深度学习必学知识点之梯度(Gradient)
梯度是机器学习中衡量模型参数调整方向和大小的关键指标。它通过损失函数的偏导数来表示参数更新方向,梯度下降算法利用该信息逐步优化模型。在单变量函数中梯度是导数,多变量函数中则是偏导数向量。实际应用中通过反向传播计算梯度:前向传播计算损失,反向传播逐层求导,最后用学习率控制参数更新步长。梯度指示了损失函数下降最快的方向和幅度,帮助模型找到最优解,是训练过程中的核心导航工具。
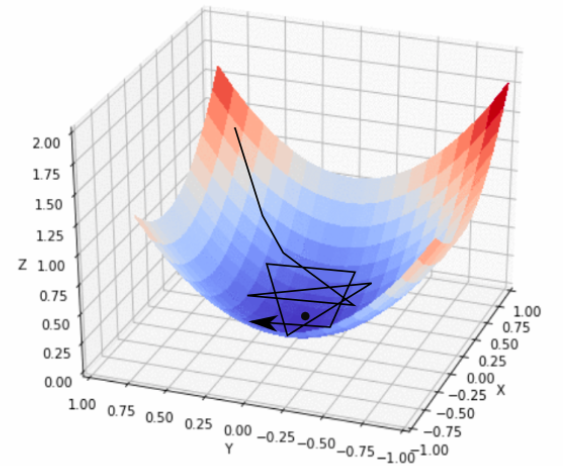
梯度(Gradient) 是机器学习和深度学习中的一个核心概念。为了帮助大家理解,我用一个通俗的例子来解释。
1. 类比:山坡与方向
想象你正在一座山上,目标是找到山谷的最低点(也就是损失函数的最小值)。你蒙着眼睛,只能通过脚下的坡度来判断方向。你需要一步一步地往山下走,最终到达最低点。
-
山坡的坡度:代表梯度。
-
坡度越陡,说明你离最低点越远。
-
坡度越平缓,说明你离最低点越近。
-
-
坡度的方向:告诉你应该往哪个方向走才能更快地下山。
在这个类比中:
-
山:代表模型的损失函数(Loss Function),衡量模型预测值与真实值之间的误差。
-
坡度:就是梯度,指示你每一步应该往哪个方向走。
-
最低点:就是损失函数的最小值,也就是模型的最优解。
2. 什么是梯度?
在数学中,梯度是一个向量,表示函数在某一点的变化率最快的方向。对于机器学习模型来说:
-
损失函数:衡量模型预测值与真实值之间的误差。
-
梯度:是损失函数对模型参数的偏导数,指示参数应该如何更新才能使损失函数减小。
公式如下:

3. 梯度的作用
梯度告诉模型:
-
方向:参数应该往哪个方向更新才能使损失函数减小。
-
大小:参数应该更新多少(由学习率控制)。
在梯度下降法中,模型参数的更新公式为:

4. 梯度的直观理解
(1)单变量函数

(2)多变量函数
对于多变量函数,梯度是一个向量,每个分量是函数对相应参数的偏导数。例如:
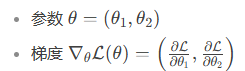
5. 梯度的计算
在实际应用中,梯度是通过反向传播算法(Backpropagation)计算的。具体步骤:
-
前向传播:计算模型的预测值和损失函数。
-
反向传播:从损失函数开始,逐层计算梯度。
-
参数更新:根据梯度更新模型参数。
6. 总结
-
梯度 是损失函数对模型参数的偏导数,指示参数应该如何更新才能使损失函数减小。
-
梯度的方向:告诉模型参数应该往哪个方向更新。
-
梯度的大小:告诉模型参数应该更新多少(由学习率控制)。
-
通过梯度下降法,模型可以逐步找到损失函数的最小值,从而优化模型性能。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)