Pandas 一文速通(数据分析岗必备知识)
Pandas 简介,Series,DataFrame,读取 CSV,读取 JSON,数据清洗,数据预处理,数值数据分析,时间序列分析,性能优化
PS:本篇笔记总结了 Pandas 的关键知识点,欢迎访问我的博客:Dasi’s Blog查看更多知识
0. 前言
在 python 中引用 numpy 库格式为 import pandas as pd,所以本笔记都用 pd 代替 pandas,同时省略了引入库语句
1. Pandas 简介
Pandas 一开始我以为是和熊猫有联系,或者像 Python 那样以蟒蛇命名,现在才知道原来 Pandas 指的是 “Python Data Analysis” 即 Python 数据分析。
为什么 Pandas 能够直接命名为 Python 数据分析,而不是像 NumPy 一样用 Python 数组命名,这取决于其强大的数据功能:
- 数据清洗:处理缺失数据、重复数据等
- 数据操作:支持高效的数据选择、筛选、切片,按条件提取数据、合并、连接多个数据集、数据分组、汇总统计等操作,可以进行复杂的数据变换
- 数据分析:进行统计分析、聚合、分组等
- 数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化
- 数据文件:可以轻松读写 CSV、Excel、JSON 等多种文件格式
- 数据缺失:用
pd.NA和 “NaN(Not a Number)” 表示缺失数据,而不是 None 、跳过或者报错
2. Series
2.1 创建
Series 是 Pandas 的一个核心数据结构,类似于一个一维的数组,可以存储任何数据类型(整型、浮点型、字符型、对象等),并通过索引来访问元素。
pd.Series(data=, index=, dtype=, name=)
- data:可以是列表、数组、字典等
- index:按照 data 顺序指定索引值,如果不提供会自动创建一个默认的
range(n)作为索引,其中 n 是 data 的长度 - dtype:指定数据类型,如果不提供此参数,则根据数据自动推断数据类型
- name:Series 的名称,注意不是变量名,而是一个属性值
Series 与 list 和 numpy 最大的不同之处就在于,它可以给对象命名,还可以自定义索引值,以及不同索引的数据类型可以不一样
name = 'Dasi'
indices = ['age', 'school', 'major']
values = [21, 'sysu', 'cs']
my_series = pd.Series(values, index=indices, name=name)
print(my_series)

虽然技术上可以将 Series 的数据类型设置为 object 来存放不同类型的数据,但推荐在数据分析中尽量保持 Series 的数据类型一致,以便利用 Pandas 和 NumPy 的高效运算
可以发现一个索引对应一个值,所以可以用字典的键值对进行初始化,并且还能利用索引访问值
name = 'Dasi'
my_dict = {'age': 21, 'school': 'sysu', 'major': 'cs'}
my_series = pd.Series(my_dict, name=name)
print(my_series["school"], my_series["age"])

2.2 属性
| 属性 | 功能 |
|---|---|
| index | 获取索引 |
| values | 获取数据,以 NumPy 形式返回 |
| size | 获取元素个数,即行数 |
| name | 获取名称 |
student = 'Dasi'
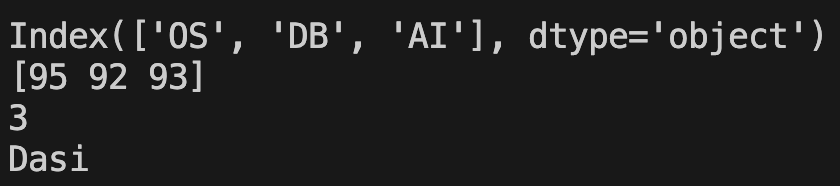
exams = ['OS', 'DB', 'AI']
scores = [95, 92, 93]
my_series = pd.Series(scores, index=exams, name=student)
print(my_series.index)
print(my_series.values)
print(my_series.size)
print(my_series.name)
2.3 有关索引的方法
| 方法 | 功能 |
|---|---|
| head(n) | 获取前 n 行 |
| tail(n) | 获取后 n 行 |
| iloc[] | 通过位置索引来选择数据 |
| loc[] | 通过标签索引来选择数据 |
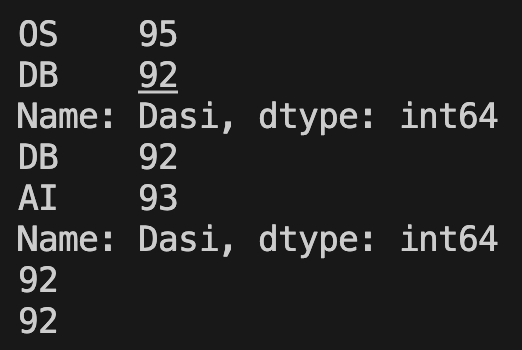
student = 'Dasi'
exams = ['OS', 'DB', 'AI']
scores = [95, 92, 93]
my_series = pd.Series(scores, index=exams, name=student)
print(my_series.head(2))
print(my_series.tail(2))
print(my_series.iloc[1])
print(my_series.loc['DB'])
2.3 有关元素的方法
| 方法 | 功能 |
|---|---|
| astype(dtype) | 将元素转换为指定类型 |
| replace(to_replace, value) | 将元素转换为指定值 |
| apply(func) 或 map(func) | 将指定函数应用于每个元素 |
| shift(periods) | 将元素向上(负数)或向下(正数)平移,超出会丢弃,空出会补 NaN |
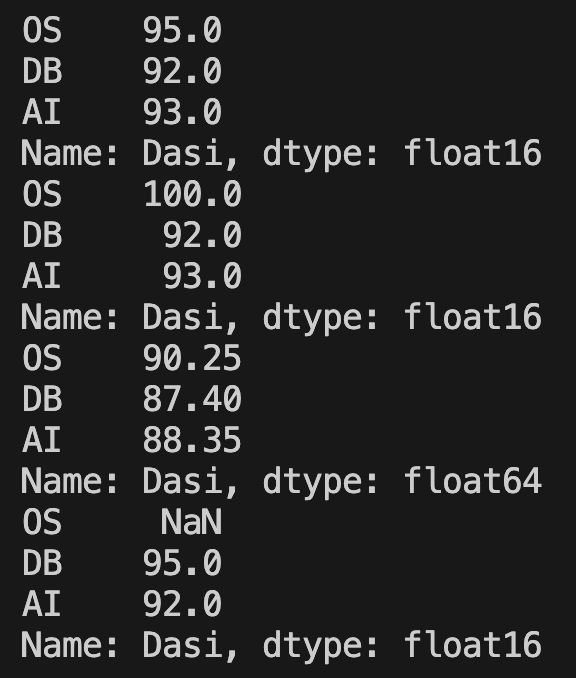
def discount(x):
return x * 0.95
student = 'Dasi'
exams = ['OS', 'DB', 'AI']
scores = [95, 92, 93]
my_series = pd.Series(scores, index=exams, name=student)
my_series = my_series.astype('float16')
print(my_series)
print(my_series.replace(95.0, 100.0))
print(my_series.map(discount))
print(my_series.shift(1))
2.4 有关 NaN 的方法
| 方法 | 功能 |
|---|---|
| dropna() | 删除 NaN 值对应的行 |
| fillna(value) | |
| isna() | 返回一个布尔 Series 表示每个索引对应的值是否为 NaN |
| notna() | 返回一个布尔 Series 表示每个索引对应的值是否为 NaN |
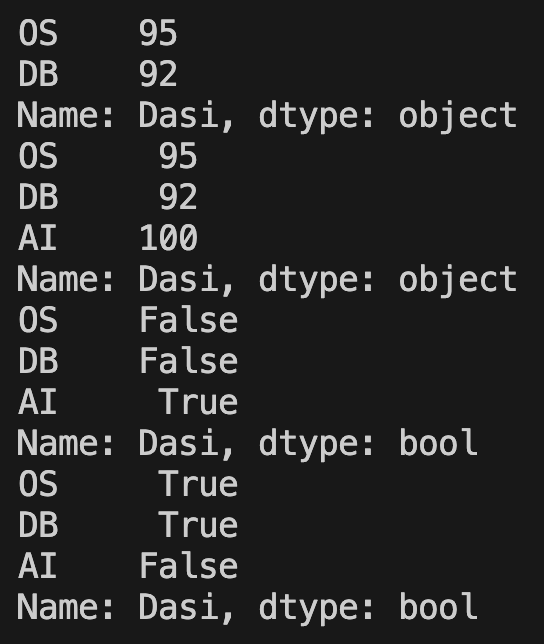
student = 'Dasi'
exams = ['OS', 'DB', 'AI']
scores = [95, 92, pd.NA]
my_series = pd.Series(scores, index=exams, name=student)
print(my_series.dropna())
print(my_series.fillna(100))
print(my_series.isna())
print(my_series.notna())
2.5 有关统计的方法
| 方法 | 功能 |
|---|---|
| unique() | 去重,返回唯一值组成的 Series |
| value_counts() | 返回每个唯一值个数组成的 Series |
| sort_values() | 对值进行排序 |
| sort_index() | 对索引进行排序 |
| rank() | 返回元素按值的排名,如果多个元素值相同,则会按照平均排名分配相同的排名值 |
| describe() | 获取统计描述 |
| corr(series) | 返回与另一个 Series 的皮尔逊相关系数 |
| cov(series) | 返回与另一个 Series 的协方差 |
| diff(periods) | 计算当前值与前一个值之间的差值 |
| cunsum() | 返回累计和 |
| cumprod() | 返回累计乘积 |
student = 'Dasi'
exams = ['OS', 'DB', 'AI']
scores = [92, 92, 95]
my_series = pd.Series(scores, index=exams, name=student)
print(my_series.value_counts())
print(my_series.rank())
print(my_series.sort_index())
print(my_series.sort_values())
print(my_series.diff(1))
print(my_series.cumsum())
print(my_series.describe())
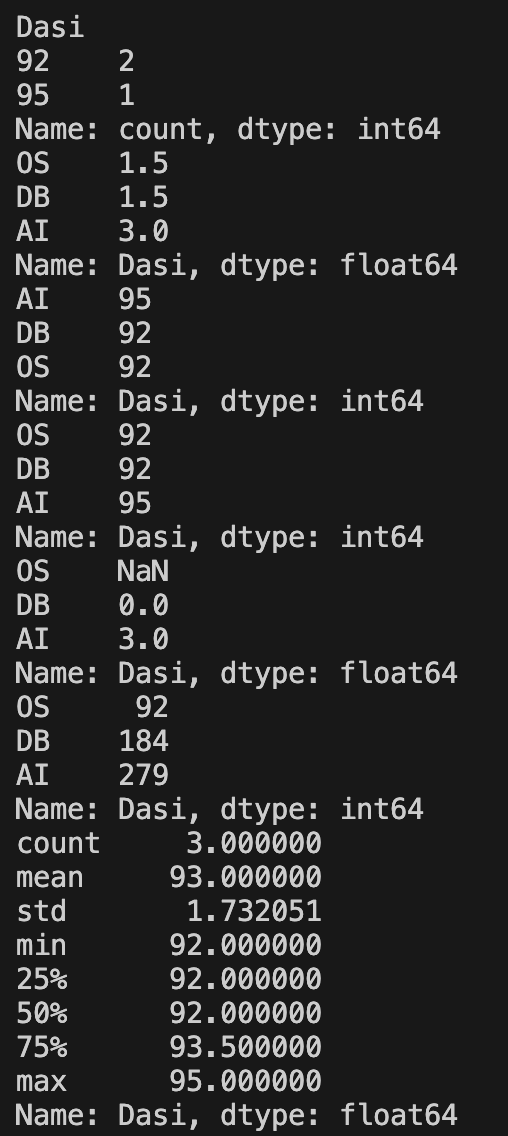
2.6 布尔索引/条件过滤
可以利用条件表达式获得布尔索引,然后利用布尔索引进行条件过滤得到满足条件的 Series
student = 'Dasi'
exams = ['OS', 'DB', 'AI']
scores = [92, 92, 95]
my_series = pd.Series(scores, index=exams, name=student)
print(my_series > 92)
print(my_series[my_series > 92])
3. DataFrame
Series 的大部分属性和方法都同样适用于 DataFrame
3.1 创建
DataFrame 是 Pandas 中的另一个核心数据结构,类似于一个二维的表格或数据库中的数据表,它含有一组有序的列,每列可以是不同的数据类型。
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典,Series 的名称作为列索引,值之间共用一个行索引
pandas.DataFrame(data=, index=, columns=)
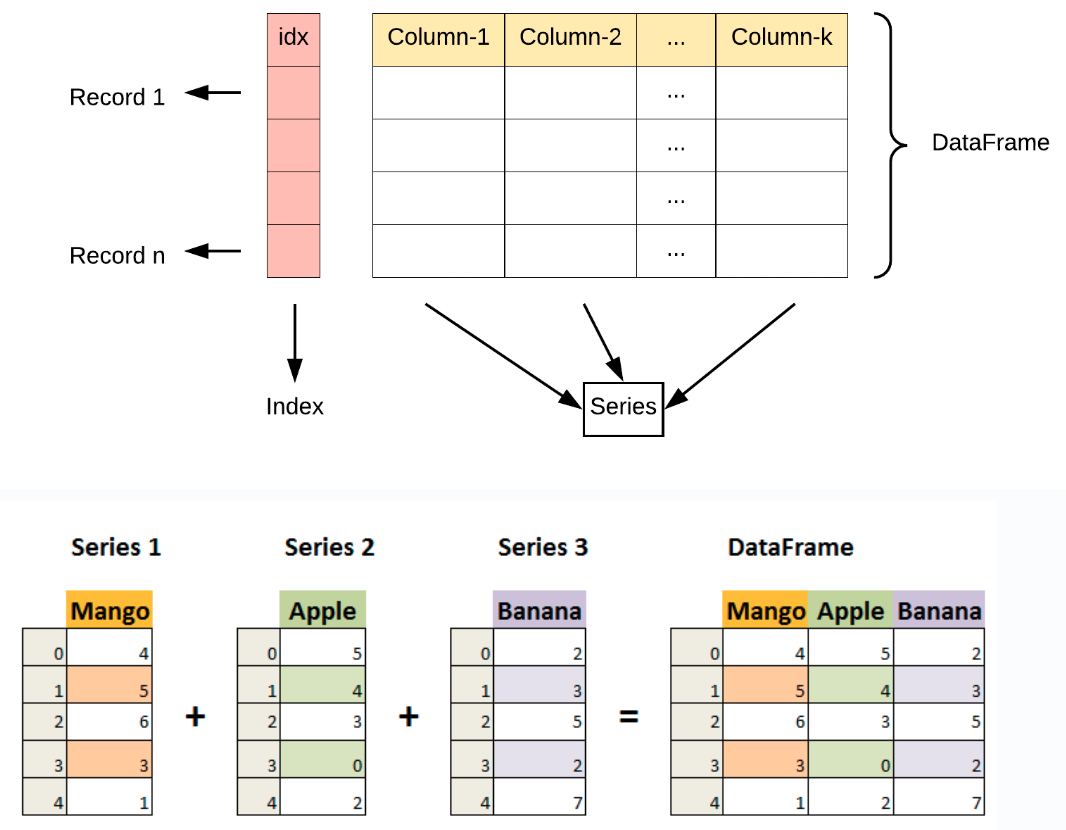
创建一个 DataFrame 有多种方式,可以用二维列表/数组、列表字典
indices = ['Dasi', 'Jason', 'wyw']
my_list = [['SYSU', 21], ['THFLS', 20], ['JJXX', 18]]
col_index = ['School', 'Age']
print(pd.DataFrame(my_list, index=indices, columns=col_index))
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [95,92,93]}
print(pd.DataFrame(my_dict, index=indices))
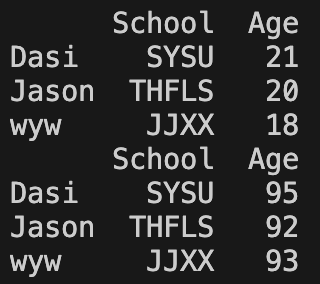
实际上每一行每一列都可以视为一个 Series:如果是某一行,Series 的名称就是当前行索引的标签,Series 的索引值就是列索引的值;如果是某一列,Series 的名称就是当前列的标签,Series 的索引值就是行索引的值
indices = ['Dasi', 'Jason', 'wyw']
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [20 ,21, 18]}
df = pd.DataFrame(my_dict, index=indices)
print(df.loc['Dasi'])
print(df['School'])
直接使用索引值获取列而不是行
3.2 属性
这里主要列举相比于 Series 多出来的属性
| 属性 | 功能 |
|---|---|
| shape | 返回元组 (行数, 列数) |
| columns | 返回所有列标签 |
| index | 返回所有行标签 |
| dtypes | 返回每一列的数据类型 |
indices = ['Dasi', 'Jason', 'wyw']
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [20 ,21, 18]}
df = pd.DataFrame(my_dict, index=indices)
print(df.shape)
print(df.columns)
print(df.index)
print(df.dtypes)
3.3 增删查改
增加列
- 直接通过给列标签赋值即可
- 使用
DataFrame.assign(name=value)方法 - 使用
DataFrame.insert(idx, name, value) - 使用
pd.merge(df1, df2, left_index=True, right_index=True)
indices = ['Dasi', 'Jason', 'wyw']
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [95,92,93]}
df = pd.DataFrame(my_dict, index=indices)
print(df)
df['Gender'] = ['Female', 'Male', 'Male']
df = df.assign(Height=[180, 160, 178])
df.insert(2, 'Weight', [88, 78, 60])
df2 = pd.DataFrame(data=['A', 'B', 'O'], columns=['Blood'], index = df.index)
df = pd.merge(df, df2, left_index=True, right_index=True)
print(df)
增加行
- 可以直接通过 loc 新标签来赋值
- 可以使用
pd.concat([df1, df2])将一个 df2 拼接在 df1 后面
indices = ['Dasi', 'Jason', 'wyw']
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [20 ,21, 18]}
df = pd.DataFrame(my_dict, index=indices)
print(df)
df.loc['Wan'] = ['MiLuo', 5]
add_df = pd.DataFrame([['GZHU', 22]], index=['Di'], columns=df.columns)
df = pd.concat([df, add_df])
print(df)
删除列:使用 DataFrame.drop(index, axis, inplace) 方法,其中 index 指定行或列的标签,axis=1 表示删除列,axis=0 表示删除行,inplace 选择是否原地修改
indices = ['Dasi', 'Jason', 'wyw']
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [20 ,21, 18]}
df = pd.DataFrame(my_dict, index=indices)
print(df)
df.drop('School', axis=1, inplace=True)
df.drop('wyw', axis=0, inplace=True)
print(df)
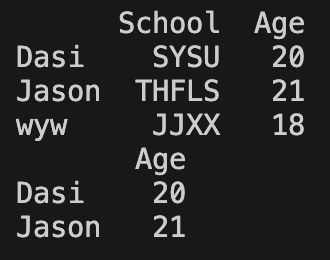
查询:除了 loc、iloc 查询,DataFrame 还支持以下两个方法
- query:用列标签对应的值的条件选择,侧重于数值查找
- filter:直接用行标签或列标签进行条件选择,侧重于名称查找
indices = ['Dasi', 'Jason', 'wyw']
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [20 ,21, 18], 'Score': [95, 88, 92]}
df = pd.DataFrame(my_dict, index=indices)
print(df.query('Age >= 20'))
print(df.filter(like='S', axis=1))
print(df.filter(regex='^.*e', axis=1))
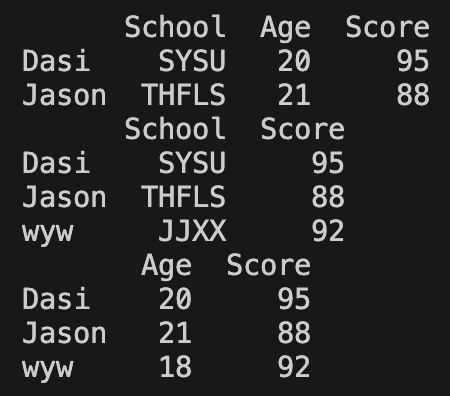
修改行或列
- 利用 loc、iloc 确定行列后直接修改
- 可以根据列标签直接修改
- apply:对元素的值进行条件修改
indices = ['Dasi', 'Jason', 'wyw']
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [20 , 21, 18], 'Score': [95, 88, 92]}
df = pd.DataFrame(my_dict, index=indices)
print(df)
df.iloc[0] = ['SYSU_', 18, 95]
df.loc['wyw', 'Age'] = 22
df['Score'] = df['Score'].apply(lambda x : x-5)
print(df)
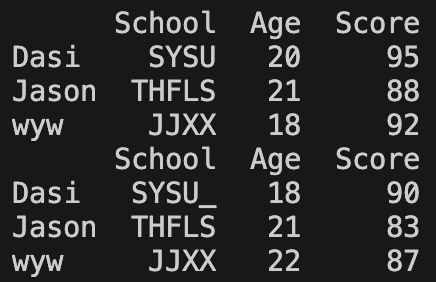
3.4 重塑
将数据表从长模式转为宽模式,即将原先的属性值作为行标签和列标签,注意返回的将会是一个 MultiIndex DataFrame
DataFrame.pivot(index, columns, values)
- index:指定列标签的值作为新的行索引
- columns:指定列标签的值作为新的列索引
- values:指定列标签的值作为每个单元格的值
将数据表从宽模式转为长模式,即将原先的属性值作为行标签和列标签
DataFrame.melt(id_vars, var_name, value_name)
- id_vars:指定不需要转换的列,即保留下来的标识列
- var_name:存放各列索引的列标签名字
- value_name:存放各单元格值的列标签名字
df = pd.DataFrame({
'date': ['2025-04-01', '2025-04-01', '2025-04-02', '2025-04-02'],
'city': ['A', 'B', 'A', 'B'],
'temperature': [20, 25, 22, 27],
'sunny': [False, True, False, True]
})
print("原始数据:")
print(df)
df_pivot = df.pivot(index='date', columns='city', values='temperature')
print("\nPivot 后的宽格式 DataFrame:")
print(df_pivot)
print("\n重置行索引后的 DataFrame:")
df_reset = df_pivot.reset_index()
print(df_reset)
df_melt = df_reset.melt(id_vars='date', var_name='city', value_name='temperature')
print("\nMelt 后的长格式 DataFrame:")
print(df_melt)
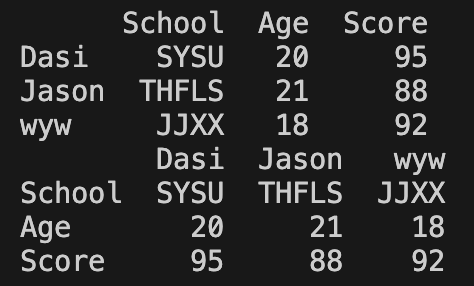
DataFrame.transpose() 和 DataFrame.T 将行和列互换
indices = ['Dasi', 'Jason', 'wyw']
my_dict = {'School': ['SYSU','THFLS','JJXX'], 'Age': [20 , 21, 18], 'Score': [95, 88, 92]}
df = pd.DataFrame(my_dict, index=indices)
print(df)
print(df.T)
4. CSV
CSV(Comma-Separated Values)即逗号分隔值,其文件以纯文本形式存储表格数据,实际应用中,pandas 经常被用来对 csv 类型的表格数据进行处理。
下面使用菜鸟教程提供的 csv 数据进行分析
4.1 read_csv
pd.read_csv(path_or_buf, sep=',', header='infer', names=None, usecols=None, dtype=None, nrows=None, skiprows=None, skipfooter=0, encoding=None, na_values=None)
| 参数 | 功能 |
|---|---|
| sep | 字段分隔符,默认是英文逗号’,’ |
| header | 指定哪一行作为列标题,默认为 0 即第一行,可以设置为 None 表示没有标题 |
| names | 传入一个列表自定义列名 |
| usecols | 指定需要读取的列,可以传入列名的列表或列索引的列表 |
| dtype | 将读取的数据转换为指定的数据类型,可以传入字典来为不同的列设置不同的数据类型 |
| nrows | 指定只读取前 n 行数据 |
| skiprows | 用于跳过文件开头的若干行数据,传入整数表示跳过前几行;也可以传入一个列表,指定需要跳过的具体行号。 |
| skipfooter | 指定跳过文件末尾的若干行 |
| encoding | 文件的编码格式,常用的有 utf-8 或 latin1 |
| na_values | 传入一个列表指定哪些值被认为是缺失值 |
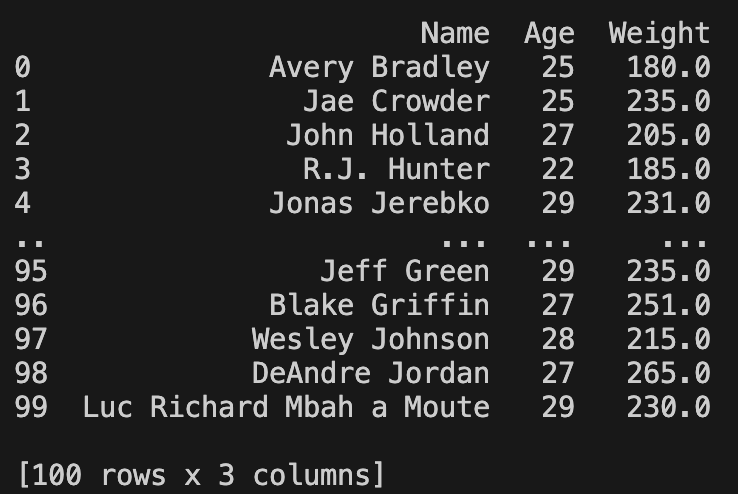
df = pd.read_csv('nba.csv', sep=',', usecols=['Name', 'Age', 'Weight'], header=0, dtype={'Age': int, 'Weight': float}, nrows=100, na_values=['NA', '--', ''], encoding='utf-8')
print(df)
4.2 to_csv
DataFrame.to_csv(path_or_buf, sep=',', columns=None, header=True, index=True, encoding=None, line_terminator=None)
| 参数 | 功能 |
|---|---|
| sep | 指定字段之间的分隔符,默认是英文逗号 , |
| index | 是否将行索引写入 CSV 文件,默认为 True |
| header | 是否将列标题写入 CSV 文件,默认为 True |
| columns | 指定要写入 CSV 文件的列的列表,若不指定则写入所有列 |
| line_terminator | 指定行结束符,默认为 \n |
| encoding | 指定输出文件的编码格式 |
除了上述之外,to_csv() 还专门提供了处理引号的参数
- quoting:决定了哪些字段会被包裹在引号中
- 0/csv.QUOTE_MINIMAL:只有当字段包含特殊字符(例如分隔符、换行符、或引号)时,才会自动加上引号
- 1/csv.QUOTE_ALL:所有字段都会被引号包裹
- 2/csv.QUOTE_NONNUMERIC:所有非数字字段都会被引号包裹
- 3/csv.QUOTE_NONE:不使用引号包裹任何字段
- quotechar:指定决定了在字段内部出现引号时,是自动重复引号(True),还是使用 escapechar 来转义
- doublequote:True 表示当字段中出现引号字符时,会使用两个连续的引号来表示一个引号
- escapechar:指定了用于转义特殊字符的字符
5. JSON
JSON(JavaScript Object Notation)即JavaScript 对象标记法,是轻量级的文本数据交换格式
下面使用菜鸟教程提供的 JSON 数据进行分析
所以我一直没搞懂 json 到底怎么念,有些人念“鸡森”,有些人念“杰森”,还有些人念“杰尚”,还是干脆直接念 J-S-O-N…
5.1 JSON 简介
在这里简要提一下 JSON 的作用和意义,它实际上是现实生活中经常接触到的文件。
JSON 按照我的理解就是嵌套键值对,当然官方说明是嵌套的对象和数组,先人给 JSON 制定了简单但极其严格的语法规范,并且极其严格地限制了可以使用的数据类型,保证了跨语言、跨平台的数据交换和存储的高效性、一致性和可读性,从而方便网络传输和机器解析。
基本数据类型
- 字符串:必须由双引号 “” 包裹,注意只能是双引号!
- 数值:可以是整数或浮点数,不需要引号
- 布尔值:只有 true 和 false 两个值
- null:表示空值或无数据
复合数据类型
- 对象:由一对大括号 {} 包裹,内部由零个或多个键值对构成,键必须是字符串,键和值之间用冒号 : 分隔,每个键值对之间用逗号 , 分隔(注意最后一个键值对不需要额外的逗号)
- 数组:由一对方括号 [] 包裹,内部包含零个或多个元素,各元素之间用逗号 , 分隔,元素可以是任意 JSON 支持的数据类型
嵌套数据类型:通常最外层表示一个实体,内层表示若干属性,数组表示属性的若干取值
{
"person": {
"name": "Dasi",
"age": 21,
"hobbies": ["reading", "cycling", "swimming"],
"address": {
"street": "4 ZhiShan SYSU",
"city": "GuangZhou"
},
"isStudent": true,
"isMarried": false
}
}
JSON 格式
| 格式 | 描述 | 结果 |
|---|---|---|
| split | 使用 index、columns 和 data 分割 | {“index”:[“a”,“b”],“columns”:[“A”,“B”],“data”:[[1,2],[3,4]]} |
| records | 每一行都是一个字典 | [{“A”:1,“B”:2},{“A”:3,“B”:4}] |
| index | 索引为键,值为字典 | {“a”:{“A”:1,“B”:2},“b”:{“A”:3,“B”:4}} |
| columns | 列名为键,值为字典 | {“A”:{“a”:1,“b”:3},“B”:{“a”:2,“b”:4}} |
| values | 只有数据 | [[1,2],[3,4]] |
5.2 read_json
pd.read_json(path_or_buf, orient=None, dtype=None, convert_axes=True, convert_dates=True, encoding=None, keep_default_na=True,)
| 参数 | 功能 |
|---|---|
| orient | 定义 JSON 数据的格式方式 |
| dtype | 指定列的数据类型 |
| convert_axes | 是否将轴转换为合适的数据类型 |
| convert_dates | 是否将日期解析为日期类型 |
| keep_default_na | 指定是否保留默认的 NA 值 |
'''
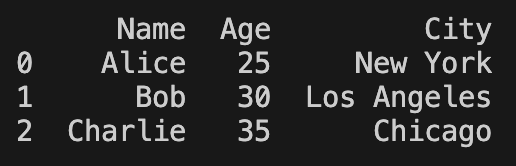
[
{"Name": "Alice", "Age": 25, "City": "New York"},
{"Name": "Bob", "Age": 30, "City": "Los Angeles"},
{"Name": "Charlie", "Age": 35, "City": "Chicago"}
]
'''
df = pd.read_json("data.json", orient='records')
print(df)
pd.json_normalize() 用于将嵌套 JSON 数据“扁平化”成一个平面表格,参数有
- record_path:指定需要展开的嵌套列表
- meta:指定嵌套列表中要保留的其他元数据字段
- errors:指定遇到不存在的字段时是
raise报错还是ignore跳过 - sep:指定元数据嵌套字段之间的分隔符,默认是 ‘.’
data = {
"school_name": "SYSU",
"info" : {
"class": "Year 1",
"president": "Dasi",
"contacts": {
"email": "example@email.com",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
df = pd.json_normalize(
data,
record_path =['students'],
meta=[
"school_name",
["info", "class"],
["info", "contacts", "tel"]
],
sep=":"
)

5.3 to_json
DataFrame.to_json(path_or_buf, orient=None, date_format=None, double_precision=10, force_ascii=True, date_unit='ms', default_handler=None)
| 参数 | 说明 |
|---|---|
| orient | 指定生成的 JSON 数据的结构方式 |
| default_handler | 提供一个处理函数,将这些对象转换为可序列化的格式 |
| lines | 布尔值,只适用于 records 格式,将每个 DataFrame 行生成一行 JSON 文本 |
| encoding | 指定输出 JSON 文件的编码格式 |
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
})
df.to_json('data.json', orient='records', lines=True)
'''
{"Name":"Alice","Age":25,"City":"New York"},
{"Name":"Bob","Age":30,"City":"Los Angeles"},
{"Name":"Charlie","Age":35,"City":"Chicago"}
'''
每个记录独占一行,不会被包含在一个外部的数组,即最外层没有方括号 []
6. 数据清洗
6.1 缺失值处理
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
| 参数 | 说明 |
|---|---|
| axis | 0 删除行,1 删除列 |
| how | any 只要存在至少一个缺失值就删除,all 表示只有当所有值都是缺失值才删除 |
| thresh | 指定保留行或列所需的最少非缺失值数量 |
| subset | 传递列字段组成的列表,仅在这些列上检查缺失值 |
| inplace | True 直接在原 DataFrame 上修改,False 返回修改后新的 DataFrame |
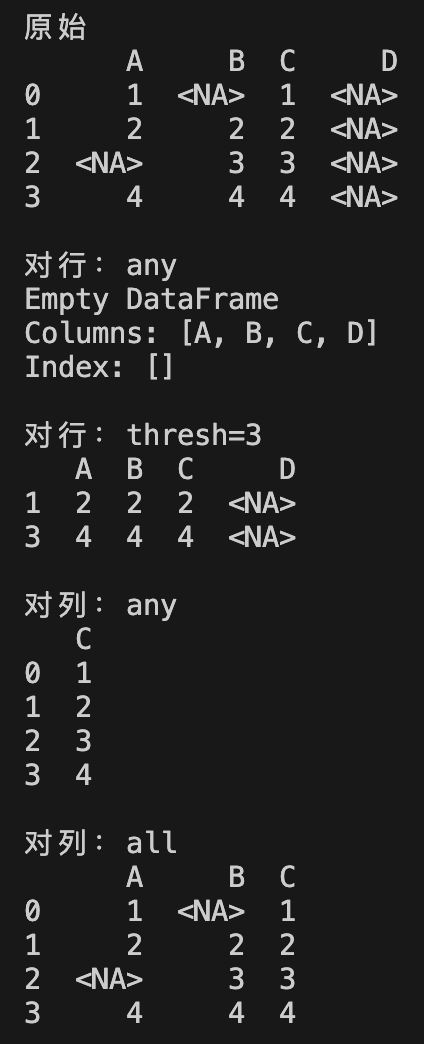
df = pd.DataFrame({
"A": [1, 2, pd.NA, 4],
"B": [pd.NA, 2, 3, 4],
"C": [1, 2, 3, 4],
"D": [pd.NA, pd.NA, pd.NA, pd.NA]
})
print("原始")
print(df)
print("\n对行:any")
print(df.dropna(axis=0, how='any'))
print("\n对行:thresh=3")
print(df.dropna(axis=0, thresh=3))
print("\n对列:any")
print(df.dropna(axis=1, how='any'))
print("\n对列:all")
print(df.dropna(axis=1, how='all'))
DataFrame.fillna(axis=0, value=None, method=None, limit=None, inplace=False)
| 参数 | 说明 |
|---|---|
| axis | 0 填充行,1 填充列 |
| value | 用来替换缺失值的值,可以是单个标量或标签为键的字典 |
| method | ffill 表示用前一个非空值填充缺失值,bfill 表示用后一个非空值填充缺失值 |
| limit | 指定最大连续填充缺失值的数量 |
| inplace | True 直接在原 DataFrame 上修改,False 返回修改后新的 DataFrame |
df = pd.DataFrame({
"A": [1, 2, pd.NA, 4],
"B": [pd.NA, 2, 3, 4],
"C": [1, 2, 3, 4],
"D": [pd.NA, pd.NA, pd.NA, pd.NA]
})
print("原始")
print(df)
print("\n填充 0")
print(df.fillna(axis=0, value=0))
print("\n每一行根据列标签填充")
print(df.fillna(axis=0, value={"A":1, "B":2, "C":3, "D":4}))
print("\n每一列向前填充")
print(df.fillna(axis=0, method="ffill"))
print("\n每一列最多填充 2 个")
print(df.fillna(axis=0, value=0, limit=2))

替换空单元格的常用方法是均值(
df.mean(axis))、中位数值(df.median(axis))或众数(df.mode(axis)),其中axis=0表示计算每一列,axis=1表示计算每一行
6.2 重复值处理
DataFrame.drop_duplicates(subset=None, keep='first', inplace='Fasle', ignore_index=False)
| 参数 | 说明 |
|---|---|
| subset | 传递列标签的列表,指定用来判定在该列上的取值是否重复 |
| keep | first 保留第一次出现的记录,last 保留最后一次出现的记录,false 不保留任何记录 |
| inplace | True 直接在原 DataFrame 上修改,False 返回修改后新的 DataFrame |
| ignore_index | True 表示从 0 开始重置索引,False 返回原来的索引 |
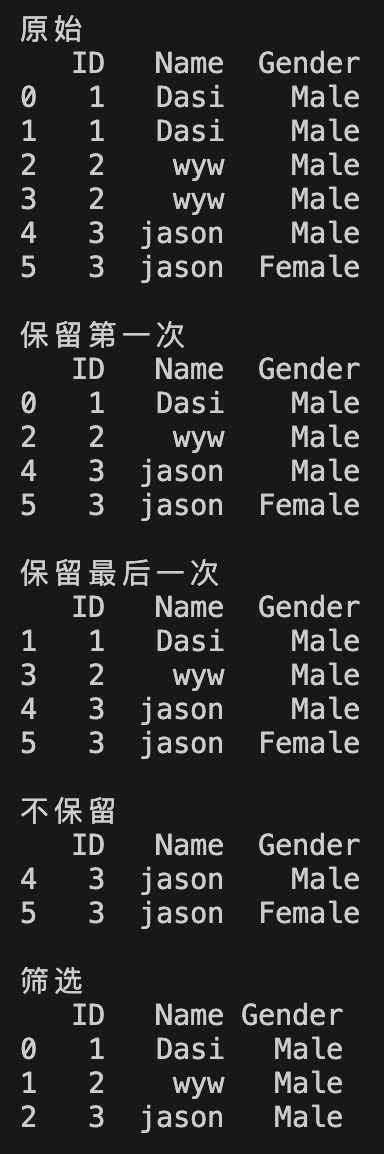
df = pd.DataFrame({
"ID": [1, 1, 2, 2, 3, 3],
"Name": ["Dasi", "Dasi", "wyw", "wyw", "jason", "jason"],
"Gender": ["Male", "Male", "Male", "Male", "Male", "Female"]
})
print("原始")
print(df)
print("\n保留第一次")
print(df.drop_duplicates(keep='first'))
print("\n保留最后一次")
print(df.drop_duplicates(keep='last'))
print("\n不保留")
print(df.drop_duplicates(keep=False))
print("\n筛选")
print(df.drop_duplicates(keep='first', subset=["ID", "Name"], ignore_index=True))
6.3 异常值处理
对于数值型数据,通常使用两种方法定义异常值
IQR = Q3 - Q1:数据的第一四分位数和第三四分位数相减得到四分位距,通常认为低于 Q1 - 1.5IQR 或高于 Q3 + 1.5IQR 的数据为异常值,可以直接利用 DataFrame.quantile(x) 获得数据的 x 分位数
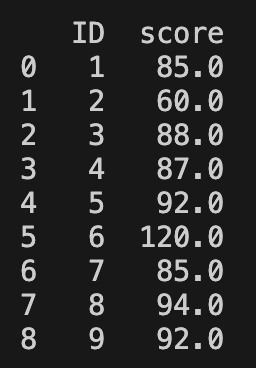
df = pd.DataFrame({
"ID": [1, 2, 3, 4, 5, 6, 7, 8, 9],
"score": [85, 60, 88, 87, 92, 120, 85, 94, 92]
})
Q1 = df['score'].quantile(0.25)
Q3 = df['score'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = (df['score'] < lower_bound) | (df['score'] > upper_bound)
Z-Score = abs((x_i - x_mean) / x_std):计算每个数据点与均值的偏离程度,大于某个阈值则认为是异常值,可以直接利用 DataFrame.mean() 和 DataFrame.std() 获取均值和标准差
df = pd.DataFrame({
"ID": [1, 2, 3, 4, 5, 6, 7, 8, 9],
"score": [85, 60, 88, 87, 92, 120, 85, 94, 92]
})
mean_val = df['score'].mean()
std_val = df['score'].std()
z_score = (df['score'] - mean_val) / std_val
outliers = abs(z_score) > 1.0
删除异常值:用取反操作 ~ 来保留正常值
df = df[~outliers]
替换异常值:选择中位数/均值/众数充当替换的值,然后利用 DataFrame.loc() 确定行列索引来赋值
df.loc[outliers, 'score'] = df['score'].median()
6.4 替换值处理
DataFrame.replace(to_replace=None, value=None, regex=False) 用于将 DataFrame 中指定的值替换为其它值,支持替换单值替换、多值替换,字典映射替换以及正则表达式替换
df = pd.DataFrame({
"Value": [0, 1, 2, 0, 4],
"Fruit": ["Banana", "Berry", "Apple", "Grape", "Bennet"]
})
print("单个值")
print(df.replace(to_replace=0, value=pd.NA))
print("\n多个值")
print(df.replace(to_replace=[0,1], value=pd.NA))
print("\n字典")
print(df.replace(to_replace={"Value": {0: pd.NA}, "Fruit": {"Berry": "Blueberry"}}))
print("\n正则表达式")
print(df.replace(to_replace=r'^B.*', value='B-fruit', regex=True))

7. 数据预处理
7.1 格式转换
数据类型转换 DataFrame.astype(dtype, copy)
- 传递单一数据类型:表示对所有元素应用
- 传递字典:键为列名,值为目标数据类型
df = pd.DataFrame({
"ID": [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0],
"score": [85, 60, 88, 87, 92, 120, 85, 94, 92]
})
df = df.astype(dtype={"ID":int, "score":float})
print(df)
日期类型转换
pd.to_datetime(data, dayfirst=False, yearfirst=False, utc=None, format=None, exact=True, unit=None)
| 参数 | 说明 |
|---|---|
| dayfirst | 布尔值,表示第一部分为日,如 DD/MM/YYYY |
| yearfirst | 布尔值,表示第一部分为年,如 YYYY/MM/DD |
| format | 指定日期字符串的解析格式,如 '%Y-%m-%d' |
| exact | 布尔值,表示严格按照 format 指定的格式解析日期 |
| utc | 布尔值,则返回带有 UTC 时区的日期时间 |
| unit | 指定该数值表示的时间单位,如 's'(秒)、'ms'(毫秒)、'us'(微秒)、'ns'(纳秒) |
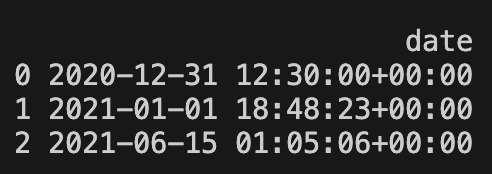
df = pd.DataFrame({
"date": ["31/2020/12 12:30:00", "01/2021/01 18:48:23", "15/2021/06 01:05:06"]
})
df["date"] = pd.to_datetime(df["date"], utc=True, format='%d/%Y/%m %H:%M:%S', exact=True)
print(df)
7.2 数值处理
数值处理的主要目的是将原始数值数据转换为便于模型或机器学习容易处理的格式,可以消除数据量级的差异
标准化(Standardization):将数据转换为均值为 0、标准差为 1 的标准高斯分布
mean_val = df["value"].mean()
std_val = df["value"].std()
df["standardized"] = (df["value"] - mean_val) / std_val
归一化(Normalization)是将数据缩放到 [0, 1] 区间内,其中最小值对应 0,最大值对应 1,其它值按比例分布
min_val = df["value"].min()
max_val = df["value"].max()
df["normalized"] = (df["value"] - min_val) / (max_val - min_val)
7.3 类别处理
标签编码:将每个唯一的类别映射到一个整数值
DataFrame.astype("category"):将类别列转换为 Pandas 的 “category” 类型DataFrame.cat.categories:获得 “category” 类型的类别列表DataFrame.cat.catcodes:获得 “category” 类型的类别编码
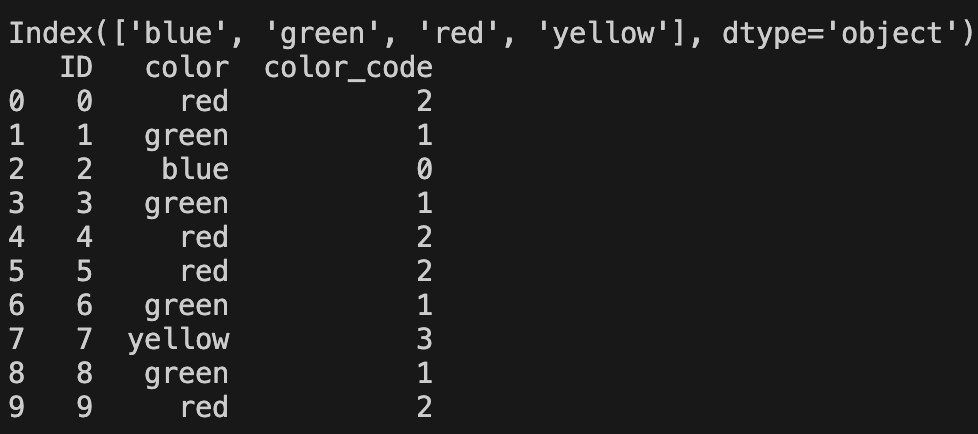
df = pd.DataFrame({
"ID": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
"color": ["red", "green", "blue", "green", "red", "red", "green", "yellow", "green", "red"]
})
color_label = df["color"].astype("category")
print(color_label.cat.categories)
df["color_code"] = color_label.cat.codes
print(df)
独热编码指的是将类别变量转换为数值变量的编码方法,如果某个样本属于该类别,则该列的值为 True/1,否则为 False/0
pd.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
| 参数 | 说明 |
|---|---|
| columns | 指定需要进行独热编码的列,否则对所有非数值型列进行编码 |
| prefix | 为独热编码的列指定前缀,默认使用原列名 |
| prefix_sep | 前缀和类别值的分隔符,默认为 ‘_’ |
| dummy_na | 布尔值,指定是否为缺失值创建一个单独的独热编码列 |
| dtype | 指定独热编码列的数据类型,通常是布尔类型或整数类型 |
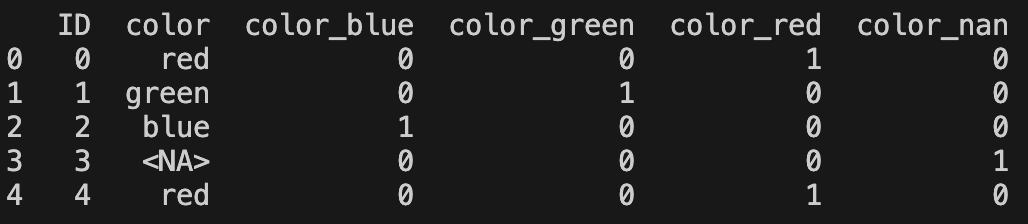
df = pd.DataFrame({
"ID": [0, 1, 2, 3, 4],
"color": ["red", "green", "blue", pd.NA, "red"]
})
df_dummies = pd.get_dummies(df["color"], prefix="color", dummy_na=True, dtype=int)
df = pd.concat([df, df_dummies], axis=1)
print(df)
7.4 数据抽样
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
| 参数 | 说明 |
|---|---|
| n | 要抽取的样本数量 |
| frac | 要抽取的样本比例 |
| axis | 0 是对行进行采样,1 是对列进行采样 |
| replace | 是否有放回抽样 |
| weights | 每个样本的抽样权重 |
| random_state | 控制随机种子,用于结果复现 |
df = pd.DataFrame({
"ID": range(10),
"Letter": list("abcdefghij")
})
print(df.sample(frac=0.4, axis=0))
print(df.sample(n=3, replace=True, axis=1))
8. 数值数据分析
8.1 排序
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
| 参数 | 说明 |
|---|---|
| by | 用于排序的列名,可以是单个列名可以是列明列表 |
| axis | 0 表示对列排序(默认),1 表示对行排序 |
| ascending | 布尔值,True 表示升序(默认),False 表示降序 |
| inplace | 布尔值,True 直接在原 DataFrame 修改,False 表示返回新对象(默认) |
| kind | 排序算法,有 quicksort(默认), mergesort, heapsort |
| ignore_index | True 表示返回结果的索引将被重置为默认的整数索引 |
| key | 传递函数,用于在排序前对值进行映射 |
df = pd.DataFrame({
"A": [3, 1, 2],
"B": [4, 8, 5],
"C": ["Banana", "apple", "Watermalon"]
})
print(df.sort_values(by="A", ascending=True))
print(df.sort_values(by="B", ascending=True))
print(df.sort_values(by="C", ascending=True, key=lambda x:x.str.lower()))

8.2 聚合
DataFrame.groupby(by).agg(func):允许你根据一个或多个键(通常为列)将数据分组,然后对每个组应用聚合函数
- by:传递列名或列名列表进行分组
- func:传递字典,指明对哪个列应用哪个聚合函数,可以是内置函数如 mean, sum, min, max, count, std 等,也可以是自定义函数
df = pd.DataFrame({
'Department': ['HR', 'Finance', 'HR', 'IT', 'IT'],
'Employee': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Gender': ['Female', 'Male', 'Female', 'Male', 'Female'],
'Salary': [50000, 60000, 55000, 70000, 75000]
})
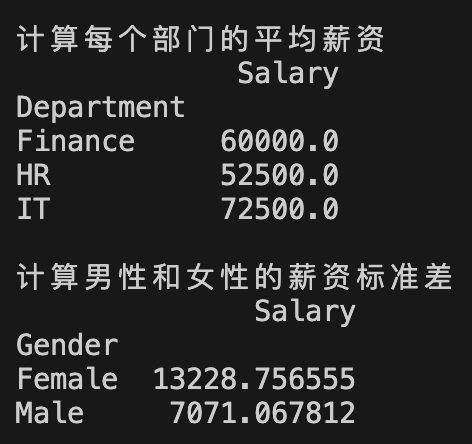
print("计算每个部门的平均薪资")
print(df.groupby('Department').agg({'Salary':'mean'}))
print("\n计算男性和女性的薪资标准差")
print(df.groupby('Gender').agg({'Salary':'std'}))
8.3 自定义操作
有时候我们不只是对分组的数据进行传统的求均值、最值等,而是按照自定义的逻辑,我们主要借助以下两个方法实现
DataFrame.apply(func):对 DataFrame 的每个分组或每一行/列应用一个函数lambda 参数: 表达式:快速定义一个匿名函数,对给定可迭代对象的每个元素应用指定的表达式
df = pd.DataFrame({
'Department': ['HR', 'Finance', 'HR', 'IT', 'IT'],
'Employee': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Gender': ['Female', 'Male', 'Female', 'Male', 'Female'],
'Salary': [50000, 60000, 55000, 70000, 75000]
})
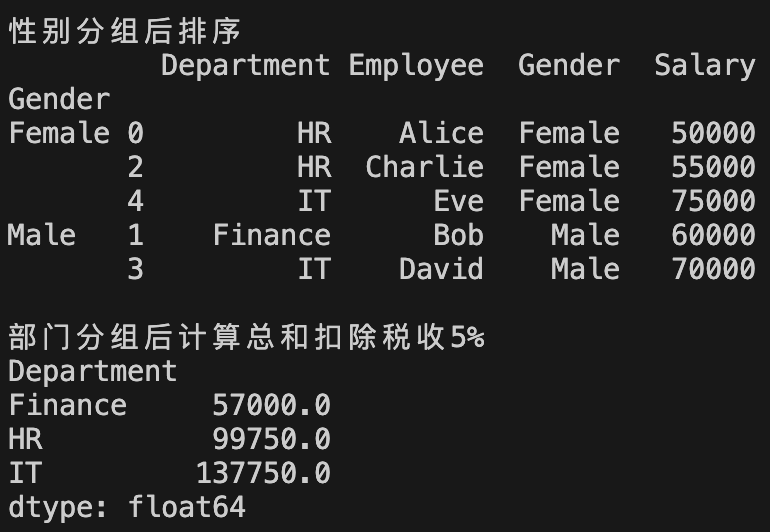
print("性别分组后排序")
print(df.groupby('Gender').apply(lambda x: x.sort_values(by="Salary")))
print("\n部门分组后计算总和扣除税收5%")
print(df.groupby('Department').apply(lambda x: x["Salary"].sum() * 0.95))
8.4 透视
透视:在数据分析中指的是将数据进行重塑,即将某些列变为行标签,某些列变为列标签,然后在行列标签每个值对应的交叉点上进行汇总,最后对这些数据进行聚合,从而快速理解数据中不同维度之间的关系和分布情况
pd.pivot_table(data, aggfunc='mean',
values=None, index=None, columns=None,
fill_value=None, dropna=True,
margins=False, margins_name='All'
)
| 参数 | 说明 |
|---|---|
| values | 需要聚合的列,可以是单个列名或列名列表,如果不指定则默认是所有数值列 |
| index | 指定作为行标签的列 |
| columns | 指定作为列标签的列 |
| aggfunc | 聚合函数或自定义函数 |
| fill_value | 聚合结果中将缺失值替换为指定的值 |
| dropna | 布尔值,True 会丢弃全部为 NaN 的列 |
| margins | 布尔值,True 则会添加一行和一列显示汇总统计 |
| margins_name | 设置汇总行和汇总列的名称 |
df = pd.DataFrame({
"Department": ["HR", "Finance", "HR", "IT", "IT", "Finance"],
"Employee": ["Alice", "Bob", "Charlie", "David", "Eve", "Frank"],
"Gender": ["Female", "Male", "Male", "Male", "Female", "Male"],
"Salary": [50000, 60000, 55000, 70000, 75000, 65000],
"Bonus": [5000, 6000, 5500, 7000, 7500, 6500]
})
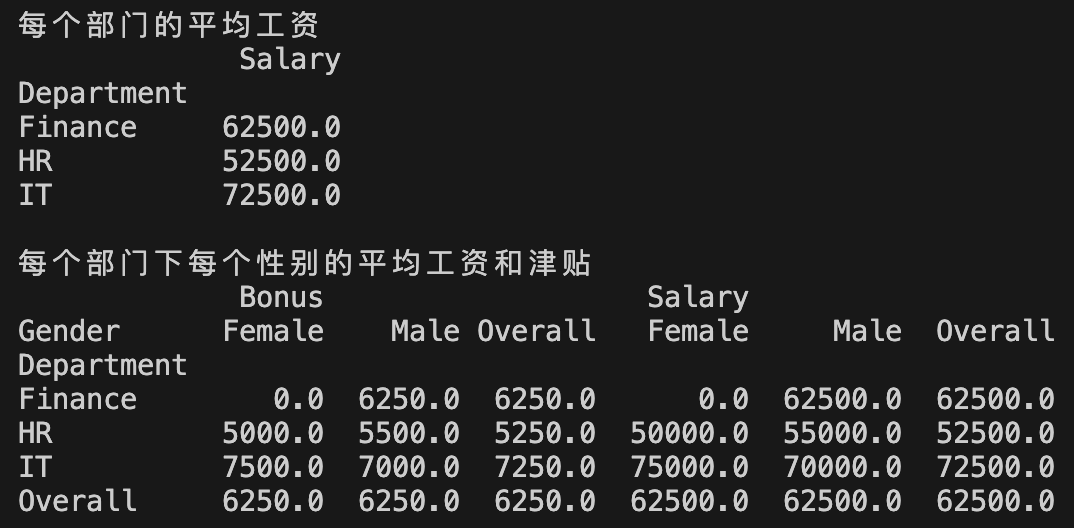
print("每个部门的平均工资")
print(pd.pivot_table(df, values="Salary", index="Department", aggfunc='mean'))
print("\n每个部门下每个性别的平均工资和津贴")
print(pd.pivot_table(df, values=["Salary", "Bonus"],
index="Department", columns="Gender",
aggfunc="mean", fill_value=0,
margins=True, margins_name="Overall"))
8.5 交叉
交叉表和透视表的参数几乎一样,但是交叉表需要指明行标签和列标签,侧重于计数统计,比如计算某两类变量各自组合的出现次数
df = pd.DataFrame({
'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Region': ['North', 'South', 'North', 'South', 'West', 'East']
})
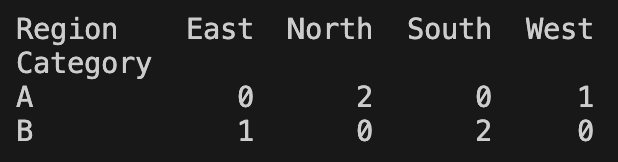
print(pd.crosstab(df['Category'], df['Region']))
9. 时间序列分析
pandas 的时间数据对象类型为 datetime64[ns],用于存储时间序列
9.1 时间频率
锚点:是时间周期对齐的“参考点”,对于不同的频率会自动对齐到下一个锚点
| 频率代码 | 含义 | 默认锚点 |
|---|---|---|
| B | 工作日 | 周一到周五 |
| D | 日历日 | 每天 |
| W | 周 | 周日 |
| W-MON~W-SUN | 星期 | 对应星期 |
| M | 月末 | 每月最后一天 |
| MS | 月初 | 每月第一天 |
| BM | 商业月末 | 每月最后一个工作日 |
| BMS | 商业月初 | 每月第一个工作日 |
| Q | 季度末 | 每年3/6/9/12月最后一天 |
| QS | 季度初 | 每年1/4/7/10月第一天 |
| BQ | 商业季度末 | 季度最后一个工作日 |
| BQS | 商业季度初 | 季度第一个工作日 |
| Y | 年末 | 每年12月31日 |
| YS | 年初 | 每年1月1日 |
| BA | 商业年末 | 每年最后一个工作日 |
| BAS | 商业年初 | 每年第一个工作日 |
| H | 小时 | 每小时整点 |
| T | 分钟 | 每分钟整点 |
| S | 秒 | 每秒钟整点 |
| L | 毫秒 | 每毫秒 |
9.2 生成时间序列
pandas.date_range(start, end=None, periods=None, freq='D', name=None, inclusive=None)
| 参数 | 功能 |
|---|---|
| start | 起始时间,字符串或 datetime 对象 |
| end | 结束时间,字符串或 datetime 对象 |
| periods | 要生成的时间点数量 |
| freq | 生成频率 |
| name | 返回的索引的名字 |
| inclusive | 是否包含起始和结束时间,可以是 ‘both’, ‘neither’, ‘left’, ‘right’ |
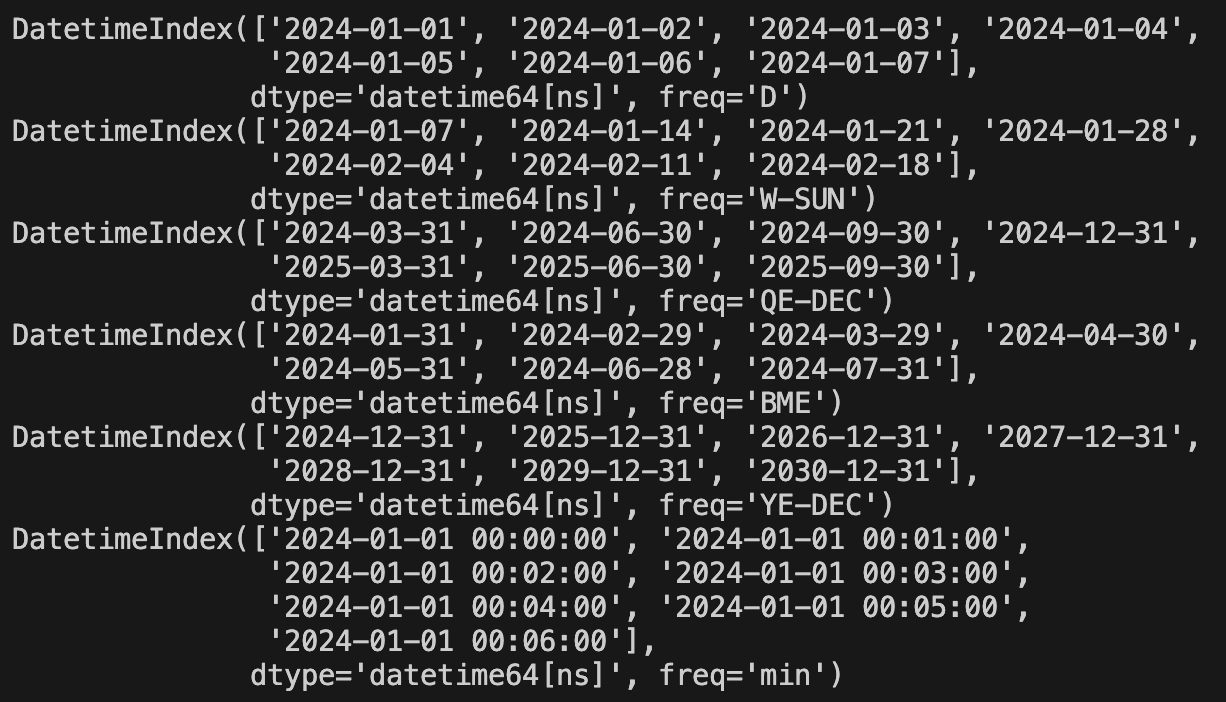
print(pd.date_range(start='2024-01-01', periods=7, freq='D'))
print(pd.date_range(start='2024-01-01', periods=7, freq='W-SUN'))
print(pd.date_range(start='2024-01-01', periods=7, freq='Q'))
print(pd.date_range(start='2024-01-01', periods=7, freq='BM'))
print(pd.date_range(start='2024-01-01', periods=7, freq='Y'))
print(pd.date_range(start='2024-01-01', periods=7, freq='T'))
9.2 转换时间序列对象
读取并利用数据文件中的日期,分为以下三步:
- 将字符串类型转换为日期时间类型
- 将日期列设置为索引,从而变成一个时间序列对象
- 通过 dt 访问器来提取日期的各个部分
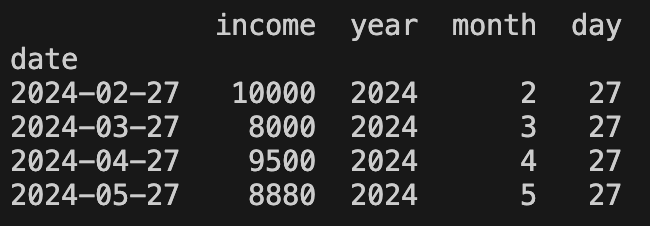
df = pd.DataFrame({
"date_str": ["2024-02-27", "2024-03-27", "2024-04-27", "2024-05-27"],
"income": [10000, 8000, 9500, 8880]
})
df['date'] = pd.to_datetime(df['date_str'])
df = df.set_index('date')
df.drop(axis=1, labels='date_str', inplace=True)
df['year'] = df.index.year
df['month'] = df.index.month
df['day'] = df.index.day
print(df)
9.3 修改频率
原始数据的频率可能是每天,每周的,因此当我们需要对其他频率的时间进行分析时,就需要修改频率,主要有以下两个方法
asfreq(freq):直接改变时间序列的频率而不进行聚合resample(rule):根据指定的时间频率将时间序列数据进行重采样,并配合聚合函数实现数据的降采样或上采样,最后得到聚合结果组成的时间序列对象
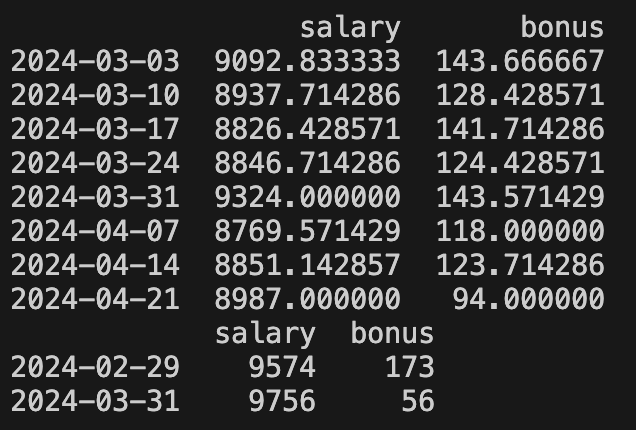
df_index = pd.date_range(start='2024-02-27', periods=50, freq='D')
df = pd.DataFrame({
'salary': np.random.randint(8000, 10000, 50),
'bonus': np.random.randint(50, 200, 50)
}, index=df_index)
print(df.resample(rule='W').mean())
print(df.asfreq(freq='M'))
 ### 9.4 时序偏移
### 9.4 时序偏移
DataFrame.shift(periods=1, freq=None, axis=0, fill_value=None)
| 参数 | 功能 |
|---|---|
| periods | 根据给定的整数移动数据 |
| freq | 根据给定的时间频率移动索引 |
| axis | 0 表示遍历列,1 表示遍历行 |
| fill_value | 指定缺失位置填充的值 |
df_index = pd.date_range(start='2024-02-27', periods=50, freq='D')
df = pd.DataFrame({
'salary': np.random.randint(8000, 10000, 50),
'bonus': np.random.randint(50, 200, 50)
}, index=df_index)
df_sample = df.resample(rule='W').mean()
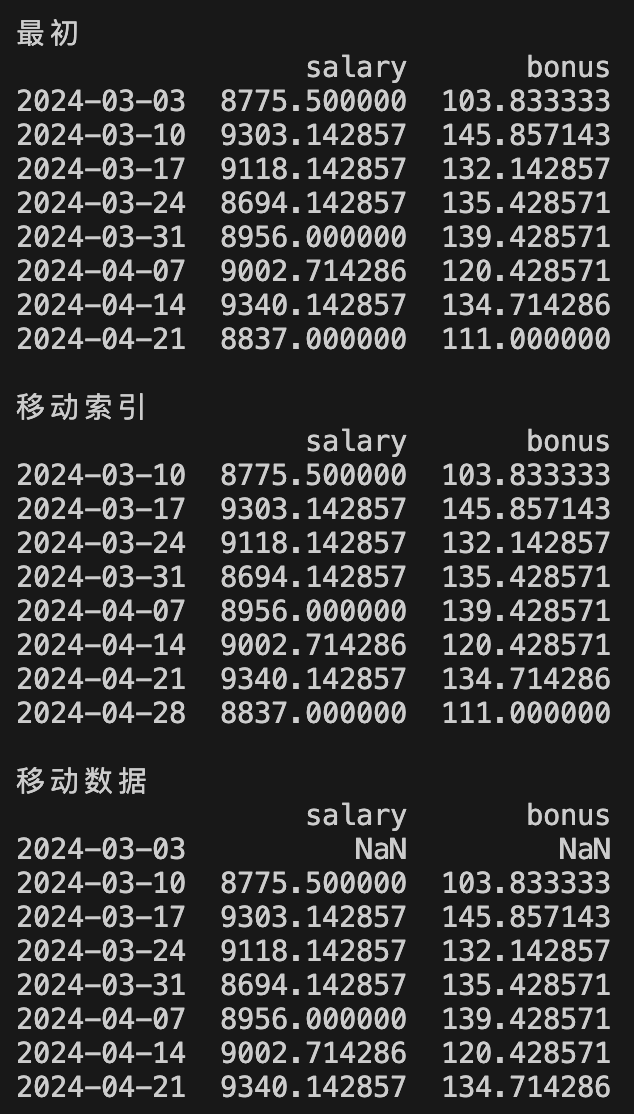
print("\n最初")
print(df_sample)
print("\n移动索引")
print(df_sample.shift(freq='W'))
print("\n移动数据")
print(df_sample.shift(periods=1))
9.5 时间窗口
DataFrame.rolling(window=None, min_periods=None, step=None, center=False, on=None, axis=0, closed=None)
| 参数 | 功能 |
|---|---|
| window | 整数表示按行滑动,字符串表示按时间跨度滑动 |
| min_periods | 窗口内最小有效值数量,否则为 NaN |
| step | 窗口移动的步长,只适用于整数滑动 |
| center | 是否以当前行为中心滚动窗口 |
| on | 指定哪一列作为时间索引,默认本身的索引 |
| closed | 时间窗口边界是否闭合 |
| axis | 0 表示遍历列,1 表示遍历行 |
df_index = pd.date_range(start='2024-02-27', periods=5, freq='D')
df = pd.DataFrame({
'salary': [100, 200, 300, 400, 600]
}, index=df_index)
print(df.rolling('3D').sum())
print(df.rolling('3D',center=True).sum())
print(df.rolling(3).sum())
print(df.rolling('3D',min_periods=1).sum())
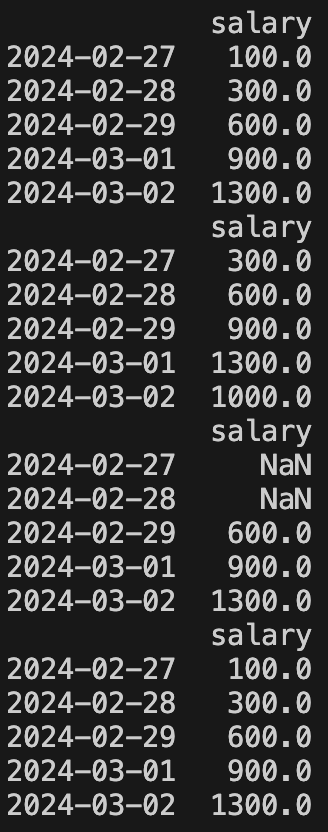
窗口默认是右对齐的,即当前索引作为窗口末尾,除非使用 center 参数,无法实现左对齐
9.6 可视化
10. 性能优化
- 使用较小的数据类型:使用
astype()转化为指定的 int16 和 float32,或者直接利用某些方法的downcast参数让系统尝试下转
df = pd.DataFrame({'A': [100, 200, 300, 400], 'B': [1000, 2000, 3000, 4000]})
df['A'] = df['A'].astype('int16')
df['B'] = df['B'].astype('int32')
- 使用 category 类型代替用作类别的字符串:系统会自动维护一个去重的类别字符串列表,category 类型在内存中存储的是整数索引,而不是字符串本身
df = pd.DataFrame({'Letter': ['A', 'B', 'A', 'C', 'B', 'A']})
df['Letter'] = df['Letter'].astype('category')
- 使用向量化操作而非循环:循环是基于 Python,而向量化操作是利用 Pandas 库底层的优化进行快速计算
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8]})
df['C'] = df['A'] + df['B']
- 使用映射而非循环:
apply()和applymap()可以在数据框架中按行或按列应用函数,能够比循环更高效
df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8]})
df['D'] = df['A'].apply(lambda x: x ** 2)
df = df.applymap(lambda x: x * 10)
- 指明合并条件,避免笛卡尔积:在处理大数据集时,可以使用 on 和 how 参数明确指定合并方式,避免不必要的计算
df1 = pd.DataFrame({'ID': [1, 2, 3], 'Value': ['A', 'B', 'C']})
df2 = pd.DataFrame({'ID': [1, 2, 3], 'Value': ['X', 'Y', 'Z']})
merged_df = pd.merge(df1, df2, on='ID', how='inner')
- 使用分块加载大数据集:Pandas 读取各类文件的函数都提供了 chunksize 参数,允许加载整个数据集时分块加载并处理,防止内存溢出
for chunk in pd.read_csv('large_file.csv', chunksize=100000):
process(chunk)
- 避免链式赋值:指的是在 Pandas 中对 DataFrame 或 Series 进行多次索引操作时,直接对中间结果进行赋值的一种操作方式
# 链式赋值
df[df['A'] > 2]['A'] = 0
# 正确赋值
df.loc[df['A'] > 2, 'A'] = 0

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)