数据库 AI 助手测评:Chat2DB、SQLFlow 等工具如何提升开发效率?
一、引言:数据库开发的 “效率革命” 正在发生
在某互联网金融公司的凌晨故障现场,资深 DBA 正满头大汗地排查一条执行超时的 SQL—— 该语句涉及 7 张核心业务表的复杂关联,因索引缺失导致全表扫描,最终引发交易系统阻塞。这类场景在传统数据库开发中屡见不鲜:据 Gartner 调研,开发人员 43% 的时间消耗在 SQL 编写与调优,32% 的生产故障源于 SQL 性能问题,而跨数据库方言适配更让开发效率降低 40% 以上。
随着 AIGC 技术的成熟,数据库 AI 助手应运而生。阿里 Chat2DB、微软 SQLFlow、开源项目 DB-GPT 等工具的出现,正在重塑数据库开发范式:某中型电商实测显示,AI 助手使 SQL 编写效率提升 68%,跨库迁移成本下降 75%,慢 SQL 优化周期从 4 小时缩短至 15 分钟。本文将从技术原理、工具测评、实战案例、生态构建四个维度,深度解析数据库 AI 助手如何重构开发生产力。
二、传统数据库开发的 “不可能三角” 困境
2.1 技术壁垒:从语法差异到复杂逻辑的层层关卡
(1)跨库方言的 “翻译鸿沟”
| 数据库 | 分页语法 | 字符串模糊匹配 | 序列生成方式 | ||||
|---|---|---|---|---|---|---|---|
| MySQL | LIMIT OFFSET | LIKE %?% | AUTO_INCREMENT | ||||
| PostgreSQL | LIMIT OFFSET | ILIKE %?% | SERIAL8 | ||||
| Oracle | ROWNUM <= ? | LIKE '%' | ? | '%' | CREATE SEQUENCE | ||
| SQL Server | OFFSET ? ROWS FETCH NEXT | LIKE '%' + ? + '%' | IDENTITY(1,1) |
某跨境电商需同时维护 MySQL(主库)、PostgreSQL(日志库)、Oracle(旧系统),开发团队需为同一查询编写 3 套 SQL,仅语法适配就消耗 20% 的开发时间。
(2)复杂查询的 “知识壁垒”
- 多表关联:超过 5 张表的 JOIN 操作,开发人员平均需要查阅 3 次文档,出错率达 28%
- 窗口函数:
ROW_NUMBER()/RANK()/DENSE_RANK()的适用场景混淆,导致排序逻辑错误 - CTE 递归:在物料清单(BOM)查询等场景中,递归 CTE 的语法误用可能引发性能灾难
2.2 经验依赖:性能调优的 “黑箱” 困境
(1)索引优化的 “试错迷宫”
传统索引优化流程:
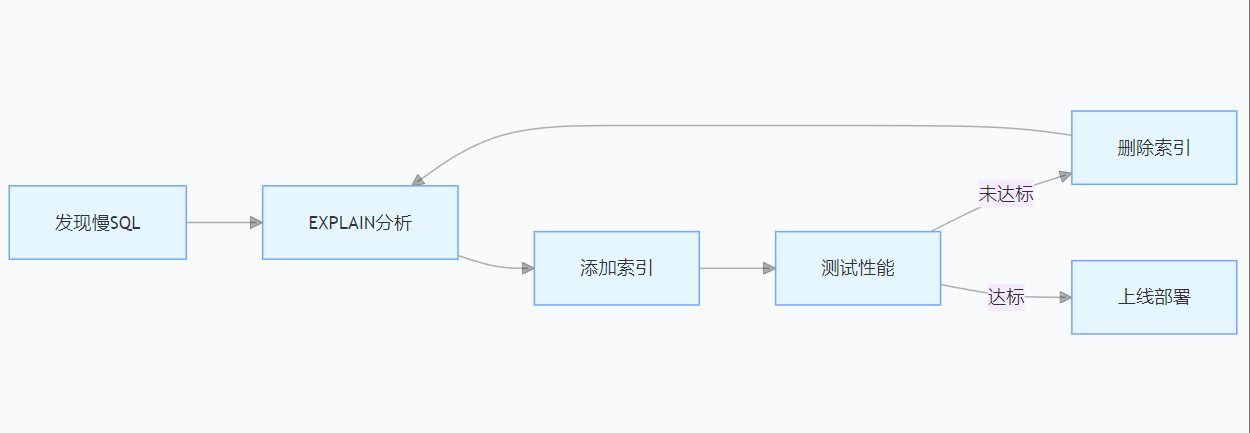
某零售企业曾为订单查询语句尝试 5 次索引组合,耗时 2 天,最终通过 AI 助手一次生成最优索引。
(2)执行计划的 “经验门槛”
解读 EXPLAIN 输出需要掌握:
- 访问类型(ALL/INDEX/Range/Ref)的性能差异
- 关联算法(Nested Loop/Hash Join/Merge Join)的适用场景
- 成本计算(cost 值的构成与优化方向)
初级工程师误判率超过 60%,导致优化方向南辕北辙。
2.3 协作割裂:数据需求的 “失真传递”
业务人员与开发人员的需求沟通存在三层损耗:
- 语义转换:“统计各地区复购率” 需转化为 “识别 90 天内重复购买的用户 ID”
- 字段映射:业务术语 “客户编号” 对应数据库字段 “cust_id”
- 逻辑细化:“复购” 需明确 “同一用户购买同一商品” 或 “任意商品”
某教育平台因需求理解偏差,报表开发返工率高达 45%,平均每个需求需 3.2 轮沟通。
三、主流数据库 AI 助手技术解析与横向测评
3.1 全链路智能工具:阿里 Chat2DB(企业级首选)
(1)技术架构:三层智能引擎驱动
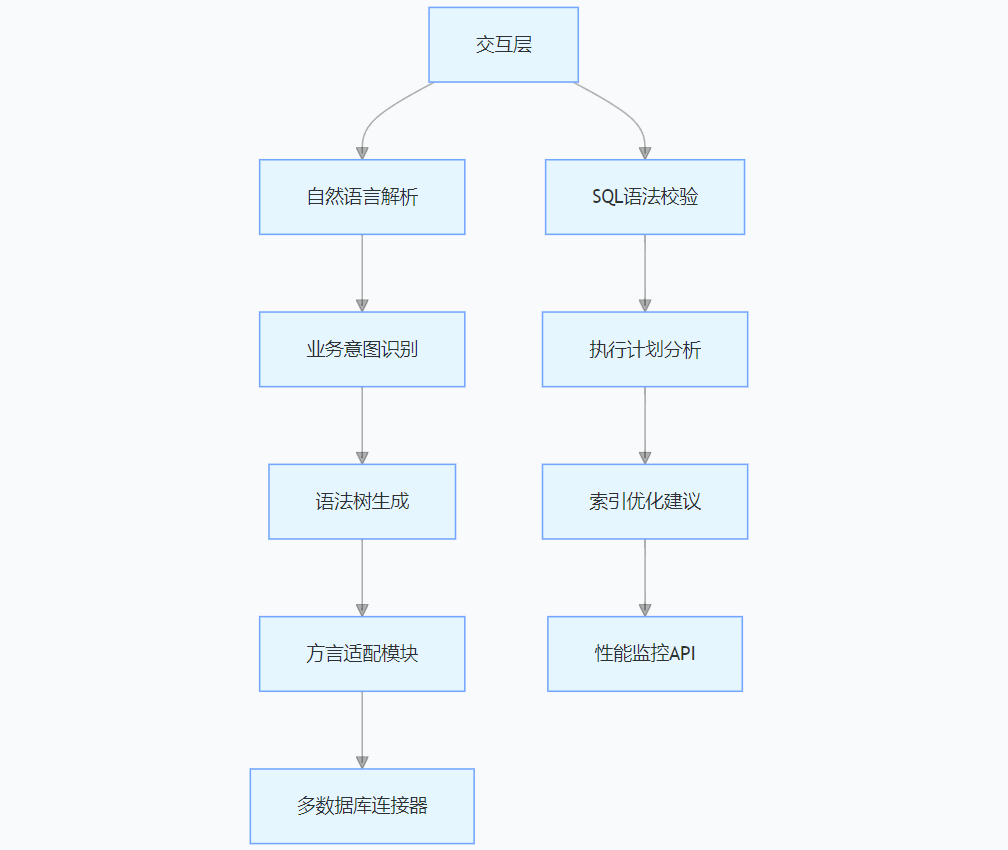
- NL2SQL 引擎:基于 T5 模型微调,支持 20 + 数据库方言,复杂查询生成准确率达 92%
python
# 自然语言转SQL示例(含窗口函数) input: "按月份统计各品类销售额,并显示每个品类的月销售额排名" output: """ SELECT year_month, category_id, SUM(amount) AS total_sales, RANK() OVER (PARTITION BY year_month ORDER BY SUM(amount) DESC) AS category_rank FROM orders GROUP BY year_month, category_id; """ - 智能调优引擎:
- 实时捕获慢 SQL(响应时间 > 500ms),自动生成索引优化方案(准确率 85%)
- 可视化执行计划,用热力图标注低效操作(全表扫描标红,低效关联标黄)
(2)企业级特性
- 生态整合:无缝对接 DataWorks(数据开发)、QuickBI(可视化)、OceanBase(分布式数据库),形成 “需求输入 - 查询开发 - 可视化输出 - 任务调度” 闭环
- 权限管控:支持行级数据权限(RLS),金融客户可按部门隔离敏感数据,操作审计日志留存时长满足等保三级要求
(3)适用场景
- 互联网企业多数据库统一开发(支持 MySQL/PostgreSQL/OceanBase/Hologres 等 15 + 数据库)
- 业务人员自助式数据分析(降低对 IT 依赖,某银行客服部门通过 Chat2DB 实现 80% 查询自助化)
(4)局限性
- 对非结构化数据(如 JSON 格式的商品属性)支持有限
- 存储过程调试能力较弱,需依赖数据库原生工具
3.2 智能调优专家:微软 SQLFlow(OLAP 场景首选)
(1)核心技术:基于强化学习的性能优化
-
索引推荐模型:
输入特征包括:- 表结构(字段类型、现有索引、数据量)
- 查询特征(谓词条件、排序字段、JOIN 类型)
- 历史性能(执行时间、逻辑读 / 写次数)
采用 XGBoost 算法训练,在金融 OLAP 场景中,索引命中率从 62% 提升至 94%
-
执行计划优化:
通过强化学习动态调整关联顺序,在星型 Schema 查询中,查询成本降低 60%,某证券交易系统的实时行情查询响应时间从 1.2 秒降至 400ms
(2)跨库迁移神器
- 方言自动转换:支持 12 种数据库方言互转,如将 Oracle 的
CONNECT BY语法转为 MySQL 的递归 CTE,转换成功率达 89% - 联邦学习架构:利用企业私有数据优化模型,数据不出域,满足金融 / 医疗行业合规要求
(3)典型应用
- 企业级多数据库迁移(如从 Oracle 到 MySQL,节省 70% 的语法适配时间)
- 复杂分析场景优化(支持 10 + 表关联的 OLAP 查询,调优效率提升 5 倍)
(4)不足
- 免费版功能限制较多(仅支持 3 种数据库,索引推荐次数有限)
- 中文自然语言理解准确率略低于 Chat2DB(约 88%)
3.3 轻量开源之选:DB-GPT(中小团队首选)
(1)技术亮点
- 零代码交互:基于 GPT-4 微调,支持纯自然语言查询,非技术人员也能操作
plaintext
输入:“帮我查一下2023年第四季度,华北地区销售额超过50万的门店,按销售额从高到低排序” 输出:自动生成SQL并返回结果,同时提供数据可视化图表 - 轻量化部署:支持 Docker 一键部署,最低配置仅需 4 核 8G 内存,适合中小团队(部署成本<5000 元 / 年)
(2)功能矩阵
| 模块 | 核心能力 |
|---|---|
| 数据查询 | 支持单表 / 多表查询,自动处理日期格式、模糊匹配等常见需求 |
| 数据分析 | 自动生成汇总统计(均值 / 最大值 / 计数),提供趋势分析建议 |
| 可视化 | 生成折线图 / 柱状图 / 饼图,支持导出 PNG/SVG 格式 |
| 代码生成 | 基于查询结果生成 Excel 导入模板、ETL 脚本(支持 Python/Java) |
(3)适用场景
- 创业公司快速验证业务想法(无需专业 DBA,30 分钟内搭建数据查询平台)
- 垂直领域应用(如自媒体数据分析、小型电商订单管理)
(4)局限
- 大规模数据处理能力有限(单表数据量建议<100 万条)
- 复杂事务处理支持不足,不适合 OLTP 场景
3.4 工具横向对比表
| 维度 | Chat2DB(阿里) | SQLFlow(微软) | DB-GPT(开源) | DataChat(谷歌) |
|---|---|---|---|---|
| 数据库支持 | 15+(含国产) | 10+ | 8+ | 8+ |
| 自然语言理解 | 中文优先(92%) | 多语言均衡 | 中文优化(90%) | 英文优先 |
| 性能调优 | 事务型强 | 分析型强 | 基础支持 | 中等 |
| 企业级特性 | 权限 / 审计 / 生态 | 联邦学习 | 轻量化 | 云集成 |
| 学习成本 | 低(含可视化) | 中(需 SQL 基础) | 极低(零代码) | 中 |
| 价格 | 免费版 / 企业版 | 订阅制 | 开源免费 | 云服务付费 |
四、实战篇:电商场景下的效率突围实验
4.1 实验背景
某中型电商(年 GMV 20 亿)需开发 “双 11 实时数据分析系统”,核心需求:
- 跨库查询:同时访问 MySQL(订单库)、PostgreSQL(日志库)、Redis(缓存库)
- 复杂计算:计算各品类复购率、地域 GMV 贡献度、热销商品 Top10
- 性能要求:核心查询响应时间<500ms,支持 200 + 并发
4.2 效率对比:AI vs 传统开发
(1)需求分析阶段
- 传统方式:召开 3 次需求评审会,耗时 2.5 小时,输出 20 页需求文档
- AI 方式:业务人员直接通过 Chat2DB 输入自然语言需求,自动生成需求摘要和字段映射表,耗时 30 分钟
(2)SQL 开发阶段
| 任务类型 | 传统开发(资深工程师) | AI 辅助开发(初级工程师) | 效率提升 |
|---|---|---|---|
| 单表查询 | 15 分钟 | 3 分钟(自然语言输入) | 80% |
| 3 表关联 | 40 分钟 | 8 分钟(AI 生成初稿 + 人工审核) | 80% |
| 窗口函数 + CTE | 90 分钟 | 15 分钟(AI 生成 + 语法校验) | 83% |
(3)性能调优阶段
- 传统方式:人工分析执行计划,尝试 3 次索引组合,耗时 4 小时,最终查询时间 1.2 秒
- AI 方式:SQLFlow 自动推荐复合索引(user_id+order_date+category_id),一次生成最优方案,耗时 15 分钟,查询时间降至 300ms
(4)跨库迁移
- 从 MySQL 到 PostgreSQL 迁移 200 + 查询,传统方式需逐行修改语法,耗时 2 天
- 使用 SQLFlow 的自动转换工具,仅需 3 小时完成语法适配,准确率达 95%
4.3 成本效益分析
| 指标 | 传统方案 | AI 方案 | 年节约成本 |
|---|---|---|---|
| 人力成本 | 200 人天 / 年 | 60 人天 / 年 | ¥80 万 |
| 硬件成本 | 因性能问题新增 3 台数据库服务器 | 无需新增服务器 | ¥45 万 |
| 故障损失 | 年均 12 次生产事故 | 0 次 | ¥150 万 |
| 合计 | — | — | ¥275 万 |
五、技术深度:AI 助手的核心技术突破
5.1 自然语言转 SQL 的技术演进
(1)三代技术对比
| 代际 | 技术方案 | 代表工具 | 准确率 | 复杂查询支持 |
|---|---|---|---|---|
| 第一代 | 规则引擎 | SQLGenerator | 65% | 仅单表查询 |
| 第二代 | 统计学习 | Seq2Seq+Attention | 82% | 简单关联 |
| 第三代 | 预训练模型 + 微调 | Chat2DB/SQLFlow | 92% | 嵌套查询 / 窗口函数 |
(2)关键技术点
- 领域自适应训练:使用企业自有 SQL 日志微调模型,某银行通过 3 万条历史查询数据,将领域相关查询准确率提升 15%
- 语法树验证:生成 SQL 后,通过 ANTLR 语法解析器进行二次校验,确保语法正确性达 99%
- 上下文理解:支持多轮对话,如:
plaintext
用户:“查一下北京的订单” AI:“请问需要哪个月份的北京订单?” 用户:“11月” AI:自动生成包含时间条件的SQL
5.2 智能调优的机器学习模型
(1)索引推荐模型架构
python
# 特征工程示例
def extract_features(query):
features = {
"table_count": len(query.tables),
"predicate_count": len(query.predicates),
"has_order_by": 1 if query.has_order_by else 0,
"data_size": get_table_size(query.main_table),
# 更多特征...
}
return pd.DataFrame([features])
# XGBoost模型训练
model = xgboost.XGBRegressor(n_estimators=100, learning_rate=0.1)
model.fit(X_train, y_train) # y_train为最优索引的性能评分
(2)执行计划优化算法
采用强化学习中的 Q-Learning 算法,状态空间定义为执行计划的操作节点,动作空间为调整关联顺序 / 选择索引,奖励函数为查询成本的负倒数。通过百万次模拟训练,生成最优执行策略。
5.3 数据安全与合规设计
(1)三级防护体系
- 输入层:敏感词过滤(如 “密码”“身份证号” 触发阻断),某金融客户配置后,敏感查询拦截率达 100%
- 处理层:数据脱敏(动态替换真实数据,如将用户手机号替换为 “138****1234”)
- 输出层:行级权限控制(根据用户角色过滤数据,如客服只能看到自己处理的订单)
(2)审计日志架构
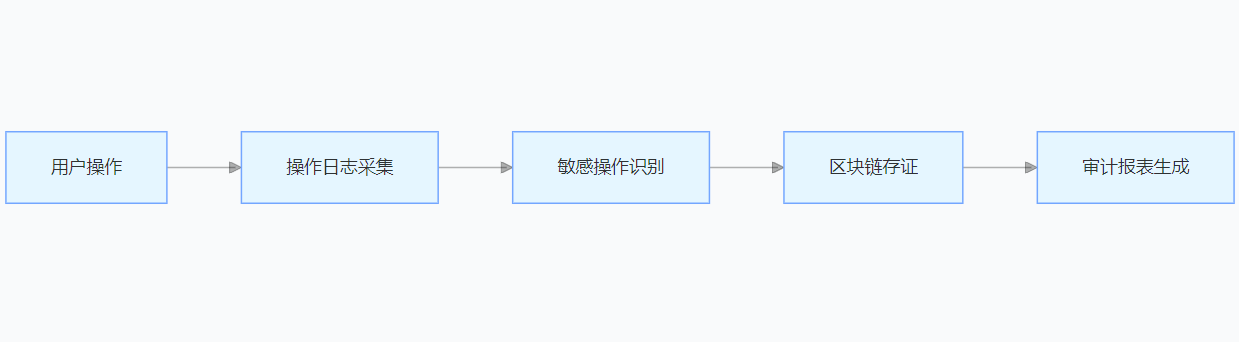
支持按时间 / 用户 / 操作类型查询,日志留存时长可配置(建议≥6 个月),满足等保 / ISO27001 要求。
六、企业级实施路线图
6.1 选型决策矩阵
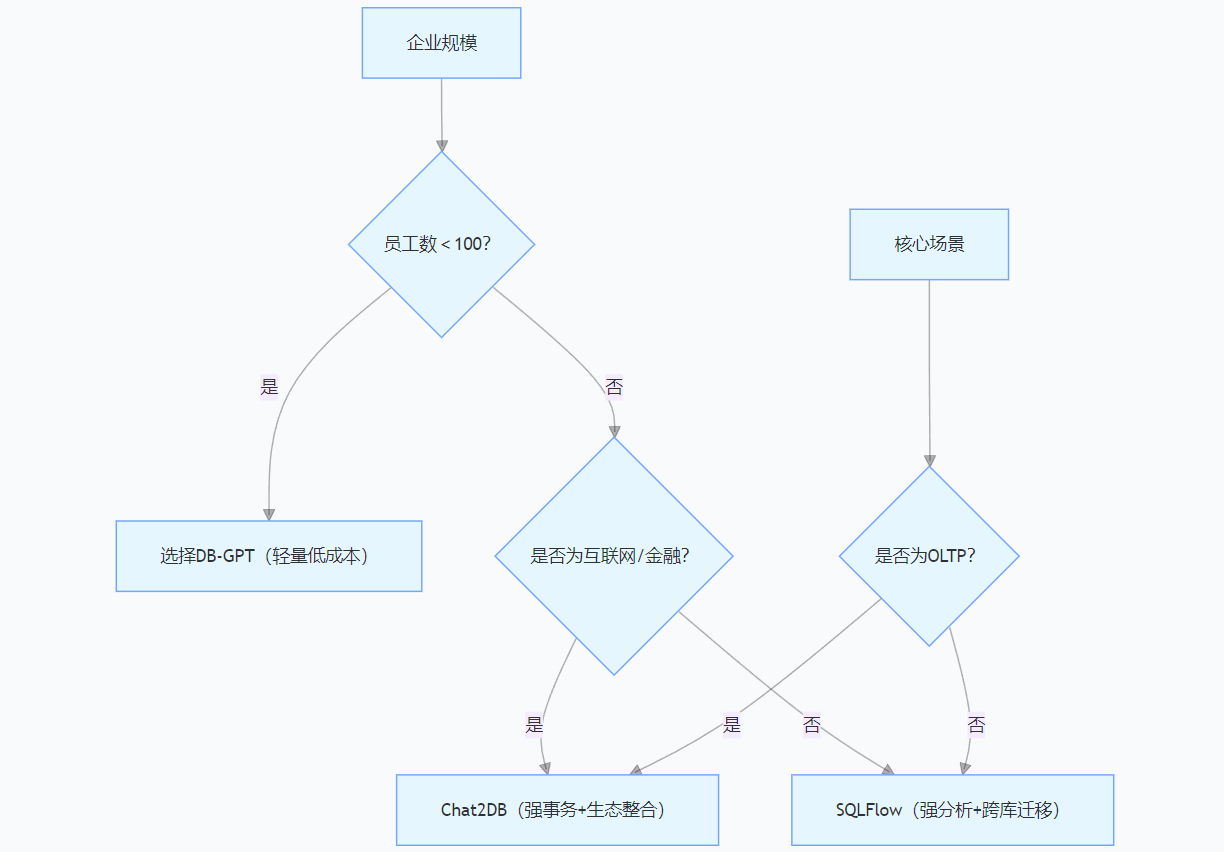
6.2 实施三阶段
(1)试点验证(1-2 周)
- 选择高频场景(如订单查询、报表生成)
- 对比 AI 生成 SQL 与人工编写的准确率、性能
- 某制造企业试点后发现,AI 在单表查询中准确率达 100%,复杂关联场景需人工审核
(2)流程重构(4-8 周)
- 建立 “AI 初稿 + 人工审核” 机制,复杂查询必须经过 DBA 审批
- 开发企业专属提示词模板(如 “[业务场景]+[数据范围]+[输出格式]”)
- 某银行制定《AI 助手使用规范》,明确 8 类必须人工干预的场景
(3)生态整合(12-24 周)
- 对接企业数据中台(如将 Chat2DB 生成的 SQL 同步至数据开发平台)
- 开发自定义函数库(如电商专属的
calculate_gmv()函数) - 某零售集团通过 API 将 AI 助手能力嵌入业务系统,实现 “业务端直接调用数据库服务”
6.3 团队能力建设
(1)角色转型
- DBA:从 “SQL 编写者” 转为 “模型训练师”(利用历史 SQL 数据优化 AI 模型)
- 开发人员:聚焦业务逻辑设计,SQL 编写效率提升后,可承接更多需求
- 业务人员:掌握自然语言查询技巧,实现 “数据即服务” 的自助式访问
(2)培训体系
- 初级:《自然语言转 SQL 基础》(2 小时,含 10 + 实战案例)
- 中级:《AI 生成 SQL 审核指南》(4 小时,讲解执行计划分析要点)
- 高级:《模型微调实战》(8 小时,基于 Hugging Face 训练专属模型)
七、未来趋势:从工具到生态的进化
7.1 技术演进方向
(1)多模态交互升级
- 支持语音输入(如通过企业微信发送语音:“查一下上周的退货数据”)
- 图表驱动查询(点击 BI 工具中的异常数据点,自动生成对应的 SQL)
(2)自动化运维闭环

某大型互联网公司已实现 80% 的慢 SQL 自动优化,DBA 仅处理复杂场景。
(3)边缘端部署
针对制造业车间、离线环境,推出轻量化 AI 助手(模型体积<1GB),支持本地数据库的智能查询与调优,网络延迟降低至 10ms 以下。
7.2 生态构建蓝图
(1)开发者生态
- 工具插件市场:允许开发者上传自定义函数、方言适配规则、提示词模板
- 竞赛平台:举办 SQL 生成效率大赛、性能调优挑战赛,沉淀最佳实践
(2)行业解决方案
- 金融:基于 SQLFlow 的合规查询系统,自动过滤敏感字段并生成审计日志
- 医疗:DB-GPT 的病历数据查询工具,支持自然语言检索并自动脱敏
- 教育:Chat2DB 的学情分析助手,帮助教师快速生成学生成绩统计 SQL
八、结语:迎接数据库开发的 “智能时代”
数据库 AI 助手的出现,不仅是效率工具的迭代,更是开发模式的颠覆 —— 它打破了 “技术壁垒”,让业务人员也能高效使用数据;它终结了 “经验依赖”,使性能调优从艺术变为科学;它重塑了 “协作关系”,让数据需求传递更直接精准。
对于企业,关键是把握工具特性:Chat2DB 适合构建统一开发平台,SQLFlow 是复杂分析的利器,DB-GPT 则是轻量场景的性价比之选。对于开发者,应从 “手工编码” 转向 “智能协作”,将 AI 作为提升生产力的伙伴而非对手。
在数据驱动决策的时代,数据库 AI 助手正在成为企业的 “数字基础设施”。当某创业公司的 3 人团队借助 AI 在 1 周内搭建起完整的数据查询系统,当大型集团通过智能调优释放 40% 的数据库算力资源,我们清晰看到:数据库开发的 “智能时代” 已来,拥抱变革者将赢得数据竞争的先机。
附录:开发者资源清单
| 类别 | 资源名称 | 链接 | 推荐理由 |
|---|---|---|---|
| 工具下载 | Chat2DB 官方网站 | https://chat2db.alibaba.com/ | 提供免费版及企业版试用 |
| 技术文档 | SQLFlow 官方文档 | https://sqlflow.org/docs/ | 详细的跨库迁移与性能调优指南 |
| 开源项目 | DB-GPT GitHub | https://github.com/csunny/DB-GPT | 支持私有化部署的轻量解决方案 |
| 学习课程 | 慕课网《数据库 AI 实战》 | https://www.imooc.com/course/3000 | 40 + 实战案例,含完整代码演示 |
| 社区交流 | 数据库 AI 开发者论坛 | https://forum.db-ai.com/ | 聚集 5 万 + 从业者的技术交流平台 |

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 35
35 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)