360在离线混部 koordinator 和 hadoop-yarn 方案
公司内容器云平台使用的koordinator来调度和管理离线pod,大数据平台使用的hadoop yarn的方式来调度和运行离线作业。早期的使用方式是yarn以常驻pod的方式运行在k8s集群并通过koordinator的压制驱逐等手段来保证在线服务的稳定(每个node运行一个离线pod)。但这种运行方式有两个的弊端:1、比如申请的离线pod规格为16c 32G,运行过程中koordinator将
公司内容器云平台使用的koordinator来调度和管理离线pod,大数据平台使用的hadoop yarn的方式来调度和运行离线作业。早期的使用方式是yarn以常驻pod的方式运行在k8s集群并通过koordinator的压制驱逐等手段来保证在线服务的稳定(每个node运行一个离线pod)。但这种运行方式有两个的弊端:
1、比如申请的离线pod规格为16c 32G,运行过程中koordinator将pod可使用资源压制到10c,resourceManager仍然以16c的容量来调度任务,这样势必造成任务间的资源争抢,导致任务运行时间增长。
2、koordinator的驱逐机制有两个条件,离线pod资源满意度(整机离线可用资源 / 离线pod-request资源 < 60%)与离线pod资源实际使用率(离线pod-use-cores / pod-limit-cores > 80%), 当两个条件同时满足时会对离线pod进行驱逐。 此时会有一个场景当离线pod在满负荷运行任务时,且此时任务已经运行了一个小时很快就运行完成了,此时koordinator对离线进行了压制,且压制的满意度小于60%,满足了如上两个条件触发了离线pod驱逐,已经运行一个小时的任务就会失败。虽然任务会调度到其他的pod运行,但任务完成时间有可能会超过用户的预期时间。
一、方案
针对如上两个痛点,最理想的方案如下:
1、能够实时上报yarn-pod的最大可用资源,这样resourceManager能够根据上报的资源量进行任务调度,避免调度的任务过多导致的资源争抢。
2、koordinator驱逐机制,不直接驱逐离线pod,而是驱逐离线pod中运行的任务,通过计算决定驱逐哪些任务,如果能够接受任务运行稍慢一些,甚至可以不用驱逐任务。
二、社区方案
1、koordinator社区提供yarn-operator组件来实时完成上报nm可用资源到rm。上报资源是调用resourceManager的grpc updateNodeResource方法来实现的。
2、yarn-operator还未提供驱逐task的能力。
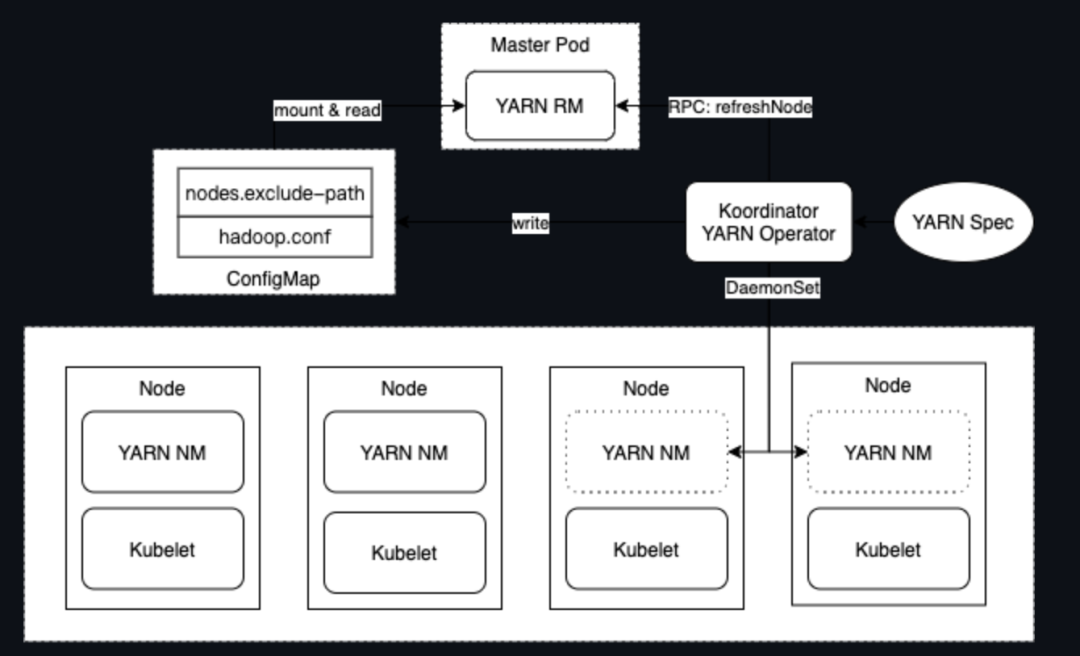
如上图,关于yarn集群的一些配置以configmap的形式挂载到yarn-operator,使yarn-operator能够通过rpc的形式调用yarn-rm的接口;当node资源有更新时,yarn-operator会获取到对应node节点上的nm可以用资源并上报资源到rm上。
如上的运行方式也会有一些风险:1、当线上大量部署时,会产生大量上报资源的请求,yarn-RM压力大增。2、yarn-operator未提供驱逐task的能力,在一些特殊场景下会影响任务的运行时长。
三、方案优化
优化后的方案对koordinator和yarn-pod均有一定的侵入性,针对360内部yarn的使用方式做的定制开发,一些思路可供参考,以下方案仅针对k8s-node与nm一一对应的场景。
1、上报资源
使用yarn-operator组件,但在其基础上做了两点优化:
-
在yarn-nm最大可用资源发生变化时且变化率超过10%时才触发上报资源((rm记录的nm cpu-cores - 此时最大可用cpu-cores)/ 此时最大可用cpu-cores > 10%),减少上报频次。
-
在yarn-operator与resourceManager之间增加了一层,该层汇总nm的最大可用资源,定时统一上报到rm,进一步减少rm的压力。
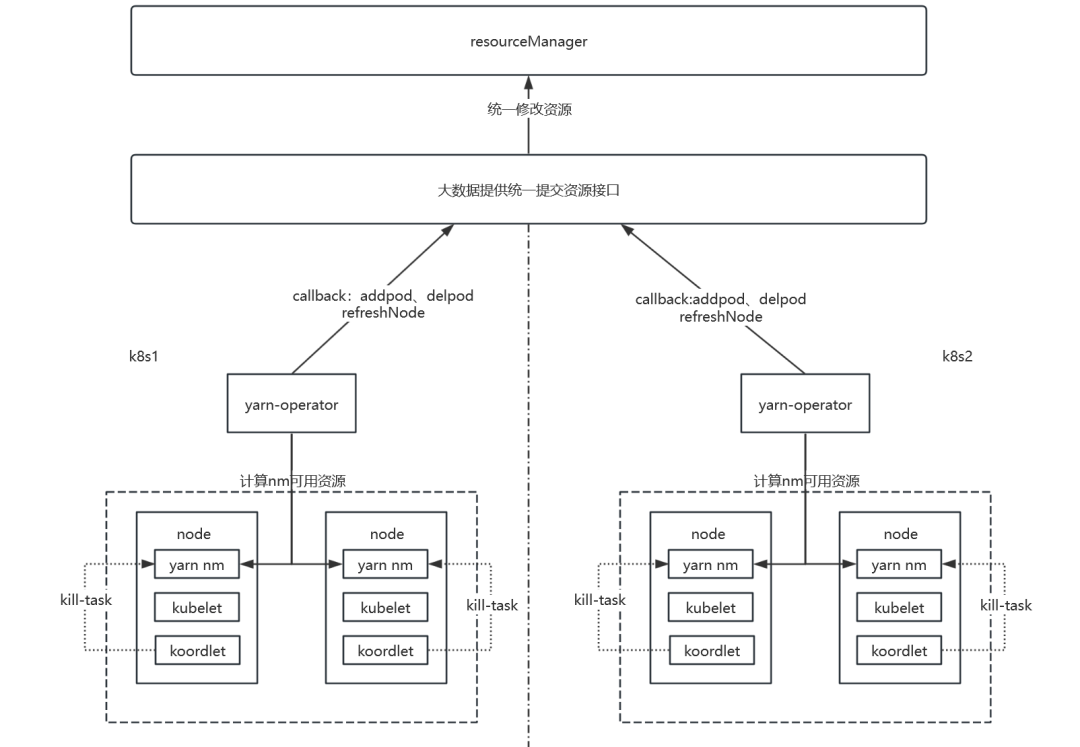
2、驱逐task
针对驱逐task,我们对yarn-pod和koordinator都做了一些定制性开发工作。
-
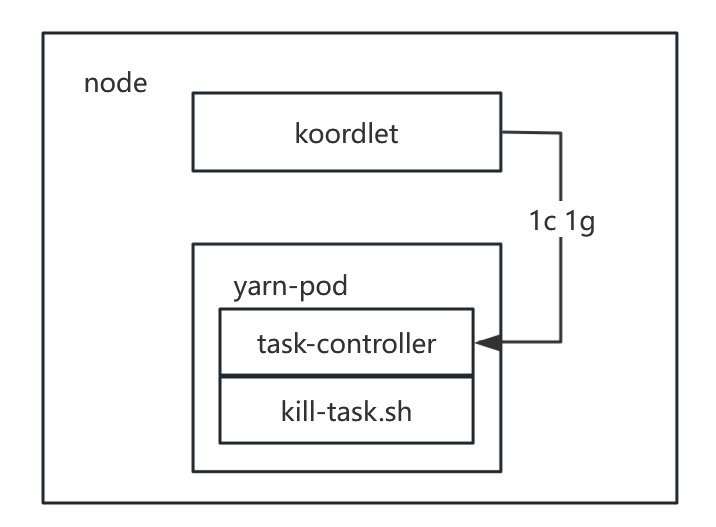
在yarn-pod中我们内置了一个kill-task脚本,该脚本接收两个参数,需要释放的cpu个数和内存大小,至于kill哪些task则由脚本内部逻辑决定,本次不做讨论。
-
在yarn-pod中内置了一个后台服务,该服务接收koordlet发送的需要释放的cpu个数和内存大小,然后定时执行kill-task脚本来驱逐task。
-
修改了koordlet的驱逐逻辑,koordlet计算出需要释放的cpu 内存大小后优先调用yarn-pod内置的服务,达到驱逐task的效果。
四、总结
360内部一些k8s集群cpu日均利用率较高能达到25%左右,在白天业务高峰时cpu利用率能达到40%左右,一些node节点的cpu利用率能够达到70%+,由于白天也会有部分离线任务运行在云平台,此时势必造成yarn-pod的资源压制大量驱逐,离线服务质量严重降低。通过上报nm可用资源的方式解决了resourceManager一直以pod limit资源量调度任务导致的资源争抢的问题。在资源紧张的情况下通过只驱逐任务的方式进一步提升离线任务的成功率。
在公司内部离线pod的部署使用了HPA自动扩容功能,扩容功能不必多说,但是在缩容时很大概率会缩容到有大量任务运行的pod,此时就需要指定pod缩容的功能,可以使用pod-deletion-cost特性来完成指定离线pod缩容的功能。
五、未来规划
现在这套离线任务运行架构还是不能完美的运行在云平台上,25年离线任务服务平台会做进一步的优化,每一任务的运行都会启动一个pod,为解决离线pod数量过多k8s-scheduler压力过大的问题,k8s平台还会引入volcano组件,利用volcano的调度器、podgroup、queue等功能解决调度问题和资源分配等问题。
END
360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。
目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案,助力客户降本增效,累计服务业务1000+。
智汇云致力于为各行各业的业务及应用提供强有力的产品、技术服务,帮助企业和业务实现更大的商业价值。
官网:https://zyun.360.cn 或搜索“360智汇云”
客服电话:4000052360
欢迎使用我们的产品!😊
关注公众号,干货满满的前沿技术文章等你来。想看哪方面内容,也欢迎留言和我们交流!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)