李沐《动手学深度学习》第7章 - 卷积神经网络
✅ 参数大幅压缩(从十亿级降到千级)✅ 自然具备平移不变性✅ 通过局部性减少过拟合✅ 更深层可实现全图感知✅ 通道机制可提取多种特征✅ 训练更高效,泛化能力更强。

📘 李沐《动手学深度学习》第7章 - 卷积神经网络
🧠 7.1 从全连接层到卷积 | 为什么 CNN 是图像识别的天然结构
“你永远无法用锤子拧螺丝。用错工具,是深度学习效率低下的根源。”
—— 徐策
一、引子:MLP 能处理图像吗?
在前面的章节中,我们使用了多层感知机(MLP)解决分类任务。这种模型结构设计用于处理表格数据,每个特征相互独立,没有空间结构。
但图像是不同的。
以一张 1MP(100万像素)的猫狗图像为例:
-
输入维度:1000000
-
若隐藏层仅设置为 1000 个神经元
-
则参数数量:$1000000 \times 1000 = 10^9$(十亿)
❗ 问题来了:
-
模型庞大,训练耗资源
-
容易过拟合
-
不具备“位置不敏感”能力(例如,猫脸在左下角和右上角的处理完全不同)
二、三大原则构建 CNN
为解决这些问题,我们希望网络具备以下“归纳偏好(Inductive Bias)”:
🔁 1. 平移不变性(Translation Invariance)
物体出现在图像的哪个位置,不应影响它的被识别结果。
CNN 通过滑动同一个卷积核,在整张图像中提取相同类型的特征,实现了权重共享,自然具备平移不变性。
📍 2. 局部感受野(Locality)
图像特征(比如猫的眼睛)通常由邻近像素决定,我们不需要每次都看整张图。
CNN 的每个神经元只连接局部区域(比如 3×3 或 5×5),实现参数显著压缩,同时保留关键特征。
🧱 3. 层级结构(从局部到全局)
尽管底层卷积感知范围小,但随着层数加深,神经元的感受野逐渐扩大,最终能够整合全图信息。
这使得 CNN 既可以捕捉局部纹理,也能识别整体轮廓。
三、从全连接到卷积的数学演化
✅ 原始全连接层:
假设输入是二维图像,MLP 中每个隐藏神经元都连接所有输入像素:
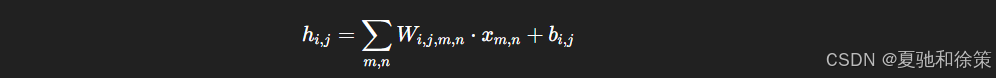
参数数量庞大,且对位置信息极其敏感。
✅ 权重共享后:
我们使用同一套卷积核参数 $w_{m,n}$:
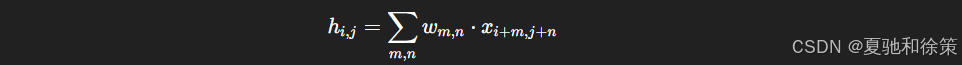
这就是卷积的雏形,具有平移不变性。
✅ 再加入局部性假设:
限制卷积核尺寸为 3×3 或 5×5,小范围感受野:
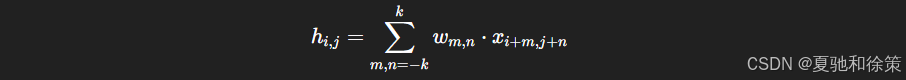
参数大幅减少,训练效率提升。
四、通道机制(Channels)
真实图像不仅有空间结构,还有颜色通道(如 RGB)。输入实际上是一个三阶张量:
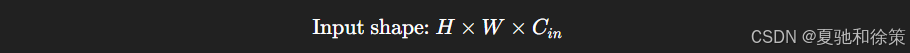
卷积核的尺寸也随之变成:
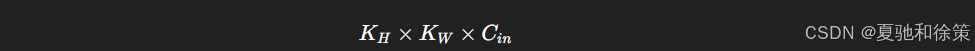
输出可以有多个通道(称为 feature maps),输出形状为:

每一个输出通道提取一种图像特征,例如边缘、角点、纹理等。
五、卷积 vs 互相关
严格数学定义中,卷积包含核的翻转:
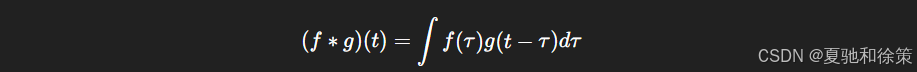
但在深度学习中,实际使用的是互相关:
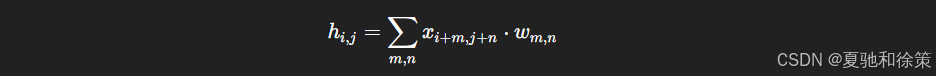
虽然没有翻转,但效果一致,因此大家仍称之为卷积。
六、CNN 的好处总结
✅ 参数大幅压缩(从十亿级降到千级)
✅ 自然具备平移不变性
✅ 通过局部性减少过拟合
✅ 更深层可实现全图感知
✅ 通道机制可提取多种特征
✅ 训练更高效,泛化能力更强
七、思考与拓展
-
🤔 音频数据中卷积是否适用? 是的,常用于频谱图(1D 卷积 or 2D 卷积)
-
🤔 文本数据是否适合卷积? 部分场景(如情感分类)可用 CNN,但现在更多采用 Transformer
-
🤔 翻译不变性是否始终有效? 不一定,比如在图像风格迁移中,位置是关键信息
八、小结
卷积神经网络不是凭空而来的发明,而是从 MLP 出发,在追求参数效率和泛化能力中自然演化出来的结构。
它正是通过引入 平移不变性 + 局部感受野 + 通道机制 三大原则,实现了对图像结构的高效建模。
“深度学习的本质,就是将问题的结构注入网络。”
—— 徐策


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)