Taskflow概述 -- github官网翻译
【github链接】https://github.com/taskflow/taskflow
1.概述
Taskflow 是一个帮助你快速编写并行和异构任务程序的Modern C++ 框架。以下是为什么选择 Taskflow 的几个理由,以及一些用户对它的评价:
为什么选择 Taskflow?
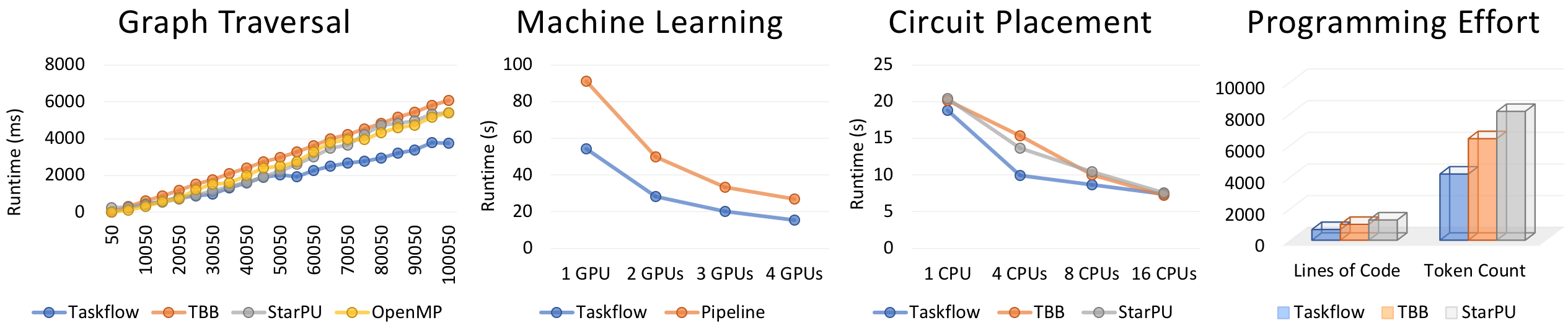
- 速度更快:相比许多现有的任务编程框架,Taskflow 在处理复杂的并行工作负载时表现得更快。
- 表达力更强:它允许开发者更直观地实现任务分解策略,无论是规则计算模式还是不规则计算模式都能很好地集成。
- 易于集成:提供了比其他框架更容易的下拉式集成(drop-in integration),便于快速上手使用。
- 高效的窃取式调度器(work-stealing scheduler):优化了多线程性能,确保了在复杂计算环境下的高效执行。
Taskflow 的应用
Taskflow 致力于支持学术和工业研究项目中关于并行与异构计算的开发。无论你是从事学术研究还是工业应用,Taskflow 都能为你的项目提供强有力的支持。
用户评价
- Damien Hocking @Corelium Inc:“Taskflow 是我见过最干净的任务API。”
- Glen Fraser:“Taskflow 拥有非常简单且优雅的任务接口。其性能也扩展得很好。”
- Hayabusa @Learning:“Taskflow 让我能以智能的方式处理并行处理。”
- Jean-Michaël @KDAB:“仅用了几个小时的编码,Taskflow 就提高了我们图引擎的吞吐量。”
- 获得了 2018 年 Cpp Conference 的最佳开源并行编程库海报奖。
- 在 2019 年 ACM Multimedia Conference 上获得了开源软件竞赛二等奖。
这些评价不仅展示了 Taskflow 在实际应用中的有效性,也反映了它在社区中的受欢迎程度和技术认可度。
更多信息
如果你想了解更多关于 Taskflow 的信息,可以查看其[文档]https://taskflow.github.io/ ,[CookBook] https://taskflow.github.io/taskflow/Cookbook.html,或者阅读他们发表在 IEEE TPDS 上的技术论文来获取技术细节。此外,还有一个简短的介绍视频可以帮助你快速了解 Taskflow 的核心概念和用途。通过这些资源,你可以深入理解 Taskflow 如何帮助你提高项目的并行处理能力和效率。
2. Taskflow支持的任务类型
它支持静态任务,动态任务、条件任务,组合任务以及GPU任务编程
2.1 静态任务 Static Tasking
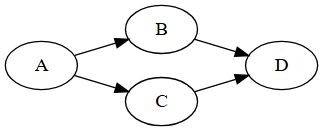
#include <taskflow/taskflow.hpp> // Taskflow is header-only
int main(){
tf::Executor executor;
tf::Taskflow taskflow;
auto [A, B, C, D] = taskflow.emplace( // create four tasks
[] () { std::cout << "TaskA\n"; },
[] () { std::cout << "TaskB\n"; },
[] () { std::cout << "TaskC\n"; },
[] () { std::cout << "TaskD\n"; }
);
A.precede(B, C); // A runs before B and C
D.succeed(B, C); // D runs after B and C
executor.run(taskflow).wait();
return 0;
}
2.2 动态任务 Subflow Tasking
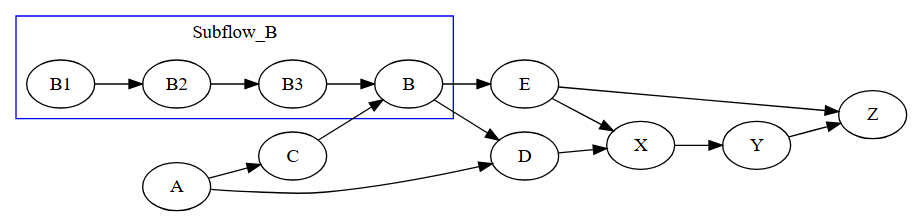
tf::Task A = taskflow.emplace([](){}).name("A");
tf::Task C = taskflow.emplace([](){}).name("C");
tf::Task D = taskflow.emplace([](){}).name("D");
tf::Task B = taskflow.emplace([] (tf::Subflow& subflow) {
tf::Task B1 = subflow.emplace([](){}).name("B1");
tf::Task B2 = subflow.emplace([](){}).name("B2");
tf::Task B3 = subflow.emplace([](){}).name("B3");
B3.succeed(B1, B2); // B3 runs after B1 and B2
}).name("B");
A.precede(B, C); // A runs before B and C
D.succeed(B, C); // D runs after B and C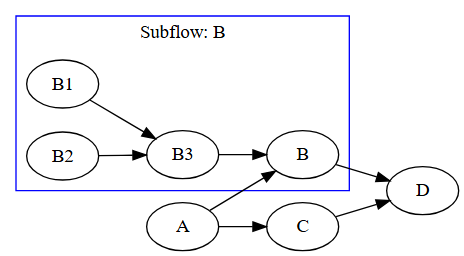
Taskflow 的动态任务(Dynamic Tasking)特性允许在任务执行过程中动态生成子流(subflow graph),从而实现动态并行性(dynamic parallelism)。这种能力非常适合处理运行时依赖关系未知或需要根据某些条件动态生成任务的情况。
动态任务的核心机制
- tf::Subflow:
- tf::Subflow 是 Taskflow 提供的一个接口,用于在任务执行过程中动态生成子流。
- 子流中的任务会在当前任务的上下文中并行执行,并且可以与其他任务共享资源。
- 动态并行性:
- 动态任务允许在运行时生成新的任务和依赖关系,而不需要预先定义整个任务图。
- 这种方式特别适合处理递归算法、分治算法或其他需要动态生成任务的场景。
使用场景
1. 递归算法:
- 例如快速排序(QuickSort)或归并排序(MergeSort),可以在划分阶段动态生成子任务来处理不同的数据分区。
2. 分治策略:
- 对于需要将问题分解为多个子问题的算法,可以使用动态任务来递归地生成子任务。
3. 运行时依赖:
- 当任务之间的依赖关系在运行时才能确定时,可以通过动态任务来灵活构建任务图。
2.3 条件任务 Conditional Tasking
tf::Taskflow taskflow;
tf::Task A = taskflow.emplace([](){}).name("A");
tf::Task B = taskflow.emplace([](){}).name("B");
tf::Task C = taskflow.emplace([](){}).name("C");
tf::Task D = taskflow.emplace([](){}).name("D");
tf::Task E = taskflow.emplace([](){}).name("E");
tf::Task F = taskflow.emplace([](){}).name("F");
tf::Task G = taskflow.emplace([](){}).name("G");
tf::Task H = taskflow.emplace([](){}).name("H");
tf::Task I = taskflow.emplace([](){}).name("I");
tf::Task K = taskflow.emplace([](){}).name("K");
tf::Task L = taskflow.emplace([](){}).name("L");
tf::Task M = taskflow.emplace([](){}).name("M");
tf::Task cond_1 = taskflow.emplace([](){ return std::rand()%2; }).name("cond_1");
tf::Task cond_2 = taskflow.emplace([](){ return std::rand()%2; }).name("cond_2");
tf::Task cond_3 = taskflow.emplace([](){ return std::rand()%2; }).name("cond_3");
A.precede(B, F);
B.precede(C);
C.precede(D);
D.precede(cond_1);
E.precede(K);
F.precede(cond_2);
H.precede(I);
I.precede(cond_3);
L.precede(M);
cond_1.precede(B, E); // return 0 to 'B' or 1 to 'E'
cond_2.precede(G, H); // return 0 to 'G' or 1 to 'H'
cond_3.precede(cond_3, L); // return 0 to 'cond_3' or 1 to 'L'
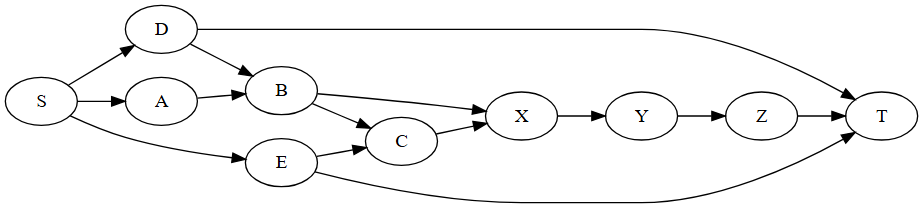
taskflow.dump(std::cout);上述代码创建了三个条件任务:
1. 条件任务 `cond_1`,当返回 0 时循环回到任务 B,当返回 1 时继续执行任务 E;
2. 条件任务 `cond_2`,当返回 0 时跳转到任务 G,当返回 1 时跳转到任务 H;
3. 条件任务 `cond_3`,当返回 0 时循环回到自身,当返回 1 时继续执行任务 L。

tf::Taskflow taskflow;
tf::Task init = taskflow.emplace([](){}).name("init");
tf::Task stop = taskflow.emplace([](){}).name("stop");
// creates a condition task that returns a random binary
tf::Task cond = taskflow.emplace(
[](){ return std::rand() % 2; }
).name("cond");
init.precede(cond);
// creates a feedback loop {0: cond, 1: stop}
cond.precede(cond, stop);上面的例子通过一个条件任务(第 7-10 行)实现了一个简单但常用的反馈循环,该任务返回一个随机的二进制值。如果 `cond` 的返回值为 0,则循环回到自身;否则停止。
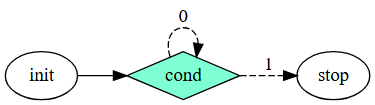
Taskflow 的条件任务(Conditional Tasking)特性允许开发者在任务图中快速做出控制流决策,从而实现循环和条件分支。这种能力使得 Taskflow 能够支持端到端的任务图设计,而无需依赖复杂的外部逻辑或手动管理任务依赖关系。
条件任务的核心概念
1. 动态控制流:
- 在任务执行过程中,可以根据某些条件动态决定接下来执行哪些任务。
- 这种机制非常适合实现循环、条件分支或其他需要运行时决策的场景。
2. 无缝集成到任务图:
- 条件任务可以直接嵌入到任务图中,与其他任务共享相同的调度器和执行上下文。
- 通过条件任务,可以轻松实现复杂的控制流逻辑,而无需修改任务图的整体结构。
3. 灵活性:
- 支持基于任务输出、外部状态或运行时条件的动态决策。
- 可以与其他 Taskflow 特性(如动态任务、子流)结合使用,构建更复杂的应用。
使用场景
1. 数据驱动的流程控制:
- 根据输入数据的特征动态调整任务执行路径。例如,在数据处理管道中,根据数据类型选择不同的处理逻辑。
2. 算法中的条件分支:
- 在实现复杂算法时,可以根据中间结果动态选择不同的计算路径。例如,机器学习中的模型选择或优化策略。
3. 循环与递归:
- 条件任务可以用于实现循环或递归逻辑。例如,分治算法中根据问题规模动态生成子任务。
4. 错误处理:
- 在任务执行过程中检测错误,并根据错误类型动态选择恢复或终止策略。
2.4 组合任务 Taskflow Composition

tf::Taskflow f1, f2;
// create taskflow f1 of two tasks
tf::Task f1A = f1.emplace([]() { std::cout << "Task f1A\n"; })
.name("f1A");
tf::Task f1B = f1.emplace([]() { std::cout << "Task f1B\n"; })
.name("f1B");
// create taskflow f2 with one module task composed of f1
tf::Task f2A = f2.emplace([]() { std::cout << "Task f2A\n"; })
.name("f2A");
tf::Task f2B = f2.emplace([]() { std::cout << "Task f2B\n"; })
.name("f2B");
tf::Task f2C = f2.emplace([]() { std::cout << "Task f2C\n"; })
.name("f2C");
tf::Task f1_module_task = f2.composed_of(f1)
.name("module");
f1_module_task.succeed(f2A, f2B)
.precede(f2C);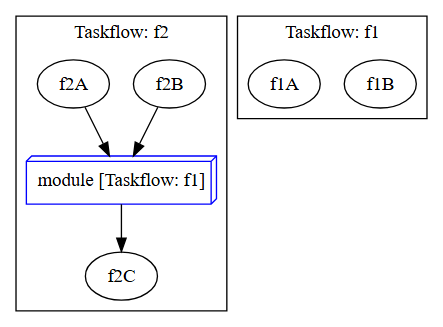
Taskflow 的可组合性(Composability)是其核心优势之一。通过将任务流设计为模块化和可重用的块,开发者可以构建大规模并行图,并在单个作用域内优化这些模块。这种设计不仅提高了代码的可读性和维护性,还使得复杂任务图的构建变得更加直观和高效。
可组合性的关键特性
1. 模块化设计:
- 任务流可以被分割成多个小的、独立的任务块或子流,每个块专注于特定的功能。
- 这种模块化设计使得代码更加清晰,便于理解和维护。
2. 可重用性:
- 一旦定义了一个任务块或子流,就可以在不同的上下文中多次使用它,减少重复代码。
- 例如,你可以创建一个通用的数据处理管道作为子流,并在多个主任务流中复用它。
3. 易于优化:
- 模块化的任务块通常比整个任务图更容易进行性能优化。
- 开发者可以在不影响其他部分的情况下,针对特定的任务块进行优化。
4. 灵活的组合方式:
- Taskflow 提供了多种方式来组合任务块,如嵌入子流、动态生成任务等。
- 这种灵活性允许根据具体需求调整任务图结构,适应不同的应用场景。
示例代码
以下是一个展示如何通过组合模块化和可重用的任务块来构建大规模并行图的例子:
#include <taskflow/taskflow.hpp>
// 定义一个可重用的子流:数据处理管道
tf::Taskflow create_data_pipeline() {
tf::Taskflow pipeline;
auto [read, process, store] = pipeline.emplace(
[] () { std::cout << "Reading data\n"; },
[] () { std::cout << "Processing data\n"; },
[] () { std::cout << "Storing data\n"; }
);
// 设置依赖关系:read -> process -> store
read.precede(process);
process.precede(store);
return pipeline;
}
int main() {
tf::Executor executor;
tf::Taskflow main_taskflow;
// 创建两个可重用的数据处理管道
auto pipeline1 = create_data_pipeline();
auto pipeline2 = create_data_pipeline();
// 在主任务流中嵌入这两个子流
main_taskflow.composed_of(pipeline1).name("Pipeline 1");
main_taskflow.composed_of(pipeline2).name("Pipeline 2");
// 添加额外的任务,并设置依赖关系
auto [init, finalize] = main_taskflow.emplace(
[] () { std::cout << "Initializing...\n"; },
[] () { std::cout << "Finalizing...\n"; }
);
init.precede(pipeline1).precede(pipeline2); // 初始化后执行两个子流
pipeline1.notify(finalize); // 子流完成后通知finalize
pipeline2.notify(finalize); // 子流完成后通知finalize
// 执行任务流
executor.run(main_taskflow).wait();
return 0;
}
程序解析
1. 定义可重用的子流:
- create_data_pipeline 函数创建了一个包含三个步骤的数据处理管道:读取数据、处理数据、存储数据。
- 这个子流可以在不同的上下文中复用。
2. 主任务流中的组合:
- 在 main 函数中,我们创建了两个相同的数据处理管道实例 pipeline1 和 pipeline2。
- 使用 composed_of 方法将这两个子流嵌入到主任务流中。
3. 依赖关系设置:
- init 任务在初始化后触发两个子流的执行。
- finalize 任务在两个子流都完成后执行,确保所有数据处理任务完成后再进行最终操作。
4. 输出结果:
Initializing...
Reading data
Processing data
Storing data
Reading data
Processing data
Storing data
Finalizing...使用场景
- 复杂的数据处理流程:
- 将数据读取、处理、存储等步骤封装为独立的子流,然后根据需要在主任务流中组合这些子流。
- 并行计算与任务调度:
- 对于需要并行执行多个相似任务的应用场景,可以通过组合多个相同的子流来实现高效的并行计算。
- 模块化的软件开发:
- 在大型项目中,利用 Taskflow 的可组合性,可以将不同功能模块设计为独立的任务块,便于团队协作和代码维护。
2.5 GPU任务 Concurrent CPU-GPU Tasking

__global__ void saxpy(size_t N, float alpha, float* dx, float* dy) {
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) {
y[i] = a*x[i] + y[i];
}
}
// create a CUDA Graph task
tf::Task cudaflow = taskflow.emplace([&]() {
tf::cudaGraph cg;
tf::cudaTask h2d_x = cg.copy(dx, hx.data(), N);
tf::cudaTask h2d_y = cg.copy(dy, hy.data(), N);
tf::cudaTask d2h_x = cg.copy(hx.data(), dx, N);
tf::cudaTask d2h_y = cg.copy(hy.data(), dy, N);
tf::cudaTask saxpy = cg.kernel((N+255)/256, 256, 0, saxpy, N, 2.0f, dx, dy);
saxpy.succeed(h2d_x, h2d_y)
.precede(d2h_x, d2h_y);
// instantiate an executable CUDA graph and run it through a stream
tf::cudaGraphExec exec(cg);
tf::cudaStream stream;
stream.run(exec).synchronize();
}).name("CUDA Graph Task");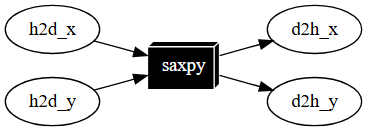
Taskflow 确实支持 GPU 任务(GPU Tasking),这使得开发者能够利用 Nvidia CUDA Graph 加速广泛的科学计算应用,通过 CPU 和 GPU 的协同计算来提升性能。这种能力允许你在复杂的并行计算环境中充分利用 GPU 的强大计算资源,同时保持任务图的灵活性和可扩展性。
3. 启动异步任务
tf::Executor executor;
// create asynchronous tasks directly from an executor
std::future<int> future = executor.async([](){
std::cout << "async task returns 1\n";
return 1;
});
executor.silent_async([](){ std::cout << "async task does not return\n"; });
// create asynchronous tasks with dynamic dependencies
tf::AsyncTask A = executor.silent_dependent_async([](){ printf("A\n"); });
tf::AsyncTask B = executor.silent_dependent_async([](){ printf("B\n"); }, A);
tf::AsyncTask C = executor.silent_dependent_async([](){ printf("C\n"); }, A);
tf::AsyncTask D = executor.silent_dependent_async([](){ printf("D\n"); }, B, C);
executor.wait_for_all();4. 执行一个任务流
// runs the taskflow once
tf::Future<void> run_once = executor.run(taskflow);
// wait on this run to finish
run_once.get();
// run the taskflow four times
executor.run_n(taskflow, 4);
// runs the taskflow five times
executor.run_until(taskflow, [counter=5](){ return --counter == 0; });
// block the executor until all submitted taskflows complete
executor.wait_for_all();5. 标准并行算法
Taskflow 为你定义了算法,使你能够使用标准的 C++ 语法快速表达常见的并行模式,例如并行迭代、并行归约和并行排序。
// standard parallel CPU algorithms
tf::Task task1 = taskflow.for_each( // assign each element to 100 in parallel
first, last, [] (auto& i) { i = 100; }
);
tf::Task task2 = taskflow.reduce( // reduce a range of items in parallel
first, last, init, [] (auto a, auto b) { return a + b; }
);
tf::Task task3 = taskflow.sort( // sort a range of items in parallel
first, last, [] (auto a, auto b) { return a < b; }
);
// standard parallel GPU algorithms
tf::cudaTask cuda1 = cudaflow.for_each( // assign each element to 100 on GPU
dfirst, dlast, [] __device__ (auto i) { i = 100; }
);
tf::cudaTask cuda2 = cudaflow.reduce( // reduce a range of items on GPU
dfirst, dlast, init, [] __device__ (auto a, auto b) { return a + b; }
);
tf::cudaTask cuda3 = cudaflow.sort( // sort a range of items on GPU
dfirst, dlast, [] __device__ (auto a, auto b) { return a < b; }
);此外,Taskflow 提供了可组合的图构建模块,帮助你高效实现常见的并行算法,例如并行流水线。
// create a pipeline to propagate five tokens through three serial stages
tf::Pipeline pl(num_parallel_lines,
tf::Pipe{tf::PipeType::SERIAL, [](tf::Pipeflow& pf) {
if(pf.token() == 5) {
pf.stop();
}
}},
tf::Pipe{tf::PipeType::SERIAL, [](tf::Pipeflow& pf) {
printf("stage 2: input buffer[%zu] = %d\n", pf.line(), buffer[pf.line()]);
}},
tf::Pipe{tf::PipeType::SERIAL, [](tf::Pipeflow& pf) {
printf("stage 3: input buffer[%zu] = %d\n", pf.line(), buffer[pf.line()]);
}}
);
taskflow.composed_of(pl)
executor.run(taskflow).wait();
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)