强化学习(赵世钰版)-学习笔记(5.蒙特卡罗法)
·
本章内容是算法与方法部分的第二章,用于处理模型参数未知的情况。
比如说一个投掷硬币的问题,正反面各设定一个得分,如果知道该模型的参数(即正反面出现的概率),则很容易计算出这个投掷硬币问题的得分期望值(其中一面的得分×这一面出现的概率,两面都算一遍再加起来)。

但是如果不知道模型参数(即不知道每一面出现的概率),那么可以对硬币投掷多次,通过采集到的样本对问题进行估算(本例子是对得分的期望值进行估算),这种方法就叫做蒙特卡罗估计(Monte Carlo Estimation)。

蒙特卡罗方法的准确性与样本数量有关,样本量越大,则估计出的结果越准确。
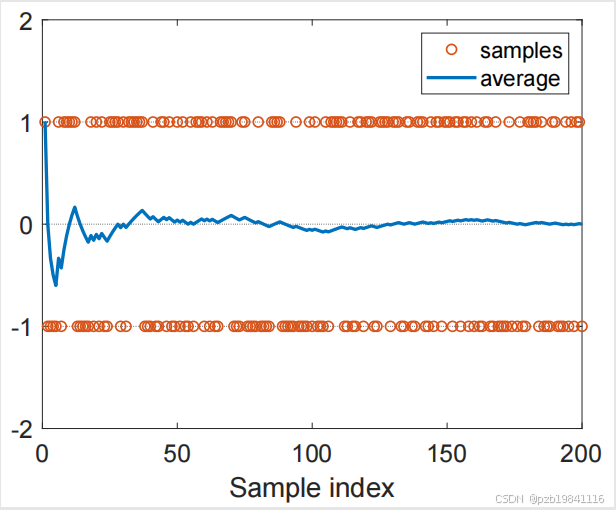
这个依据的是统计学中的大数定理(low of large number),前提是样本之间要相互独立(independent and Identically distributed),否则无法保证样本的随机性。

蒙特卡罗方法本质上是一系列方法的统称,核心理念是利用一系列重复的随机采样,来解决一个近似问题( approximation problem)。优点就是可以在不知道模型参数,或者不依赖模型参数的情况下,利用样本解决问题。其实这也反映出数据科学的相关特点,要解决一个问题,要么需要知道模型信息,要么需要获取到足够多相互独立的数据。
下面介绍基于MC最简单的强化学习算法-MC Basic,该算法是对策略迭代算法的修改,将蒙特卡罗方法替换原有的依赖模型参数的计算。策略迭代算法大致分为两步,核心是计算模型中各状态下每个行为的行为值。

那么这个行为值如何计算呢?如果有模型参数,则套用公式予以计算即可(第四章的内容)。如果模型参数未知,则就用样本来进行估计。

如何利用数据获取到行为值呢,本质上就是在系统里面多跑几个回合(Episode),利用采集到的结果对行为值进行估计。

所以,MC Basic算法与策略迭代算法类似,都是分两步进行。第一步策略评估,策略迭代法是用模型参数计算各行为值,而MC Basic是直接用采样的样本进行估算。

第二步是策略更新,两个算法的操作是一样的,都是讲最优行为替换原有的行为。

下面是MC Basic算法的伪代码(没有仔细看)

MC Basic算法是基于蒙特卡罗算法的相对最简单的方法,它是基于值迭代法改进的方法,将其中的行为值计算这一步,改用采样的样本进行估计,而不是直接用模型参数计算(因为模型参数可能是未知的)。理论上也可以对状态值进行估计,但是状态值不能直接指导策略的更新,还得转换成行为值,所以不如直接对行为值进行估计。MC Basic的计算效率较低,因此很少用在实际当中,仅用于教学。
针对MC Basic低效问题的改进算法叫MC Exploring Starts算法。首先课程介绍了一些概念,一个策略确定以后(可能参数不知道),每个回合本质上就是一个状态-行为的链。每个确定的时间下,都会有一个确定的状态-行为对,我们称作访问了一个状态-行为对。
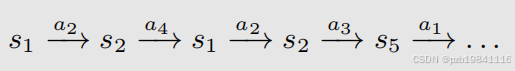
基于MC的算法,本质上就是计算每个回合的返回值,并估算行为值。而MC Basic的思路是在策略估计阶段,需要搜集到一个状态-行为对上所有的回合数据,再进行行为值的估算。这种策略的问题在于效率太低,需要等到所有的采样完全结束后,才能得到行为值的估算结果。改进的思路就是按回合进行迭代(episode by episode),每次回合结束后都对现有的行为值进行修正,不用等到所有采样结束后才出结果。这种思路跟截断策略迭代类似,虽然每一步不是非常精确但胜在速度快,最后也能收敛到真实值上。
MC Exploring Starts算法的伪代码如下所示

Exploring Starts意味着每个状态-行为对上,都要产生足够多的回合(Episode)数量,否则就不准了(跟大数定理说的是一回事)。

理论上必须对每个状态下每个行为进行充分的探索,才能找到最优的行为值,否则很有可能会漏掉。但是在实际操作中,很难保证这个前提假设,所有状态下的所有行为,都得到了充分的探索(比如小概率事件或零概率事件,每次抽样都没有抽到)。
这样就引出了第三个算法,不包含Exploring Starts的MC算法-MC e-Greedy(希腊字母打不出来)。

这里又引入了一个新的概念-软策略(soft policy),指的是所有候选项发生的概率都是正的(即所有的事件都是有可能发生的)。常用的策略分为两种,一个是确定性的策略,比如贪心策略,每次都选概率最大的。一个是随机性策略,比如软策略。

为什么要引入软策略,目的就是一个回合足够的长,那么就会访问到所有的状态-行为对,这样就避免了大量的回合采样(只跑少量的几个回合,就访问到了所有的状态-行为对),因此这个Exploring Starts就可以取消掉了。

那么如何实现这个软策略呢,就是这个算法的标题,用一个特殊的贪心策略。数学公式很复杂,本质上就是给其他不容易访问到的状态-行为对,分配一些小的概率,不要一棒子打死。

而算法的这个超参数,用于调整整个算法的特性。取值越小算法越趋近于贪心算法,只注重眼前利益。取值越大越富有冒险精神,倾向于探索新的路径。

如何将这个软策略嵌入到原有的MC Basic方法中呢?就是对算法第一步的修改,更改这里的行为发生的概率。

下面是整个算法的伪代码

这个算法的特点也很明显,优点是有探索精神,不需要大量的回合来探索所有的状态-行为对。缺点是结果通常意义下不是全局最优解。

这里就结束了,核心思路跟上一章完全不同,是用蒙特卡罗的方法对目标值(即行为值)进行抽样与估计,不依赖于模型的相关参数(或者参数获取不到的时候)。基于蒙特卡罗的算法有三个,MC Basic是基础,后面两个是对他的改进。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)