TimescaleDB | 时序数据库
TimescaleDB:本质是Postgresql数据库的扩展,Postgresql原本关系数据库的能力依旧在,可以同时支持时序表和关系表。
为啥需要时序数据库
● 关系数据库单表数据量大后查询慢(关系数据库单表数据几千万上亿后查询变慢明显)
● 时序数据特点,高写入并发,写入后很少修改
● 数据压缩、自动清理能力
为啥使用TimescaleDB
● 灵活性:TimescaleDB支持标准SQL,对于习惯SQL的团队来说更容易上手,且能更好地与现有的分析工具和框架集成(我们的业务存在多指标关联分析行转列等需求可以方便处理)。
● 扩展性:作为PostgreSQL的扩展,TimescaleDB继承了其强大的生态系统和可扩展性,适用于从小型到超大规模的数据集(比如大模型需要的向量数据库和搜索场景需要的倒排索引和相关性排序)。
● 运维与学习成本:如果团队对PostgreSQL或Mysql熟悉,转向TimescaleDB的迁移成本相对较低。
● 生产成本:同时支持关系表和时序表,不需要部署两套数据库。
● 局限性:相比原生时序数据库如InfluxDB、TDengine等,大数据量时性能略低,存储占用空间更大。
一些概念
TimescaleDB:本质是Postgresql数据库的扩展,Postgresql原本关系数据库的能力依旧在,可以同时支持时序表和关系表。
分区(partition):把数据按时间或者其他维度划分成多个物理表(chunk),每个表就是一个分区。
时序表(超表hypertable):本质上是Postgresql的分区表,相比于分区表提供了自动分区、元数据管理、查询优化、插入优化、数据压缩保留策略、连续聚合能力等。
VACUUM:主要用于清理数据库中的死元组,以及回收空间以提高存储效率和性能。
本地部署
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=123456 -v /home/timescaledb/data:/var/lib/postgresql/data timescale/timescaledb
客户端访问
可以用DBeaver + PostgreSQL驱动
日常使用
普通表的DML及DDL等操作兼容Postgresql语法。
创建时序表
-- 1. 创建普通表
CREATE TABLE IF NOT EXISTS dm_tag_value (
tag_name VARCHAR(200) NOT NULL ,
tag_value VARCHAR(1000) DEFAULT '',
time TIMESTAMP NOT NULL
);
COMMENT ON COLUMN dm_tag_value.tag_name IS '位号名';
COMMENT ON COLUMN dm_tag_value.tag_value IS '位号值';
COMMENT ON COLUMN dm_tag_value.time IS '时间';
-- 2. 创建超表
-- 默认按周分区(字段类型不同默认值不同)
SELECT create_hypertable('dm_tag_value', by_range('time'));
-- 指定分区间隔
SELECT create_hypertable('dm_tag_value', by_range('time', INTERVAL '7 hours'));
-- 修改时间间隔,修改只对未来数据有效(等现有分区结束)
SELECT set_chunk_time_interval('dm_tag_value', INTERVAL '24 hours');
-- 高级能力,时间字段在大字段里面
CREATE TABLE my_table (
metric_id serial not null,
data jsonb,
);
CREATE FUNCTION get_time(jsonb) RETURNS timestamptz AS $$
SELECT ($1->>'time')::timestamptz
$$ LANGUAGE sql IMMUTABLE;
SELECT create_hypertable('my_table', by_range('data', '1 day', 'get_time'));
-- 添加更多分区维度
SELECT add_dimension('m_tag_value', by_hash('tag_name', 4));
查看分区
SELECT show_chunks('dm_tag_value');
-- 根据时间过滤
SELECT show_chunks('dm_tag_value', created_before => INTERVAL '3 months');
SELECT show_chunks('dm_tag_value', older_than => DATE '2017-01-01');
-- 直接查元数据
SELECT *
FROM timescaledb_information.chunks
WHERE hypertable_name = 'dm_tag_value';
查询数据量和空间占用
-- 表数据行数(表大了后count(*)会很慢给,不一定能查出来)
SELECT approximate_row_count('dm_tag_value');
-- 空间占用
SELECT hypertable_size('dm_tag_value');
--更多细节
SELECT * FROM hypertable_detailed_size('dm_tag_value') ORDER BY node_name;
--按分区
SELECT * FROM chunks_detailed_size('dm_tag_value')
ORDER BY chunk_name, node_name;
--获取所有表占用的空间
SELECT hypertable_name, hypertable_size(format('%I.%I', hypertable_schema, hypertable_name)::regclass)
FROM timescaledb_information.hypertables;
-- 查看分区压缩情况
SELECT * FROM hypertable_compression_stats('dm_tag_value');
SELECT pg_size_pretty(after_compression_total_bytes) as total
FROM hypertable_compression_stats('dm_tag_value');
-- 其他方法
SELECT relname AS table_name,
pg_size_pretty(pg_total_relation_size(relid)) AS total_size,
pg_size_pretty(pg_relation_size(relid)) AS table_size,
pg_size_pretty(pg_indexes_size(relid)) AS indexes_size
FROM pg_stat_user_tables
ORDER BY pg_total_relation_size(relid) DESC;
-- 按大小排序
SELECT
table_name,
total_size,
table_size,
indexes_size,
-- 抽取数值并转换单位为字节数
CASE
WHEN total_size LIKE '%kB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint
WHEN total_size LIKE '%MB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint * 1024
WHEN total_size LIKE '%GB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint * 1024 * 1024
ELSE regexp_replace(total_size, '[^0-9]', '', 'g')::bigint
END AS total_size_k
FROM
(
SELECT relname AS table_name,
pg_size_pretty(pg_total_relation_size(relid)) AS total_size,
pg_size_pretty(pg_relation_size(relid)) AS table_size,
pg_size_pretty(pg_indexes_size(relid)) AS indexes_size
FROM pg_stat_user_tables where relname like '%_chunk'
)
ORDER BY total_size_k DESC;
--查看未压缩分区容量
select sum(total_size_m) from (
SELECT
CASE
WHEN total_size LIKE '%kB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint / 1024
WHEN total_size LIKE '%MB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint
WHEN total_size LIKE '%GB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint * 1024
ELSE regexp_replace(total_size, '[^0-9]', '', 'g')::bigint
END AS total_size_m
FROM
(
SELECT relname AS table_name,
pg_size_pretty(pg_total_relation_size(relid)) AS total_size,
pg_size_pretty(pg_relation_size(relid)) AS table_size,
pg_size_pretty(pg_indexes_size(relid)) AS indexes_size
FROM pg_stat_user_tables where relname in (SELECT chunk_name
FROM timescaledb_information.chunks
WHERE range_start >= '2024-07-18' AND range_end < '2024-07-20')
))
--查看压缩分区容量
select sum(total_size_m) from (
SELECT
CASE
WHEN total_size LIKE '%kB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint / 1024
WHEN total_size LIKE '%MB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint
WHEN total_size LIKE '%GB' THEN regexp_replace(total_size, '[^0-9]', '', 'g')::bigint * 1024
ELSE regexp_replace(total_size, '[^0-9]', '', 'g')::bigint
END AS total_size_m
FROM
(
SELECT relname AS table_name,
pg_size_pretty(pg_total_relation_size(relid)) AS total_size,
pg_size_pretty(pg_relation_size(relid)) AS table_size,
pg_size_pretty(pg_indexes_size(relid)) AS indexes_size
FROM pg_stat_user_tables where relname in (select table_name
FROM _timescaledb_catalog.chunk c
where creation_time >= '2024-11-19' and creation_time < '2024-11-20' and table_name like 'compress%')
))
删除分区过期数据
-- 删除多少天之前的分区
SELECT drop_chunks('dm_tag_value', created_before => now() - INTERVAL '3 months');
--删除指定日期之前的分区
SELECT drop_chunks('dm_tag_value','2024-06-21'::timestamp);
--删除所有表历史分区
SELECT drop_chunks(format('%I.%I', hypertable_schema, hypertable_name)::regclass, INTERVAL '3 months')
FROM timescaledb_information.hypertables;
-- 添加分区过期策略
SELECT add_retention_policy('dm_tag_value', drop_after => INTERVAL '6 months');
-- 删除过期策略
SELECT remove_retention_policy('dm_tag_value');
压缩分区
-- 修改表为可压缩,同时指定压缩策略
ALTER TABLE <table_name> SET (timescaledb.compress,
timescaledb.compress_orderby = '<column_name> [ASC | DESC] [ NULLS { FIRST | LAST } ] [, ...]',
timescaledb.compress_segmentby = '<column_name> [, ...]',
timescaledb.compress_chunk_time_interval='interval'
);
-- 压缩指定分区
SELECT compress_chunk('_timescaledb_internal._hyper_1_3_chunk', if_not_compressed => true);
-- 解压指定分区
SELECT decompress_chunk('_timescaledb_internal._hyper_2_2_chunk');
-- 解压所有分区
SELECT decompress_chunk(c, true) FROM show_chunks('dm_tag_value') c;
-- 修改压缩分区后重新压缩
recompress_chunk(
chunk REGCLASS,
if_not_compressed BOOLEAN = false
)
-- 添加压缩策略
SELECT add_compression_policy('dm_tag_value', INTERVAL '30 days');
-- 删除压缩策略
SELECT remove_compression_policy('dm_tag_value');
使用函数
系统函数
Timescale Documentation | Hyperfunctions
自定义函数
CREATE OR REPLACE FUNCTION get_devices_avg_custom_time(
device_names TEXT[],
interval_seconds INT,
duration_minutes INT,
delay_seconds INT
)
RETURNS TABLE (device_name TEXT, interval_time TIMESTAMPTZ, avg_value DOUBLE PRECISION) AS $$
BEGIN
RETURN QUERY
SELECT
tag_name AS device_name,
time_bucket(INTERVAL '1 second' * interval_seconds, app_time) AS interval_time,
AVG(tag_value) AS avg_value
FROM
timeseries_data
WHERE
tag_name = ANY(device_names)
AND app_time >= NOW() - INTERVAL '1 minute' * duration_minutes - INTERVAL '1 second' * delay_seconds
AND app_time < NOW() - INTERVAL '1 second' * delay_seconds
GROUP BY
device_name, interval_time
ORDER BY
device_name, interval_time;
END;
$$ LANGUAGE plpgsql;
SELECT * FROM get_devices_avg_custom_time(
ARRAY['device_1', 'device_2'],
30, -- 每隔30秒
60, -- 最近60分钟
120 -- 延时120秒
);
用自定义函数作为调度任务
CREATE OR REPLACE PROCEDURE user_defined_action(job_id int, config jsonb) LANGUAGE PLPGSQL AS
$$
BEGIN
RAISE NOTICE 'Executing action % with config %', job_id, config;
END
$$;
SELECT add_job('user_defined_action','1h');
SELECT add_job('user_defined_action','1h', fixed_schedule => false);
连续聚合
-- 删除视图
drop MATERIALIZED view cagg_dm_tag_value_agg;
-- 创建视图
CREATE MATERIALIZED VIEW cagg_dm_tag_value_agg
WITH (timescaledb.continuous) AS
select
tag_name,
TIME_BUCKET('5 MIN', app_time) AS app_time,
first(tag_value,app_time) as tag_value ,
first(tag_time,app_time) as tag_time ,
first(quality,app_time) as quality
FROM dm_tag_value
GROUP BY tag_name ,TIME_BUCKET('5 MIN', app_time)
WITH NO DATA;
-- 添加持续聚合运行策略
SELECT add_continuous_aggregate_policy('cagg_dm_tag_value_agg',
start_offset => INTERVAL '3 days',
end_offset => INTERVAL '1 day',
schedule_interval => INTERVAL '1 hour');
-- 手动执行聚合
CALL refresh_continuous_aggregate(
'cagg_dm_tag_value_agg',
(NOW() - INTERVAL '3 days')::timestamp,
(NOW() - INTERVAL '1 day')::timestamp
);
-- 删除聚合策略
SELECT remove_continuous_aggregate_policy('cagg_dm_tag_value_agg');
按小时连续聚合
CREATE MATERIALIZED VIEW dm_tag_value_hourly
WITH (timescaledb.continuous) AS
SELECT
dm.tag_name AS tag_name,
time_bucket(INTERVAL '1 hour', dm.app_time) AS app_time ,
first(tag_value,app_time)
FROM
dm_tag_value dm
GROUP BY
dm.tag_name, time_bucket(INTERVAL '1 hour', dm.app_time);
SELECT add_continuous_aggregate_policy('dm_tag_value_hourly',
start_offset => INTERVAL '1 day',
end_offset => INTERVAL '1 hour',
schedule_interval => INTERVAL '1 hour');
任务
CREATE OR REPLACE PROCEDURE user_defined_action(job_id int, config jsonb) LANGUAGE PLPGSQL AS
$$
BEGIN
RAISE NOTICE 'Executing action % with config %', job_id, config;
END
$$;
SELECT add_job('user_defined_action','1h');
SELECT add_job('user_defined_action','1h', fixed_schedule => false);
SELECT alter_job(1000, schedule_interval => INTERVAL '2 days');
SELECT delete_job(1000);
SET client_min_messages TO DEBUG1;
CALL run_job(1000);
其他
一些常用的元信息表
-- 查看有哪些时序表
SELECT * from timescaledb_information.hypertables;
-- 查看有哪些任务
SELECT * FROM timescaledb_information.jobs;
-- 查看有哪些分区表
SELECT * FROM timescaledb_information.chunks ;-- 查看有哪些连续聚合
SELECT * FROM timescaledb_information.continuous_aggregates;
-- 查看有哪些分区维度
SELECT * from timescaledb_information.dimensions
ORDER BY hypertable_name, dimension_number;
-- 查看压缩情况
SELECT * FROM timescaledb_information.chunk_compression_settings
-- 查看数据库活跃连接情况
SELECT
pid,
usename,
state,
state_change,
wait_event_type,
wait_event,
query
FROM pg_stat_activity
WHERE state = 'active';
行转列
CREATE EXTENSION IF NOT EXISTS tablefunc;
SELECT *
FROM crosstab(
'SELECT app_time, tag_name, tag_value FROM dm_tag_value where tag_name in (''TAG41'',''TAG42'',''TAG43'') and app_time between ''2024-06-04 00:00:00.000'' and ''2024-06-04 23:59:59.000'' ORDER BY 1, 2',
'SELECT DISTINCT tag_name FROM dm_tag_value where tag_name in (''TAG41'',''TAG42'',''TAG43'') ORDER BY 1'
) AS ct (
app_time TIMESTAMPTZ,
tag_v1 NUMERIC,
tag_v2 numeric,
tag_v3 NUMERIC
);
取最近一条记录
-- opt: interpolate、before、after
CREATE OR REPLACE FUNCTION public.get_latest_records(tag_names text[], t timestamp without time zone DEFAULT now(), opt text DEFAULT 'before'::text)
RETURNS TABLE(tag_name character varying, app_time timestamp without time zone, tag_value character varying)
LANGUAGE plpgsql
AS $function$
DECLARE
tag text;
query text;
current_tags text[];
BEGIN
-- 获取当前记录
current_tags := ARRAY(
SELECT a.tag_name
FROM public.get_current_records(tag_names, t, opt) a
);
-- 先返回所有当前记录
RETURN QUERY SELECT * FROM public.get_current_records(tag_names, t, opt);
-- 查询不在当前记录内的标签
FOR tag IN SELECT unnest(tag_names)
LOOP
IF NOT (tag = ANY(current_tags)) THEN
IF opt = 'after' THEN
query := format('
SELECT dm_tag_value.tag_name, dm_tag_value.app_time, dm_tag_value.tag_value
FROM dm_tag_value
WHERE dm_tag_value.tag_name = %L AND dm_tag_value.app_time >= %L
ORDER BY dm_tag_value.app_time ASC
LIMIT 1', tag, t);
ELSIF opt = 'interpolate' THEN
query := format('WITH closest_before AS (
SELECT dm_tag_value.tag_name, dm_tag_value.app_time, dm_tag_value.tag_value
FROM dm_tag_value
WHERE dm_tag_value.tag_name = %L AND dm_tag_value.app_time <= %L
ORDER BY app_time DESC
LIMIT 1
),
closest_after AS (
SELECT dm_tag_value.tag_name, dm_tag_value.app_time, dm_tag_value.tag_value
FROM dm_tag_value
WHERE dm_tag_value.tag_name = %L AND dm_tag_value.app_time > %L
ORDER BY app_time ASC
LIMIT 1
),
combined AS (
SELECT
b.tag_name AS name,
EXTRACT(EPOCH FROM b.app_time) AS time_before,
CAST(b.tag_value AS DOUBLE PRECISION) AS value_before,
EXTRACT(EPOCH FROM a.app_time) AS time_after,
CAST(a.tag_value AS DOUBLE PRECISION) AS value_after
FROM closest_before b
FULL JOIN closest_after a ON 1=1
)
SELECT
COALESCE(combined.name,ca.tag_name, cb.tag_name) AS tag_name,
CAST(%L AS TIMESTAMP) AS app_time,
CASE
WHEN cb.app_time IS NOT NULL AND ca.app_time IS NOT NULL THEN
CAST((value_before + (value_after - value_before) * (EXTRACT(EPOCH FROM TIMESTAMP %L) - time_before) / (time_after - time_before)) AS VARCHAR(1000))
WHEN cb.app_time IS NOT NULL THEN
CAST(cb.tag_value AS VARCHAR(1000))
WHEN ca.app_time IS NOT NULL THEN
CAST(ca.tag_value AS VARCHAR(1000))
ELSE
NULL
END AS tag_value
FROM combined
LEFT JOIN closest_before cb ON 1=1
LEFT JOIN closest_after ca ON 1=1'
, tag, t , tag,t ,t, t);
ELSE
query := format('
SELECT dm_tag_value.tag_name, dm_tag_value.app_time, dm_tag_value.tag_value
FROM dm_tag_value
WHERE dm_tag_value.tag_name = %L AND dm_tag_value.app_time <= %L
ORDER BY dm_tag_value.app_time DESC
LIMIT 1', tag, t);
END IF;
RETURN QUERY EXECUTE query;
END IF;
END LOOP;
END;
$function$
;
SELECT *
FROM get_latest_records(ARRAY['TAG8710_ISYS7.1', 'TAG8728_ISYS7.1', 'TAG8727_ISYS7.1'], '2024-07-18','interpolate');
间隔采样
--按间隔取位号数据
CREATE OR REPLACE FUNCTION get_one_tag_with_interval_seconds(
tag_names TEXT[],
interval_seconds INT,
duration_minutes INT,
delay_seconds INT
)
RETURNS TABLE (tag_name VARCHAR, app_time timestamp,tag_value TEXT) AS $$
BEGIN
RETURN QUERY
SELECT
dm_tag_value.tag_name,
time_bucket(INTERVAL '1 second' * interval_seconds, dm_tag_value.app_time) AS interval_time,
min(concat(cast(dm_tag_value.app_time as VARCHAR),'|',dm_tag_value.tag_value,'|',dm_tag_value.quality)) as app_time_tag_value
FROM
dm_tag_value
WHERE
dm_tag_value.tag_name = ANY(tag_names)
AND dm_tag_value.app_time >= NOW() - INTERVAL '1 minute' * duration_minutes - INTERVAL '1 second' * delay_seconds
AND dm_tag_value.app_time < NOW() - INTERVAL '1 second' * delay_seconds
GROUP BY
dm_tag_value.tag_name, interval_time;
END;
$$ LANGUAGE plpgsql;
多线程执行
DO $$
DECLARE
start_time TIMESTAMPTZ := '2024-07-14 00:00:00';
end_time TIMESTAMPTZ := '2024-07-14 03:00:00';
BEGIN
WHILE start_time < '2024-07-17 18:15:00' LOOP
INSERT INTO dm_tag_value_1 (id,ds_id,tag_name, tag_value,tag_time, app_time,quality,create_time)
SELECT id,ds_id,tag_name, tag_value,tag_time, app_time,quality,create_time
FROM dm_tag_value_his
WHERE app_time >= start_time and app_time < end_time;
start_time := end_time;
end_time := end_time + INTERVAL '3 hours';
END LOOP;
END $$;
数据库参数配置
数据库推荐配置
8核/32G下的推荐配置
-- 8核/32G下的推荐配置
-- 日志时区
ALTER SYSTEM SET log_timezone = 'Asia/Shanghai';
-- 数据时区
ALTER SYSTEM SET timezone = 'Asia/Shanghai';
-- 加载扩展
ALTER SYSTEM SET shared_preload_libraries TO timescaledb,pg_stat_statements;
-- 最大连接数
ALTER SYSTEM SET max_connections TO '100';
-- 预分配给时序库缓存区的内存大小(用于缓存数据和索引,一般系统内存的25%左右)
ALTER SYSTEM SET shared_buffers TO '8GB';
-- 后台工作线程的可用内存
ALTER SYSTEM SET maintenance_work_mem TO '2GB';
-- 查询线程用于排序、hash等操作的内存
ALTER SYSTEM SET work_mem = '64MB';
-- 可用缓存大小(包含shared_buffers缓存和系统自身缓存,一般系统内存的50%-75%)
ALTER SYSTEM SET effective_cache_size TO '24GB';
-- 设置控制检查点的完成目标时(数据从内存刷到磁盘),值范围从 0 到 1,数字越大表示越慢,相对的对查询影响抖动越小
ALTER SYSTEM SET checkpoint_completion_target = '0.9';
-- 设置随机访问页面的成本,默认值是4(根据磁盘类型不同修改,一般HDD硬盘设置4,SSD硬盘可以设置1.1或2)
ALTER SYSTEM SET random_page_cost TO 4;
-- 为表和索引收集统计信息的目标行数,提高这个值可以让优化器获取更详细的统计数据,帮助生成更优化的查询计划。在有复杂查询的情况下增加这个值,可以提高查询性能,但同时会耗更多资源。
ALTER SYSTEM SET default_statistics_target = '100';
-- IO并发限
ALTER SYSTEM SET effective_io_concurrency = '20';
-- 写缓冲区大小
ALTER SYSTEM SET wal_buffers = '32MB';
-- WAL文件最大尺寸,设置较大的 WAL 文件能在高负载的写操作情况下,减少检查点的发生频率,提高性能。
ALTER SYSTEM SET max_wal_size TO '4GB';
-- WAL文件最小尺寸,较大的最小 WAL 大小可以在写负载下降时保留一些 WAL 文件,避免频繁的文件创建和删除,提高性能。
ALTER SYSTEM SET min_wal_size TO '1GB';
-- 后台工作线程最大数量
ALTER SYSTEM SET max_parallel_maintenance_workers TO 8;
-- 每个事务允许的最大锁定数量允许最大锁表/分区数量(因为分区拆的比较多,所以需要设置比较大)
ALTER SYSTEM SET max_locks_per_transaction to 2048;
-- 最大工作进程数量
ALTER SYSTEM SET max_worker_processes = '32';
-- 一个查询可用的最大并行工作进程数量
ALTER SYSTEM SET max_parallel_workers = '16';
-- 允许尝试使用(Huge Pages)能力,内存大于等于32G可以配置
ALTER SYSTEM SET huge_pages = 'try';
-- 限制每次解压最大影响行数,0表示不限制
ALTER SYSTEM SET timescaledb.max_tuples_decompressed_per_dml_transaction = 0;
-- 触发自动分析的阈值,即表中最少达到多少修改后会触发分析,高该值可减少分析的频率,节省资源,但也可能导致统计数据过时。
ALTER SYSTEM SET autovacuum_analyze_threshold = 10;
-- 触发自动分析的比例,设置较小的比例可以让自动分析更频繁地运行,帮助保持统计信息更新,但也会增加数据库的开销
ALTER SYSTEM SET autovacuum_analyze_scale_factor = 0.01;
-- 记录执行时间超过指定毫秒的语句的日志,这里是 30000 毫秒
ALTER SYSTEM SET log_min_duration_statement = '30000';
-- 记录指定类型SQL的日志,none表示不记录,all表示记录所有
ALTER SYSTEM SET log_statement = 'none';
-- 是否记录每个sql的执行时间off表示不记录
ALTER SYSTEM SET log_duration = 'off';
-- 记录日志格式
ALTER SYSTEM SET log_line_prefix = '%m [%p]: [%l-1] db=%d,user=%u,app=%a,client=%h ';
-- 设置检查点的最大间隔时间
ALTER SYSTEM SET checkpoint_timeout = '10min';
常见问题
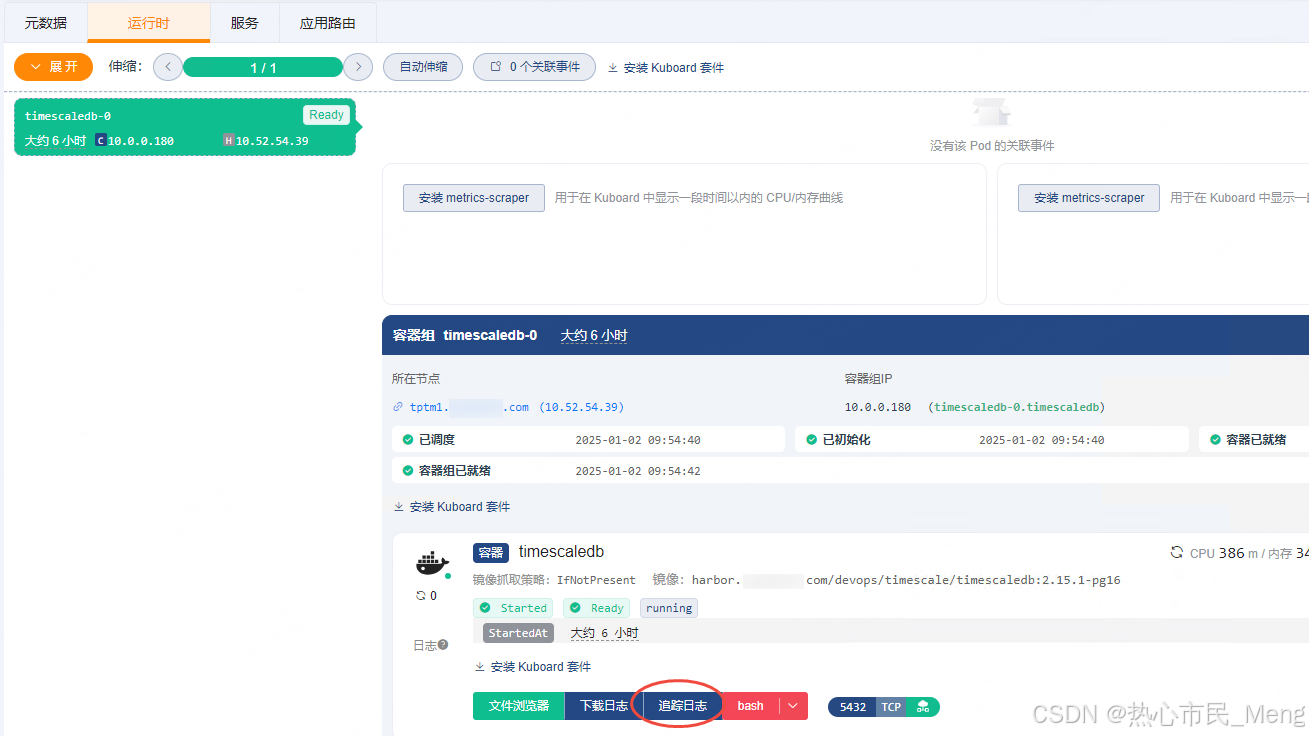
有问题可以先看日志,怎么看日志?
登录Kuboard,找到devops空间下的timescaledb容器,追踪日志
1. 数据库频繁recover重启
原因:一次查询数据量多需要内存多,可用内存不够,一般是缓存空间不够。
排查:进Kuboard找到TimescaleDB的内存使用情况,是不是已经满负荷运作。
如果内存已经100%:可能需要考虑扩容,或者修改查询,减少单次请求数据量。
如果内存没用满:检查下数据库配置是否合理,具体根据内存大小设置合理值(参考数据库配置)
show shared_buffers;
show effective_cache_size;
2. could not resize shared memory segment “/PostgreSQL.xx“ to xx bytes: No space left on device问题
原因:
1. PostgreSQL动态共享内存过小,Docker的默认/dev/shm大小为64MB
解决:修改PostgreSQL共享内存的大小为256M
2. 单次查询涉及分区过多,超过配置限制
show max_locks_per_transaction;
-- 修改配置需要重启数据库
ALTER SYSTEM SET max_locks_per_transaction to 2048;
3. 查询慢问题
1. 检查数据库负荷(内存、CPU),是否资源满了
2. 查看执行计划,是否走到索引
EXPLAIN analyze
select * from dm_tag_value dtv where tag_name='XX.LJS.FIQ_8A196.SUM' and app_time > '2024-12-30 23:50:50' order by app_time
4. 连接卡住问题,时序表数据量大了后,一次普通的查询重复执行有概率会出现连接卡死,要等几分钟才释放。
原因:目前看可能是bug(druid分页查询或数据库函数内直接 RETURN QUERY返回数据时会出现)
解决:用数据库函数,在数据库函数里使用RETURN QUERY EXECUTE query 方式返回数据,比如
query := 'WITH RankedData AS (
SELECT
tag_name,
app_time,
tag_value,
ROW_NUMBER() OVER (PARTITION BY tag_name ORDER BY app_time desc) as row_num
FROM
dm_tag_value
WHERE
app_time <= $2 AND app_time > $1 AND tag_name = ANY ($4::text[])
)
SELECT
tag_name,
app_time,
tag_value
FROM
RankedData
WHERE
row_num = 1;';
RETURN QUERY EXECUTE query USING t1, t ,t2, tag_names;
``
## **<font style="color:#1a1a1a;">最佳实践</font>**
### **<font style="color:#1a1a1a;">建表</font>**
<font style="color:#333333;">时序表必须要有</font><font style="color:#333333;">TIMESTAMP列,用于分区(分区列会默认建索引)</font>
<font style="color:#333333;">示例:</font>
```sql
begin;
--建普通表
CREATE table if not exists tpt_warning_record (
warning_time TIMESTAMP NOT NULL,
tag_name VARCHAR(200) NOT NULL ,
info TEXT DEFAULT NULL
);
COMMENT ON COLUMN tpt_warning_record.warning_time IS '预警时间';
COMMENT ON COLUMN tpt_warning_record.tag_name IS '位号';
COMMENT ON COLUMN tpt_warning_record.info IS '预警信息';
--转时序表,同时会自动创建索引
SELECT create_hypertable('tpt_warning_record', 'warning_time', chunk_time_interval => interval '1 day');
--建其他索引,比如位号
CREATE INDEX idx_tpt_warning_record_time_name ON tpt_warning_record (tag_name,warning_time desc);
--设置分区保留时间30天
SELECT add_retention_policy('tpt_warning_record', INTERVAL '30 days');
--修改表为支持压缩
ALTER TABLE dm_tag_value SET (timescaledb.compress);
--设置压缩策略压缩30天前数据,每天执行
SELECT add_compression_policy('tpt_warning_record', compress_after => INTERVAL '7d');
end;
1. 非分区列要建索引的话,需要跟分区列建复合索引,除时间分区列外其他分区列尽量不要超过一个.
2. 分区大小规范:为了提高性能最好是整个分区能完全加载到内存,建议每个分区存储数据量大小是内存的四分之一,比如内存是4G那分区不要超过1G,具体多少条记录根据每行数据大小估算,以此来确定是7天还是1天或几个小时一个分区。
3. 建索引的时候可以选择正序或倒序,根据实际业务查询选择,比如使用的时候是时间倒序那么索引语句可以这样,如果查询排序和索引排序方向不一致影响性能。
CREATE INDEX idx_tpt_warning_record_time_name ON tpt_warning_record (tag_name,warning_time desc);
写入性能
1. 数据插入尽量使用批量插入提升性能
2. 数据同时会插入到多个分区,可以采用并行插入提升性能
查询性能
时序数据表一般存储大量数据,使用不当会严重影响性能并且容易出现内存耗尽.尽可能的减少扫描行数.
1. 对于只插入不更新的数据尽量尽早压缩(比如压缩一天前数据),压缩后能大大提升按索引的查询性能.
2. 查询都要带上索引字段(都带上时间分区列字段,减少扫描行数),不走索引的全量扫描的性能和普通数据库没有区别,表数据量大了就很慢。
3. 因为数据库内存有限,查询结果大的情况使用分页查询,带上limit数量
4. 查询不要随意order by,尽量走默认排序(order by 和索引顺序一致)
5. 时间过滤时不要用时间函数,会影响性能
比如:
--错误如下:
SELECT app_time,tag_name,tag_value,quality FROM dm_tag_value WHERE DATE(app_time) = '2024-06-19'
--正确如下:
SELECT app_time,tag_name,tag_value,quality FROM dm_tag_value WHERE app_time >= '2024-06-19' and app_time < '2024-06-20'
1. 时序数据库有一些特有函数可以大大提高性能。
比如:按时间窗口聚合
SELECT time_bucket('1 day', time_column) AS day, AVG(value_column)
FROM table_name
GROUP BY day;
比如:用物理视图做连续预聚合,适合要对大时间范围做聚合的场景
CREATE MATERIALIZED VIEW continuous_aggregate_view WITH (timescaledb.continuous) AS
SELECT time_bucket('1 day', time_column) AS day, AVG(value_column)
FROM table_name
GROUP BY day;
SELECT add_continuous_aggregate_policy('continuous_aggregate_view',
start_offset => INTERVAL '1 month',
end_offset => INTERVAL '1 day',
schedule_interval => INTERVAL '1 hour');
其他一些高级查询:Timescale Documentation | Perform advanced analytic queries
性能优化
-- 查看vacuum和autovacuum情况
SELECT
schemaname,
relname,
last_vacuum,
last_autovacuum,
vacuum_count,
autovacuum_count
FROM
pg_stat_user_tables;
SELECT relname,
last_vacuum,
last_autovacuum,
vacuum_count,
autovacuum_count
FROM pg_stat_user_tables
WHERE relname like '%chunk';
-- 手动vacuum
VACUUM ANALYZE dm_tag_value;
-- vacuum分区表
VACUUM ANALYZE _timescaledb_internal._hyper_1_7_chunk;
-- 打开慢查询日志
ALTER SYSTEM SET log_min_duration_statement = '30000';
ALTER SYSTEM SET log_statement = 'none';
ALTER SYSTEM SET log_duration = 'off';
ALTER SYSTEM SET log_line_prefix = '%m [%p]: [%l-1] db=%d,user=%u,app=%a,client=%h ';
SELECT pg_reload_conf();
数据管理和维护
1. 使用 add_retention_policy 定期删除旧数据,管理数据库的存储。
2. 定期使用 VACUUM 和 ANALYZE 维护表,保持数据库性能。
3. 慢SQL查询
-- 安装扩展
CREATE EXTENSION IF NOT EXISTS pg_stat_statements;
-- 查询慢sql
SELECT *
FROM pg_stat_statements
ORDER BY max_exec_time DESC
LIMIT 10;
--清空重新统计
SELECT pg_stat_statements_reset();
位号时序表
-- 创建时序表
CREATE TABLE IF NOT EXISTS dm_tag_value (
id BIGINT DEFAULT NULL,
ds_id BIGINT DEFAULT NULL,
tag_name VARCHAR(200) NOT NULL ,
tag_value VARCHAR(1000) DEFAULT '',
tag_time TIMESTAMP DEFAULT NULL,
app_time TIMESTAMP NOT NULL,
quality INTEGER DEFAULT NULL,
create_time TIMESTAMP DEFAULT NULL
);
COMMENT ON COLUMN dm_tag_value.id IS 'id';
COMMENT ON COLUMN dm_tag_value.ds_id IS '数据源id';
COMMENT ON COLUMN dm_tag_value.tag_name IS '位号名';
COMMENT ON COLUMN dm_tag_value.tag_value IS '位号值';
COMMENT ON COLUMN dm_tag_value.tag_time IS '实时数据库tag返回时间';
COMMENT ON COLUMN dm_tag_value.app_time IS '查询实时数据库时间';
COMMENT ON COLUMN dm_tag_value.quality IS '质量码';
COMMENT ON COLUMN dm_tag_value.create_time IS '创建时间';
DO $$
begin
PERFORM create_hypertable('dm_tag_value', 'app_time', 'tag_name', 50);
PERFORM set_chunk_time_interval('dm_tag_value', INTERVAL '1 day');
ALTER TABLE dm_tag_value SET (timescaledb.compress, timescaledb.compress_orderby = 'app_time DESC', timescaledb.compress_segmentby = 'tag_name');
PERFORM add_compression_policy('dm_tag_value', INTERVAL '2 days');
CREATE INDEX idx_dm_tag_value_time_name ON dm_tag_value (app_time,tag_name);
PERFORM add_retention_policy('dm_tag_value', INTERVAL '1 year');
EXCEPTION
WHEN OTHERS THEN
RAISE NOTICE 'An unexpected error occurred: %', SQLERRM;
END $$;
-- 创建连续聚合
CREATE EXTENSION IF NOT EXISTS tablefunc;
DO $$
begin
CREATE MATERIALIZED VIEW dm_tag_value_hourly
WITH (timescaledb.continuous) AS
SELECT
dm.tag_name AS tag_name,
time_bucket(INTERVAL '1 hour', dm.app_time) AS app_time ,
first(tag_value,app_time) as tag_value
FROM
dm_tag_value dm
GROUP BY
dm.tag_name, time_bucket(INTERVAL '1 hour', dm.app_time)
WITH NO DATA;
CREATE INDEX idx_dm_tag_value_hourly_name_time ON dm_tag_value_hourly (tag_name,app_time);
PERFORM add_continuous_aggregate_policy('dm_tag_value_hourly',
start_offset => INTERVAL '1 day',
end_offset => INTERVAL '30 minutes',
schedule_interval => INTERVAL '1 hour');
EXCEPTION
WHEN OTHERS THEN
RAISE NOTICE 'An unexpected error occurred: %', SQLERRM;
END $$;
-- 函数
CREATE OR REPLACE FUNCTION get_current_records(
tag_names text[],
t timestamp DEFAULT now(),
opt text DEFAULT 'before'
)
RETURNS TABLE(tag_name varchar(200), app_time timestamp, tag_value varchar(1000)) AS $$
declare
t1 timestamp;
t2 timestamp;
query text;
begin
IF opt = 'after' then
t1 := t;
t2 := t + INTERVAL '1 minute';
ELSIF opt = 'interpolate' then
t1 := t - INTERVAL '1 minute';
t2 := t + INTERVAL '1 minute';
else
t1 := t - INTERVAL '1 minute';
t2 := t;
END IF;
IF opt = 'after' then
query := 'WITH RankedData AS (
SELECT
tag_name,
app_time,
tag_value,
ROW_NUMBER() OVER (PARTITION BY tag_name ORDER BY app_time) as row_num
FROM
dm_tag_value
WHERE
app_time >= $2 and app_time < $3 AND tag_name = ANY ($4::text[])
)
SELECT
tag_name,
app_time,
tag_value
FROM
RankedData
WHERE
row_num = 1;';
ELSIF opt = 'interpolate' THEN
query := 'WITH RankedData_b AS (
SELECT
tag_name,
app_time,
tag_value,
ROW_NUMBER() OVER (PARTITION BY tag_name ORDER BY app_time desc) as row_num
FROM
dm_tag_value
WHERE
app_time <= $2 AND app_time > $1 AND tag_name = ANY ($4::text[])
),
closest_before AS (
SELECT
RankedData_b.tag_name,
RankedData_b.app_time,
RankedData_b.tag_value
FROM
RankedData_b
WHERE
RankedData_b.row_num = 1
),
RankedData_a AS (
SELECT
tag_name,
app_time,
tag_value,
ROW_NUMBER() OVER (PARTITION BY tag_name ORDER BY app_time) as row_num
FROM
dm_tag_value
WHERE
app_time > $2 and app_time < $3 AND tag_name = ANY ($4::text[])
),
closest_after AS (
SELECT
RankedData_a.tag_name,
RankedData_a.app_time,
RankedData_a.tag_value
FROM
RankedData_a
WHERE
RankedData_a.row_num = 1
),
combined AS (
SELECT
b.tag_name AS name,
EXTRACT(EPOCH FROM b.app_time) AS time_before,
CAST(b.tag_value AS DOUBLE PRECISION) AS value_before,
EXTRACT(EPOCH FROM a.app_time) AS time_after,
CAST(a.tag_value AS DOUBLE PRECISION) AS value_after
FROM closest_before b
FULL JOIN closest_after a ON a.tag_name=b.tag_name
)
SELECT
COALESCE(combined.name,ca.tag_name, cb.tag_name) AS tag_name,
CAST($2 AS TIMESTAMP) AS app_time,
CASE
WHEN cb.app_time IS NOT NULL AND ca.app_time IS NOT NULL THEN
CAST((value_before + (value_after - value_before) * (EXTRACT(EPOCH FROM $2) - time_before) / (time_after - time_before)) AS VARCHAR(1000))
WHEN cb.app_time IS NOT NULL THEN
CAST(cb.tag_value AS VARCHAR(1000))
WHEN ca.app_time IS NOT NULL THEN
CAST(ca.tag_value AS VARCHAR(1000))
ELSE
NULL
END AS tag_value
FROM combined
LEFT JOIN closest_before cb ON combined.name=cb.tag_name
LEFT JOIN closest_after ca ON combined.name=ca.tag_name';
else
query := 'WITH RankedData AS (
SELECT
tag_name,
app_time,
tag_value,
ROW_NUMBER() OVER (PARTITION BY tag_name ORDER BY app_time desc) as row_num
FROM
dm_tag_value
WHERE
app_time <= $2 AND app_time > $1 AND tag_name = ANY ($4::text[])
)
SELECT
tag_name,
app_time,
tag_value
FROM
RankedData
WHERE
row_num = 1;';
END IF;
RETURN QUERY EXECUTE query USING t1, t ,t2, tag_names;
END;
$$ LANGUAGE plpgsql;
CREATE OR REPLACE FUNCTION public.get_latest_records(
tag_names text[],
t timestamp without time zone DEFAULT now(),
opt text DEFAULT 'before'::text
)
RETURNS TABLE(tag_name character varying, app_time timestamp without time zone, tag_value character varying)
LANGUAGE plpgsql
AS $function$
DECLARE
tag text;
query text;
current_tags text[];
BEGIN
-- 获取当前记录
current_tags := ARRAY(
SELECT a.tag_name
FROM public.get_current_records(tag_names, t, opt) a
);
-- 先返回所有当前记录
RETURN QUERY SELECT * FROM public.get_current_records(tag_names, t, opt);
-- 查询不在当前记录内的标签
FOR tag IN SELECT unnest(tag_names)
LOOP
IF NOT (tag = ANY(current_tags)) THEN
IF opt = 'after' THEN
query := format('
SELECT dm_tag_value.tag_name, dm_tag_value.app_time, dm_tag_value.tag_value
FROM dm_tag_value
WHERE dm_tag_value.tag_name = %L AND dm_tag_value.app_time >= %L
ORDER BY dm_tag_value.app_time ASC
LIMIT 1', tag, t);
ELSIF opt = 'interpolate' THEN
query := format('WITH closest_before AS (
SELECT dm_tag_value.tag_name, dm_tag_value.app_time, dm_tag_value.tag_value
FROM dm_tag_value
WHERE dm_tag_value.tag_name = %L AND dm_tag_value.app_time <= %L
ORDER BY app_time DESC
LIMIT 1
),
closest_after AS (
SELECT dm_tag_value.tag_name, dm_tag_value.app_time, dm_tag_value.tag_value
FROM dm_tag_value
WHERE dm_tag_value.tag_name = %L AND dm_tag_value.app_time > %L
ORDER BY app_time ASC
LIMIT 1
),
combined AS (
SELECT
b.tag_name AS name,
EXTRACT(EPOCH FROM b.app_time) AS time_before,
CAST(b.tag_value AS DOUBLE PRECISION) AS value_before,
EXTRACT(EPOCH FROM a.app_time) AS time_after,
CAST(a.tag_value AS DOUBLE PRECISION) AS value_after
FROM closest_before b
FULL JOIN closest_after a ON 1=1
)
SELECT
COALESCE(combined.name,ca.tag_name, cb.tag_name) AS tag_name,
CAST(%L AS TIMESTAMP) AS app_time,
CASE
WHEN cb.app_time IS NOT NULL AND ca.app_time IS NOT NULL THEN
CAST((value_before + (value_after - value_before) * (EXTRACT(EPOCH FROM TIMESTAMP %L) - time_before) / (time_after - time_before)) AS VARCHAR(1000))
WHEN cb.app_time IS NOT NULL THEN
CAST(cb.tag_value AS VARCHAR(1000))
WHEN ca.app_time IS NOT NULL THEN
CAST(ca.tag_value AS VARCHAR(1000))
ELSE
NULL
END AS tag_value
FROM combined
LEFT JOIN closest_before cb ON 1=1
LEFT JOIN closest_after ca ON 1=1'
, tag, t , tag,t ,t, t);
ELSE
query := format('
SELECT dm_tag_value.tag_name, dm_tag_value.app_time, dm_tag_value.tag_value
FROM dm_tag_value
WHERE dm_tag_value.tag_name = %L AND dm_tag_value.app_time <= %L
ORDER BY dm_tag_value.app_time DESC
LIMIT 1', tag, t);
END IF;
RETURN QUERY EXECUTE query;
END IF;
END LOOP;
END;
$function$
;
CREATE OR REPLACE FUNCTION public.get_tag_history_count_with_interval_seconds(tag_names text[], begin_time timestamp without time zone, end_time timestamp without time zone, interval_seconds integer)
RETURNS TABLE(tag_name character varying, tag_count bigint)
LANGUAGE plpgsql
AS $function$
DECLARE
sql_query text;
BEGIN
interval_seconds := GREATEST(interval_seconds, 1);
-- 构建动态 SQL 查询
sql_query := '
WITH grouped_data AS (
SELECT
dm.tag_name,
time_bucket(INTERVAL ''1 second'' * ' || interval_seconds || ', dm.app_time) AS interval_time,
min(dm.app_time) AS app_time_tag_value
FROM
dm_tag_value dm
WHERE
dm.tag_name = ANY($1)
AND dm.app_time >= $2
AND dm.app_time < $3
GROUP BY
dm.tag_name, interval_time
)
SELECT
gd.tag_name AS tag_name,
count(gd.tag_name) AS tag_count
FROM
grouped_data gd
GROUP BY
gd.tag_name;';
-- 执行动态 SQL
RETURN QUERY EXECUTE sql_query USING tag_names, begin_time, end_time;
END;
$function$
;
DROP FUNCTION IF EXISTS public.get_tag_history_with_interval_seconds(_text, timestamp, timestamp, int4, int4, int4);
CREATE OR REPLACE FUNCTION public.get_tag_history_with_interval_seconds(
tag_names text[],
begin_time timestamp without time zone,
end_time timestamp without time zone,
interval_seconds integer,
page_size integer,
page_index integer,
sort_order text DEFAULT 'ASC'
)
RETURNS TABLE(tag_name character varying, app_time timestamp without time zone, tag_value text)
LANGUAGE plpgsql
AS $function$
DECLARE
sql_query text;
BEGIN
interval_seconds := GREATEST(interval_seconds, 1);
page_size := LEAST(page_size, 200000);
IF sort_order IS NULL OR (sort_order <> 'ASC' AND sort_order <> 'DESC') THEN
sort_order := 'ASC'; -- 默认排序
END IF;
-- 构建动态 SQL 查询
sql_query := 'WITH grouped_data AS (
SELECT
dm.tag_name AS tag_name,
time_bucket(INTERVAL ''1 second'' * ''' || interval_seconds || ''', dm.app_time) AS interval_time,
min(concat(cast(dm.app_time AS VARCHAR), ''|'', dm.tag_value, ''|'', dm.quality, ''|'', cast(dm.tag_time AS VARCHAR))) as app_time_tag_value,
ROW_NUMBER() OVER (PARTITION BY dm.tag_name ORDER BY time_bucket(INTERVAL ''1 second'' * ''' || interval_seconds || ''', dm.app_time) ' || sort_order || ') AS row_num
FROM
dm_tag_value dm
WHERE
dm.tag_name = ANY($1)
AND dm.app_time >= $2
AND dm.app_time < $3
GROUP BY
dm.tag_name, interval_time
)
SELECT
gd.tag_name,
gd.interval_time AS app_time,
gd.app_time_tag_value AS tag_value
FROM
grouped_data gd
WHERE
gd.row_num > ($4 * ($5 - 1)) AND gd.row_num <= ($4 * $5)
ORDER BY
gd.tag_name, gd.interval_time ' || sort_order || ' ;';
-- 执行动态 SQL
RETURN QUERY EXECUTE sql_query USING tag_names, begin_time, end_time, page_size, page_index;
END;
$function$;
版本升级(只升TimescaleDB版本不升级PG)
1. timescaledb切换新版本镜像(pg不同版本可能不兼容)
2. 在容器或客户端中登录psql,使用 -X 标志(如果需要)
psql -X -h <your_host> -U <your_user> -d <your_database>
3. 升级扩展
ALTER EXTENSION timescaledb UPDATE;
4. 验证新版本
SELECT * FROM pg_extension WHERE extname = 'timescaledb';

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)