强化学习—策略梯度算法
首先给出第一大类的metric,其实就是state value的加权平均,它是策略的函数,不同的策略对应的它的值也不同,所以我们就可以去优化,找到一个最优的策略,使其最大。下面可以把它写成更简洁的两个向量的内积,后面在求解梯度的时候有用:那么接下来我们来看一下如何选择 d(s),这里要分两种情况,第一种就是d(s) 和 Π是没有关系的,相互独立,这种比较简单,第二种就是d(s) 依赖于Π。先来看第
1、基本思路
在值函数近似估计中,我们可以用函数来替代之前的表格来表达state value,action value。那么本文的思想类似,之前我们用表格表达策略,现在也可以用函数来表达。之前所有的内容都是value-based,以value为核心,用state value来评估策略,从本文开始是policy-based,直接建立关于策略的目标函数,通过优化这个函数就能得到最优策略。

首先我们会定义1个metric,它可以来定义什么样的策略是最优的,然后再去做优化,最简单的就是梯度上升。

用函数来表示策略,其中 和之前的w 一样,都是参数。可以提高存储和泛化能力。

表格和函数表示的区别:
①对最优策略的定义不同:

②获取一个action的概率不同:表格的话直接查,函数要用神经网络计算

③更新策略的方法不同: 表格也是直接改,函数要通过一定的规则去改变 来间接改变Π

2、 定义最优策略的Metric
2.1 Metric1 — Average state value
首先给出第一大类的metric,其实就是state value的加权平均,它是策略的函数,不同的策略对应的它的值也不同,所以我们就可以去优化,找到一个最优的策略,使其最大。

下面可以把它写成更简洁的两个向量的内积,后面在求解梯度的时候有用:

那么接下来我们来看一下如何选择 d(s),这里要分两种情况,第一种就是d(s) 和 Π是没有关系的,相互独立,这种比较简单,第二种就是d(s) 依赖于Π。先来看第一种,如果二者没有关系,那么d就不涉及到任何的梯度,所以后续在求 v 的梯度时就比较简单。

第二种就是二者有关系,d是平稳分布,根据某一策略执行,被访问的多的状态d大一点,权重大一点。

2.2 Metric 2 — average reward / average one-step reward



补充



下面的内容也要注意,在论文中经常出现 。

3、 Metrics的梯度
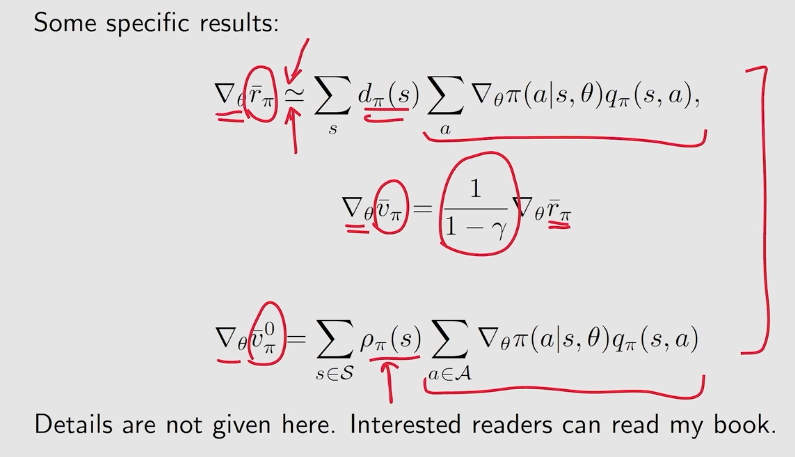
其实呢,不同的目标函数的梯度都是不同的,要考虑的情况也很多,但是它们是大同小异的,所以在这里我们给出一个统一的表达式:

具体地说,对于第一个公式,discounted case是约等于,undiscounted case是严格等于,



4、梯度上升算法(REINFORCE)
在这里给出第一个policy gradient的算法。

要估计 ,第一种是基于蒙特卡洛的算法,从(s,a)出发得到一个episode,计算return,得到g ,那么这个g实际上就是
,就用这个近似
。







腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)