【回归预测】GA-BP遗传算法优化BP神经网络-MATLAB
本文主要介绍一种基于遗传算法(Genetic Algorithm, GA)优化的BP神经网络模型(GA-BP),用于解决回归预测问题。传统BP神经网络容易陷入局部最优且对初始权值和阈值敏感,而遗传算法通过全局搜索能力优化神经网络的初始参数,可显著提升模型性能。本文通过MATLAB代码实现GA-BP模型的训练与测试,并详细解析其原理和代码实现。
一、前言
随着人工智能技术的不断发展,神经网络已成为各类复杂问题建模与预测的重要工具。本文主要介绍一种基于遗传算法(Genetic Algorithm, GA)优化的BP神经网络模型(GA-BP),用于解决回归预测问题。传统BP神经网络容易陷入局部最优且对初始权值和阈值敏感,而遗传算法通过全局搜索能力优化神经网络的初始参数,可显著提升模型性能。本文通过MATLAB代码实现GA-BP模型的训练与测试,并详细解析其原理和代码实现。
二、技术与原理简介
1.BP神经网络
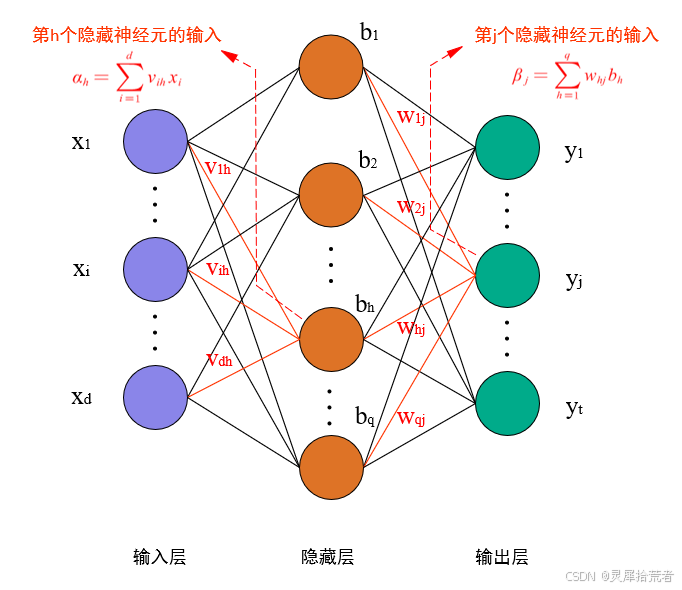
BP 神经网络是一种前馈神经网络,通常包括输入层、一个或多个隐含层以及输出层。其核心思想是利用前向传播和反向传播算法进行训练:
前向传播:输入数据依次经过各层神经元,经过加权求和及激活函数变换,最终输出预测结果。每一层的计算公式为
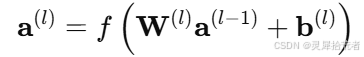
其中,𝑊(𝑙)和 𝑏(𝑙) 分别为第 𝑙 层的权重和偏置,𝑓(⋅)为激活函数(例如 tan-sigmoid)。
反向传播:计算输出层的误差后,将误差反向传递给各隐含层,利用梯度下降法更新权重和偏置,从而最小化误差函数。反向传播的关键步骤包括:
1. 计算输出层误差:
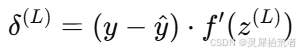
2. 逐层传播误差:
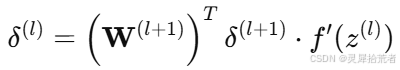
3. 参数更新:
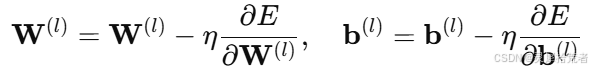
其中,𝜂 为学习率,𝐸 为误差函数(通常采用均方误差)。
这种基于梯度下降的迭代更新过程使得 BP 网络能够通过不断调整参数,使预测输出逐渐接近真实值,从而实现数据的非线性拟合与模式识别。
2. 遗传算法GA
遗传算法 (Genetic Algorithm, GA) 是一种模拟自然选择和遗传机制的优化算法。它属于进化算法 (Evolutionary Algorithm) 的范畴,通过模拟生物进化过程中的选择、交叉和变异等操作,在解空间中搜索最优解。
核心思想:
- 适者生存: 适应度高的个体更有可能被选择并遗传到下一代。
- 基因重组: 通过交叉操作,将优秀个体的基因片段进行组合,产生更优秀的后代。
- 突变: 通过变异操作,引入新的基因,增加种群的多样性,避免陷入局部最优解。
适用场景:
遗传算法适用于解决各种优化问题,特别是以下情况:
- 问题复杂,难以找到解析解。
- 搜索空间大,传统搜索方法效率低。
- 问题具有多个局部最优解。
- 需要全局最优解或近似最优解。
3. 遗传算法的基本步骤
-
初始化种群 (Initialization):
- 随机生成一定数量的个体,作为初始种群。
- 每个个体代表问题的一个潜在解,通常用二进制串、实数向量或其他编码方式表示。
- 种群大小 (Population Size) 是一个重要的参数,影响算法的搜索能力和收敛速度。
-
适应度评估 (Fitness Evaluation):
- 根据问题的目标函数,计算每个个体的适应度值 (Fitness Value)。
- 适应度值越高,表示个体越优秀,越接近问题的最优解。
- 适应度函数的设计是遗传算法的关键,它直接影响算法的性能。
-
选择 (Selection):
- 根据个体的适应度值,选择一部分个体作为父代,用于产生下一代。
- 常用的选择方法包括:
- 轮盘赌选择 (Roulette Wheel Selection): 个体被选择的概率与其适应度值成正比。
- 公式:
- 个体 i 被选择的概率: Pi = fi / Σ fj (其中 fi 是个体 i 的适应度值,Σ fj 是所有个体的适应度值之和)
- 公式:
- 锦标赛选择 (Tournament Selection): 随机选择若干个个体,选择其中适应度最高的个体作为父代。
- 排序选择 (Rank Selection): 根据个体的适应度值进行排序,然后根据排名分配选择概率。
- 精英选择 (Elitism Selection): 直接将适应度最高的若干个个体复制到下一代,保证最优解不会丢失。
- 轮盘赌选择 (Roulette Wheel Selection): 个体被选择的概率与其适应度值成正比。
-
交叉 (Crossover):
- 以一定的概率 (交叉概率, Crossover Rate) 选择两个父代个体,交换它们的部分基因,产生新的后代。
- 常用的交叉方法包括:
- 单点交叉 (Single-Point Crossover): 在个体编码串中随机选择一个交叉点,交换两个父代个体在该点之后的基因。
- 两点交叉 (Two-Point Crossover): 在个体编码串中随机选择两个交叉点,交换两个父代个体在这两个点之间的基因。
- 均匀交叉 (Uniform Crossover): 对个体编码串中的每个基因位,以一定的概率选择一个父代个体的基因值作为后代的基因值。
- 公式 (以单点交叉为例):
- 假设两个父代个体为 P1 和 P2,交叉点为 k。
- 则产生的两个后代个体 C1 和 C2 为:
- C1 = P1[1…k] + P2[(k+1)…length(P1)]
- C2 = P2[1…k] + P1[(k+1)…length(P2)]
- (其中 P1[1…k] 表示个体 P1 的前 k 个基因,length(P1) 表示个体 P1 的长度)
-
变异 (Mutation):
- 以一定的概率 (变异概率, Mutation Rate) 改变个体编码串中的某些基因值,引入新的基因,增加种群的多样性。
- 常用的变异方法包括:
- 位翻转变异 (Bit Flip Mutation): 对于二进制编码的个体,随机选择一个基因位,将其值翻转 (0 变为 1,1 变为 0)。
- 实值变异 (Real-Value Mutation): 对于实数编码的个体,随机选择一个基因位,在其原始值上加上或减去一个随机数。
- 公式 (以位翻转变异为例):
- 假设个体 P 的第 k 个基因位需要变异。
- 如果 P[k] = 0,则 P[k] = 1。
- 如果 P[k] = 1,则 P[k] = 0。
-
种群更新 (Replacement):
- 将新生成的后代个体替换掉种群中的一部分个体,形成新的种群。
- 常用的替换方法包括:
- 全替换 (Generational Replacement): 将整个父代种群替换为新生成的后代种群。
- 部分替换 (Steady-State Replacement): 只替换掉种群中适应度较差的个体。
-
终止条件判断 (Termination Condition):
- 判断是否满足终止条件,如果满足,则算法结束,输出最优解;否则,返回步骤 2,继续迭代。
- 常用的终止条件包括:
- 达到最大迭代次数 (Maximum Iterations)。
- 找到满足要求的解 (Satisfactory Solution)。
- 种群的平均适应度值不再提高 (Convergence)。
4. GA-BP优化机制
GA通过模拟生物进化过程优化参数,关键操作如下:
染色体编码:将网络权值、阈值编码为实数染色体,长度𝐿=(𝐼+1)𝐻+(𝐻+1)𝑂L=(I+1)H+(H+1)O(𝐼,𝐻,𝑂为输入/隐藏/输出层节点数)
适应度函数:
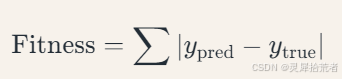
误差越小,适应度越高。
选择操作:
采用轮盘赌法,个体选择概率为:
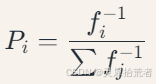
其中 𝑓𝑖 为第 𝑖 个个体的误差。
交叉与变异:交叉:随机选择两个染色体,按概率交换部分基因。变异:按概率对染色体中某一位进行扰动,引入随机性。
三、代码详解
本文的 MATLAB 代码主要分为以下几个部分:
1. 数据加载与预处理
clear,clc;close all
load data1 data1
rng(43,'twister')
N=length(data1);
temp=randperm(N);
ttt=2;ppp=950;f_=ttt;
P_train = data1(temp(1: ppp), 1: ttt)';
T_train = data1(temp(1: ppp), 3)';
M = size(P_train, 2);
P_test = data1(temp(ppp+1: end), 1: ttt)';
T_test = data1(temp(ppp+1: end), 3)';
N = size(P_test, 2);说明:
- 通过
load加载数据,并利用randperm随机打乱顺序,确保样本的随机性。 - 按照预设的样本数(前 950 个为训练集,其余为测试集)划分数据。
- 数据转置后以列向量形式存储,便于后续矩阵计算。
2. 数据归一化
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
说明:
- 使用
mapminmax函数将数据缩放到 [0,1] 区间,这有助于提高网络训练的稳定性和收敛速度。 - 分别对输入数据和目标数据进行归一化处理,后续在仿真测试时再将结果反归一化还原。
3. 网络创建、训练
%% GA
num_iter_all=5;
for NN=1:num_iter_all
input_num=size(P_train,1); %输入特征个数
hidden_num=12; %隐藏层神经元个数
output_num=size(T_train,1); %输出特征个数
% 遗传算法参数初始化
iter_num=4; %总体进化迭代次数
group_num=5; %种群规模
cross_pro=0.6; %交叉概率
mutation_pro=0.2; %变异概率,相对来说比较小
%这个优化的主要思想就是优化网络参数的初始选择,初始选择对于效果好坏是有较大影响的
num_all=input_num*hidden_num+hidden_num+hidden_num*output_num+output_num;%网络总参数,只含一层隐藏层
lenchrom=ones(1,num_all); %种群总长度
limit=[-2*ones(num_all,1) 2*ones(num_all,1)]; %初始参数给定范围
t1=clock;
%% 初始化种群
input_data=p_train;
output_data=t_train;
for i=1:group_num
initial=rand(1,length(lenchrom)); %产生0-1的随机数
initial_chrom(i,:)=limit(:,1)'+(limit(:,2)-limit(:,1))'.*initial; %变成染色体的形式,一行为一条染色体
fitness_value=fitness1(initial_chrom(i,:),input_num,hidden_num,output_num,input_data,output_data);
fitness_group(i)=fitness_value;
end
[bestfitness,bestindex]=min(fitness_group);
bestchrom=initial_chrom(bestindex,:); %最好的染色体
avgfitness=sum(fitness_group)/group_num; %染色体的平均适应度
trace=[avgfitness bestfitness]; % 记录每一代进化中最好的适应度和平均适应度
%% 迭代过程
input_chrom=initial_chrom;
% iter_num=1;
for num=1:iter_num
num
% 选择
[new_chrom,new_fitness]=select(input_chrom,fitness_group,group_num); %把表现好的挑出来,还是和种群数量一样
% avgfitness=sum(new_fitness)/group_num;
%交叉
new_chrom=Cross(cross_pro,lenchrom,new_chrom,group_num,limit);
% 变异
new_chrom=Mutation(mutation_pro,lenchrom,new_chrom,group_num,num,iter_num,limit);
% 计算适应度
for j=1:group_num
sgroup=new_chrom(j,:); %个体
new_fitness(j)=fitness1(sgroup,input_num,hidden_num,output_num,input_data,output_data);
end
%找到最小和最大适应度的染色体及它们在种群中的位置
[newbestfitness,newbestindex]=min(new_fitness);
[worestfitness,worestindex]=max(new_fitness);
% 代替上一次进化中最好的染色体
if bestfitness>newbestfitness
bestfitness=newbestfitness;
bestchrom=new_chrom(newbestindex,:);
end
new_chrom(worestindex,:)=bestchrom;
new_fitness(worestindex)=bestfitness;
avgfitness=sum(new_fitness)/group_num;
% disp([bestfitness]);
trace=[trace;avgfitness bestfitness]; %记录每一代进化中最好的适应度和平均适应度
end
end说明:
input_num表示输入数据的特征数量。hidden_num设置了隐藏层的神经元数量。output_num是目标数据的输出特征数量。iter_num表示遗传算法的总进化代数。group_num是种群的规模,即每代有多少个体参与进化。cross_pro和mutation_pro分别是交叉操作和变异操作的概率。num_all计算了网络中所有参数(包括输入层到隐藏层的权重、隐藏层偏置、隐藏层到输出层的权重以及输出层偏置)的总数。lenchrom表示染色体的长度,即每个染色体所包含的基因数目,等于网络中参数的数量。limit设定了所有参数的初始范围为 [−2,2]。fitness1函数用于计算每个个体的适应度值,表示该个体的网络在给定数据上的表现。bestfitness表示当前种群中最优秀个体的适应度值。bestchrom表示当前种群中最优秀个体的基因。avgfitness表示当前种群的平均适应度。- 初始种群,其中每个个体是一个向量,表示网络参数(权重和偏置)。
- 迭代过程包括选择、交叉、变异等步骤,不断优化种群中的个体。
- 每一代迭代后,都会更新最优适应度,并记录进化过程中的适应度变化。
4. 神经网络参数更新
%% 把最优初始阀值权值赋予网络预测
% %用遗传算法优化的BP网络进行值预测
net=newff(p_train,t_train,hidden_num,{'tansig','purelin'});
w1=bestchrom(1:input_num*hidden_num); %输入和隐藏层之间的权重参数
B1=bestchrom(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置
w2=bestchrom(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...
hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置
B2=bestchrom(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...
hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置
%网络权值赋值
net.iw{1,1}=reshape(w1,hidden_num,input_num);
net.lw{2,1}=reshape(w2,output_num,hidden_num);
net.b{1}=reshape(B1,hidden_num,1);
net.b{2}=reshape(B2,output_num,1);
net.trainParam.epochs=20; %最大迭代次数
net.trainParam.lr=0.1; %学习率
net.trainParam.goal=0.00001;
[net,~]=train(net,p_train,t_train);说明:
- 将遗传算法优化得到的最佳参数(权重和偏置)赋给BP网络。
- 创建一个包含一个隐藏层的BP神经网络,并使用
newff函数初始化网络。
5.仿真与测试与反归一化
%% 仿真测试
t_sim1 = sim(net, p_train);
t_sim2 = sim(net, p_test );
%% 数据反归一化
T_sim1 = mapminmax('reverse', t_sim1, ps_output);
T_sim2 = mapminmax('reverse', t_sim2, ps_output);说明:
- 使用优化后的网络对训练数据和测试数据进行仿真,得到预测值。
- 将预测结果从归一化状态转换回原始的数值范围。
6. 性能评价指标计算
%% 计算评价指标
error1 = sqrt(sum((T_sim1 - T_train).^2) ./ M); % 训练集 RMSE
error2 = sqrt(sum((T_test - T_sim2).^2) ./ N); % 测试集 RMSE
R1 = 1 - norm(T_train - T_sim1)^2 / norm(T_train - mean(T_train))^2; % 训练集 R²
R2 = 1 - norm(T_test - T_sim2)^2 / norm(T_test - mean(T_test))^2; % 测试集 R²
mse1 = sum((T_sim1 - T_train).^2) ./ M; % 训练集 MSE
mse2 = sum((T_sim2 - T_test).^2) ./ N; % 测试集 MSE
SE1 = std(T_sim1 - T_train);
RPD1 = std(T_train) / SE1; % 训练集剩余预测残差
SE = std(T_sim2 - T_test);
RPD2 = std(T_test) / SE; % 测试集 RPD
MAE1 = mean(abs(T_train - T_sim1)); % 训练集 MAE
MAE2 = mean(abs(T_test - T_sim2)); % 测试集 MAE
MAPE1 = mean(abs((T_train - T_sim1) ./ T_train)); % 训练集 MAPE
MAPE2 = mean(abs((T_test - T_sim2) ./ T_test)); % 测试集 MAPE
MBE1 = sum(T_sim1 - T_train) ./ M; % 训练集 MBE
MBE2 = sum(T_sim2 - T_test) ./ N; % 测试集 MBE
说明:
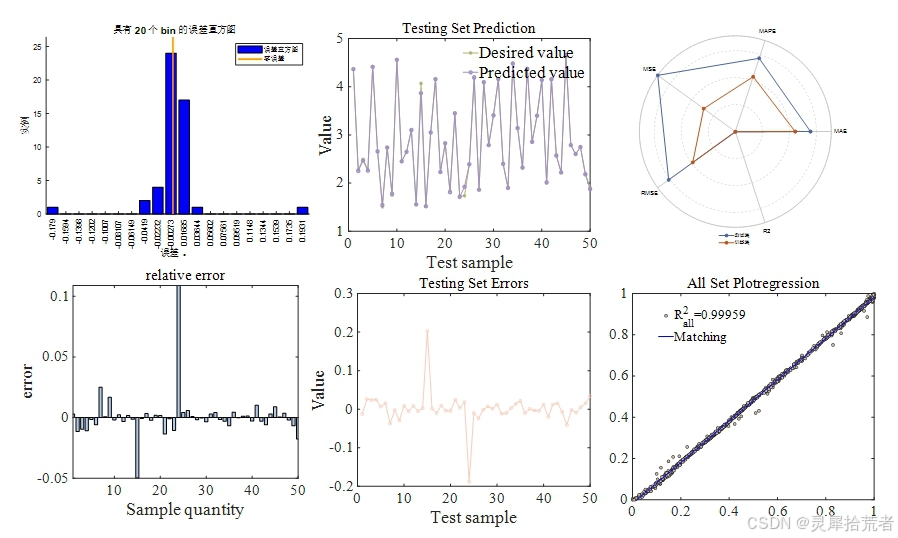
- 利用多种指标(RMSE、𝑅2 、MSE、RPD、MAE、MAPE、MBE)对模型在训练集和测试集上的表现进行定量评估。
- 决定系数 𝑅2 的计算公式为:
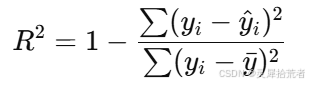
其中 𝑦𝑖 为实际值,𝑦^𝑖 为预测值,𝑦ˉ 为实际值的均值。
7. 完整代码
clear,clc;close all
load data1 data1
rng(43,'twister')
N=length(data1);
temp=randperm(N);
ttt=2;ppp=950;f_=ttt;
P_train = data1(temp(1: ppp), 1: ttt)';
T_train = data1(temp(1: ppp), 3)';
M = size(P_train, 2);
P_test = data1(temp(ppp+1: end), 1: ttt)';
T_test = data1(temp(ppp+1: end), 3)';
N = size(P_test, 2);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% GA
num_iter_all=5;
for NN=1:num_iter_all
input_num=size(P_train,1); %输入特征个数
hidden_num=12; %隐藏层神经元个数
output_num=size(T_train,1); %输出特征个数
% 遗传算法参数初始化
iter_num=4; %总体进化迭代次数
group_num=5; %种群规模
cross_pro=0.6; %交叉概率
mutation_pro=0.2; %变异概率,相对来说比较小
%这个优化的主要思想就是优化网络参数的初始选择,初始选择对于效果好坏是有较大影响的
num_all=input_num*hidden_num+hidden_num+hidden_num*output_num+output_num;%网络总参数,只含一层隐藏层
lenchrom=ones(1,num_all); %种群总长度
limit=[-2*ones(num_all,1) 2*ones(num_all,1)]; %初始参数给定范围
t1=clock;
%% 初始化种群
input_data=p_train;
output_data=t_train;
for i=1:group_num
initial=rand(1,length(lenchrom)); %产生0-1的随机数
initial_chrom(i,:)=limit(:,1)'+(limit(:,2)-limit(:,1))'.*initial; %变成染色体的形式,一行为一条染色体
fitness_value=fitness1(initial_chrom(i,:),input_num,hidden_num,output_num,input_data,output_data);
fitness_group(i)=fitness_value;
end
[bestfitness,bestindex]=min(fitness_group);
bestchrom=initial_chrom(bestindex,:); %最好的染色体
avgfitness=sum(fitness_group)/group_num; %染色体的平均适应度
trace=[avgfitness bestfitness]; % 记录每一代进化中最好的适应度和平均适应度
%% 迭代过程
input_chrom=initial_chrom;
% iter_num=1;
for num=1:iter_num
num
% 选择
[new_chrom,new_fitness]=select(input_chrom,fitness_group,group_num); %把表现好的挑出来,还是和种群数量一样
% avgfitness=sum(new_fitness)/group_num;
%交叉
new_chrom=Cross(cross_pro,lenchrom,new_chrom,group_num,limit);
% 变异
new_chrom=Mutation(mutation_pro,lenchrom,new_chrom,group_num,num,iter_num,limit);
% 计算适应度
for j=1:group_num
sgroup=new_chrom(j,:); %个体
new_fitness(j)=fitness1(sgroup,input_num,hidden_num,output_num,input_data,output_data);
end
%找到最小和最大适应度的染色体及它们在种群中的位置
[newbestfitness,newbestindex]=min(new_fitness);
[worestfitness,worestindex]=max(new_fitness);
% 代替上一次进化中最好的染色体
if bestfitness>newbestfitness
bestfitness=newbestfitness;
bestchrom=new_chrom(newbestindex,:);
end
new_chrom(worestindex,:)=bestchrom;
new_fitness(worestindex)=bestfitness;
avgfitness=sum(new_fitness)/group_num;
% disp([bestfitness]);
trace=[trace;avgfitness bestfitness]; %记录每一代进化中最好的适应度和平均适应度
end
end
%% 把最优初始阀值权值赋予网络预测
% %用遗传算法优化的BP网络进行值预测
net=newff(p_train,t_train,hidden_num,{'tansig','purelin'});
w1=bestchrom(1:input_num*hidden_num); %输入和隐藏层之间的权重参数
B1=bestchrom(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置
w2=bestchrom(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...
hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置
B2=bestchrom(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...
hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置
%网络权值赋值
net.iw{1,1}=reshape(w1,hidden_num,input_num);
net.lw{2,1}=reshape(w2,output_num,hidden_num);
net.b{1}=reshape(B1,hidden_num,1);
net.b{2}=reshape(B2,output_num,1);
net.trainParam.epochs=20; %最大迭代次数
net.trainParam.lr=0.1; %学习率
net.trainParam.goal=0.00001;
[net,~]=train(net,p_train,t_train);
%% 仿真测试
t_sim1 = sim(net, p_train);
t_sim2 = sim(net, p_test );
%% 数据反归一化
T_sim1 = mapminmax('reverse', t_sim1, ps_output);
T_sim2 = mapminmax('reverse', t_sim2, ps_output);
%% 均方根误差 RMSE
error1 = sqrt(sum((T_sim1 - T_train).^2)./M);
error2 = sqrt(sum((T_test - T_sim2).^2)./N);
%% 决定系数
R1 = 1 - norm(T_train - T_sim1)^2 / norm(T_train - mean(T_train))^2;
R2 = 1 - norm(T_test - T_sim2)^2 / norm(T_test - mean(T_test ))^2;
%% 均方误差 MSE
mse1 = sum((T_sim1 - T_train).^2)./M;
mse2 = sum((T_sim2 - T_test).^2)./N;
%% RPD 剩余预测残差
SE1=std(T_sim1-T_train);
RPD1=std(T_train)/SE1;
SE=std(T_sim2-T_test);
RPD2=std(T_test)/SE;
%% 平均绝对误差MAE
MAE1 = mean(abs(T_train - T_sim1));
MAE2 = mean(abs(T_test - T_sim2));
%% 平均绝对百分比误差MAPE
MAPE1 = mean(abs((T_train - T_sim1)./T_train));
MAPE2 = mean(abs((T_test - T_sim2)./T_test));
%% 平均偏差误差MBE
MBE1 = sum(T_sim1 - T_train) ./ M ;
MBE2 = sum(T_sim2 - T_test ) ./ N ;8.子代码Cross
function new_chrom=Cross(cross_pro,lenchrom,input_chrom,group_num,limit)
%随机选择两个染色体位置交叉
% cross_pro 交叉概率
% lenchrom 染色体的长度,即所有参数的数量
% input_chrom 染色体群,经过选择遗传下来的表现比较好的
% group_num 种群规模
% new_chrom 交叉后的染色体
for i=1:group_num %每一轮for循环中,可能会进行一次交叉操作,染色体是随机选择的,交叉位置也是随机选择的,
%但该轮for循环中是否进行交叉操作则由交叉概率决定(continue控制)
pick=rand(1,2); % 随机选择两个染色体进行交叉
while prod(pick)==0 %连乘
pick=rand(1,2);
end
index=ceil(pick.*group_num); % 交叉概率决定是否进行交叉
pick=rand;
while pick==0
pick=rand;
end
if pick>cross_pro
continue;
end
% 随机选择交叉位
pick=rand;
while pick==0
pick=rand;
end
flag=0;
while flag==0
pos=ceil(pick*length(lenchrom)); %随机选择进行交叉的位置,即选择第几个变量进行交叉,注意:两个染色体交叉的位置相同
pick=rand; %交叉开始
v1=input_chrom(index(1),pos);
v2=input_chrom(index(2),pos);
input_chrom(index(1),pos)=pick*v2+(1-pick)*v1;
input_chrom(index(2),pos)=pick*v1+(1-pick)*v2; %交叉结束
%判断交叉后的两条染色体可不可行
limit1=mean(limit);
f11=isempty(find(input_chrom(index(1),:)>limit1(2)));
f12=isempty(find(input_chrom(index(1),:)<limit1(1)));
if f11*f12==0
flag1=0;
else
flag1=1;
end
f21=isempty(find(input_chrom(index(2),:)>limit1(2)));
f22=isempty(find(input_chrom(index(2),:)<limit1(1)));
if f21*f22==0
flag2=0;
else
flag2=1;
end
if flag1*flag2==0
flag=0;
else
flag=1;
end %如果两个染色体不是都可行,则重新交叉
end
end
new_chrom=input_chrom;
end9.子代码fitness1
function fitness_value=fitness1(input_chrom,input_num,hidden_num,output_num,input_data,output_data)
%该函数用来计算适应度值
%input_chrom 输入种群
%input_num 输入层的节点数,即数据特征数量
%output_num 隐含层节点数,隐藏层神经元的个数
%input_data 训练输入数据
%output_data 训练输出数据
%fitness_value 个体适应度值
w1=input_chrom(1:input_num*hidden_num); %输入和隐藏层之间的权重参数
B1=input_chrom(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置
w2=input_chrom(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...
hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置
B2=input_chrom(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...
hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置
% %网络权值赋值
net=newff(input_data,output_data,hidden_num,{'tansig','purelin'});
%网络进化参数
net.trainParam.epochs=20;
net.trainParam.lr=0.1;
net.trainParam.goal=0.00001;
net.trainParam.show=100;
net.trainParam.showWindow=0;
%网络权值赋值
net.iw{1,1}=reshape(w1,hidden_num,input_num);
net.lw{2,1}=reshape(w2,output_num,hidden_num);
net.b{1}=reshape(B1,hidden_num,1);
net.b{2}=reshape(B2,output_num,1);
%网络训练
net=train(net,input_data,output_data);
pre=sim(net,input_data);
error=sum(sum(abs(pre-output_data)));
fitness_value=error; %误差即为适应度
end10.子代码Mutation
function new_chrom=Mutation(mutation_pro,lenchrom,input_chrom,group_num,num,iter_num,limit)
% 本函数完成变异操作
% mutation_pro 变异概率
% lenchrom 染色体长度
% input_chrom 输入交叉过后的染色体
% group_num 种群规模
% iter_num 最大迭代次数
% limit 每个个体的上限和下限
% num 当前迭代次数
% new_chrom 变异后的染色体
for i=1:group_num %每一轮for循环中,可能会进行一次变异操作,染色体是随机选择的,变异位置也是随机选择的,
%但该轮for循环中是否进行变异操作则由变异概率决定(continue控制)
% 随机选择一个染色体进行变异
pick=rand;
while pick==0
pick=rand;
end
index=ceil(pick*group_num);
% 变异概率决定该轮循环是否进行变异
pick=rand;
if pick>mutation_pro
continue;
end
flag=0;
while flag==0
% 变异位置
pick=rand;
while pick==0
pick=rand;
end
pos=ceil(pick*sum(lenchrom)); %随机选择了染色体变异的位置,即选择了第pos个变量进行变异
pick=rand; %变异开始
fg=(pick*(1-num/iter_num))^2;
if pick>0.5
input_chrom(index,pos)=input_chrom(index,pos)+(limit(pos,2)-input_chrom(index,pos))*fg;
else
input_chrom(index,pos)=input_chrom(index,pos)-(input_chrom(index,pos)-limit(pos,1))*fg;
end %变异结束
limit1=mean(limit);
f1=isempty(find(input_chrom(index,:)>limit1(2)));
f2=isempty(find(input_chrom(index,:)<limit1(1)));
if f1*f2==0
flag=0;
else
flag=1;
end
end
end
new_chrom=input_chrom;11.子代码select
function [new_chrom,new_fitness]=select(input_chrom,fitness_group,group_num)
% 用轮盘赌在原来的函数里选择
% fitness_group 种群信息
% group_num 种群规模
% newgroup 选择后的新种群
%求适应度值倒数
fitness1=10./fitness_group; %individuals.fitness为个体适应度值
%个体选择概率
sumfitness=sum(fitness1);
sumf=fitness1./sumfitness;
%采用轮盘赌法选择新个体
index=[];
for i=1:1000 %group_num为种群数
pick=rand;
while pick==0
pick=rand;
end
for j=1:group_num
pick=pick-sumf(j);
if pick<0
index=[index j];
break;
end
end
if length(index) == group_num
break;
end
end
%新种群
new_chrom=input_chrom(index,:);
new_fitness=fitness_group(index);
end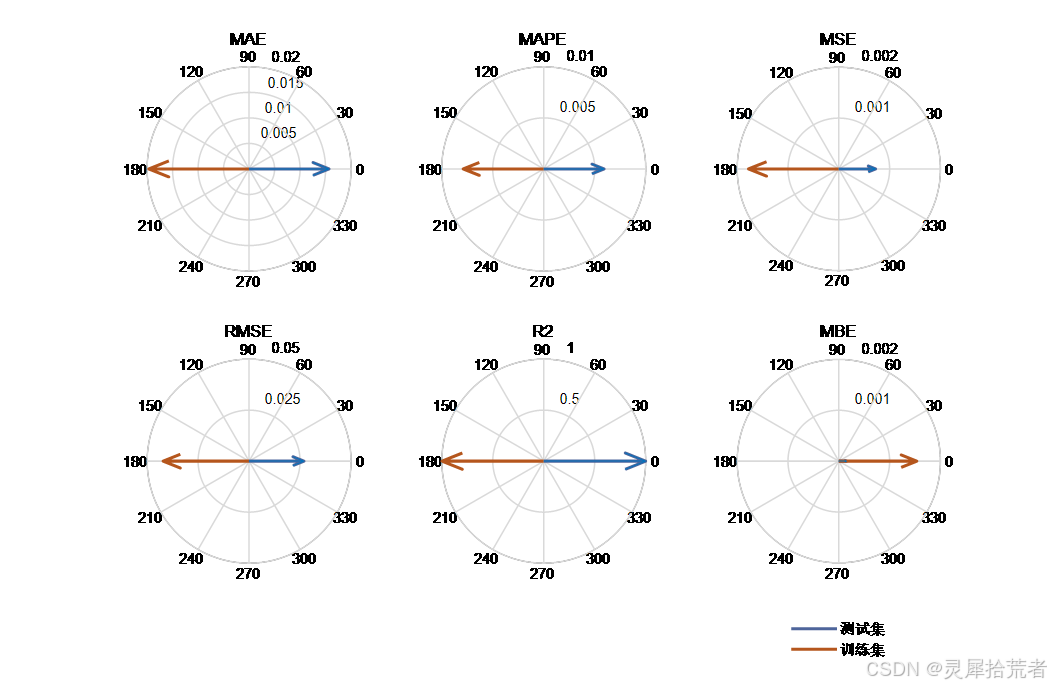
四、总结与思考
本文通过详细的代码实现和分段讲解,展示了基于 MATLAB 平台的 GA-BP 神经网络在数据拟合问题中的应用。实验结果表明,通过交叉验证确定最佳隐含层节点数,所构建的 GA-BP 网络在训练集与测试集上均获得了较低的误差和较高的决定系数,表明其具备优秀的拟合能力和泛化性能。
从实际应用角度看,该方法为非线性数据建模提供了一种有效的解决方案,但仍需注意数据预处理、参数选择等环节对模型性能的影响。未来研究可进一步探讨网络结构改进、参数优化以及多模型集成等方向,以实现更高的预测精度和稳定性。
GA优化避免了BP网络对初始参数的敏感性问题;全局搜索能力提高了模型收敛到全局最优的可能性。可尝试其他优化算法(如粒子群算法)对比性能。调整GA参数(如种群规模、交叉概率)以提升效率。
【作者声明】
本文内容基于作者对 MATLAB GA-BP 神经网络实现过程的实验与总结,所有数据和代码均为原创。文章中的观点仅代表个人见解,供读者参考交流。若有任何问题或建议,欢迎在评论区留言讨论,共同促进技术进步。
【关注我们】
如果您对神经网络、群智能算法及人工智能技术感兴趣,请关注我们的公众号,获取更多前沿技术文章、实战案例及技术分享!欢迎点赞、收藏并转发,与更多朋友一起探讨与交流!点赞+收藏+关注,后台留言可获免费资源及相关数据集。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 61
61 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)