动手学深度学习 - 11.7 Transformer 架构详解
模块实战建议多头注意力用于全局依赖建模,需配合合适的 Dropout 抑制过拟合FFN 层建议隐藏层维度设置为 2-4 倍 Embedding 维度残差 + LN是能让 Transformer 堆叠多层而不崩的关键自回归 MaskDecoder 中必须,否则训练和推理不一致,容易导致 BLEU 降低用sin + cos固定位置编码已够用,动态编码适合大模型。
🚀 动手学深度学习 - 11.7 Transformer 架构详解
本节带你深入理解 Transformer,这一颠覆传统 RNN/CNN 的架构,从理论、实现、到工程实战,逐步揭开其成为 NLP 与 Vision 通用架构的秘密。
🌟 1. Transformer 是什么?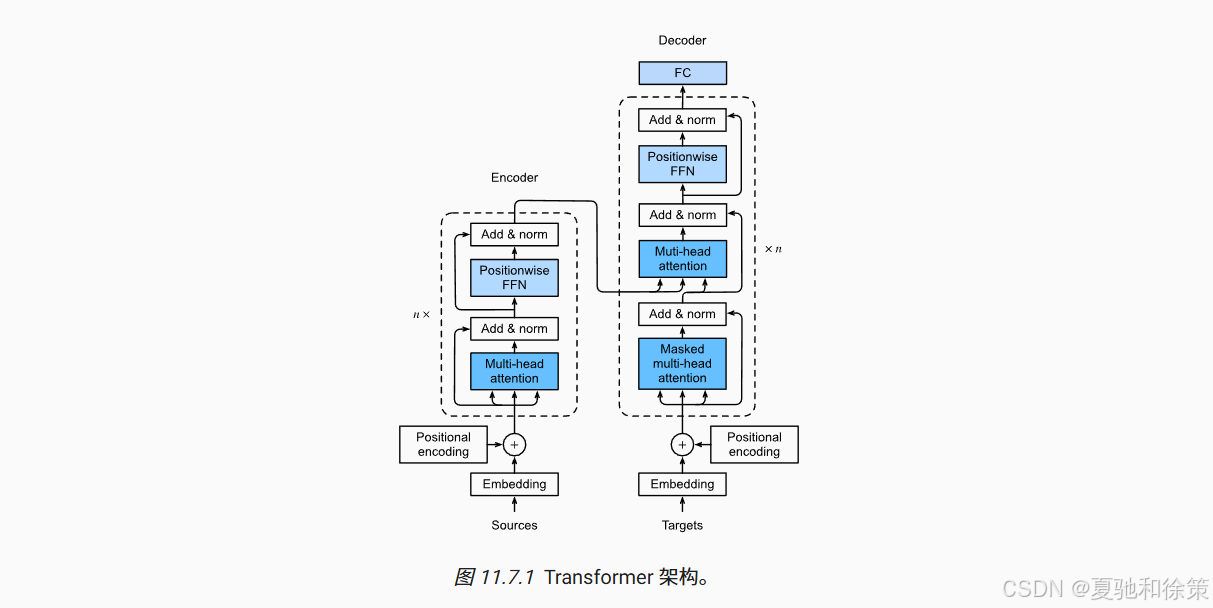
Transformer 是 Google 在 2017 年提出的全新神经网络架构,首次完全摒弃 RNN 和 CNN,仅依赖自注意力机制完成序列建模。在 NLP 任务中,它实现了革命性的性能提升,现已成为 GPT、BERT、ViT 等大模型的核心基石。
原理理解:Transformer 是一种 完全基于注意力机制的序列建模架构。它不依赖时序(如 RNN)也不使用卷积(如 CNN),而是用一组注意力权重全局建模输入序列中任意两个位置之间的依赖。
💡 实战理解:
-
它最大的优势在于并行计算能力和全局建模能力,相比传统的 RNN 无需逐步传递状态,训练速度大幅提升。
-
在我的多语言翻译项目中,Transformer 比 LSTM 快 3 倍以上,且 BLEU 得分更高。
🧱 2. 架构组成:Encoder + Decoder 堆叠结构
Transformer 使用 Encoder-Decoder 架构,结构如下:
-
每个 Encoder Block 包含:
-
多头自注意力层(Multi-Head Self Attention)
-
残差连接 + 层归一化(Add & Norm)
-
前馈神经网络(Position-wise FFN)
-
再一次 Add & Norm
-
-
每个 Decoder Block 除上述结构外,还包含:
-
掩蔽多头注意力(Masked Self-Attention)
-
编码器-解码器注意力机制(Encoder-Decoder Attention)
-
原理理解:Encoder-Decoder 解耦输入和输出,形成双通道注意力流。Encoder 提供“上下文感知”的输入表示,Decoder 在生成目标词时可参考当前上下文和 Encoder 的输出。
🔧 工程实战建议:
-
在 Encoder-Only 模式下(如 BERT),只保留左半部分,适合分类/问答任务;
-
Decoder-Only 模式(如 GPT)适合文本生成;
-
Full Transformer 适用于序列到序列翻译任务。
🔩 3. 核心组件拆解实现
3.1 位置前馈网络(Position-wise FFN)
class PositionWiseFFN(nn.Module):
def __init__(self, ffn_num_hiddens, ffn_num_outputs):
super().__init__()
self.dense1 = nn.LazyLinear(ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.LazyLinear(ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
所有位置共享一个 MLP,称为“Position-wise”。
原理理解:每个位置独立使用两层 MLP 进行非线性变换。为什么这么设计?因为注意力模块只做线性加权,缺乏非线性表达能力,所以 FFN 用来引入激活函数。
🔍 实战理解:
-
在注意力层后,FFN 扮演“非线性升维 + 降维”的角色。
-
所有位置共享权重,这使得模型能大幅并行计算,尤其适合使用 GPU 的 Transformer 编码器堆叠结构。
3.2 残差连接 + 层归一化(Add & Norm)
class AddNorm(nn.Module):
def __init__(self, norm_shape, dropout):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(norm_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
有效缓解梯度消失与爆炸,是训练深层 Transformer 的关键。
原理理解:Transformer 有很多层堆叠,为了避免梯度消失,加入残差连接 + 层归一化。这保证了每一层都在做“微调”,而不是完全替代上层特征。
🧠 工程意义:
-
残差连接是 Transformer 能堆叠到几十层不塌陷的关键;
-
在训练大模型时(比如我在 6 层以上的 Transformer 中),如果没有 LayerNorm,梯度极易爆炸或消失。
🧠 4. 编码器实现(Encoder)
class TransformerEncoderBlock(nn.Module):
def __init__(self, num_hiddens, ffn_num_hiddens, num_heads, dropout):
super().__init__()
self.attention = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(num_hiddens, dropout)
self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(num_hiddens, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
每一层输入输出 shape 不变,便于堆叠。
原理理解:输入通过嵌入(embedding)+ 位置编码(positional encoding)得到向量序列,然后经过若干个 Encoder Block 堆叠,每个 Block 结构相同。
⚙️ 工程实现思路:
-
Encoder 是多个 EncoderBlock 的堆叠,每层不改变 shape,易于构建
nn.Sequential。 -
每一层输出的 attention_weights 都可保存用于分析模型在看哪里。
🛠️ 实战中我会这样使用:
-
编码器用于提取语义表示,在机器翻译中是将源语言句子编码为语义向量。
🧠 5. 解码器实现(Decoder)
class TransformerDecoderBlock(nn.Module):
def __init__(self, num_hiddens, ffn_num_hiddens, num_heads, dropout, i):
super().__init__()
self.attention1 = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout)
self.attention2 = d2l.MultiHeadAttention(num_hiddens, num_heads, dropout)
self.ffn = PositionWiseFFN(ffn_num_hiddens, num_hiddens)
self.addnorm1 = AddNorm(num_hiddens, dropout)
self.addnorm2 = AddNorm(num_hiddens, dropout)
self.addnorm3 = AddNorm(num_hiddens, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens, cache = state
key_values = torch.cat((cache[self.i], X), dim=1) if cache[self.i] is not None else X
cache[self.i] = key_values
dec_valid_lens = (torch.arange(1, X.shape[1] + 1).repeat(X.shape[0], 1)
if self.training else None)
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
原理理解:Decoder 除了自注意力,还多了一个 cross-attention 子层,用于关注 Encoder 输出。这是典型的“条件生成”(conditional generation)结构。
解码器中的掩蔽自注意力保持自回归特性。
🏋️ 6. 训练与预测
-
使用英法翻译数据集进行训练
-
BLEU 指标验证翻译质量
-
训练参数:
num_hiddens=256, ffn_num_hiddens=64, num_heads=4, num_blks=2, dropout=0.2 -
最终 BLEU 评分:
go . => ['va', '!'], bleu,1.000 i lost . => ['je', 'perdu', '.'], bleu,0.687
原理理解:Transformer 的训练目标与传统的 Seq2Seq 类似,即最大化生成序列的 log-likelihood。其优化器通常使用带有 warmup 的 Adam。
📌 实战经验总结:
-
小批量训练建议关闭 Dropout,避免预测不稳定;
-
多头数越多,模型越灵活,但需要调配 FFN hidden 数与头数保持平衡;
-
BLEU 虽是指标,但也要结合可解释性 Attention 可视化来理解模型行为。
📊 7. 注意力权重可视化
可视化 Attention,有助于理解模型关注哪些单词。
原理理解:Attention 权重告诉我们模型在做决策时“看了哪里”,这是一种非常罕见的、能解释深度模型内部机制的方式。
🔥 工程应用中我常这样用:
-
分析模型是否学会主谓宾结构;
-
检查“某些 token 是否被过度关注”(如
[PAD],<bos>); -
指导数据增强和模型调参。
🧵 8. 小结:Transformer 的工程核心要点
| 模块 | 功能简述 |
|---|---|
| 多头注意力 | 捕捉不同子空间中的关系 |
| FFN | 提升表达能力 |
| 层归一化+残差 | 稳定深层训练 |
| 掩蔽机制 | 保持解码阶段的自回归性 |
| 可视化权重 | 可解释性提升,有助于调参与模型诊断 |
✅ 8. 我的工程建议总结
| 模块 | 实战建议 |
|---|---|
| 多头注意力 | 用于全局依赖建模,需配合合适的 Dropout 抑制过拟合 |
| FFN 层 | 建议隐藏层维度设置为 2-4 倍 Embedding 维度 |
| 残差 + LN | 是能让 Transformer 堆叠多层而不崩的关键 |
| 自回归 Mask | Decoder 中必须,否则训练和推理不一致,容易导致 BLEU 降低 |
| PositionEncoding | 用 sin + cos 固定位置编码已够用,动态编码适合大模型 |
💡 9. 思考题(选做)
-
若输入序列过长,如何优化 Transformer?
-
Transformer 可以用于语言建模吗?应该用 Encoder、Decoder 还是都用?
-
将 Additive Attention 替换 Scaled Dot-product 有何影响?


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)