手把手教学:SpringBoot整合LangChain4j实现知识库RAG检索
检索增强生成(Retrieval-augmented Generation)1. 基础大模型的局限性知识时效性差:依赖公开数据训练,存在周期性更新延迟,难以覆盖快速变化领域(如科技、金融)的新概念或实时信息。业务适配不足:无法直接访问企业内部分散的非结构化数据(如文本、Word、HTML、数据库等),导致对特定业务场景的理解受限。2. 传统方案(函数调用/系统消息)的瓶颈信息承载
(一)手把手教学:LangChain4j实现Java与AI大模型深度对话
(二)Windows搭建AI大模型应用开发环境以及踩过的坑
(三)Windows搭建AI大模型应用开发环境 - 向量数据库pgvector
(四)手把手教学:SpringBoot+LangChain4j实战全攻略
(五)手把手教学:SpringBoot整合LangChain4j实现知识库RAG检索
(六)手把手教学:SpringBoot + MCP + Cherry Studio
一、RAG
1、什么是RAG:
检索增强生成(Retrieval-augmented Generation)
1. 基础大模型的局限性
- 知识时效性差:依赖公开数据训练,存在周期性更新延迟,难以覆盖快速变化领域(如科技、金融)的新概念或实时信息。
- 业务适配不足:无法直接访问企业内部分散的非结构化数据(如文本、Word、HTML、数据库等),导致对特定业务场景的理解受限。
2. 传统方案(函数调用/系统消息)的瓶颈
- 信息承载有限:仅能处理少量简单查询,无法支持大规模业务知识的整合与调用。
3. RAG的核心价值
- 动态知识库外接:通过对接结构化业务知识库(如产品手册、客户案例、服务政策),实时检索精准信息,供大模型结合自身推理能力生成专业回答。
- 场景应用示例:
企业客服场景中,通用模型结合知识库,可基于产品详情、政策条款等内部数据生成针对性回复,提升准确性和服务效率
2、RAG工作流程
于文档的检索增强生成有两个阶段。在第一阶段,文档会被处理并安装到数据库中,通常是向量数据库。第二阶段则是如下所示的数据检索:

让我们来了解一下这些步骤是什么,然后看看下面你可以学习哪些课程来掌握它们。解释会比较简要,你可以通过学习课程来了解更多内容!
l 提取:文档有各种各样的文件格式(如.doc、.pdf 等),并且包含各种数据格式(文本、表格、图像、视频)。这些都必须被提取出来,并转换为可被后续阶段处理的格式。
l 分块:文本数据会被分解成更小的块 —— 这个过程被巧妙地命名为 “分块”。
l 嵌入:将一个文本块转换为一个代表文本含义的 “密集向量”。
l 加载:将嵌入向量和原始数据添加到数据库中。
l 数据库:数据库将为嵌入向量和数据提供存储功能。由于嵌入向量的存在,通常会使用向量数据库,但图数据库和传统数据库也会被用到。
l 查询嵌入:使用相同的嵌入模型将查询转换为密集向量。
l 检索:存储的向量和查询向量都代表含义,所以检索就是找到数据库中与查询向量 “最接近” 的 k 个条目的过程。这里面有很多细节!k 个结果会被提供给大型语言模型,它会利用这些结果形成一个 “增强” 后的回复。
3、嵌入模型(Embedding Model)
Embedding是一种将离散的非结构化数据(如文本中的单词、句子或文档)转换为连续向量的技术。
在自然语言处理(NLP)领域,Embedding通常用于将文本映射为固定长度的实数向量,以便计算机能够更好地处理和理解这些数据。每个单词或句子都可以用一个包含其语义信息的向量来表示。
Embedding常用于将文本数据映射为固定长度的实数向量,从而使计算机能够更好地处理和理解这些数据。每个单词或句子都可以用一个包含其语义信息的实数向量来表示。
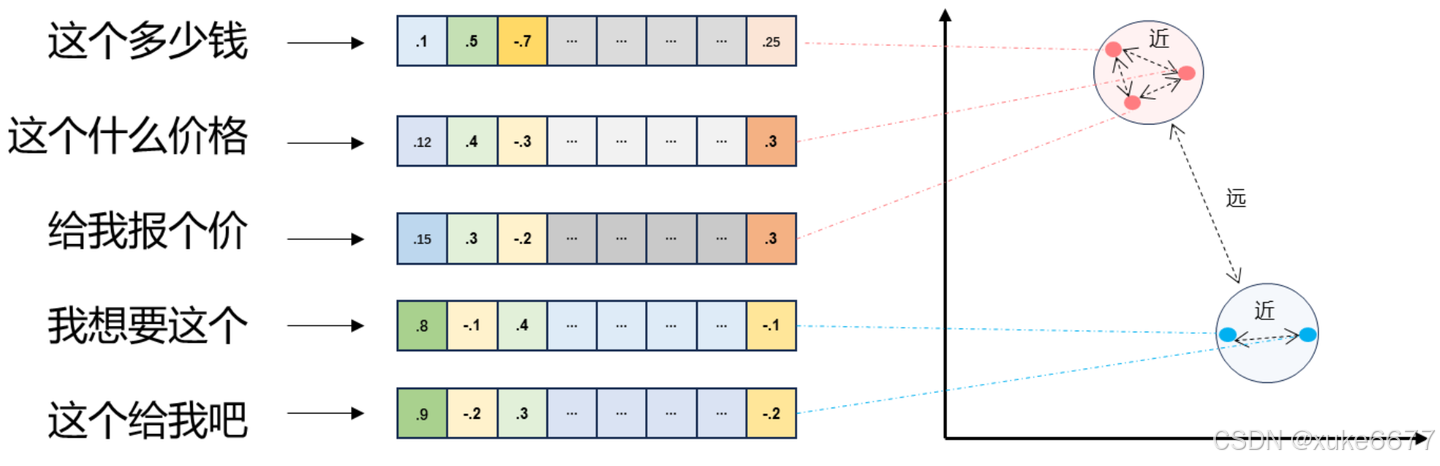
- 将文本转成一组浮点数:每个下标 i,对应一个维度。
- 整个数组对应一个多维空间的一个点,即文本向量,又叫 Embeddings。
- 向量之间可以计算距离,距离远近对应 语义相似度 大小。
二、RAG基于pgVector作为向量数据库的实战
1、向量数据库
对于向量模型生成出来的向量,我们可以持久化到向量数据库,并且能利用向量数据库来计算两个向量之间的相似度,或者根据一个向量查找跟这个向量最相似的向量。 在LangChain4j中,EmbeddingStore表示向量数据库,它有支持20+ 嵌入模型:
| Embedding Store | Storing Metadata | Filtering by Metadata | Removing Embeddings |
|---|---|---|---|
| In-memory | ✅ | ✅ | ✅ |
| Astra DB | ✅ | ||
| Azure AI Search | ✅ | ✅ | ✅ |
| Azure CosmosDB Mongo vCore | ✅ | ||
| Azure CosmosDB NoSQL | ✅ | ||
| Cassandra | ✅ | ||
| Chroma | ✅ | ✅ | ✅ |
| ClickHouse | ✅ | ✅ | ✅ |
| Coherence | ✅ | ✅ | ✅ |
| Couchbase | ✅ | ✅ | |
| DuckDB | ✅ | ✅ | ✅ |
| Elasticsearch | ✅ | ✅ | ✅ |
| Infinispan | ✅ | ||
| Milvus | ✅ | ✅ | ✅ |
| MongoDB Atlas | ✅ | ✅ | ✅ |
| Neo4j | ✅ | ||
| OpenSearch | ✅ | ||
| Oracle | ✅ | ✅ | ✅ |
| PGVector | ✅ | ✅ | ✅ |
| Pinecone | ✅ | ✅ | ✅ |
| Qdrant | ✅ | ✅ | ✅ |
| Redis | ✅ | ||
| Tablestore | ✅ | ✅ | ✅ |
| Vearch | ✅ | ||
| Vespa | |||
| Weaviate | ✅ | ✅ |
2、开发环境
1. JDK 17
2、docker中运行pgVector向量数据库
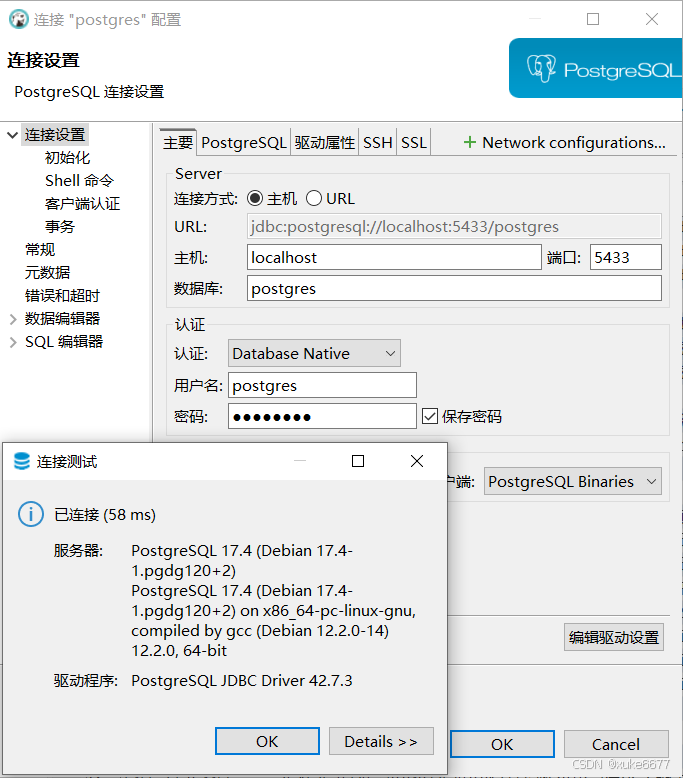
docker run --name pgvector -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=postgres -p 5433:5432 -v /home/coco/postgresql/data:/var/lib/postgresql/data -d pgvector/pgvector:pg173、连接数据库客户端DBeaver
5、启用PgVector 扩展
-- 启用PgVector 扩展
CREATE EXTENSION IF NOT EXISTS vector;
CREATE EXTENSION IF NOT EXISTS hstore;
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";三、案例代码
1、pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lc</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>langChain4j</name>
<description>langChain4j RAG Demo project for Spring Boot</description>
<properties>
<java.version>17</java.version>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<langchain.version>1.0.0-beta2</langchain.version>
<springboot.version>3.4.4</springboot.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.13</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>${langchain.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>${langchain.version}</version>
<exclusions>
<exclusion>
<artifactId>bcprov-jdk18on</artifactId>
<groupId>org.bouncycastle</groupId>
</exclusion>
<exclusion>
<artifactId>commons-compress</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${springboot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2、application.yaml
server:
port: 8081
langchain4j:
community:
dashscope:
chat-model:
api-key: 你的阿里云百炼平台apikey
model-name: qwen-max
embedding-model:
api-key: 你的阿里云百炼平台apikey
#model: multimodal-embedding-v1
model: text-embedding-v2
pgvector:
database: postgres
host: localhost
port : 5433
user: postgres
password: postgres
table: vector_store
logging:
level:
root: DEBUG
# LangChain4j 核心模块
dev.langchain4j: DEBUG3、测试文档(2025年中国房地产市场发展趋势分析.txt)
2025年中国房地产市场发展趋势分析
一、市场分化加剧,核心城市率先回暖
核心城市表现强劲
北京、上海、深圳等一线城市及部分新一线城市(如杭州、成都)土地市场热度回升,高溢价地块频现,一季度平均溢价率回升至11%。二手房市场成交活跃,北京1-2月网签量同比增长近3成,深圳、上海也呈现类似回暖趋势。
核心城市房价预计温和上涨,涨幅或不超过5%,主要因政策支持、人口流入及改善需求旺盛。
三四线城市持续承压
多数三四线城市库存高企(去化周期超36个月),房价较峰值回落超50%,部分回归至2014-2015年水平。人口流失、经济疲软导致需求低迷,政策刺激空间有限。
二、供需关系结构性调整
供应端优化
土地市场延续缩量提质趋势,一二线城市成交金额同比上升9%,核心城市供地占比提升,房企拿地更趋谨慎。
新房供应持续下降,2025年全国新建商品房供应面积预计同比减少8%,优质住房供给不足支撑核心城市房价。
需求端分化
改善型需求成为主力,高“质价比”现房及精装交付产品更受青睐。政策降低置换成本(如契税优惠、降利率),推动“一买一卖”交易活跃。
城镇化率提升至67%,年均1200万人口流入支撑一二线城市刚性需求。
三、政策驱动市场止跌回稳
需求侧支持
房贷利率降至历史低位(首套平均4.0%),二套房首付比例下调至15%,限购政策优化释放改善需求。
政府通过“以存量换增量”模式收购闲置商品房,缓解库存压力,同时推动“好房子”标准体系建设。
供给侧改革
“白名单”融资机制支持房企合理融资,2024年审批贷款超6万亿元,保交楼覆盖1500万套住房。现房销售试点扩大,占比提升至26.5%。
四、市场结构变革与风险
交易模式转型
现房销售占比持续提升,二手房因价格弹性更大成为市场回暖先行指标。2025年新房+二手房总成交额预计与2024年持平,存量房交易占比扩大。
风险与挑战
三四线城市土地财政依赖度高,房企资金链紧张导致部分项目烂尾风险仍存。
行业洗牌加速,房企从“赚快钱”转向精细化运营,需通过城市更新、产品升级提升竞争力。
总结
2025年房地产市场呈现“冰火两重天”格局:核心城市在政策托底、供需优化下温和回暖,三四线城市仍面临深度调整;政策重点从“稳规模”转向“提质量”,改善型需求与现房交易主导市场。行业整体进入“止跌回稳”关键阶段,但全面复苏仍需时间4、YAML配置文件中的pg配置类
package com.lc.langChain4j.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
@Configuration
@ConfigurationProperties(prefix = "pgvector")
@Data
public class PgConfig {
private String host;
private int port;
private String database;
private String user;
private String password;
private String table;
}5、自定义EmbeddingStore
package com.lc.langChain4j.config;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.pgvector.PgVectorEmbeddingStore;
import lombok.RequiredArgsConstructor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@RequiredArgsConstructor
public class EmbeddingStoreInit {
final PgConfig pgConfig;
@Bean
public EmbeddingStore<TextSegment> initEmbeddingStore() {
return PgVectorEmbeddingStore.builder()
.table(pgConfig.getTable())
.dropTableFirst(true)
.createTable(true)
.host(pgConfig.getHost())
.port(pgConfig.getPort())
.user(pgConfig.getUser())
.password(pgConfig.getPassword())
//.dimension(384)
.dimension(1536)
.database(pgConfig.getDatabase())
.build();
}
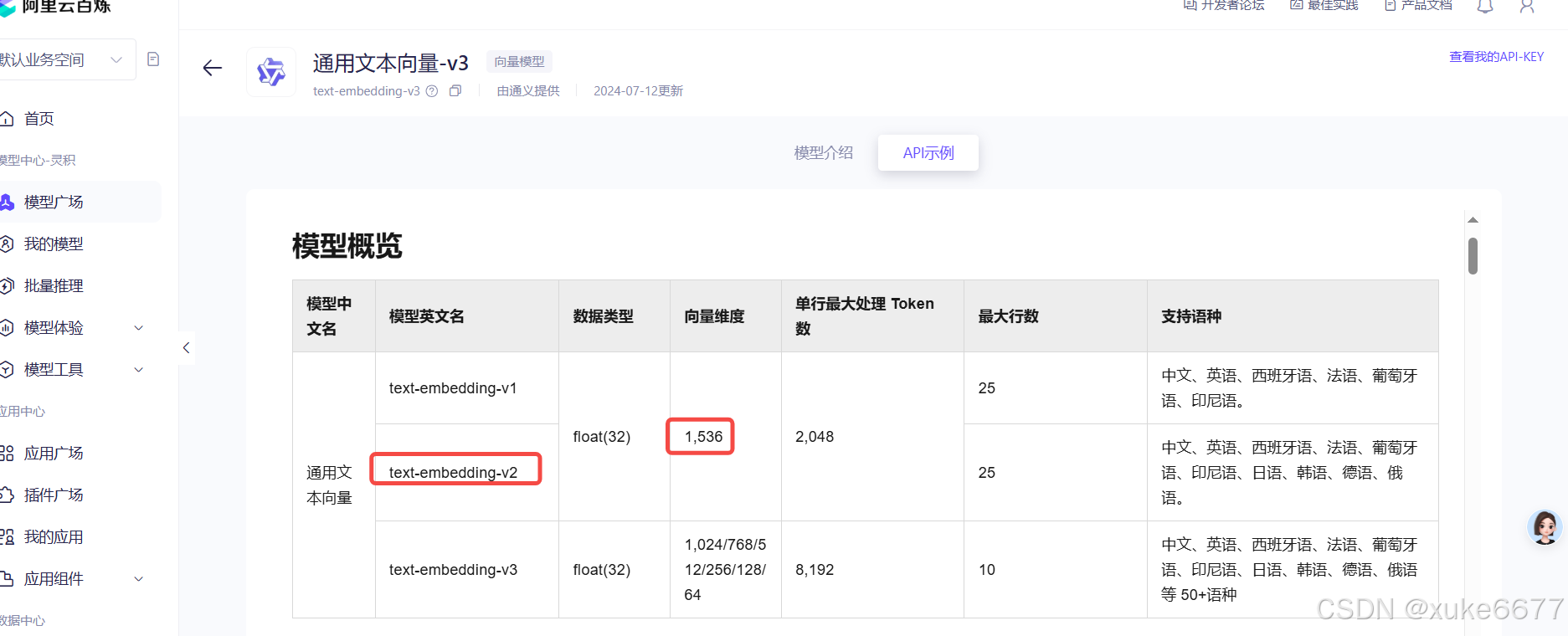
}向量维度要与API文档一致
6、创建对话助手
package com.lc.langChain4j.service;
public interface Assistant {
String chat(String message);
}
7、通过AiService创建代理对象
package com.lc.langChain4j.config;
import com.lc.langChain4j.service.Assistant;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.store.embedding.EmbeddingStore;
import lombok.RequiredArgsConstructor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@RequiredArgsConstructor
public class AssistantConfig {
final ChatLanguageModel chatLanguageModel;
@Bean
public Assistant assistant(EmbeddingStore<TextSegment> embeddingStore) {
return AiServices.builder(Assistant.class)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(15))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.chatLanguageModel(chatLanguageModel)
.build();
}
}8、RagController
package com.lc.langChain4j.controller;
import com.lc.langChain4j.service.Assistant;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.loader.ClassPathDocumentLoader;
import dev.langchain4j.data.document.loader.FileSystemDocumentLoader;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentByLineSplitter;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
@RequestMapping("/api/rag")
@RequiredArgsConstructor
public class RagController {
final EmbeddingStore<TextSegment> embeddingStore;
final EmbeddingModel embeddingModel;
/**
* 加载文件到向量数据库
*
* @return
*/
@GetMapping("/load")
public Object load() {
//Document documents = ClassPathDocumentLoader.loadDocument("documents/2025年中国房地产市场发展趋势分析.txt", new TextDocumentParser());
List<Document> documents = FileSystemDocumentLoader.loadDocuments("E:\\code\\AI\\langChain4j-demo\\demo\\target\\classes\\documents");
EmbeddingStoreIngestor.builder().embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.documentSplitter(new DocumentByLineSplitter(30, 20))
.build().ingest(documents);
return "success";
}
final Assistant assistant;
/**
* 对话
*
* @return
*/
@GetMapping("/chat")
public Object chat(@RequestParam(value = "message") String message) {
return assistant.chat(message);
}
}(1)Document Parser 文档解析器
如果要开发一个知识库系统, 这些资料可能在各种文件中, 比如word、txt、pdf、image、html等等, 所以langchain4j也提供了不同的文档解析器:
● TextDocumentParser来自 langchain4j 模块的 TextDocumentParser,它可以解析纯文本格式(e.g. TXT、HTML、MD 等)的文件。
● ApachePdfBoxDocumentParser来自langchain4j-document-parser-apache-pdfbox ,它可以解析 PDF 文件
● ApachePoiDocumentParser来自langchain4j-document-parser-apache-poi ,可以解析 MS Office 文件格式(e.g. DOC、DOCX、PPT、PPTX、XLS、XLSX 等)
● ApacheTikaDocumentParser来自 langchain4j-document-parser-apache-tika 模块中,可以自动检测和解析几乎所有现有的文件格式
(2)拆分参数:
-
maxSegmentSizeInChars : 每个文本段最大的长度
-
maxOverlapSizeInChars :两个段之间重叠的数量
(3)分隔建议:
1 过细分块的潜在问题
1 语义割裂: 破坏上下文连贯性,影响模型理解 。
2 计算成本增加:分块过细会导致向量嵌入和检索次数增多,增加时间和算力开销。
3 信息冗余与干扰:碎片化的文本块可能引入无关内容,干扰检索结果的质量,降低生成答案的准确性。
2 分块过大的弊端
1 信息丢失风险:过大的文本块可能超出嵌入模型的输入限制,导致关键信息未被有效编码。
2 检索精度下降:大块内容可能包含多主题混合,与用户查询的相关性降低,影响模型反馈效果。
9、没有加载本地文档的对话运行结果如下:
http://localhost:8081/api/rag/chat?message=2025年房地产趋势
预测2025年的房地产趋势需要考虑多个因素,包括但不限于经济状况、人口变化、政策调控以及技术进步等。虽然我无法提供确切的未来情况,但可以根据当前的趋势和已有的信息做出一些合理的推测:
1. **可持续发展与绿色建筑**:随着全球对环境保护意识的提高,预计绿色建筑、节能减排的设计理念将更加普及。使用可再生材料、提高能源效率成为新建筑项目的重要考量。
2. **智慧城市与智能家居**:科技进步推动了智慧城市的建设步伐,物联网(IoT)、人工智能(AI)等技术的应用使得住宅变得更加智能化。例如,通过手机应用程序控制家中的温度、照明甚至是安全系统已经成为可能。
3. **远程工作的影响**:自新冠疫情以来,远程办公模式被广泛接受并实践。这可能会导致人们对居住地点的选择发生变化,不再局限于大城市中心地带,而是倾向于选择更宽敞舒适且自然环境较好的郊区或乡村地区。
4. **老龄化社会的需求**:随着人口老龄化的加剧,适合老年人居住的房屋设计和服务需求将会增加。无障碍设施、健康监测系统等方面的考虑将成为重要方向之一。
5. **政府政策与市场调控**:各国政府对于房地产市场的态度及所采取的政策措施也会影响其发展趋势。比如,为了解决住房问题而推出的公共租赁房计划、首次购房者优惠政策等都可能对市场产生影响。
需要注意的是,这些只是一些基于现有条件下的分析预测,并不能完全代表实际情况。实际的发展趋势还会受到许多不可预见因素的影响。如果您想获得更准确的信息,建议关注相关行业报告以及官方发布的最新数据。10、调用文档加载接口
用于加载本地文档到向量数据库
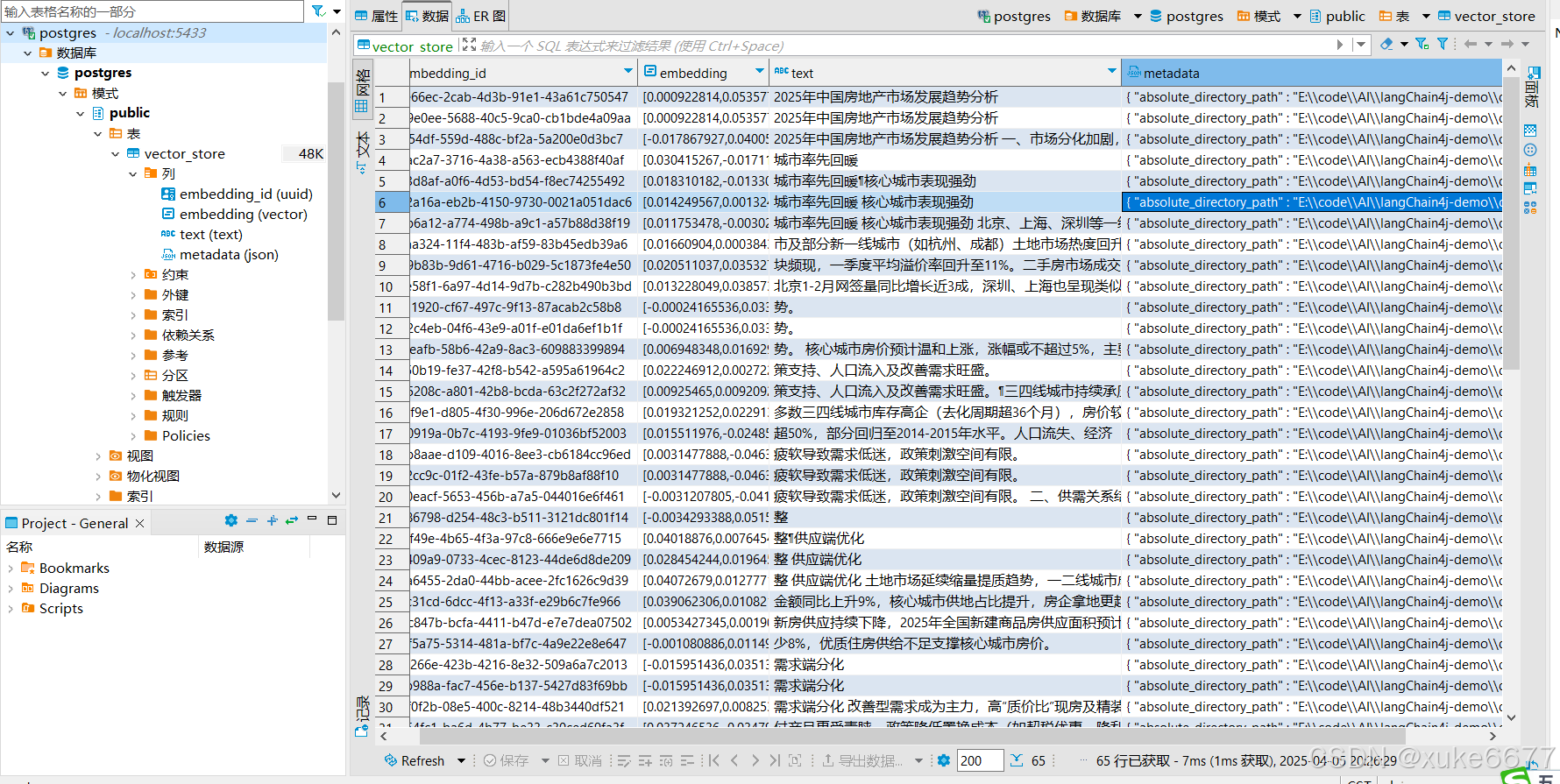
11、调用对话接口,不难发现已经基于数据库内容回答的
http://localhost:8081/api/rag/chat?message=2025年房地产趋势
基于您提供的信息,以下是对 **2025年中国房地产市场发展趋势** 的总结与分析:
---
### 一、市场分化加剧,核心城市率先回暖
1. **核心城市表现强劲**
- 北京、上海、深圳等一线城市以及部分新一线城市(如杭州、成都)将成为市场的亮点。这些城市的土地市场热度回升,高溢价地块频现,一季度平均溢价率已回升至 **11%**。
- 二手房市场成交活跃,北京1-2月网签量同比增长近 **30%**,深圳和上海也呈现类似回暖趋势。
- 核心城市房价预计温和上涨,涨幅或不超过 **5%**,主要得益于政策支持、人口流入及改善需求旺盛。
2. **三四线城市持续承压**
- 多数三四线城市库存压力巨大,去化周期超过 **36个月**,房价较峰值回落超 **50%**,部分区域房价甚至回归至 **2014-2015年水平**。
- 人口流失和经济疲软导致需求低迷,政策刺激空间有限,三四线城市的房地产市场短期内难以全面复苏。
---
### 二、供需关系结构性调整
1. **供应端优化**
- 房贷利率降至历史低位(首套平均 **4.0%**),二套房首付比例下调至 **15%**,限购政策优化释放改善需求。
- 政府通过“以存量换增量”模式收购闲置商品房,缓解库存压力,并推动“好房子”标准体系建设,提升住房质量。
2. **供给侧改革**
- “白名单”融资机制支持房企合理融资,2024年审批贷款超 **6万亿元**,保交楼覆盖 **1500万套住房**。现房销售试点扩大,占比提升至 **26.5%**。
- 新房供应持续下降,2025年全国新建商品房供应面积预计同比减少 **8%**,优质住房供给不足将支撑核心城市房价。
---
### 三、市场结构变革与风险
1. **交易模式转型**
- 现房销售占比持续提升,二手房因价格弹性更大成为市场回暖的先行指标。
- 2025年新房+二手房总成交额预计与2024年持平,但存量房交易占比将进一步扩大。
2. **风险与挑战**
- 土地市场延续缩量提质趋势,一二线城市成交金额同比上升 **9%**,核心城市供地占比提升,但房企拿地更加谨慎。
- 新房供应持续下降,优质住房供给不足将支撑核心城市房价。
3. **需求端分化**
- 改善型需求成为主力,高“质价比”现房及精装交付产品更受青睐。
- 政策降低置换成本(如契税优惠、降利率),推动“一买一卖”交易活跃。
- 城镇化率提升至 **67%**,年均 **1200万人口**流入支撑一二线城市刚性需求。
---
### 四、政策驱动市场止跌回稳
1. **需求侧支持**
- 政府继续出台宽松政策,包括降低房贷利率、优化限购限售政策、提供购房补贴等,以提振市场需求。
- 特别是针对改善型需求的支持力度加大,例如契税优惠、降低二套房首付比例等,进一步推动市场回暖。
2. **供给侧改革深化**
- 政府通过“白名单”融资机制支持优质房企发展,同时加大对问题房企的风险化解力度,确保“保交楼”任务顺利完成。
- 推动现房销售试点范围扩大,逐步改变预售制主导的市场格局,增强购房者信心。
---
### 总结与展望
2025年的中国房地产市场将呈现 **“分化、优化、转型”** 的三大特征:
1. **市场分化**:核心城市率先回暖,三四线城市持续承压,供需关系呈现明显的区域性差异。
2. **结构优化**:供应端和需求端同步调整,政府通过政策支持和供给侧改革推动市场健康发展。
3. **模式转型**:现房销售占比提升,存量房交易活跃,市场从增量开发向存量运营转变。
总体来看,2025年中国房地产市场将在政策支持下逐步止跌回稳,但恢复速度和力度将因城市能级不同而有所差异。对于购房者和投资者来说,应重点关注核心城市的机会,同时警惕三四线城市的潜在风险。
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)