大模型训练是做什么?为什么那么烧钱?
大模型就如同一个婴儿,从他诞生起,虽有大脑,但是并不聪明,需要人们教会他各种行为,如走路,吃饭,说话,写字,计算等等。首先是采集的数据或者说是买数据,可能得喂它全世界的新闻、几百亿条聊天记录、几亿本书,几十亿张图,几百亿条视频,有些是免费的有些是付费的,付费的光是买版权就是一大笔钱。练了好久,模型得考试,看看它学得咋样。总之,训练的整个过程的核心,是让模型从数据里找到最贴近真实世界的“规律” ,生
小朋友问,AI大模型为什么那么耗钱?经常听说大模型训练这个词,那么大模型训练是在做什么?今年在DeepSeek概念普及的浪潮中, 相信很多人也有这样的问题。
今天咱们就来聊聊,这训练到底是在干什么?为什么会烧那么多钱!
大模型是从英语 Large Language Models 翻译过来的,就是大语言模型。是一种深度学习模型,它通过模拟人脑的“神经网络”,从数据中学习复杂特征。大模型就如同一个婴儿,从他诞生起,虽有大脑,但是并不聪明,需要人们教会他各种行为,如走路,吃饭,说话,写字,计算等等。这就是通过训练教会孩子各种本领。人工智能也是需要训练的,让它最终掌握各种本领。这个训练过程就叫“大模型训练”。
那么人类是如何训练大模型的?
第一步,收集数据。在训练一个大脑的时候,得准备让他记住很多知识。所以训练大模型就是要收集好多数据。比如全世界的各种文字的历史文献,网页内容,图画,声音,视频等。这是海量数据。曾经狂喷DeepSeek的这位华裔开的公司,就是卖数据给各个大模型公司的。

数据的数量和质量直接影响模型的表现。数据数量可以比较容易得到,那么数据质量如何保证呢?
第二步:数据预处理:对原始数据进行清洗、分词、标注等操作,生成海量的数据,使其适用于训练模型。并不是拿到了数据就能直接喂给大模型的,需要过滤筛选一下,去除或修正其中的错误、不一致或冗余信息,以确保数据的准确性。此前有报道,豆包公司的实习生,污染了训练数据被起诉赔偿800万。这实习生真是挺能搞事的,还没赚工资,倒欠债800万。
分词是把句子分解出有意义的词语,便于后续的组合,有助于提高模型的理解能力。这以对话为主的模型(如豆包)尤为重要。
标注就是对数据的一类属性打个标记,告诉大脑这个词是描述颜色的,那个词是描述大小的 ,使得模型能够学会识别和分类不同词语信息。其实,很多数据公司就是招人来给数据打标注。比如让大模型在一幅图片中识别一辆卡车,那么需要在很多的车辆图片中标记出卡车,好让大模型记住各种形态颜色的车辆,在遇到新的卡车时 能“认出” 这是卡车。
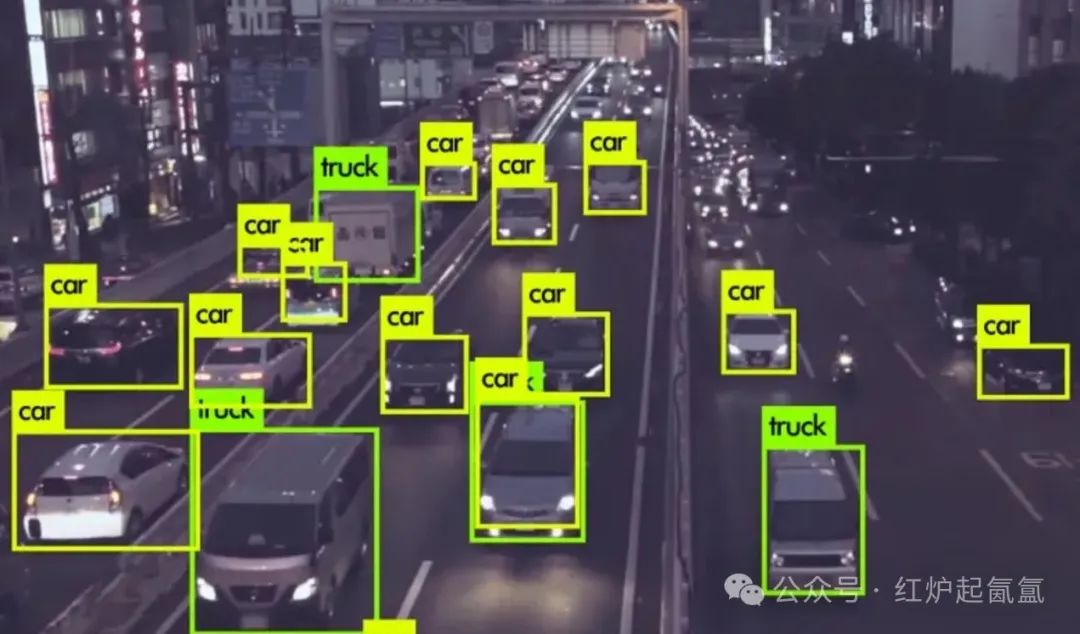
第三步,接下来,有了好的数据,就得喂给大模型吃。但它不是真的用嘴吃,而是用一种叫“神经网络”的东西“消化”。大模型的神经网络是模拟人类大脑记忆方式,就像的大脑,里面有很多小格子(叫“神经元”),专门记东西。

喂饭的过程是这样的:把数据切成小块,一口一口喂。比如,一句话“今天天气很好”,就拆成“今天”“天气”“很好”,让模型猜下一个词是什么。刚开始它啥也不知道,可能会胡猜:“今天天气……苹果?”错了!我们就告诉它:“不是苹果,是很好!”它就记下来,下次再猜就聪明点了。
第四步:反复练习“做题”——调整模型参数

几年前的人工智能对话还经常被讥笑讽刺是人工智障(上图,谷歌翻译的《出师表》的一段),但是今天的聊天机器人那是相当“体贴”。
这得益于模型对数据的反复不停的练习,使得它变聪明了。练习的过程叫“反向传播”,听着复杂,其实就像考试改错题。
比如,模型猜错了“今天天气很好”,说成了“今天天气很苹果”。我们就给它打个叉,说:“错啦,应该是‘很好’,你差了多远?”然后模型会调整自己大脑里的小格子,让“很好”这个答案的分数(权重)变高,“苹果”变低。每次猜错都改一点点,慢慢地它就学会了。
这个过程需要超级多计算,得用那种很贵的电脑芯片(GPU)运行好多天。因为它不是学一句话,而是学几亿句话,每次都必须算得特别准。
第五步:考试升级——测试和优化
练了好久,模型得考试,看看它学得咋样。比如,我们问它:“写个关于猫的故事。”它要是写出“猫咪挥动着翅膀在天上飞”,那就得再回去练。如果写出“猫咪在树上喵喵叫”,还不错,可以表扬一下。
考试不过,就得喂更多数据,或者换个方法重新训练。考试过了,就可以“毕业”,开始帮我们干活了,比如回答问题、写文章,生成图画和视频。
总之,训练的整个过程的核心,是让模型从数据里找到最贴近真实世界的“规律” ,生成准确有意义的内容,最终展示出来。
训练为什么很费钱?
因为 各个环节都很贵啊。
首先是采集的数据或者说是买数据,可能得喂它全世界的新闻、几百亿条聊天记录、几亿本书,几十亿张图,几百亿条视频,有些是免费的有些是付费的,付费的光是买版权就是一大笔钱。就像现在很多网站看个视频,听个音乐,看个文档都要付费,更别说专业刊物,论文,著作。甚至有些不公开的数据,也得从各种渠道买。数据收集、版权费、人工整理费,可能几百万,几千万甚至上亿美元。
其次,训练用的芯片GPU,TPU价格昂贵,少则几万人民币一张,多则几百万。为了压缩训练时间,都是用多块GPU协调工作,一个大模型少则几千张,多则几十万张高性能的GPU芯片.。DeepSeek据公开信息显示用了2048块GPU, ChatGPT 4据称用30000张卡,马斯克的最新大模型Grok 3 号称用了20万张卡。所以造芯片的英伟达公司赚翻了。

仅仅是买卡就得花费几亿,几十亿。
研发人员的工资高。能调教大模型的这些人,绝顶聪明,个个是大咖,都是科学家,天才级别的人。可想而知他们的工资价格。
训练过程费用高。一旦开启训练,资源消耗惊人,仅仅电费就高得离谱,几乎是欧洲一个小城市的同时长用电量。如果训练途中发现错乱了,就得重新开始训练,前面很多钱打水漂了。据说OpenAI公司的ChatGPT 5 现在训练一次的费用超过5亿美元,效果还不明显,连微软都快烧不起了,ChatGPT5 的诞生一拖再拖,一直无法如期面世。
此外,存储海量数据的容器费用,网络维护,机房的降温费用,每一项都是巨大的花费。
所以,能研发大模型的公司并不多,小公司实在掏不出那么多的钱,尤其是在目前还在烧钱研发的阶段。
最后大模型贵,是因为它吃的“饭”多、用的“厨房”豪华、请的“老师”牛、试错成本高,还得花超长时间。就像养个超级巨婴,得用金碗喂饭、请院士当家教,摔一次还得赔个金山。贵是贵,但它学会的本领也能帮我们干大事,所以才有人愿意砸钱!
关注公众号,更多精彩:


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)