数据挖掘中的分层聚类
假设集群 (B) 和集群 (C) 彼此非常相似,因此我们在第二步中将它们合并,类似于集群 (D) 和 (E),最后,我们得到集群 [(A)、(BC)、(DE)、(F)]在每次迭代中,集群都会与不同的集群合并,直到形成一个集群。我们根据算法重新计算接近度,并将两个最近的集群 ([(DE), (F)]) 合并在一起,形成新的集群,如 [(A), (BC), (DEF)]k 均值和分层聚类之间的主要区别
分层聚类方法的工作原理是将数据分组到集群树中。分层聚类首先将每个数据点视为单独的聚类。然后,它会重复执行后续步骤:
- 确定可以最接近的 2 个集群,以及
- 合并最多 2 个可比较集群。我们需要继续这些步骤,直到所有集群合并在一起。
在 Hierarchical Clustering 中,目标是生成一系列分层嵌套集群。称为 Dendrogram 的图表(Dendrogram 是一个树状图表,用于统计合并或拆分的顺序)以图形方式表示此层次结构,并且是一个倒置的树,用于描述因子合并(自下而上视图)或聚类分解(自上而下视图)的顺序。
什么是分层聚类?
分层聚类是数据挖掘中的一种聚类分析方法,可在数据集中创建聚类的分层表示。该方法首先将每个数据点视为一个单独的集群,然后迭代地组合最近的集群,直到达到停止标准。分层聚类的结果是一个树状结构,称为树状结构,它说明了聚类之间的分层关系。
与其他聚类方法相比,分层聚类具有几个优点
- 能够处理非凸集群和不同大小和密度的集群。
- 处理缺失数据和干扰数据的能力。
- 揭示数据层次结构的能力,这对于了解集群之间的关系非常有用。
分层聚类的缺点
- 需要一个标准来停止聚类过程并确定最终的聚类数。
- 该方法的计算成本和内存要求可能很高,尤其是对于大型数据集。
- 结果可能对使用的初始条件、链接标准和距离度量敏感。
总之,分层聚类是一种数据挖掘方法,它通过创建群集的分层结构将相似的数据点分组到群集中。 - 此方法可以处理不同类型的数据并揭示集群之间的关系。但是,它的计算成本可能很高,并且结果可能对某些条件很敏感。
分层聚类的类型
基本上,有两种类型的分层聚类:
- 凝聚聚类
- 分割聚类
1. 凝聚聚类
最初将每个数据点视为一个单独的 Cluster,并在每个步骤中合并最近的 Cluster 对。(这是一种自下而上的方法)。起初,每个数据集都被视为一个单独的实体或集群。在每次迭代中,集群都会与不同的集群合并,直到形成一个集群。
凝聚分层聚类的算法为:
- 计算一个分类与所有其他分类的相似性(计算邻近矩阵)
- 将每个数据点视为一个单独的集群
- 合并彼此高度相似或接近的集群。
- 重新计算每个分类的邻近矩阵
- 重复步骤 3 和 4,直到只剩下一个集群。
让我们看看使用树状图的该算法的图形表示。
注意:这只是实际算法工作原理的演示:未在假设集群之间的所有接近度下执行计算。
假设我们有六个数据点 A、B、C、D、E 和 F。
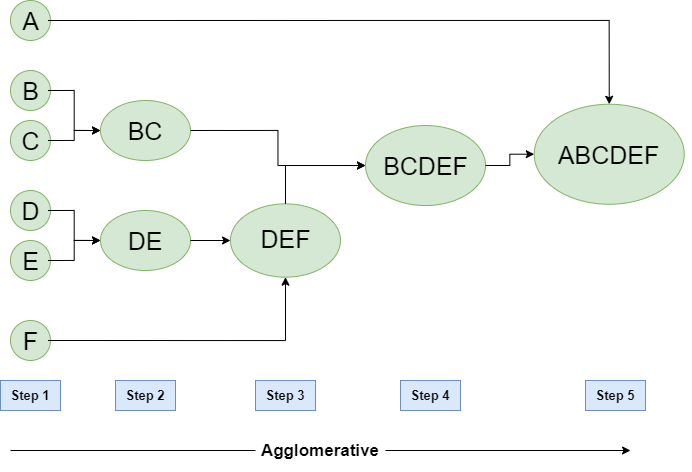
凝聚分层聚类
- 第 1 步:将每个字母视为一个集群,并计算一个集群与所有其他集群的距离。
- 第 2 步:在第二步中,将可比较的集群合并在一起以形成一个集群。假设集群 (B) 和集群 (C) 彼此非常相似,因此我们在第二步中将它们合并,类似于集群 (D) 和 (E),最后,我们得到集群 [(A)、(BC)、(DE)、(F)]
- 第 3 步:我们根据算法重新计算接近度,并将两个最近的集群 ([(DE), (F)]) 合并在一起,形成新的集群,如 [(A), (BC), (DEF)]
- 第 4 步:重复相同的过程;集群 DEF 和 BC 具有可比性,并合并在一起以形成一个新集群。我们现在只剩下集群 [(A), (BCDEF)]。
- 第 5 步:最后,将剩余的两个集群合并在一起,形成一个集群 [(ABCDEF)]。
2. 分裂分层聚类
我们可以说 Divisive Hierarchical clustering 恰好与 Agglomerative Hierarchical clustering 相反。在分割分层聚类中,我们将所有数据点视为一个聚类,在每次迭代中,我们将数据点与不具有可比性的聚类分开。最后,我们只剩下 N 个集群。
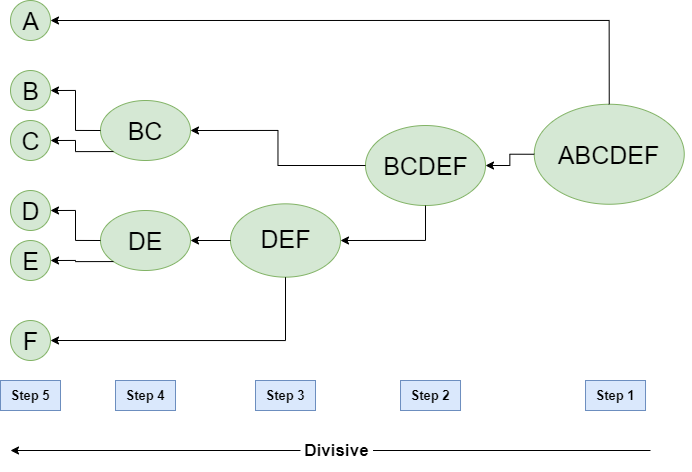
Divisive Hierarchical Clustering (划分分层聚类)
还要检查:
机器学习中的分层聚类
机器学习中的集聚方法
K 均值与层次聚类的区别
使用 Sklearn 实现凝聚聚类
常见问题 (FAQ)
1. 什么是两种类型的分层聚类?
有两种类型的分层聚类:凝聚聚类和分割聚类。在凝聚聚类中,数据点被视为单独的聚类,并根据相似性合并它们,直到形成单个聚类。在分层聚类中,数据点被视为单个聚类,然后根据差异递归划分为更小的聚类,直到单个数据点成为单独的聚类。
2. K 均值和层次聚类有什么区别?
k 均值和分层聚类之间的主要区别在于 k 均值将数据划分为预定数量的聚类 (k),而分层聚类形成聚类层次结构,而无需事先确定聚类的数量。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)