AI全栈工程师——9 LLM应用开发工具链
1 生产级LLM应用的维护要点和平台推荐
1.1 生产级LLM应用的核心维护需求
- 监控与统计
- 访问记录:追踪API调用频率、用户行为、异常请求(如恶意攻击);
- 响应时长:监控延迟指标,确保SLA(服务等级协议)达标;
- Token用量:优化成本,避免因长文本或高频请求导致超额计费;
- 计费分析:关联Token消耗与业务价值(如每请求成本、ROI);
- Prompt调试与优化
- A/B测试:对比不同Prompt版本的效果(如输出质量、稳定性);
- 敏感词过滤:防止生成违规内容;
- 上下文优化:调整Prompt结构以提高准确性(如Few-shot Learning);
- 评估与测试
- 量化指标:如输出相关性(BLEU Score)、毒性检测(Toxicity Score);
- 人工审核:通过抽样验证AI输出的实际可用性;
- 数据集与版本管理
- 回归测试集:保存历史输入/输出数据,确保模型迭代后性能不退化;
- Prompt版本控制:类似代码的Git管理,支持快速回滚。
1.2 平台推荐
-
针对以上需求,介绍两个生产级 LLM App 维护平台:
维度 LangFuse LangSmith 定位 开源+SaaS,兼容性强(LangChain/原生API) LangChain官方套件,深度集成但封闭 部署方式 开源版可自托管;SaaS提供免费/付费方案 仅SaaS(免费+付费),企业版支持私有化 核心功能 全链路追踪、成本分析、Prompt版本管理 Prompt调试、自动化测试、数据集管理 优势 成本透明,适合中小团队或定制化需求 与LangChain生态无缝协作,企业级支持 劣势 需自行维护开源部署 依赖LangChain,灵活性较低 -
平台选择建议:
- 选LangFuse若:
- 需要开源解决方案或混合部署(如敏感数据需本地化);
- 使用非LangChain框架(如直接调用OpenAI API);
- 选LangSmith若:
- 重度依赖LangChain生态,需深度调试工具;
- 企业级需求(如审计日志、团队协作)。
- 选LangFuse若:
2 LangFuse
2.1 文档及使用
-
官方网站:Langfuse;
-
项目地址:Langfuse · GitHub;
-
API文档:Langfuse API reference;
- Python SDK:langfuse API documentation;
- JS SDK:Langfuse JS/TS SDKs;
-
通过官方云服务使用:
-
访问Organizations | Langfuse,先进行登录;
-
创建组织:
-
然后创建项目,就可以看到密钥、公钥和主机了;
LANGFUSE_SECRET_KEY="sk-lf-..." LANGFUSE_PUBLIC_KEY="pk-lf-..." LANGFUSE_HOST="https://cloud.langfuse.com" # EU 服务器 # LANGFUSE_HOST="https://us.cloud.langfuse.com" # US 服务器- EU是欧洲,US是美洲;
-
需要将这三者配置到环境变量中,或者使用env文件,或者直接在代码中显示配置,此处选择方式一;
环境变量名 说明 获取方式 LANGFUSE_PUBLIC_KEYLangFuse 公钥(客户端密钥) LangFuse 项目设置 → API Keys LANGFUSE_SECRET_KEYLangFuse 私钥(服务端密钥) LangFuse 项目设置 → API Keys LANGFUSE_HOSTLangFuse 服务器地址(如果是自托管版) 默认是 https://cloud.langfuse.com -
然后在代码中添加:
import os os.environ["LANGFUSE_PUBLIC_KEY"] = "LANGFUSE_PUBLIC_KEY" os.environ["LANGFUSE_SECRET_KEY"] = "LANGFUSE_SECRET_KEY"
-
-
也可以通过 Docker 本地部署;
-
安装包:
pip install --upgrade langfuse
2.2 通过装饰器记录
2.2.1 observe装饰器
-
LangFuse 的装饰器(Decorator)主要用于简化代码,帮助开发者以更简洁的方式集成 LangFuse 的观测(Observability)和追踪(Tracing)功能。以下是它的主要用途和优势:
- 自动追踪函数调用:通过
@observe或@traceable等装饰器,可以自动记录函数的输入、输出、执行时间、错误等信息,无需手动添加日志代码; - 减少样板代码:传统手动追踪需要在函数开头和结尾插入记录逻辑,而装饰器通过注解(Annotation)自动完成,代码更干净;
- 支持异步函数:LangFuse 的装饰器通常兼容异步函数(如
async def),方便在异步框架(如 FastAPI)中使用; - 自定义元数据:可通过装饰器参数添加额外信息(如标签、用户ID等),丰富追踪数据;
- 与其他工具集成:装饰器生成的追踪数据可直接对接 LangFuse 的可视化面板,用于分析性能、调试或监控;
- 自动追踪函数调用:通过
-
例:
- 使用 阿里云通义千问(Qwen-Turbo) 模型生成一个简单的对话响应(“Hello, World!”);
- 通过 LangFuse 记录整个 LLM 调用的日志(用于监控和分析);
import os # observe:LangFuse 的装饰器,用于自动记录函数调用和 LLM 交互 # langfuse_context:LangFuse 的上下文管理器,用于手动提交日志 from langfuse.decorators import observe, langfuse_context from langchain_openai import ChatOpenAI from langchain.schema import HumanMessage os.environ["LANGFUSE_PUBLIC_KEY"] = "LANGFUSE_PUBLIC_KEY" os.environ["LANGFUSE_SECRET_KEY"] = "LANGFUSE_SECRET_KEY" # LangFuse 装饰器,自动记录该函数的:输入参数、输出结果、执行时间、内部调用的 LLM 交互细节 @observe() def run(): model = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-turbo", temperature=0 ) # 调用模型并获取响应 response = model.invoke([HumanMessage(content="对我说Hello, World!")]) return response.content # 调用 run() 函数并打印返回内容(由于有 @observe(),LangFuse 会自动记录此次调用) print(run()) # 强制提交日志 langfuse_context.flush() -
结果:
Hello, World! 😊 -
在官网应该是可以看到数据记录(不知道为啥我没有):
2.2.2 几个概念
-
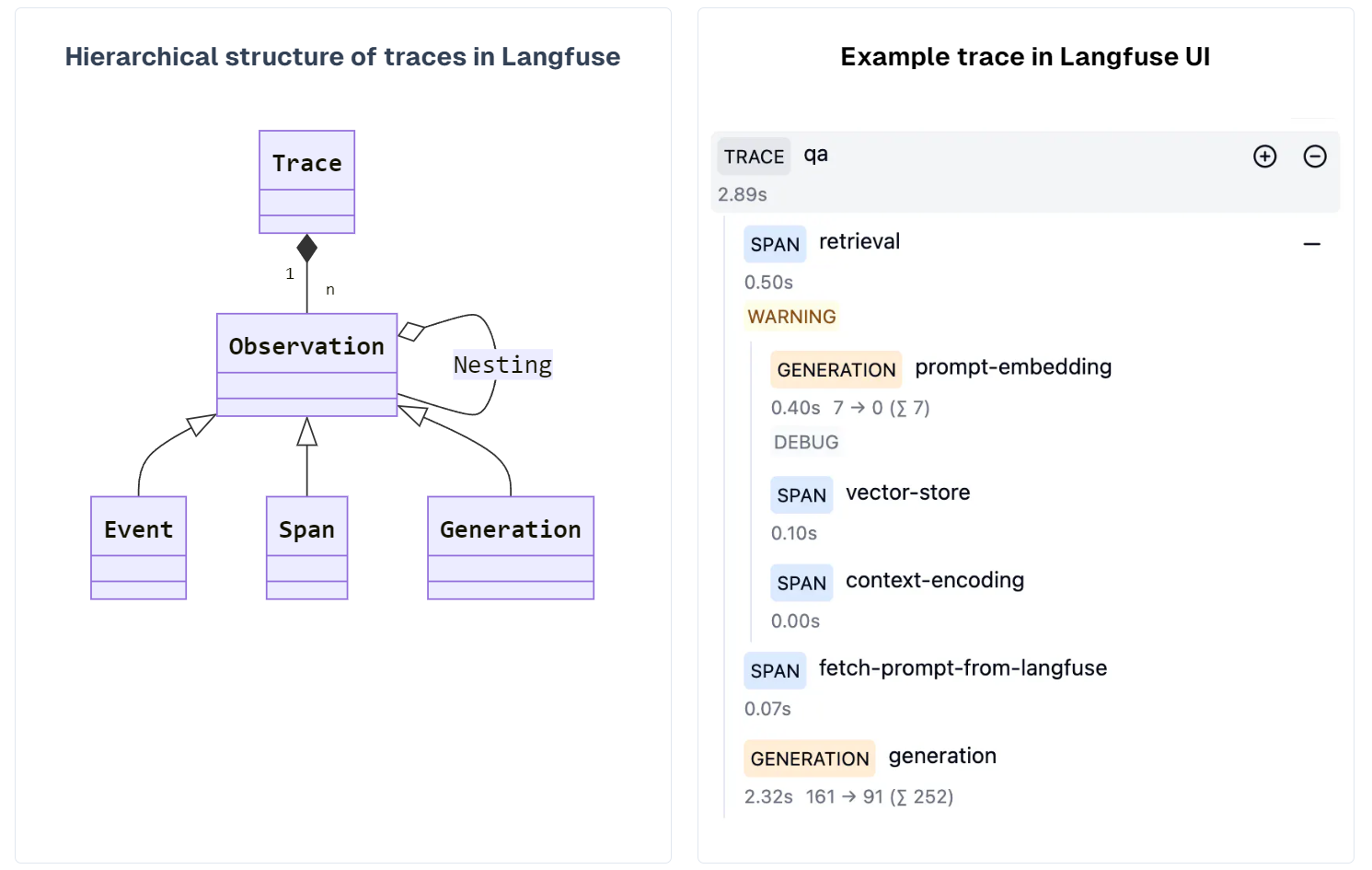
Trace:Trace 是 LangFuse 中对用户与系统一次完整交互的记录,就像一次对话或任务执行的全程日志。它不仅记录交互中的输入(比如用户提问)和输出(系统回答) ,还能添加自定义的元数据,像标识用户身份的用户名、用于跟踪会话状态的 session id 等,这些元数据能帮助后续分析和定位问题;
-
Observation:Observation 是 Trace 内部的子过程。它可以有不同类型,用来细分 Trace 中的具体操作或阶段,而且不同类型的 Observation 还能嵌套,方便更细致地结构化记录交互过程;
-
Event:Event 是最基础的记录单元,在一次 Trace 里,每一个单独的事件,例如某个按钮点击、数据开始传输等,都可以用 Event 记录。它就像搭建 Trace 这座大厦的最小砖块,用来记录交互过程中一个个离散的动作;
-
Span:Span 代表 Trace 中某个有时间消耗的过程。比如系统处理用户请求时,执行某个算法、查询数据库等操作,会花费一定时间,就可以用 Span 来记录这个过程的起止时间,从而统计出耗时,方便性能分析,查看哪些环节比较耗时,可能存在性能瓶颈;
-
Generation:Generation 是专门针对与 AI 模型交互的 Span。像调用 embedding 模型把文本转化为向量表示,或者调用大语言模型(LLM)生成文本回答等操作,都由 Generation 来记录。这在基于 AI 的应用中很关键,能追踪 AI 模型调用的具体情况,包括输入、输出以及耗时等,有助于优化与 AI 模型相关的性能和效果;
-
2.2.3 observe() 装饰器的参数
-
observe()装饰器源码:def observe( self, func: Optional[Callable[P, R]] = None, *, name: Optional[str] = None, as_type: Optional[Literal["generation"]] = None, capture_input: bool = True, capture_output: bool = True, transform_to_string: Optional[Callable[[Iterable], str]] = None, ) -> Callable[[Callable[P, R]], Callable[P, R]]: -
参数说明
func: Optional[Callable[P, R]] = None- 被装饰的目标函数(Python 装饰器标准参数);
- 类型注解
P(参数) 和R(返回值) 使用泛型保留原始函数的签名;
name: Optional[str] = None- 自定义此次观测的名称(用于 LangFuse 界面中的标识);
- 默认使用函数名(
func.__name__);
as_type: Optional[Literal["generation"]] = None- 指定记录类型,目前仅支持
"generation"(表示 LLM 生成操作); - 用于 LangFuse 分类不同类型的追踪(未来可能扩展);
- 指定记录类型,目前仅支持
capture_input: bool = True- 是否记录函数的输入参数;
- 设为
False可屏蔽敏感数据;
capture_output: bool = True- 是否记录函数的返回值;
- 设为
False可屏蔽敏感输出;
transform_to_string: Optional[Callable[[Iterable], str]] = None- 自定义输入/输出的序列化方法;
- 默认使用
str()转换,但可覆盖为 JSON 序列化等
-
返回值
- 返回一个装饰器函数:
Callable[[Callable[P, R]], Callable[P, R]] - 符合标准装饰器的类型签名(输入函数 → 包装后的函数)
- 返回一个装饰器函数:
-
例:
from langfuse.decorators import observe, langfuse_context from langchain_openai import ChatOpenAI from langchain_core.messages import HumanMessage import os os.environ["LANGFUSE_PUBLIC_KEY"] = "LANGFUSE_PUBLIC_KEY" os.environ["LANGFUSE_SECRET_KEY"] = "LANGFUSE_SECRET_KEY" @observe(name="HelloWorld") def run(): # 配置阿里云通义千问模型 model = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量获取API key base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云兼容OpenAI的接口 model="qwen-turbo", # 使用qwen-turbo模型 temperature=0 # 控制生成结果的随机性 ) # 调用模型并获取响应 response = model.invoke([HumanMessage(content="对我说Hello, World!")]) return response.content print(run()) langfuse_context.flush()@observe(name="HelloWorld")的name参数 主要用于 跟踪和标识观测的 LLM 调用,具体作用如下:- 在 Langfuse 仪表盘中显示
- 这个
name会作为该观测(Observation)的 名称 显示在 Langfuse 的 Web 仪表盘(Dashboard)中; - 例如,如果你在代码里调用了
run()多次,Langfuse 会记录每次调用,并在 UI 中显示为HelloWorld,方便你快速识别不同的观测点; - 用于日志记录和检索。在 Langfuse 的 日志系统 中,
name会作为该调用的标识符,方便你:- 搜索(如过滤
name:"HelloWorld"的观测); - 分类(比如区分不同功能的 LLM 调用);
- 分析(比如统计
HelloWorld调用的延迟、成本、错误率等);
- 搜索(如过滤
- 配合
@observe的其他参数。@observe还支持其他参数,比如:metadata(记录额外信息,如用户ID、环境变量等);input/output(显式指定输入输出,而非自动捕获);level(设置日志级别,如DEBUG、ERROR等);
- 如果没有设置
name会怎样?- 如果不指定
name,Langfuse 会默认使用 函数名(如run)作为观测名称; - 但显式设置
name更清晰,尤其是在多个函数调用相同 LLM 时,可以更好地区分它们;
- 如果不指定
-
结果:
Hello, World! 😊
2.2.4 langfuse_context
-
通过
langfuse_context记录 User ID、Metadata 等,例:from langfuse.decorators import observe, langfuse_context from langchain_core.messages import HumanMessage from langchain_openai import ChatOpenAI import os os.environ["LANGFUSE_PUBLIC_KEY"] = "LANGFUSE_PUBLIC_KEY" os.environ["LANGFUSE_SECRET_KEY"] = "LANGFUSE_SECRET_KEY" @observe() def run(): langfuse_context.update_current_trace( name="HelloWorld", user_id="shisan", tags=["test", "demo"] ) model = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量获取API key base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云兼容OpenAI的接口 model="qwen-turbo", # 使用qwen-turbo模型 temperature=0 # 控制生成结果的随机性 ) # 调用模型并获取响应 response = model.invoke([HumanMessage(content="对我说Hello, World!")]) return response.content print(run()) langfuse_context.flush() -
结果:
Hello, World! 😊
2.3 通过 LangChain 的回调集成
-
例:
import os from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate from langchain_core.output_parsers import StrOutputParser from langchain_openai import ChatOpenAI from langchain_core.runnables import RunnablePassthrough from langfuse.decorators import langfuse_context, observe os.environ["LANGFUSE_PUBLIC_KEY"] = "LANGFUSE_PUBLIC_KEY" os.environ["LANGFUSE_SECRET_KEY"] = "LANGFUSE_SECRET_KEY" model = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量获取API key base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # 阿里云兼容OpenAI的接口 model="qwen-turbo", # 使用qwen-turbo模型 temperature=0 # 控制生成结果的随机性 ) # 创建对话提示模板,定义了一个简单的人类消息模板,要求对输入的名字说 hello prompt = ChatPromptTemplate.from_messages([ HumanMessagePromptTemplate.from_template("Say hello to {input}!") ]) # 创建字符串输出解析器,用于将模型输出解析为字符串 parser = StrOutputParser() # 构建处理链 chain = ( {"input": RunnablePassthrough()} # RunnablePassthrough():传递输入不变 | prompt # 应用提示模板 | model # 调用语言模型 | parser # 解析输出为字符串 ) # 装饰器 @observe() def run(): langfuse_context.update_current_trace( name="LangChainDemo", user_id="shisan", ) # 获取当前 LangChain 回调处理器 langfuse_handler = langfuse_context.get_current_langchain_handler() return chain.invoke( input="SHISAN", # 调用之前构建的 chain,输入为 "SHISAN" config={"callbacks": [langfuse_handler]} # 在配置中传入 Langfuse 的回调处理器,以便记录交互过程 ) print(run()) # 强制刷新 Langfuse 记录,确保所有跟踪数据被发送到服务器(因为 Langfuse 默认是异步发送数据) langfuse_context.flush() -
例:
Hello, SHISAN! How can I assist you today?
2.4 构建一个实际应用
- 需求:构建一个AGI 课堂跟课助手,根据课程内容,判断学生问题是否需要老师解答;
- 判断该问题是否需要老师解答,回复’Y’或’N’;
- 判断该问题是否已有同学问过。
2.4.1 构建 PromptTemplate
-
例:
# 构建 PromptTemplate from langchain.prompts import PromptTemplate # 判断问题是否需要老师回答 need_answer = PromptTemplate.from_template(""" ********* 你是AIGC课程的助教,你的工作是从学员的课堂交流中选择出需要老师回答的问题,加以整理以交给老师回答。 课程内容: {outlines} ********* 学员输入: {user_input} ********* 如果这是一个需要老师答疑的问题,回复Y,否则回复N。 只回复Y或N,不要回复其他内容。""") # 检查问题是否重复 check_duplicated = PromptTemplate.from_template(""" ********* 已有提问列表: [ {question_list} ] ********* 新提问: {user_input} ********* 已有提问列表是否有和新提问类似的问题? 回复Y或N, Y表示有,N表示没有。 只回复Y或N,不要回复其他内容。""") # 课程内容 outlines = """ LangChain 模型 I/O 封装 模型的封装 模型的输入输出 PromptTemplate OutputParser 数据连接封装 文档加载器:Document Loaders 文档处理器 内置RAG:RetrievalQA 记忆封装:Memory 链架构:Chain/LCEL 大模型时代的软件架构:Agent ReAct SelfAskWithSearch LangServe LangChain.js """ # 已有提问列表 question_list = [ "LangChain可以商用吗", "LangChain开源吗", ]
2.4.2 创建chain
-
例:
# 创建 chain model = ChatOpenAI(temperature=0, seed=42) parser = StrOutputParser() need_answer_chain = ( need_answer | model | parser ) is_duplicated_chain = ( check_duplicated | model | parser )
2.4.3 用 Trace 记录一个多次调用 LLM 的过程
-
下面是一个TRACE结构,展示了一个分布式追踪(Distributed Tracing)的层次关系,常用于监控和分析复杂系统中的请求流程;
TRACE (id: trace_id) | |-- SPAN: LLMCain (id: generated by Langfuse) | | | |-- GENERATION: OpenAI (id: generated by Langfuse) | |-- SPAN: LLMCain (id: generated by 'next_span_id') | | | |-- GENERATION: OpenAI (id: generated by Langfuse)- TRACE (id: trace_id)
- 这是整个请求的根节点,代表一个完整的端到端事务;
trace_id是这个事务的唯一标识符,会在整个调用链中传递;
- 第一个 SPAN: LLMCain
- 表示事务中的第一个主要操作段;
- 这里的"LLMCain"可能是某个大语言模型服务的名称;
- 这个SPAN有一个由Langfuse自动生成的ID;
- 包含的子节点:
- GENERATION: OpenAI
- 表示在这个SPAN中调用了OpenAI的生成操作;
- ID也是由Langfuse自动生成;
- GENERATION: OpenAI
- 第二个 SPAN: LLMCain
- 表示事务中的第二个主要操作段;
- 可能是对同一个LLM服务的另一次调用;
- 这个SPAN的ID是通过’next_span_id’机制生成的(可能是某种序列化ID生成方式);
- 包含的子节点:
- 另一个 GENERATION: OpenAI
- 表示在这个SPAN中又进行了一次OpenAI生成操作;
- 另一个 GENERATION: OpenAI
- TRACE (id: trace_id)
-
这种结构通常用于:
- 分析请求在不同服务间的流转;
- 计算每个环节的耗时;
- 诊断性能瓶颈;
- 追踪AI生成内容的调用链;
-
每个SPAN代表一个独立的工作单元,而GENERATION代表具体的AI生成操作。这种层级关系可以帮助开发者理解复杂系统中各个组件的交互情况;
-
例:通过代码演示 trace 和 span 的概念
from langfuse.decorators import langfuse_context, observe # 主流程 @observe() def verify_question(question: str, outlines: str, question_list: list, user_id: str) -> bool: # 设置当前追踪的元数据 langfuse_context.update_current_trace( name="AGIClassAssistant", # 命名 user_id=user_id, # 关联用户ID ) # 获取Langfuse的回调处理器,用于后续链的调用追踪 langfuse_handler = langfuse_context.get_current_langchain_handler() # 调用第一个链判断是否需要回答 need_answer_result = need_answer_chain.invoke( {"user_input": question, "outlines": outlines}, config={"callbacks": [langfuse_handler]} ) print(f"是否需要回答: {need_answer_result}") # 如果是需要回答的问题,再检查是否重复 if need_answer_result == 'Y': is_duplicated_result = is_duplicated_chain.invoke( {"user_input": question, "question_list": "\n".join(question_list)}, config={"callbacks": [langfuse_handler]} ) print(f"是否重复: {is_duplicated_result}") # 如果不是重复问题,加入问题列表并返回True if is_duplicated_result == 'N': question_list.append(question) return True return False # 实际调用 ret = verify_question( # "LangChain支持Java吗", "LangChain有商用许可吗", # "老师好", outlines, question_list, user_id="shisan", ) print(ret) langfuse_context.flush() -
结果:
是否需要回答: Y 是否重复: Y False -
实际上下面的实现方式更优:
- 将上面的
通过代码演示 trace 和 span 的概念的例子和已有提问列表注释;
from langfuse.decorators import langfuse_context, observe import numpy as np from openai import OpenAI cache = {} # Embedding生成模块:将文本转换为1024维向量 @observe(as_type="generation") # as_type参数用于指定记录类型,目前仅支持"generation"(表示 LLM 生成操作),用于 LangFuse 分类不同类型的追踪 def get_embeddings(text): # 检查缓存 if text in cache: return cache[text] client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) # 调用国产embedding模型 response = client.embeddings.create( model="text-embedding-v3", input=[text], dimensions=1024, encoding_format="float" ) # 提取embedding并缓存 embedding = response.data[0].embedding cache[text] = embedding # 记录模型调用元数据(可选) langfuse_context.update_current_observation( model="text-embedding-v3", model_parameters={ "dimensions": 1024, "encoding_format": "float" } ) return embedding # 计算余弦相似度 @observe() def cos_sim(v, m): '''计算输入向量v与矩阵m中每个向量的余弦相似度''' score = np.dot(m, v) / (np.linalg.norm(m, axis=1) * np.linalg.norm(v)) return score.tolist() # 通过cosine相似度阈值判断是否重复 @observe() def check_duplicated(query, existing, threshold=0.825): # 阈值选择:0.825是经验值,需根据实际场景调整 query_vec = np.array(get_embeddings(query)) # 获取查询文本的embedding mat = np.array([item[1] for item in existing]) # 已有问题的embedding矩阵 cos = cos_sim(query_vec, mat) return max(cos) >= threshold # 判断最高相似度是否超阈值 # 判断是否需要回答 @observe() def need_answer(question, outlines): # 获取Langfuse的回调处理器,用于追踪当前调用链 langfuse_handler = langfuse_context.get_current_langchain_handler() # 调用LangChain处理链(need_answer_chain)进行判断 result = need_answer_chain.invoke( {"user_input": question, "outlines": outlines}, # 输入参数 config={"callbacks": [langfuse_handler]} # 注入Langfuse回调 ) # 返回布尔值:模型返回'Y'时表示需要回答 return result == 'Y' # 已有提问列表 question_list = [ ("LangChain可以商用吗", get_embeddings("LangChain可以商用吗")), ("LangChain开源吗", get_embeddings("LangChain开源吗")), ] # # 问题验证流程 @observe() def verify_question( question: str, outlines: str, question_list: list, user_id, ) -> bool: langfuse_context.update_current_trace( name="AGIClassAssistant2", user_id=user_id, ) # 判断是否需要回答 if need_answer(question, outlines): # 判断是否重复 if not check_duplicated(question, question_list): vec = cache[question] question_list.append((question, vec)) return True return False ret = verify_question( # "LangChain支持Java吗", "LangChain有商用许可吗", outlines, question_list, user_id="shisan" ) print(ret) langfuse_context.flush() - 将上面的
-
结果:
False
2.4.4 用 Session 记录一个用户的多轮对话
-
下图展示了 LangFuse 如何通过 Session(会话) 结构来记录一个用户的多轮对话流程;
SESSION (id: session_id) | |-- TRACE |-- TRACE |-- TRACE |-- ...-
Session(会话)
- 作用:表示一个用户的一次完整对话会话(例如一次客服咨询、一次AI助手对话等);
- ID:
session_id是该会话的唯一标识符,用于关联同一用户的多轮交互; - 特点:
- 一个 Session 可以包含多次用户与系统的交互(即多个
TRACE); - 适合长期跟踪用户行为(如跨天、跨场景的对话);
- 一个 Session 可以包含多次用户与系统的交互(即多个
-
TRACE(跟踪记录)
- 作用:记录用户在一次完整交互中的多轮对话(例如用户输入→系统回复→用户反馈→系统最终回复);
- 层级关系:一个 Session 下会包含多个
TRACE,每个TRACE代表一次独立的交互流程; - 典型场景:
- 用户发起一个问题(TRACE 1);
- 用户后续追问或补充(TRACE 2);
- 系统多次响应(每个 TRACE 可能包含更细粒度的步骤,如生成、检索等);
-
例:假设用户与AI助手对话:
Session (session_id: "abc123") |-- TRACE 1(用户提问:"推荐适合新手的Python教程" → 系统回复) |-- TRACE 2(用户追问:"这些教程是否免费?" → 系统回复) |-- TRACE 3(用户反馈:"谢谢,我试试第一个")
-
-
例:
- 下面的代码不与
2.4.1 构建 PromptTemplate至2.4.3 用 Trace 记录一个多次调用 LLM 的过程一起,若用PyCharm需重新创建一个文件来编写;
import os from langchain_openai import ChatOpenAI from langchain_core.messages import HumanMessage, SystemMessage from datetime import datetime from langfuse.decorators import langfuse_context, observe os.environ["LANGFUSE_PUBLIC_KEY"] = "LANGFUSE_PUBLIC_KEY" os.environ["LANGFUSE_SECRET_KEY"] = "LANGFUSE_SECRET_KEY" now = datetime.now() llm = ChatOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-turbo", temperature=0, ) messages = [ SystemMessage(content="你是AGIClass的课程助理。"), ] session_id = "chat-" + now.strftime("%d/%m/%Y %H:%M:%S") @observe() def chat_one_turn(user_input, user_id, turn_id): langfuse_context.update_current_trace( name=f"ChatTurn{turn_id}", user_id=user_id, session_id=session_id ) langfuse_handler = langfuse_context.get_current_langchain_handler() messages.append(HumanMessage(content=user_input)) response = llm.invoke(messages, config={"callbacks": [langfuse_handler]}) messages.append(response) return response.content user_id = "shisan" turn_id = 0 while True: user_input = input("User: ") if user_input.strip() == "": break reply = chat_one_turn(user_input, user_id, turn_id) print("AI: " + reply) turn_id += 1 langfuse_context.flush() - 下面的代码不与
-
结果:
User: 你好 AI: 你好!我是AGIClass的课程助理,有什么我可以帮助你的吗?😊 User: 没什么 AI: 好的,如果你有任何问题或需要帮助的时候,随时可以找我哦!📚👩🏫 User: 谢谢 AI: 不客气!如果有其他问题,记得随时来找我。祝你学习愉快!🌟✨ User:
2.5 数据集与测试
2.5.1 在线标注
2.5.2 上传已有数据集
-
在项目文件夹下已放入以下文件:
-
参考代码:
import os import json os.environ["LANGFUSE_PUBLIC_KEY"] = "LANGFUSE_PUBLIC_KEY" os.environ["LANGFUSE_SECRET_KEY"] = "LANGFUSE_SECRET_KEY" # 调整数据格式 {"input":{...},"expected_output":"label"} data = [] with open('my_annotations.jsonl', 'r', encoding='utf-8') as fp: for line in fp: example = json.loads(line.strip()) item = { "input": { "outlines": example["outlines"], "user_input": example["user_input"] }, "expected_output": example["label"] } data.append(item) from langfuse import Langfuse from tqdm import tqdm dataset_name = "my-dataset" # 初始化客户端 langfuse=Langfuse() # 测试连接:尝试创建一个简单的 Trace try: trace = langfuse.trace( name="test-connection", metadata={"test": True} ) print("✅ Langfuse 连接成功!") print(f"Trace ID: {trace.id}") except Exception as e: print("❌ Langfuse 连接失败,错误信息:", e) # 创建数据集,如果已存在不会重复创建 try: langfuse.create_dataset( name=dataset_name, # optional description description="My first dataset", # optional metadata metadata={ "author": "shisan", "type": "demo" } ) except: pass # 考虑演示运行速度,只上传前50条数据 for item in tqdm(data[:50]): langfuse.create_dataset_item( dataset_name="my-dataset", input=item["input"], expected_output=item["expected_output"] ) -
结果:
✅ Langfuse 连接成功! Trace ID: 2d44a951-93c5-4ed3-be78-a7e8cde96658 Unauthorized. Please check your public/private host settings. Refer to our installation and setup guide: https://langfuse.com/docs/sdk/typescript/guide for details on SDK configuration. 0%| | 0/50 [00:00<?, ?it/s]Unauthorized. Please check your public/private host settings. Refer to our installation and setup guide: https://langfuse.com/docs/sdk/typescript/guide for details on SDK configuration. 0%| | 0/50 [00:00<?, ?it/s] Traceback (most recent call last): File "C:\Users\22263\Desktop\Project\ai-full-stack-engineer\9_llm-tools\2.5.2 上传已有数据集.py", line 57, in <module> langfuse.create_dataset_item( File "C:\python3.12.7\Lib\site-packages\langfuse\client.py", line 601, in create_dataset_item raise e File "C:\python3.12.7\Lib\site-packages\langfuse\client.py", line 598, in create_dataset_item return self.client.dataset_items.create(request=body) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "C:\python3.12.7\Lib\site-packages\langfuse\api\resources\dataset_items\client.py", line 81, in create raise UnauthorizedError( langfuse.api.resources.commons.errors.unauthorized_error.UnauthorizedError: status_code: 401, body: {'message': "Invalid credentials. Confirm that you've configured the correct host."}- 连接成功但数据集操作失败 → 几乎肯定是 API 密钥权限不足 或 数据集已存在但权限冲突。
2.5.3 定义评估函数
-
参考代码:
def simple_evaluation(output, expected_output): return output == expected_output
2.5.4 运行测试
-
参考代码:
from langchain.prompts import PromptTemplate from langchain_openai import ChatOpenAI from langchain_core.output_parsers import StrOutputParser need_answer = PromptTemplate.from_template(""" ********* 你是AIGC课程的助教,你的工作是从学员的课堂交流中选择出需要老师回答的问题,加以整理以交给老师回答。 课程内容: {outlines} ********* 学员输入: {user_input} ********* 如果这是一个需要老师答疑的问题,回复Y,否则回复N。 只回复Y或N,不要回复其他内容。""") model = ChatOpenAI(temperature=0, seed=42) parser = StrOutputParser() chain_v1 = ( need_answer | model | parser ) -
在数据集上测试效果:
from concurrent.futures import ThreadPoolExecutor import threading from langfuse import Langfuse from datetime import datetime langfuse = Langfuse() lock = threading.Lock() def run_evaluation(chain, dataset_name, run_name): dataset = langfuse.get_dataset(dataset_name) def process_item(item): with lock: # 注意:多线程调用此处要加锁,否则会有id冲突导致丢数据 handler = item.get_langchain_handler(run_name=run_name) # Assuming chain.invoke is a synchronous function output = chain.invoke(item.input, config={"callbacks": [handler]}) # Assuming handler.root_span.score is a synchronous function handler.trace.score( name="accuracy", value=simple_evaluation(output, item.expected_output) ) print('.', end='', flush=True) # for item in dataset.items: # process_item(item) with ThreadPoolExecutor(max_workers=4) as executor: executor.map(process_item, dataset.items)run_evaluation(chain_v1, "my-dataset", "v1-"+datetime.now().strftime("%d/%m/%Y %H:%M:%S")) # 保证全部数据同步到云端 langfuse_context.flush()
2.5.5 Prompt 调优与回归测试
-
优化Prompt,实施思维链,参考代码如下:
from langchain.prompts import PromptTemplate need_answer = PromptTemplate.from_template(""" ********* 你是AIGC课程的助教,你的工作是从学员的课堂交流中选择出需要老师回答的问题,加以整理以交给老师回答。 你的选择需要遵循以下原则: 1 需要老师回答的问题是指与课程内容或AI/LLM相关的技术问题; 2 评论性的观点、闲聊、表达模糊不清的句子,不需要老师回答; 3 学生输入不构成疑问句的,不需要老师回答; 4 学生问题中如果用“这”、“那”等代词指代,不算表达模糊不清,请根据问题内容判断是否需要老师回答。 课程内容: {outlines} ********* 学员输入: {user_input} ********* Analyse the student's input according to the lecture's contents and your criteria. Output your analysis process step by step. Finally, output a single letter Y or N in a separate line. Y means that the input needs to be answered by the teacher. N means that the input does not needs to be answered by the teacher.""")from langchain_core.output_parsers import BaseOutputParser import re class MyOutputParser(BaseOutputParser): """自定义parser,从思维链中取出最后的Y/N""" def parse(self, text: str) -> str: matches = re.findall(r'[YN]', text) return matches[-1] if matches else 'N'chain_v2 = ( need_answer | model | MyOutputParser() ) -
回归测试:
run_evaluation(chain_v2, "my-dataset", "cot-"+datetime.now().strftime("%d/%m/%Y %H:%M:%S")) # 保证全部数据同步到云端 langfuse_context.flush()
2.6 Prompt 版本管理
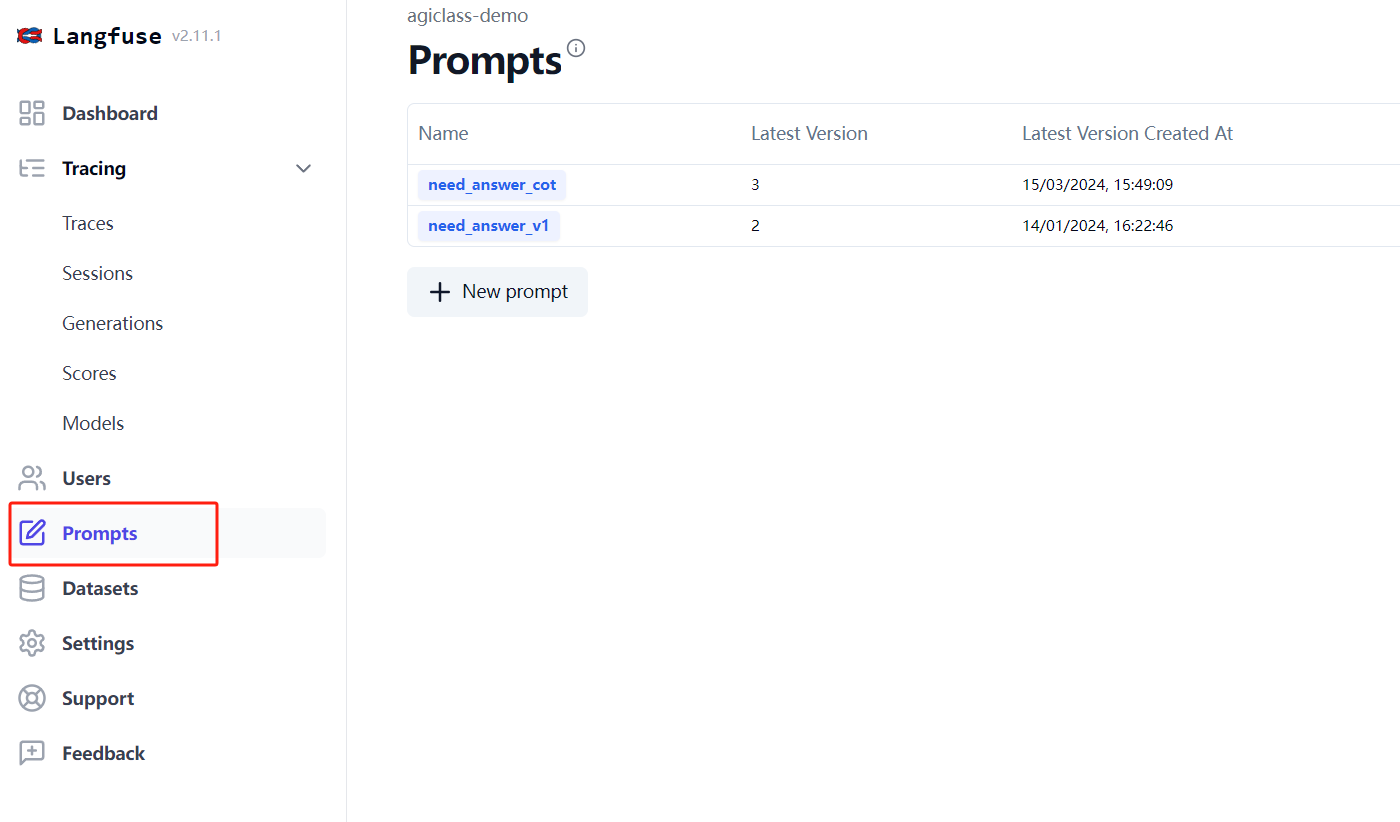
-
目前只支持 Langfuse 自己的 SDK,参考代码:
from langfuse import Langfuse langfuse = Langfuse() # 按名称加载 prompt = langfuse.get_prompt("need_answer_v1") # 按名称和版本号加载 prompt = langfuse.get_prompt("need_answer_v1", version=2) # 对模板中的变量赋值 compiled_prompt = prompt.compile(input="老师好", outlines="test") print(compiled_prompt)# 获取 config prompt = langfuse.get_prompt("need_answer_v1", version=5) print(prompt.config)
2.7 如何比较两个句子的相似性:一些经典 NLP 的评测方法
-
编辑距离:也叫莱文斯坦距离(Levenshtein),是针对二个字符串的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串;
- 具体计算过程是一个动态规划算法:编辑距离python实现及内存优化 - 知乎;
- 衡量两个句子的相似度时,可以以词为单位计算;
-
BLEU Score:
- 计算输出与参照句之间的 n-gram 准确率(n=1…4);
- 对短输出做惩罚;
- 在整个测试集上平均下述值;
- 完整计算公式: B L E U 4 = min ( 1 , o u t p u t − l e n g t h r e f e r e n c e − l e n g t h ) ( ∏ i = 1 4 p r e c i s i o n i ) 1 4 \mathrm{BLEU}_4=\min\left(1,\frac{output-length}{reference-length}\right)\left(\prod_{i=1}^4 precision_i\right)^{\frac{1}{4}} BLEU4=min(1,reference−lengthoutput−length)(∏i=14precisioni)41;
- 函数库:NLTK :: nltk.translate.bleu_score;
-
Rouge Score:
- Rouge-N:将模型生成的结果和标准结果按 N-gram 拆分后,只计算召回率;
- Rouge-L: 利用了最长公共子序列(Longest Common Sequence),计算: P = L C S ( c , r ) l e n ( c ) P=\frac{LCS(c,r)}{len(c)} P=len(c)LCS(c,r), R = L C S ( c , r ) l e n ( r ) R=\frac{LCS(c,r)}{len(r)} R=len(r)LCS(c,r), F = ( 1 + β 2 ) P R R + β 2 P F=\frac{(1+\beta^2)PR}{R+\beta^2P} F=R+β2P(1+β2)PR;
- 函数库:rouge-score · PyPI;
- 对比 BLEU 与 ROUGE:
- BLEU 能评估流畅度,但指标偏向于较短的翻译结果(brevity penalty 没有想象中那么强);
- ROUGE 不管流畅度,所以只适合深度学习的生成模型:结果都是流畅的前提下,ROUGE 反应参照句中多少内容被生成的句子包含(召回);
-
METEOR: 另一个从机器翻译领域借鉴的指标。与 BLEU 相比,METEOR 考虑了更多的因素,如同义词匹配、词干匹配、词序等,因此它通常被认为是一个更全面的评价指标;
- 对语言学和语义词表有依赖,所以对语言依赖强;
-
**注意:**此类方法常用于对文本生成模型的自动化评估。实际使用中,我们通常更关注相对变化而不是绝对值(调优过程中指标是不是在变好)。
2.8 基于 LLM 的测试方法
- LangFuse 提供了基于 LLM 和 Prompt 的自动测试工具;
- 具体参考:Fully managed LLM-as-a-judge evaluation - Langfuse;
- **注意:**此类方法,对于用于评估的 LLM 自身能力有要求。需根据具体情况选择使用。
2.9 与 LlamaIndex 集成
-
安装包:
pip install --upgrade llama-index -
参考代码:
from llama_index.core import Settings from llama_index.core.callbacks import CallbackManager from langfuse.llama_index import LlamaIndexCallbackHandler # 定义 LangFuse 的 CallbackHandler langfuse_callback_handler = LlamaIndexCallbackHandler() # 修改 LlamaIndex 的全局设定 Settings.callback_manager = CallbackManager([langfuse_callback_handler])from llama_index.core import VectorStoreIndex, SimpleDirectoryReader from llama_index.core.node_parser import SentenceSplitter from llama_index.readers.file import PyMuPDFReader from llama_index.core import Settings from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding # 指定全局llm与embedding模型 Settings.llm = OpenAI(temperature=0, model="gpt-4o") Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512) Settings.transforms = [SentenceSplitter(chunk_size=300, chunk_overlap=100)] # 加载 pdf 文档 documents = SimpleDirectoryReader("./data", file_extractor={".pdf": PyMuPDFReader()}).load_data() # 指定 Vector Store 用于 index index = VectorStoreIndex.from_documents(documents) # 构建单轮 query engine query_engine = index.as_query_engine()response = query_engine.query("llama2有多少参数") print(response) -
自定义 Trace 参数,参考代码:
langfuse_callback_handler.set_trace_params( user_id="wzr", session_id="llamaindex-session", tags=["demo"] )response = query_engine.query("llama2安全吗") print(response) -
更多接口与参数,请参考官方文档。
3 LangSmith
3.1 文档及使用
-
LangChain 官方的 SaaS 服务,不开源;
-
平台入口:LangSmith;
-
将你的 LangChain 应用与 LangSmith 链接,需要:
-
安装LangSmith:
pip install --upgrade langsmith -
注册账号,并申请一个
LANGCHAIN_API_KEY; -
在环境变量中设置以下值:
export LANGCHAIN_TRACING_V2=true export LANGCHAIN_PROJECT=YOUR_PROJECT_NAME #自定义项目名称(可选) export LANGCHAIN_API_KEY=LANGCHAIN_API_KEY # LangChain API Key -
程序中的调用将自动被记录:
import os from datetime import datetime os.environ["LANGCHAIN_TRACING_V2"] = "true" os.environ["LANGCHAIN_PROJECT"] = "HelloWorld-Demo"
-
3.2 基本功能
-
Traces
-
LLM Calls
-
Monitor
-
Playground
-
参考代码:
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, ) from langchain_core.output_parsers import StrOutputParser from langchain_openai import ChatOpenAI from langchain_core.runnables import RunnablePassthrough model = ChatOpenAI(model="gpt-3.5-turbo") prompt = ChatPromptTemplate.from_messages([ HumanMessagePromptTemplate.from_template("Say hello to {input}!") ]) # 定义输出解析器 parser = StrOutputParser() chain = ( {"input": RunnablePassthrough()} | prompt | model | parser )chain.invoke("小赵")
3.3 数据集管理与测试
3.3.1 在线标注
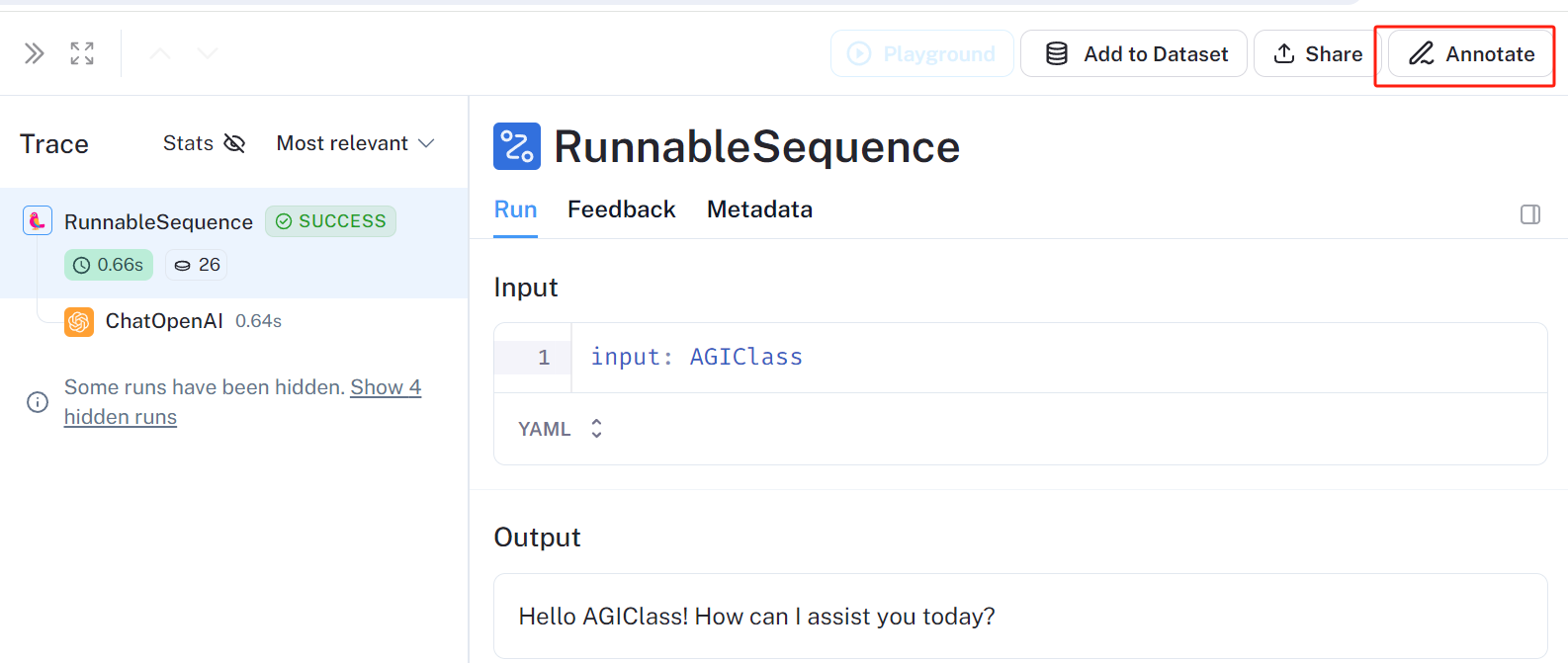
3.3.2 上传数据集
-
参考代码:
import json data = [] with open('my_annotations.jsonl', 'r', encoding='utf-8') as fp: for line in fp: example = json.loads(line.strip()) item = { "input": { "outlines": example["outlines"], "user_input": example["user_input"] }, "expected_output": example["label"] } data.append(item)from langsmith import Client client = Client() dataset_name = "Assistant-"+datetime.now().strftime("%d/%m/%Y %H:%M:%S") dataset = client.create_dataset( dataset_name, # 数据集名称 description="AGIClass线上跟课助手的标注数据", # 数据集描述 ) inputs, outputs = zip( *[({"input": item["input"]}, {"label": item["expected_output"]}) for item in data[:50]] ) client.create_examples(inputs=inputs, outputs=outputs, dataset_id=dataset.id)
3.3.3 评估函数
-
参考代码:
from langsmith.schemas import Example, Run def correct_label(root_run: Run, example: Example) -> dict: score = root_run.outputs.get("output") == example.outputs.get("label") return {"score": int(score), "key": "accuracy"}
3.3.4 运行测试
-
参考代码:
from langchain.prompts import PromptTemplate from langchain_openai import ChatOpenAI from langchain_core.output_parsers import StrOutputParser need_answer = PromptTemplate.from_template(""" ********* 你是AIGC课程的助教,你的工作是从学员的课堂交流中选择出需要老师回答的问题,加以整理以交给老师回答。 课程内容: {outlines} ********* 学员输入: {user_input} ********* 如果这是一个需要老师答疑的问题,回复Y,否则回复N。 只回复Y或N,不要回复其他内容。""") model = ChatOpenAI(temperature=0, seed=42) parser = StrOutputParser() chain_v1 = need_answer | model | parserfrom langsmith.evaluation import evaluate results = evaluate( lambda inputs: chain_v1.invoke(inputs["input"]), data=dataset_name, evaluators=[correct_label], experiment_prefix="Acc", description="测试ChainV1",

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)