【AI大模型】GRPO+LoRA:大模型训练极简方案!收藏这篇就够了!!
随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~在进行实践 GRPO 的时候,发现现存占用过大,deepseed 一键 VLLM 安装常常与 cuda 不适配,因此尝试一直采样 lora 小参数微调,环境要求更低的方式进行 GRPO
前言
随着DeepSeek爆火,面试中也越来越高频出现,因此训练营也更新了DeepSeek系列技术的深入拆解。包括MLA、MTP、专家负载均衡、FP8混合精度训练,Dual-Pipe等关键技术,力求做到全网最硬核的解析~
在进行实践 GRPO 的时候,发现现存占用过大,deepseed 一键 VLLM 安装常常与 cuda 不适配,因此尝试一直采样 lora 小参数微调,环境要求更低的方式进行 GRPO 实践。
GRPO + LoRA 代码实践:一套高效训练大模型的最小实现。
本文将分享如何使用 LoRA 对大语言模型进行高效参数微调,并结合 GRPO 奖励优化方法,实现一个完整的“奖励微调”训练流程。
本文以 Qwen2.5-3B-Instruct 为例。
1、背后思路
在训练大语言模型时,我们通常面临两个问题:
- 模型太大,无法全参数微调;
- 传统监督微调不足以优化输出质量。
本实践结合两种轻量且高效的技术路线:
- 使用 LoRA 对少量注意力层参数进行低秩更新,节省显存;
- 使用 GRPO 奖励优化训练(RLHF),鼓励输出结构正确、答案准确。
2、环境准备
import sys, types, importlib.machinerybnb_name = "bitsandbytes"spec = importlib.machinery.ModuleSpec(name=bnb_name, loader=None, is_package=True)bnb = types.ModuleType(bnb_name)bnb.__spec__ = specbnb.__path__ = []bnb.__version__ = "0.0.0"nn_name = bnb_name + ".nn"nn_spec = importlib.machinery.ModuleSpec(name=nn_name, loader=None, is_package=True)bnb_nn = types.ModuleType(nn_name)bnb_nn.__spec__ = nn_specbnb_nn.__path__ = []class Linear4bit: passclass Linear8bitLt: passbnb_nn.Linear4bit = Linear4bitbnb_nn.Linear8bitLt = Linear8bitLtbnb.nn = bnb_nnsys.modules[bnb_name] = bnbsys.modules[nn_name] = bnb_nn
**说明:**定义 bitsandbytes 中的 mock 类,用于绕过安装依赖。
3、数据加载与预处理
from datasets import load_datasetimport reSYSTEM_PROMPT = "你是一个擅长用 XML 格式输出链式思考和答案的数学助理,使用这种格式进行回答<reasoning>...</reasoning>\n<answer>...</answer>"def extract_final_answer(text: str) -> str: match = re.search(r'####\s*(\d+)', text) if match: return match.group(1).strip() match = re.search(r'\\boxed\{(.*?)\}', text) if match: return match.group(1).strip() return ""def preprocess(example): return { "prompt": [ {"role": "system", "content": SYSTEM_PROMPT}, {"role": "user", "content": example["question"]}, ], "answer": extract_final_answer(example["answer"]), }raw = load_dataset("gsm8k", "main", split="train")dataset = raw.map(preprocess, remove_columns=raw.column_names)
**说明:**加载 HuggingFace 上的 gsm8k 数学问答数据集,用于训练微调。
使用正则表达式提取答案中 #### 后面的数字,作为最终答案。加载 HuggingFace 上的 gsm8k 数学问答数据集,用于训练微调。
4、模型加载与 LoRA 挂载
from transformers import AutoTokenizer, AutoModelForCausalLMfrom peft import LoraConfig, get_peft_modelfrom modelscope import snapshot_downloadimport torchMODEL_ID = "Qwen/Qwen2.5-3B-Instruct"OUTPUT_DIR = "outputs/qwen3b-grpo-lora-fp16"DEVICE_ID = 0torch.cuda.set_device(DEVICE_ID)local_path = snapshot_download(MODEL_ID)tokenizer = AutoTokenizer.from_pretrained(local_path, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_tokenbase_model = AutoModelForCausalLM.from_pretrained( local_path, torch_dtype=torch.float16, device_map="auto", trust_remote_code=True,)base_model.gradient_checkpointing_enable()lora_cfg = LoraConfig( r=16, lora_alpha=32, lora_dropout=0.05, bias="none", task_type="CAUSAL_LM", target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ],)model = get_peft_model(base_model, lora_cfg)model.print_trainable_parameters()
**说明:**定义 LoRA 的配置,包括秩 r、dropout、目标模块等。通过 modelscope 下载 Qwen2.5 模型文件至本地。
通过 modelscope 下载 Qwen2.5 模型文件至本地。定义 LoRA 的配置,包括秩 r、dropout、目标模块等。
5、奖励函数设计(GRPO 核心)
import redef extract_xml_answer(text: str) -> str: match = re.search('<answer>(.*)</answer>', text, re.DOTALL) return match.group(1).strip() if match else ""def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]: responses = [completion[0]['content'] for completion in completions] extracted = [extract_xml_answer(r) for r in responses] return [1.0 if a in r else 0.0 for r, a in zip(extracted, answer)]def soft_format_reward_func(completions, **kwargs) -> list[float]: pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>" responses = [c[0]["content"] for c in completions] return [2.0 if re.search(pattern, r, re.DOTALL) else 0.0 for r in responses]def strict_format_reward_func(completions, **kwargs) -> list[float]: pattern = r"^\s*<reasoning>.*?</reasoning>\s*<answer>.*?</answer>\s*$" responses = [c[0]["content"] for c in completions] return [4.0 if re.search(pattern, r, re.DOTALL) else 0.0 for r in responses]
6、启动 GRPO 训练
from trl import GRPOConfig, GRPOTrainertrain_args = GRPOConfig( fp16=True, per_device_train_batch_size=16, gradient_accumulation_steps=8, learning_rate=2e-4, num_train_epochs=1, lr_scheduler_type="cosine", warmup_ratio=0.05, max_grad_norm=0.3, logging_steps=1, save_steps=100, output_dir=OUTPUT_DIR, report_to="tensorboard", max_prompt_length=512, max_completion_length=64, num_generations=8, use_vllm=False,)trainer = GRPOTrainer( model=model, processing_class=tokenizer, reward_funcs=[ soft_format_reward_func, strict_format_reward_func, correctness_reward_func ], args=train_args, train_dataset=dataset,)trainer.train()
说明: 定义 GRPO 训练参数,例如 batch size、学习率、日志步数等。定义 GRPO 训练参数,例如 batch size、学习率、日志步数等。
构建 GRPOTrainer 实例,接收模型、tokenizer、奖励函数和训练集。启动 GRPO 微调训练过程。
7、模型保存
model.save_pretrained(OUTPUT_DIR)tokenizer.save_pretrained(OUTPUT_DIR)print(f"✔ LoRA Adapter + Tokenizer 已保存到 {OUTPUT_DIR}")
说明: 保存训练后的 LoRA 模型和 tokenizer。
8、总结
通过这次实战,我们构建了一个完整的 Qwen2.5 + LoRA + GRPO 套件:
- 高效加载与处理数据
- 轻量 LoRA 微调
- 多奖励 GRPO 策略优化输出
- 可复用、可部署的训练脚本
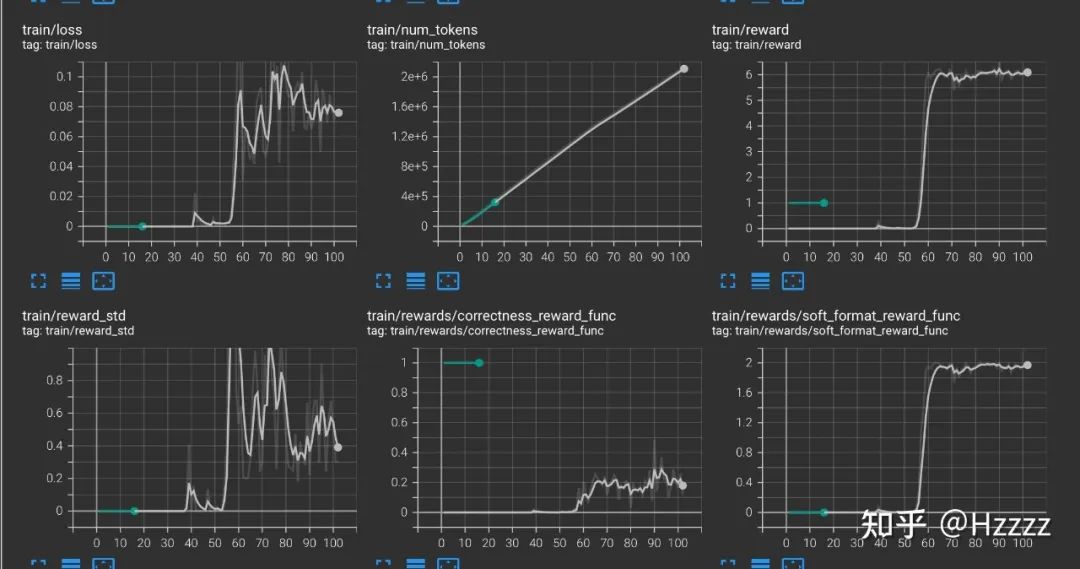
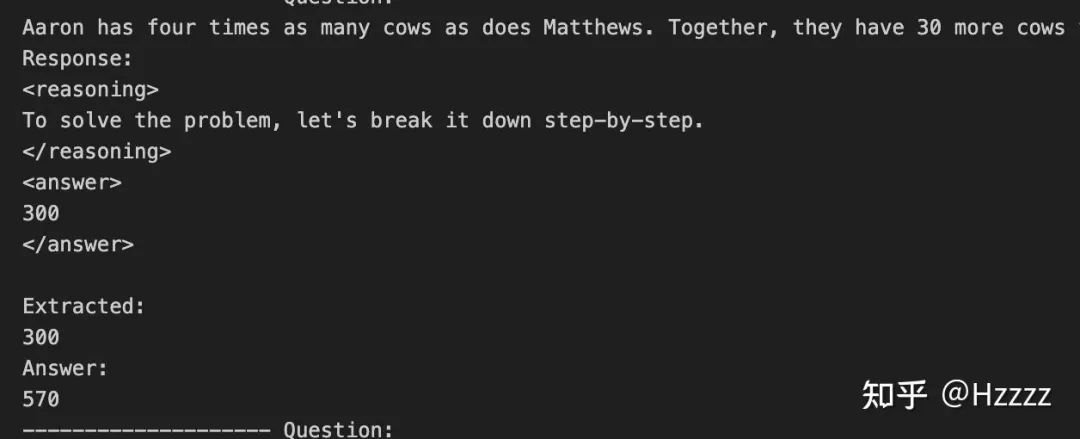
9、运行效果
运行效果如下图:
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)