双向循环神经网络
BIRNN
双向循环神经网络
给一个例子:
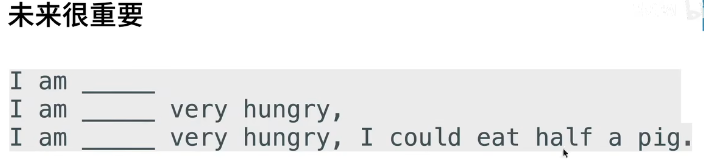

这类似于我们做的完形填空,核心思想就是说:
- 取决于过去和未来的上下文,可以填很不一样的词
- 目前为止 RNN 只看过去
- 在填空的时候,我们也可以看未来
这也就引出来了双向 RNN
双向 RNN
具体而言,就是:
一个前向 RNN 隐层
一个方向 RNN 隐层
合并两个隐状态得到输出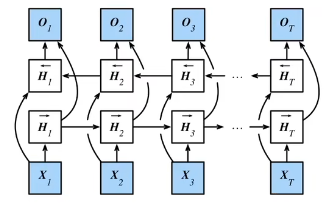
{H→t=ϕ(XtWxh(f)+H→t−1Whh(f)+bh(f)),H←t=ϕ(XtWxh(b)+H←t+1Whh(b)+bh(b)),Ht=[H→t,H←t]Ot=HtWhq+bq \left\{ \begin{aligned} \overrightarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(f)} + \overrightarrow{\mathbf{H}}_{t-1} \mathbf{W}_{hh}^{(f)} + \mathbf{b}_h^{(f)}), \\ \overleftarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(b)} + \overleftarrow{\mathbf{H}}_{t+1} \mathbf{W}_{hh}^{(b)} + \mathbf{b}_h^{(b)}), \\ \mathbf{H}_t &= [\overrightarrow{\mathbf{H}}_t, \overleftarrow{\mathbf{H}}_t] \\ \mathbf{O}_t &= \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q \end{aligned} \right. ⎩
⎨
⎧HtHtHtOt=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f)),=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b)),=[Ht,Ht]=HtWhq+bq
根据上述的原理,实际上可以发现,我在模型进行训练的时候还是比较好做的,也就是将后面的东西拿过来,前面的东西拿过去: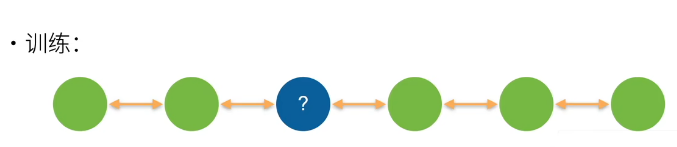
但是问题就是,上述模型进行推理的话,不是很好做,因为推理的时候,未来的信息我的模型看不到:(因此,双向循环神经网络不适合于推理,几乎是不能用在去预测下面的一个词上面),因此双向 RNN 的主要作用就是对一个句子做特征提取,比如在做翻译的时候,给定一个句子,需要翻译下一个句子,这个给定的句子可以双向的去看。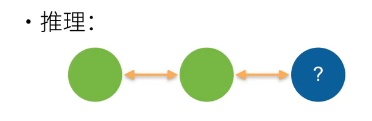
总结
- 双向循环神经网络通过反向更新的隐藏层来利用方向时间信息
- 通常用来对序列抽取特征、填空,而不是预测未来
QA 思考
Q1:双向RNN,反向的初始 hidden state 是什么?
A1:就是 0 。
时间序列是不能做双向的
Q2:双向循环神经网络,在正向和反向之间有权重关系没?
A2:没有,他们就是一个连接关系,而不是相加。
Q3:双向是否可以深度双向
A3:是的,如下图,框出的部分两层是一组单元,再向上加这样的单元即可做深层的。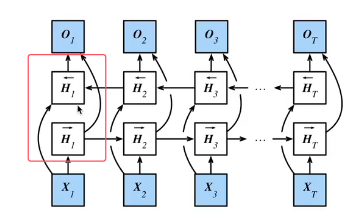
详细论述
双向循环神经网络
在序列学习中,我们以往假设的目标是:在给定观测的情况下(例如,在时间序列的上下文中或在语言模型的上下文中),对下一个输出进行建模。虽然这是个典型情景,但不是唯一的。
还可能发生什么其它的情况呢?我们考虑以下三个在文本序列中填空的任务。
- 我
___。 - 我
___饿了。 - 我
___饿了,我可以吃半头猪。
根据可获得的信息量,我们可以用不同的词填空,如“很高兴”(“happy”)、“不”(“not”)和“非常”(“very”)。很明显,每个短语的“下文”传达了重要信息(如果有的话),而这些信息关乎到选择哪个词来填空,所以无法利用这一点的序列模型将在相关任务上表现不佳。例如,如果要做好命名实体识别(例如,识别“Green”指的是“格林先生”还是绿色),不同长度的上下文范围重要性是相同的。为了获得一些解决问题的灵感,让我们先迂回到概率图模型。
隐马尔可夫模型中的动态规划
这一小节是用来说明动态规划问题的,具体的技术细节对于理解深度学习模型并不重要,但它有助于我们思考为什么要使用深度学习,以及为什么要选择特定的架构。
如果我们想用概率图模型来解决这个问题,可以设计一个隐变量模型:在任意时间步ttt,假设存在某个隐变量hth_tht,通过概率P(xt∣ht)P(x_t \mid h_t)P(xt∣ht)控制我们观测到的xtx_txt。此外,任何ht→ht+1h_t \to h_{t+1}ht→ht+1转移都是由一些状态转移概率P(ht+1∣ht)P(h_{t+1} \mid h_{t})P(ht+1∣ht)给出。这个概率图模型就是一个隐马尔可夫模型(hidden Markov model,HMM),如 :numref:fig_hmm所示。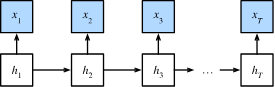 🏷
🏷fig_hmm
因此,对于有TTT个观测值的序列,我们在观测状态和隐状态上具有以下联合概率分布:
P(x1,…,xT,h1,…,hT)=∏t=1TP(ht∣ht−1)P(xt∣ht), where P(h1∣h0)=P(h1).P(x_1, \ldots, x_T, h_1, \ldots, h_T) = \prod_{t=1}^T P(h_t \mid h_{t-1}) P(x_t \mid h_t), \text{ where } P(h_1 \mid h_0) = P(h_1).P(x1,…,xT,h1,…,hT)=t=1∏TP(ht∣ht−1)P(xt∣ht), where P(h1∣h0)=P(h1).
:eqlabel:eq_hmm_jointP
现在,假设我们观测到所有的xix_ixi,除了xjx_jxj,并且我们的目标是计算P(xj∣x−j)P(x_j \mid x_{-j})P(xj∣x−j),
其中x−j=(x1,…,xj−1,xj+1,…,xT)x_{-j} = (x_1, \ldots, x_{j-1}, x_{j+1}, \ldots, x_{T})x−j=(x1,…,xj−1,xj+1,…,xT)。由于P(xj∣x−j)P(x_j \mid x_{-j})P(xj∣x−j)中没有隐变量,因此我们考虑对h1,…,hTh_1, \ldots, h_Th1,…,hT选择构成的所有可能的组合进行求和。如果任何hih_ihi可以接受kkk个不同的值(有限的状态数),这意味着我们需要对kTk^TkT个项求和,
这个任务显然难于登天。幸运的是,有个巧妙的解决方案:动态规划(dynamic programming)。
要了解动态规划的工作方式,我们考虑对隐变量h1,…,hTh_1, \ldots, h_Th1,…,hT的依次求和。根据 :eqref:eq_hmm_jointP,将得出:
P(x1,…,xT)=∑h1,…,hTP(x1,…,xT,h1,…,hT)=∑h1,…,hT∏t=1TP(ht∣ht−1)P(xt∣ht)=∑h2,…,hT[∑h1P(h1)P(x1∣h1)P(h2∣h1)]⏟π2(h2)=defP(x2∣h2)∏t=3TP(ht∣ht−1)P(xt∣ht)=∑h3,…,hT[∑h2π2(h2)P(x2∣h2)P(h3∣h2)]⏟π3(h3)=defP(x3∣h3)∏t=4TP(ht∣ht−1)P(xt∣ht)=…=∑hTπT(hT)P(xT∣hT).\begin{aligned} &P(x_1, \ldots, x_T) \\ =& \sum_{h_1, \ldots, h_T} P(x_1, \ldots, x_T, h_1, \ldots, h_T) \\ =& \sum_{h_1, \ldots, h_T} \prod_{t=1}^T P(h_t \mid h_{t-1}) P(x_t \mid h_t) \\ =& \sum_{h_2, \ldots, h_T} \underbrace{\left[\sum_{h_1} P(h_1) P(x_1 \mid h_1) P(h_2 \mid h_1)\right]}_{\pi_2(h_2) \stackrel{\mathrm{def}}{=}} P(x_2 \mid h_2) \prod_{t=3}^T P(h_t \mid h_{t-1}) P(x_t \mid h_t) \\ =& \sum_{h_3, \ldots, h_T} \underbrace{\left[\sum_{h_2} \pi_2(h_2) P(x_2 \mid h_2) P(h_3 \mid h_2)\right]}_{\pi_3(h_3)\stackrel{\mathrm{def}}{=}} P(x_3 \mid h_3) \prod_{t=4}^T P(h_t \mid h_{t-1}) P(x_t \mid h_t)\\ =& \dots \\ =& \sum_{h_T} \pi_T(h_T) P(x_T \mid h_T). \end{aligned}======P(x1,…,xT)h1,…,hT∑P(x1,…,xT,h1,…,hT)h1,…,hT∑t=1∏TP(ht∣ht−1)P(xt∣ht)h2,…,hT∑π2(h2)=def [h1∑P(h1)P(x1∣h1)P(h2∣h1)]P(x2∣h2)t=3∏TP(ht∣ht−1)P(xt∣ht)h3,…,hT∑π3(h3)=def [h2∑π2(h2)P(x2∣h2)P(h3∣h2)]P(x3∣h3)t=4∏TP(ht∣ht−1)P(xt∣ht)…hT∑πT(hT)P(xT∣hT).
通常,我们将前向递归(forward recursion)写为:
πt+1(ht+1)=∑htπt(ht)P(xt∣ht)P(ht+1∣ht).\pi_{t+1}(h_{t+1}) = \sum_{h_t} \pi_t(h_t) P(x_t \mid h_t) P(h_{t+1} \mid h_t).πt+1(ht+1)=ht∑πt(ht)P(xt∣ht)P(ht+1∣ht).
递归被初始化为π1(h1)=P(h1)\pi_1(h_1) = P(h_1)π1(h1)=P(h1)。符号简化,也可以写成πt+1=f(πt,xt)\pi_{t+1} = f(\pi_t, x_t)πt+1=f(πt,xt),
其中fff是一些可学习的函数。这看起来就像我们在循环神经网络中讨论的隐变量模型中的更新方程。与前向递归一样,我们也可以使用后向递归对同一组隐变量求和。这将得到:
P(x1,…,xT)=∑h1,…,hTP(x1,…,xT,h1,…,hT)=∑h1,…,hT∏t=1T−1P(ht∣ht−1)P(xt∣ht)⋅P(hT∣hT−1)P(xT∣hT)=∑h1,…,hT−1∏t=1T−1P(ht∣ht−1)P(xt∣ht)⋅[∑hTP(hT∣hT−1)P(xT∣hT)]⏟ρT−1(hT−1)=def=∑h1,…,hT−2∏t=1T−2P(ht∣ht−1)P(xt∣ht)⋅[∑hT−1P(hT−1∣hT−2)P(xT−1∣hT−1)ρT−1(hT−1)]⏟ρT−2(hT−2)=def=…=∑h1P(h1)P(x1∣h1)ρ1(h1).\begin{aligned} & P(x_1, \ldots, x_T) \\ =& \sum_{h_1, \ldots, h_T} P(x_1, \ldots, x_T, h_1, \ldots, h_T) \\ =& \sum_{h_1, \ldots, h_T} \prod_{t=1}^{T-1} P(h_t \mid h_{t-1}) P(x_t \mid h_t) \cdot P(h_T \mid h_{T-1}) P(x_T \mid h_T) \\ =& \sum_{h_1, \ldots, h_{T-1}} \prod_{t=1}^{T-1} P(h_t \mid h_{t-1}) P(x_t \mid h_t) \cdot \underbrace{\left[\sum_{h_T} P(h_T \mid h_{T-1}) P(x_T \mid h_T)\right]}_{\rho_{T-1}(h_{T-1})\stackrel{\mathrm{def}}{=}} \\ =& \sum_{h_1, \ldots, h_{T-2}} \prod_{t=1}^{T-2} P(h_t \mid h_{t-1}) P(x_t \mid h_t) \cdot \underbrace{\left[\sum_{h_{T-1}} P(h_{T-1} \mid h_{T-2}) P(x_{T-1} \mid h_{T-1}) \rho_{T-1}(h_{T-1}) \right]}_{\rho_{T-2}(h_{T-2})\stackrel{\mathrm{def}}{=}} \\ =& \ldots \\ =& \sum_{h_1} P(h_1) P(x_1 \mid h_1)\rho_{1}(h_{1}). \end{aligned}======P(x1,…,xT)h1,…,hT∑P(x1,…,xT,h1,…,hT)h1,…,hT∑t=1∏T−1P(ht∣ht−1)P(xt∣ht)⋅P(hT∣hT−1)P(xT∣hT)h1,…,hT−1∑t=1∏T−1P(ht∣ht−1)P(xt∣ht)⋅ρT−1(hT−1)=def [hT∑P(hT∣hT−1)P(xT∣hT)]h1,…,hT−2∑t=1∏T−2P(ht∣ht−1)P(xt∣ht)⋅ρT−2(hT−2)=def hT−1∑P(hT−1∣hT−2)P(xT−1∣hT−1)ρT−1(hT−1) …h1∑P(h1)P(x1∣h1)ρ1(h1).
因此,我们可以将后向递归(backward recursion)写为:
ρt−1(ht−1)=∑htP(ht∣ht−1)P(xt∣ht)ρt(ht),\rho_{t-1}(h_{t-1})= \sum_{h_{t}} P(h_{t} \mid h_{t-1}) P(x_{t} \mid h_{t}) \rho_{t}(h_{t}),ρt−1(ht−1)=ht∑P(ht∣ht−1)P(xt∣ht)ρt(ht),
初始化ρT(hT)=1\rho_T(h_T) = 1ρT(hT)=1。前向和后向递归都允许我们对TTT个隐变量在O(kT)\mathcal{O}(kT)O(kT)
(线性而不是指数)时间内对(h1,…,hT)(h_1, \ldots, h_T)(h1,…,hT)的所有值求和。这是使用图模型进行概率推理的巨大好处之一。它也是通用消息传递算法 :cite:Aji.McEliece.2000的一个非常特殊的例子。
结合前向和后向递归,我们能够计算
P(xj∣x−j)∝∑hjπj(hj)ρj(hj)P(xj∣hj).P(x_j \mid x_{-j}) \propto \sum_{h_j} \pi_j(h_j) \rho_j(h_j) P(x_j \mid h_j).P(xj∣x−j)∝hj∑πj(hj)ρj(hj)P(xj∣hj).
因为符号简化的需要,后向递归也可以写为ρt−1=g(ρt,xt)\rho_{t-1} = g(\rho_t, x_t)ρt−1=g(ρt,xt),其中ggg是一个可以学习的函数。同样,这看起来非常像一个更新方程,只是不像我们在循环神经网络中看到的那样前向运算,而是后向计算。事实上,知道未来数据何时可用对隐马尔可夫模型是有益的。信号处理学家将是否知道未来观测这两种情况区分为内插和外推,有关更多详细信息,请参阅 :cite:Doucet.De-Freitas.Gordon.2001。
双向模型
如果我们希望在循环神经网络中拥有一种机制,使之能够提供与隐马尔可夫模型类似的前瞻能力,我们就需要修改循环神经网络的设计。幸运的是,这在概念上很容易,只需要增加一个“从最后一个词元开始从后向前运行”的循环神经网络,而不是只有一个在前向模式下“从第一个词元开始运行”的循环神经网络。双向循环神经网络(bidirectional RNNs)添加了反向传递信息的隐藏层,以便更灵活地处理此类信息。 :numref:fig_birnn描述了具有单个隐藏层的双向循环神经网络的架构。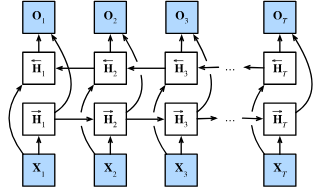
🏷fig_birnn
事实上,这与隐马尔可夫模型中的动态规划的前向和后向递归没有太大区别。其主要区别是,在隐马尔可夫模型中的方程具有特定的统计意义。双向循环神经网络没有这样容易理解的解释,我们只能把它们当作通用的、可学习的函数。这种转变集中体现了现代深度网络的设计原则:首先使用经典统计模型的函数依赖类型,然后将其参数化为通用形式。
定义
双向循环神经网络是由 :cite:Schuster.Paliwal.1997提出的,关于各种架构的详细讨论请参阅 :cite:Graves.Schmidhuber.2005。让我们看看这样一个网络的细节。
对于任意时间步ttt,给定一个小批量的输入数据Xt∈Rn×d\mathbf{X}_t \in \mathbb{R}^{n \times d}Xt∈Rn×d
(样本数nnn,每个示例中的输入数ddd),并且令隐藏层激活函数为ϕ\phiϕ。在双向架构中,我们设该时间步的前向和反向隐状态分别为H→t∈Rn×h\overrightarrow{\mathbf{H}}_t \in \mathbb{R}^{n \times h}Ht∈Rn×h和H←t∈Rn×h\overleftarrow{\mathbf{H}}_t \in \mathbb{R}^{n \times h}Ht∈Rn×h,
其中hhh是隐藏单元的数目。前向和反向隐状态的更新如下:
H→t=ϕ(XtWxh(f)+H→t−1Whh(f)+bh(f)),H←t=ϕ(XtWxh(b)+H←t+1Whh(b)+bh(b)), \begin{aligned} \overrightarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(f)} + \overrightarrow{\mathbf{H}}_{t-1} \mathbf{W}_{hh}^{(f)} + \mathbf{b}_h^{(f)}),\\ \overleftarrow{\mathbf{H}}_t &= \phi(\mathbf{X}_t \mathbf{W}_{xh}^{(b)} + \overleftarrow{\mathbf{H}}_{t+1} \mathbf{W}_{hh}^{(b)} + \mathbf{b}_h^{(b)}), \end{aligned} HtHt=ϕ(XtWxh(f)+Ht−1Whh(f)+bh(f)),=ϕ(XtWxh(b)+Ht+1Whh(b)+bh(b)),
其中,权重Wxh(f)∈Rd×h,Whh(f)∈Rh×h,Wxh(b)∈Rd×h,Whh(b)∈Rh×h\mathbf{W}_{xh}^{(f)} \in \mathbb{R}^{d \times h}, \mathbf{W}_{hh}^{(f)} \in \mathbb{R}^{h \times h}, \mathbf{W}_{xh}^{(b)} \in \mathbb{R}^{d \times h}, \mathbf{W}_{hh}^{(b)} \in \mathbb{R}^{h \times h}Wxh(f)∈Rd×h,Whh(f)∈Rh×h,Wxh(b)∈Rd×h,Whh(b)∈Rh×h
和偏置bh(f)∈R1×h,bh(b)∈R1×h\mathbf{b}_h^{(f)} \in \mathbb{R}^{1 \times h}, \mathbf{b}_h^{(b)} \in \mathbb{R}^{1 \times h}bh(f)∈R1×h,bh(b)∈R1×h都是模型参数。
接下来,将前向隐状态H→t\overrightarrow{\mathbf{H}}_tHt和反向隐状态H←t\overleftarrow{\mathbf{H}}_tHt连接起来,获得需要送入输出层的隐状态Ht∈Rn×2h\mathbf{H}_t \in \mathbb{R}^{n \times 2h}Ht∈Rn×2h。在具有多个隐藏层的深度双向循环神经网络中,该信息作为输入传递到下一个双向层。最后,输出层计算得到的输出为Ot∈Rn×q\mathbf{O}_t \in \mathbb{R}^{n \times q}Ot∈Rn×q(qqq是输出单元的数目):
Ot=HtWhq+bq.\mathbf{O}_t = \mathbf{H}_t \mathbf{W}_{hq} + \mathbf{b}_q.Ot=HtWhq+bq.这里,权重矩阵Whq∈R2h×q\mathbf{W}_{hq} \in \mathbb{R}^{2h \times q}Whq∈R2h×q和偏置bq∈R1×q\mathbf{b}_q \in \mathbb{R}^{1 \times q}bq∈R1×q是输出层的模型参数。事实上,这两个方向可以拥有不同数量的隐藏单元。
模型的计算代价及其应用
双向循环神经网络的一个关键特性是:使用来自序列两端的信息来估计输出。也就是说,我们使用来自过去和未来的观测信息来预测当前的观测。但是在对下一个词元进行预测的情况中,这样的模型并不是我们所需的。因为在预测下一个词元时,我们终究无法知道下一个词元的下文是什么,所以将不会得到很好的精度。具体地说,在训练期间,我们能够利用过去和未来的数据来估计现在空缺的词;而在测试期间,我们只有过去的数据,因此精度将会很差。下面的实验将说明这一点。
另一个严重问题是,双向循环神经网络的计算速度非常慢。其主要原因是网络的前向传播需要在双向层中进行前向和后向递归,并且网络的反向传播还依赖于前向传播的结果。因此,梯度求解将有一个非常长的链。
双向层的使用在实践中非常少,并且仅仅应用于部分场合。例如,填充缺失的单词、词元注释(例如,用于命名实体识别)以及作为序列处理流水线中的一个步骤对序列进行编码(例如,用于机器翻译)。
(双向循环神经网络的错误应用)
由于双向循环神经网络使用了过去的和未来的数据,所以我们不能盲目地将这一语言模型应用于任何预测任务。尽管模型产出的困惑度是合理的,该模型预测未来词元的能力却可能存在严重缺陷。
用下面的示例代码引以为戒,以防在错误的环境中使用它们。
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置“bidirective=True”来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
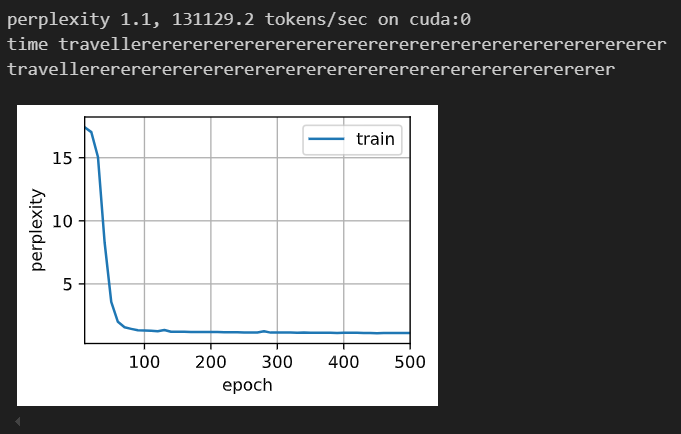
上述结果显然令人瞠目结舌。
小结
- 在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
- 双向循环神经网络与概率图模型中的“前向-后向”算法具有相似性。
- 双向循环神经网络主要用于序列编码和给定双向上下文的观测估计。
- 由于梯度链更长,因此双向循环神经网络的训练代价非常高。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)