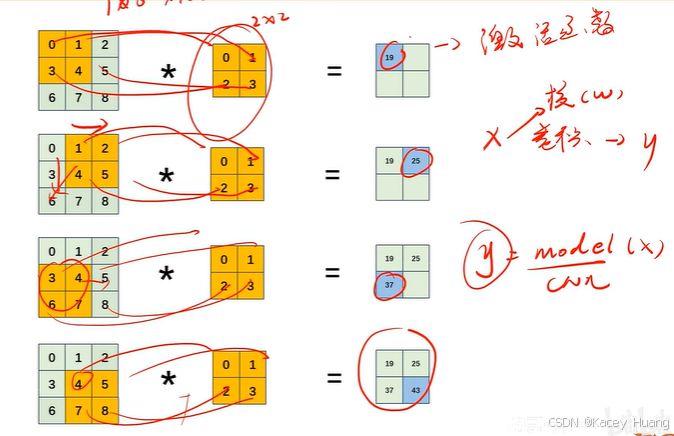
2.15 步幅
步幅就是卷积核与图像相乘时,移动的步数
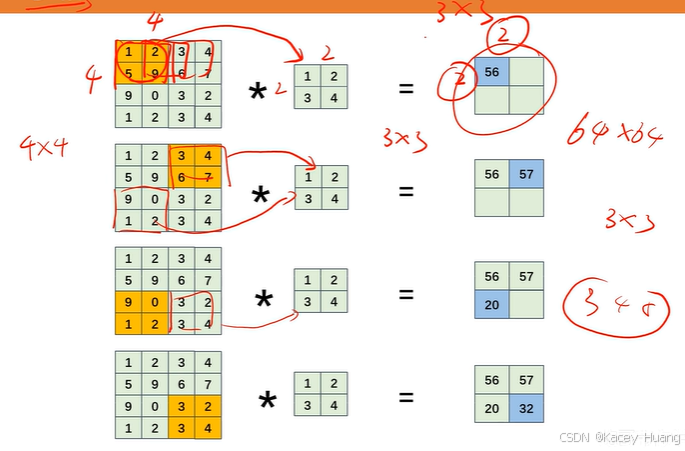
2.16 填充
步幅和填充操作,都可以控制输出图的大小。步幅越大,输出特征图越小;通过填充,输出特征图会变大
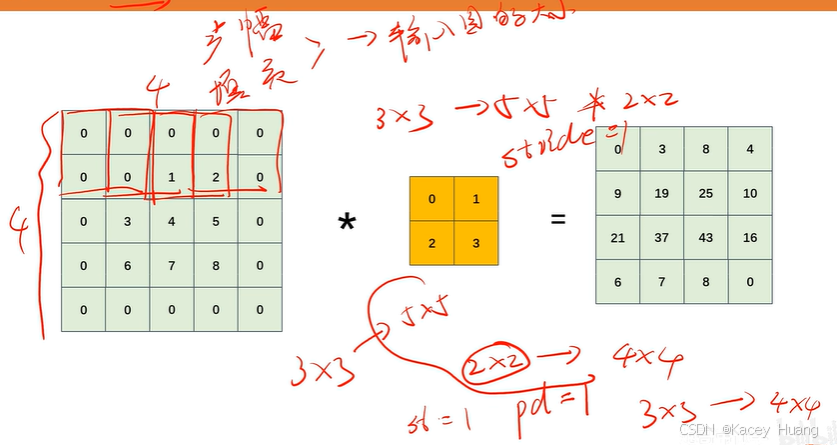
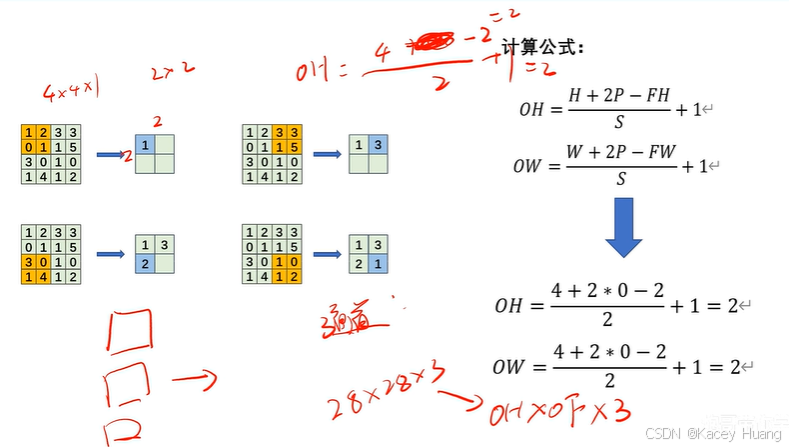
2.17 输出特征图计算公式特征图
P表示填充操作,S表示步幅。
如果计算出来是小数,一般向下取整。(Keavs,Pytorch)
下面这个计算公式非常重要!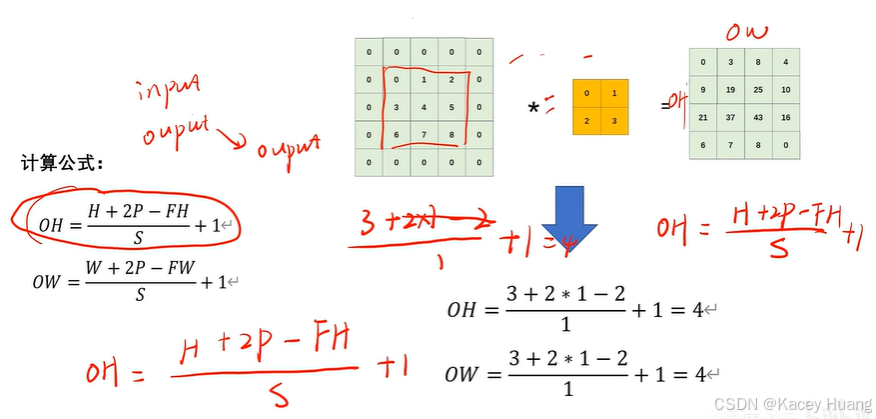
2.18 多通道卷积运算
卷积核的通道数跟输入特征图的通道数一定相同,最后输出特征图的通道数为1。(后面有通道数不为1的情况)
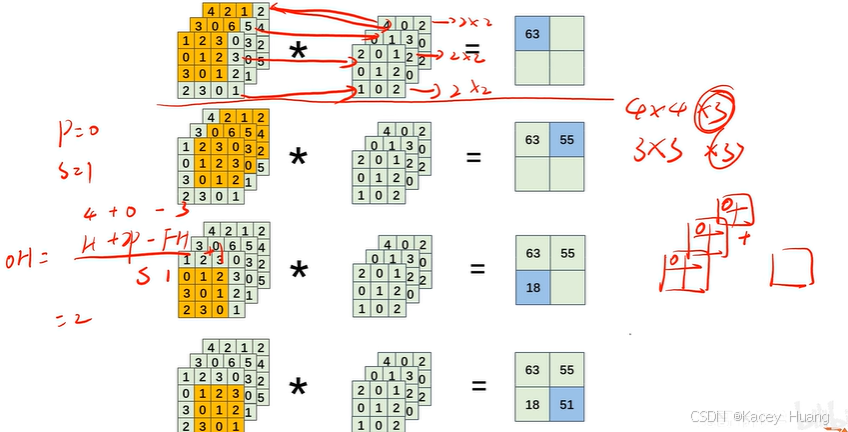
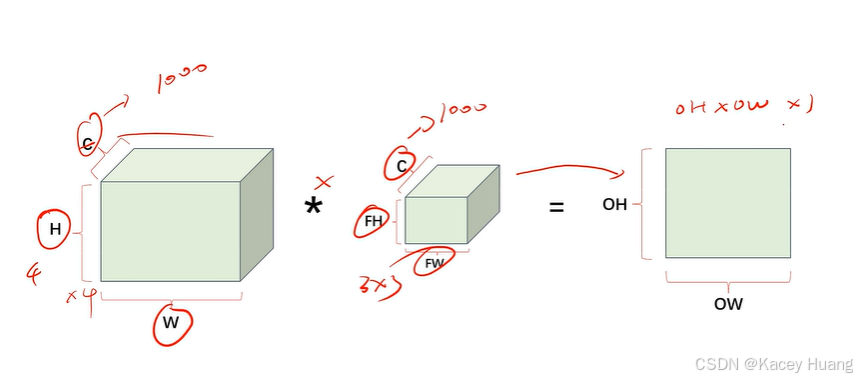
但如果卷积核的数量有FN个,则输出特征图也有FN个通道。
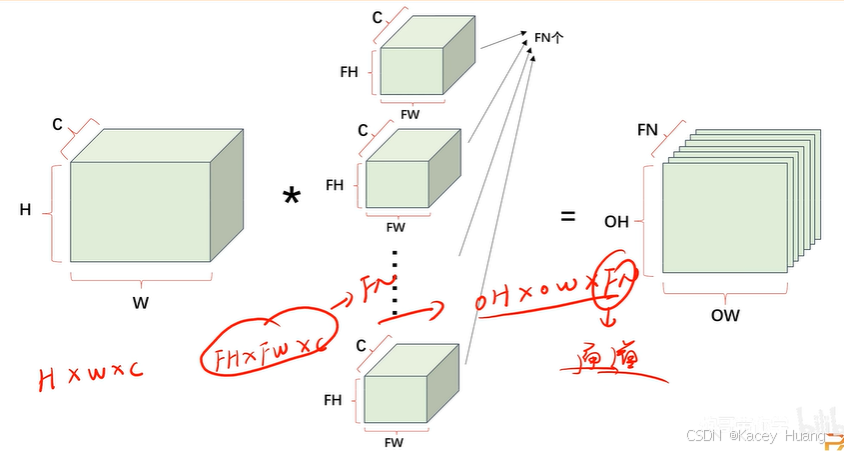

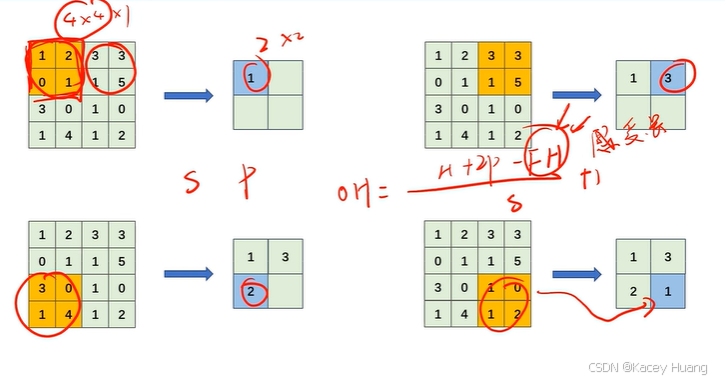
2.19 池化操作
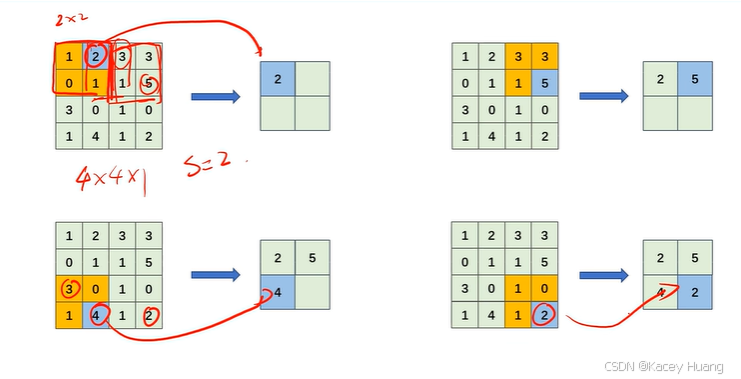
池化层在卷积神经网络中不算神经网络层,因为其不带参数,且没有池化核。池化层只算一步操作。
池化运算——最大池化运算,即找某个区域的最大值。
池化层——平均池化运算,即找一个区域的平均值
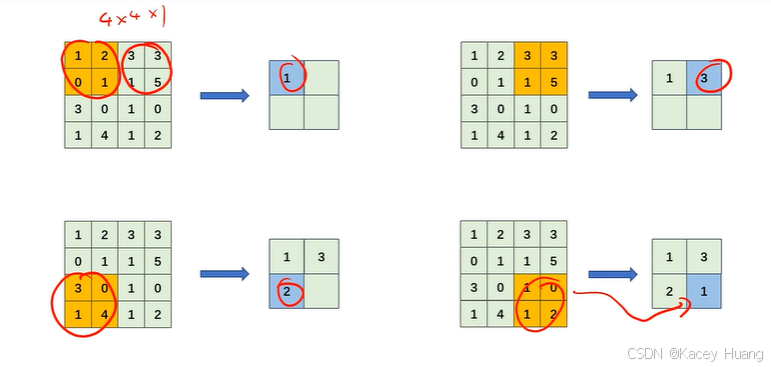
计算经过池化层后输出特征图的大小,计算公式与卷积层公式一样,其中FH为感受野。
同时,与卷积层不同的是,当输入特征图为三通道时,输出特征图也为三通道。
2.20 卷积神经网络整体结构
把理论学完啦!明天开始实战!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)