如果利用 ARIMA 模型进行GBD数据库的全球疾病负担趋势预测 (GBD系列第五集)
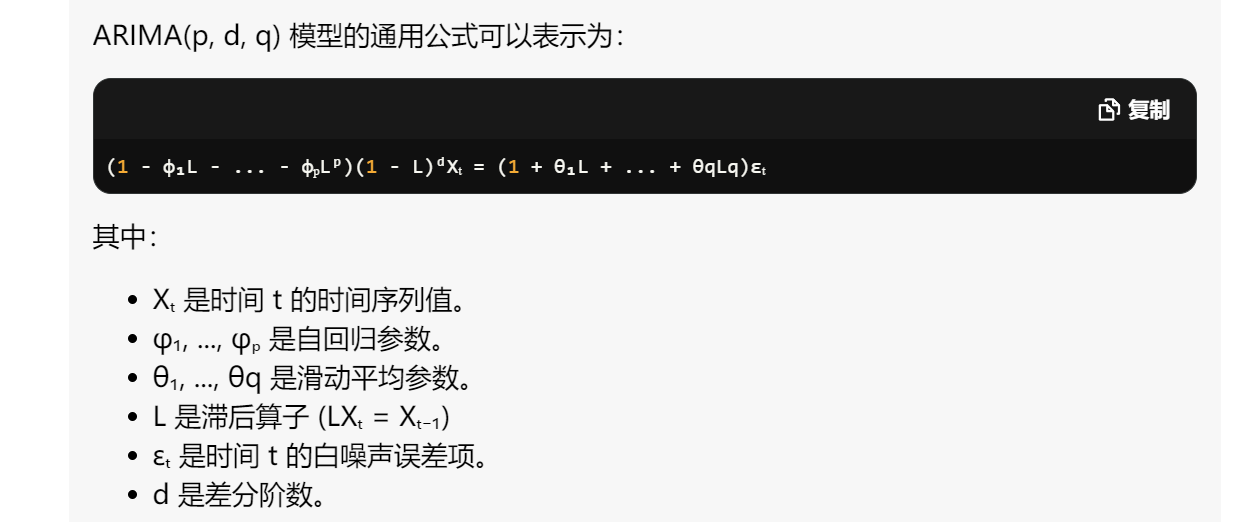
自回归积分滑动平均 (ARIMA) 模型是一种广泛使用的统计方法,专门设计用于分析和预测时间序列数据。与假设数据点彼此独立的传统回归模型不同,ARIMA 模型明确考虑了时间序列数据中固有的序列相关性。ARIMA 模型通常表示为 ARIMA(p, d, q),其中 p 是自回归阶数,d 是积分阶数,q 是滑动平均阶数。例如,ARIMA(1, 1, 1) 模型表示具有一个自回归项、一次差分和一个滑动平
自回归积分滑动平均 (ARIMA) 模型是一种广泛使用的统计方法,专门设计用于分析和预测时间序列数据。与假设数据点彼此独立的传统回归模型不同,ARIMA 模型明确考虑了时间序列数据中固有的序列相关性。这意味着当前观测值的值取决于其过去的观测值。这种能力使 ARIMA 模型成为预测各种领域(包括经济学、金融学、气象学和流行病学)中时间序列数据的强大工具。
ARIMA 模型的表示
ARIMA 模型通常表示为 ARIMA(p, d, q),其中 p 是自回归阶数,d 是积分阶数,q 是滑动平均阶数。例如,ARIMA(1, 1, 1) 模型表示具有一个自回归项、一次差分和一个滑动平均项的模型。
ARIMA 模型怎么实现GBD数据预测
GlobalBurdenR 包提供了函数来简化 GBD 数据的 ARIMA 模型实施。GBD_arima_predict函数用于对单个时间序列进行预测,而GBD_arima_predict_multi 函数用于对多个时间序列(例如,不同年龄组)进行预测
以下代码演示了如何使用 GBD_arima_predict 函数预测死亡率:
library(GlobalBurdenR)
library_required_packages()
data=read.csv('ES.csv')
# 示例:过滤数据
data_e=gbd_filter(data,measure=='Deaths',age=='Age-standardized',
sex=='Male',metric=='Rate',location=='Global')
# 预测到2050年
result_2030 <- GBD_arima_predict(data_e,
historical_title = "历史趋势",
forecast_title = "预测趋势",
x_label = "年份",
y_label = "AMSR",
color_palette = "VanGogh2",
forecast_end_year = 2050)
result_2030$forecast_data # 访问预测数据
result_2030$combined_plot # 访问历史数据和预测数据的组合图GBD_arima_predict_multi 函数用于预测多个年龄组的趋势:
######多年龄组data_age_all=gbd_filter(data,measure=='Deaths',sex=='Male',metric=='Rate',location=='Global')result_multi <- GBD_arima_predict_multi(data_age_all,historical_title = "历史趋势",forecast_title = "各年龄组死亡率趋势和预测",x_label = "年份",y_label = "死亡率",forecast_end_year = 2050,max_year = 2019)result_multi$plots # 访问每个年龄组的预测图

在公共卫生研究领域,GBD数据库结合ARIMA预测分析,已成为高质量论文写作的重要工具。掌握这一方法,将为您的学术研究开启新的视角。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)