大模型训练,DP/PP/TP/SP/EP到底怎么选?
最近春招和实习已开启了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。

大模型训练,DP/PP/TP/SP/EP到底是什么?
本文对主流大模型并行训练方式进行了简单介绍,并分析了其通信量以及编排方式。
01
并行策略
目前主流的并行策略可以分为 5 种:
-
DP 数据并行
-
PP 流水线并行
-
TP 张量并行
-
SP 序列并行
-
EP 专家并行
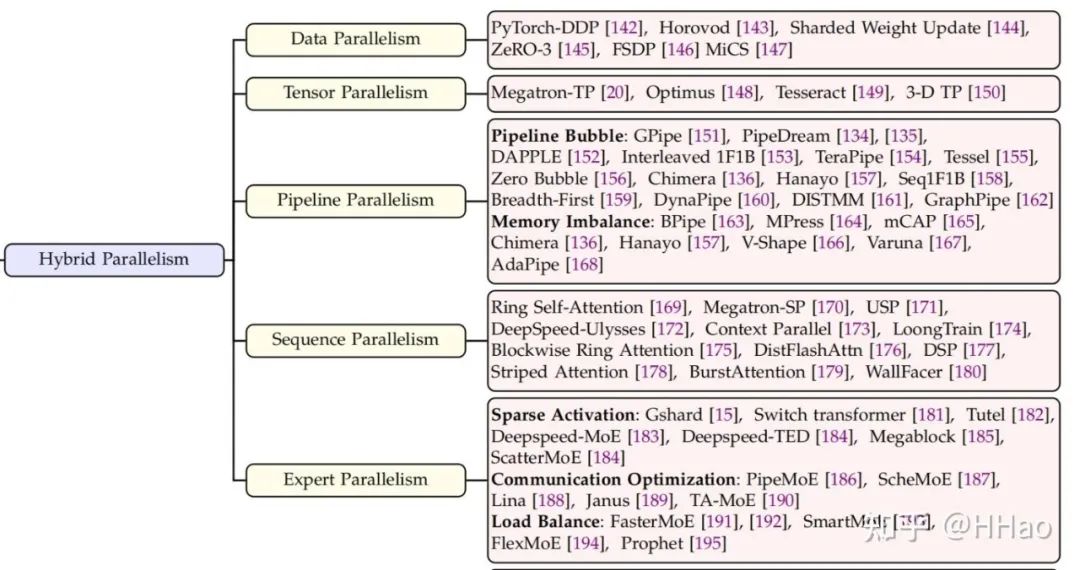
Efficient training of large language models on distributed infrastructures: a survey 中的 overview
02
前提
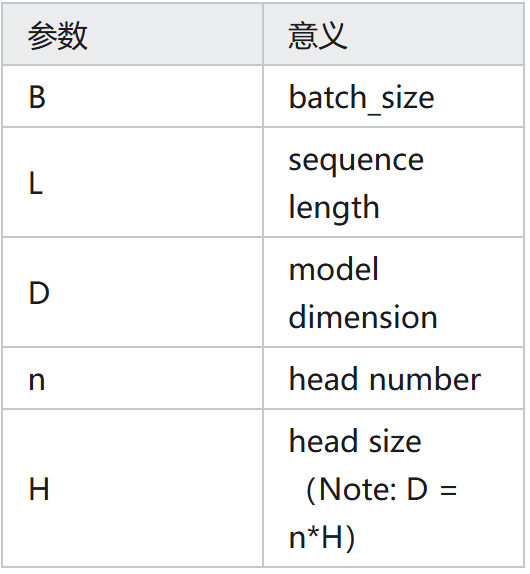
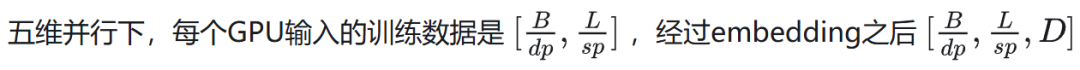
03
数据并行 (Data parallelism)

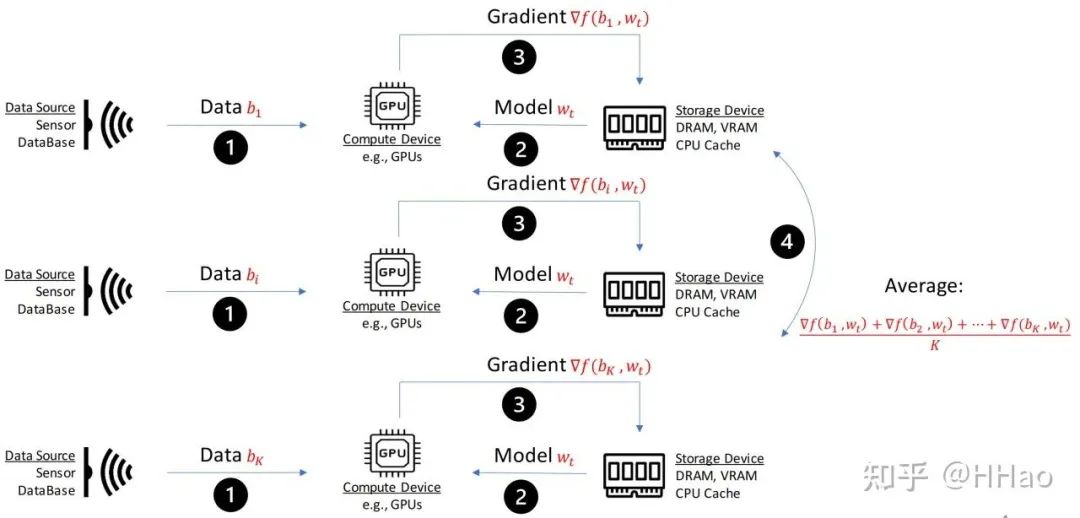
3.1 通信量

3.2 通信模式
Backward:Allreduce
3.3 流量编排
DP 通信次数较少,总通信量相对较低,且可以与反向计算 Overlap (ZeRO/FSDP 等实现方式),通常编排到 Spine/Inter-pod switch (clos 架构) 或 leaf switch (multi-rail 架构)。
04
流水线并行(Pipeline parallelism)
对模型进行切分的一种方式,将模型按照 transformer layer 进行切分。
如 Meta LLaMa3 中 126 transformer 层,被切到 16 个 PP 组中,第一个和最后一个 PP 组中为 7 层(第一个 PP 要做 embedding/位置编码等,最后一个 PP 组需要做 loss 计算),其余 8 层。
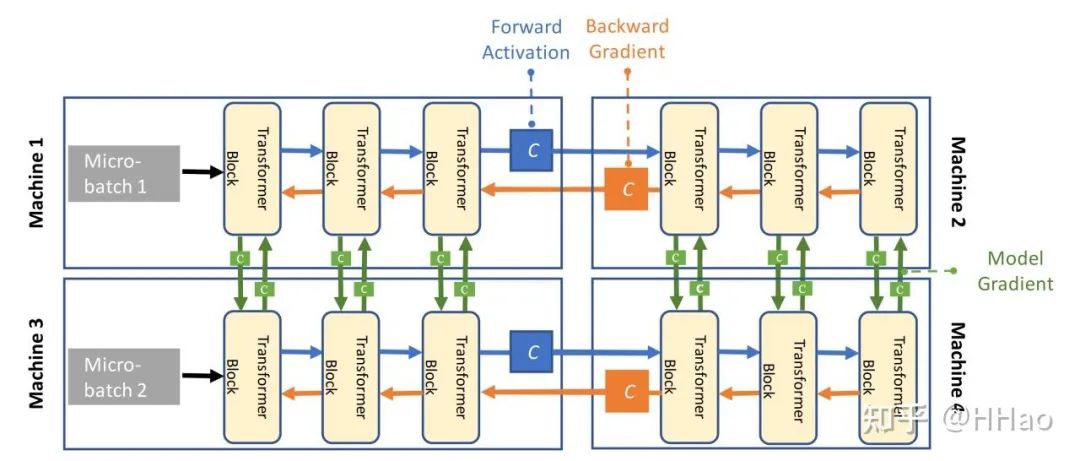
采自 hkust 课程 PPT
4.1 通信量

4.2 通信模式
fwd/bwd:P2P
4.3 流量编排
PP 通信次数少,通信量低,且可以通过多级流水分 micro batch 的方式和前向计算 Overlap。
一般被编排到 spine switch (clos/muti-rail)。工业界实现中,相当 DP 流量,编排更内层。
05
张量并行(Tensor parallelism)
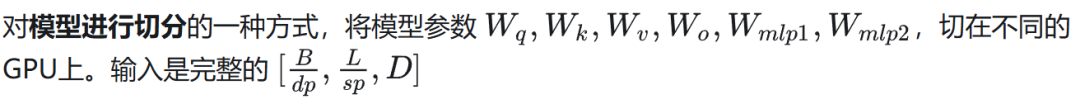
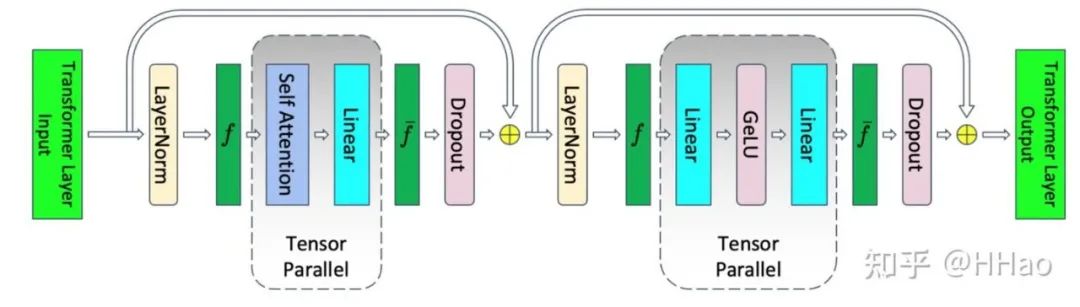
Megatron 中 TP 的实现
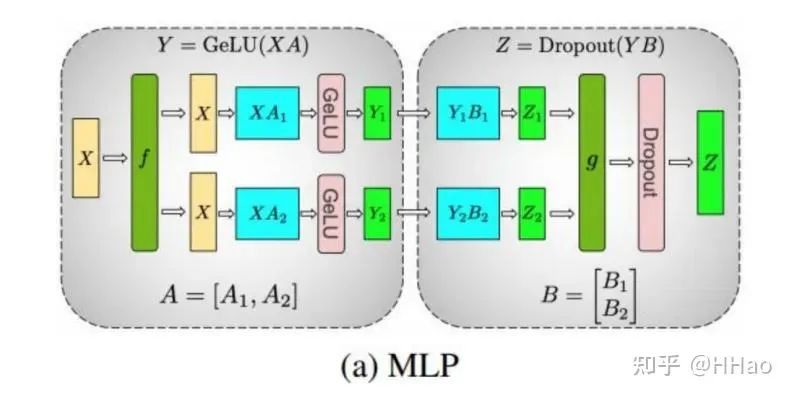
对 MLP 进行切分,第一个 MLP A 纵切,第二个 MLP B 横切
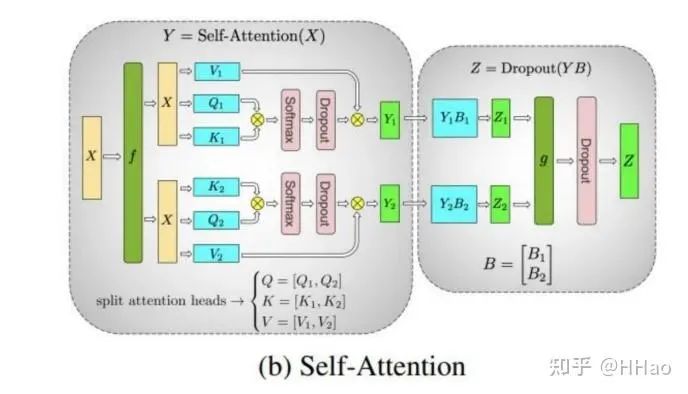
对 Attention 中的多头进行切分,将不同的头切分到不同的 GPU 上
5.1 通信量
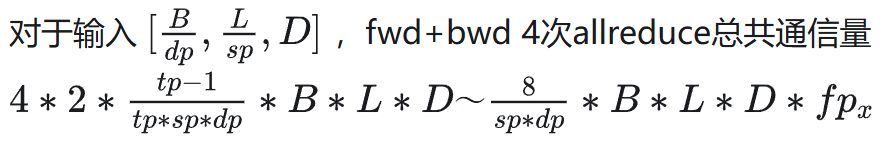
5.2 通信模式
fwd/bwd: Allreduce
5.3 流量编排
通信频繁,总通信量大,编排在 High bandwidth domain,比如单 Server 内 Nvlink。
06
序列并行 (Sequence parallelism)
6.1 TP-SP Megatron
注意到在 TP 中,Layernorm 层和 Droupout 层没有被切分并行,因为其在 D 维度上存在依赖,而L维度上不存在依赖,故考虑将数据在 L 维度进行切分后并行,并行度 SP=TP。
该方式更像是一种 TP 的拓展实现,而不是传统意义上的拆分 L 维度来计算 attention。
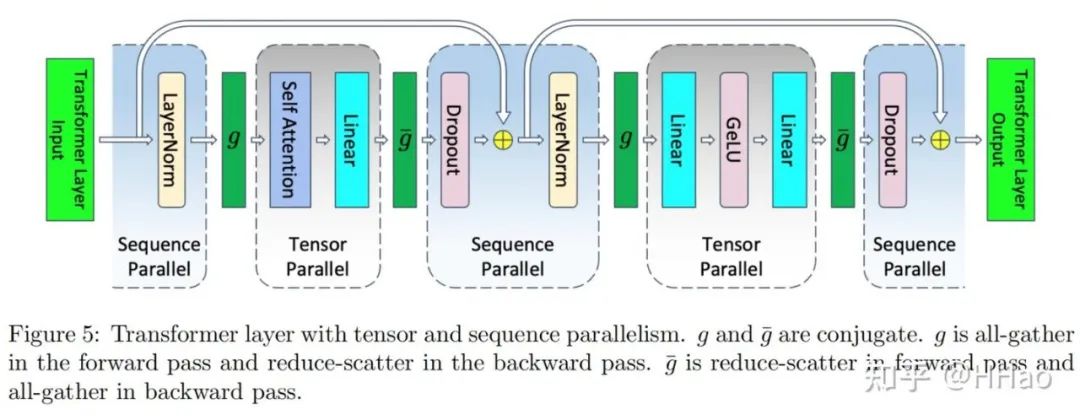
Megatron 中 TP-sp 的实现
6.1.1 通信量
Megatron 中为了减少单 GPU 存储消耗,选择反向计算的时候重新计算完整输入而不是存,多引入 2 次 allgather。

USP: A Unified Sequence Parallelism Approach forLong Context Generative AI 中的通信量分析
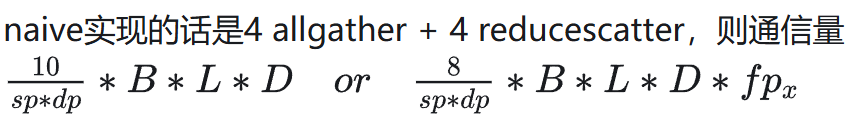
6.1.2 通信模式
all-gather 和 reduce-scatter
6.1.3 流量编排
和 TP 一致,Server 内 Nvlink 优先,TP 组即 SP 组。
6.2 Ulysses Deepspeed

总体思想:每个 GPU 上全部 head 的部分 QKV —all2all→每个 GPU 上部分 head 的完整 QKV;多 GPU 分布式 attention 计算→每个 GPU 算一部分 head 的 attention。
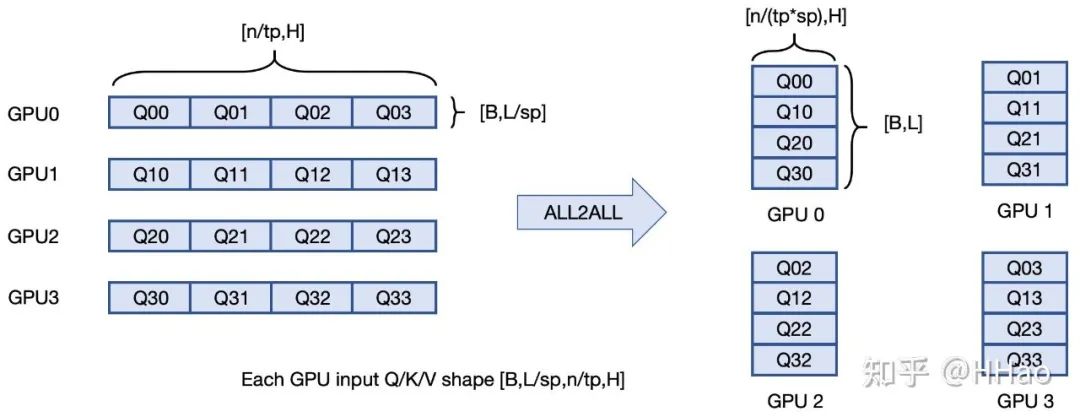
比较抽象,all2all 发送过程
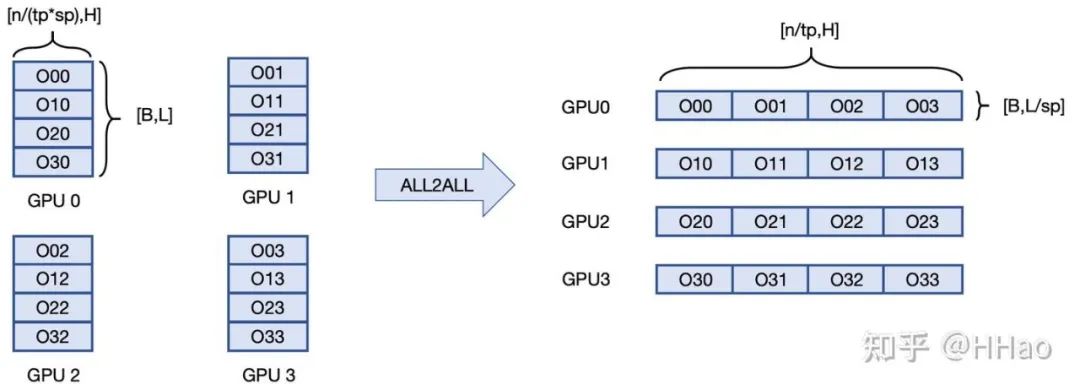
all2all 发回
6.2.1 通信量
QKVO 前向 4 次 all2all,dQ dK dV dO 反向 4 次 all2all。
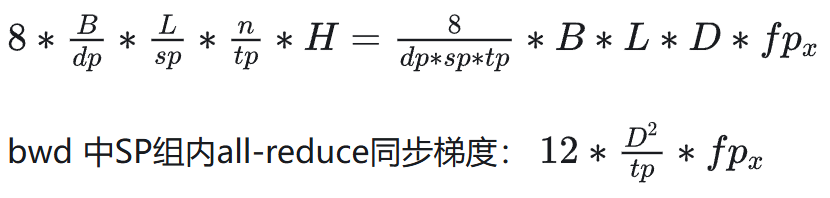
6.2.2 通信模式
fwd+bwd:all2all (qkvo),Allreduce 同步梯度。
6.2.3 流量编排
通信次数多,单次流量小,all2all 需要高 bisection 带宽,尽量编排到 HBD,不够就 leaf/spine switch。
6.3 Context Parallelism Megatron

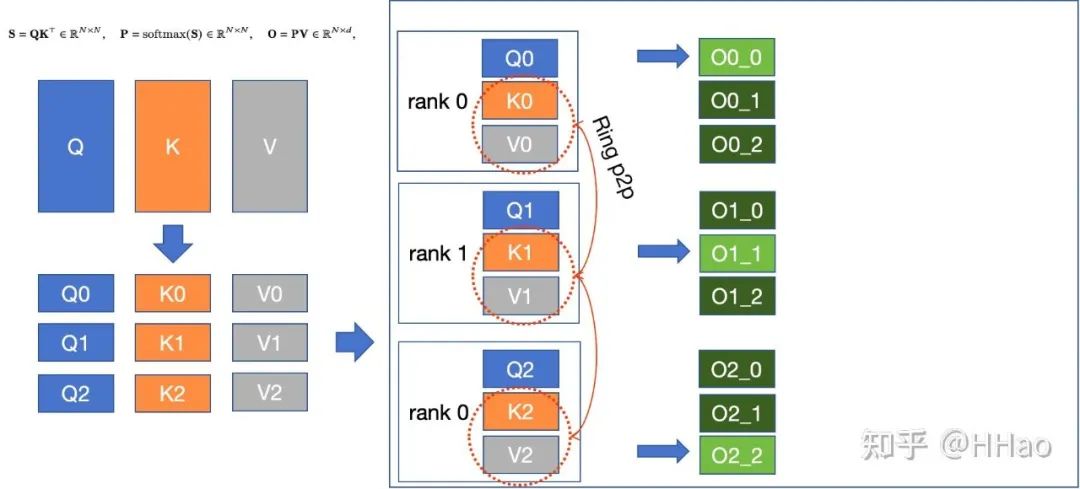
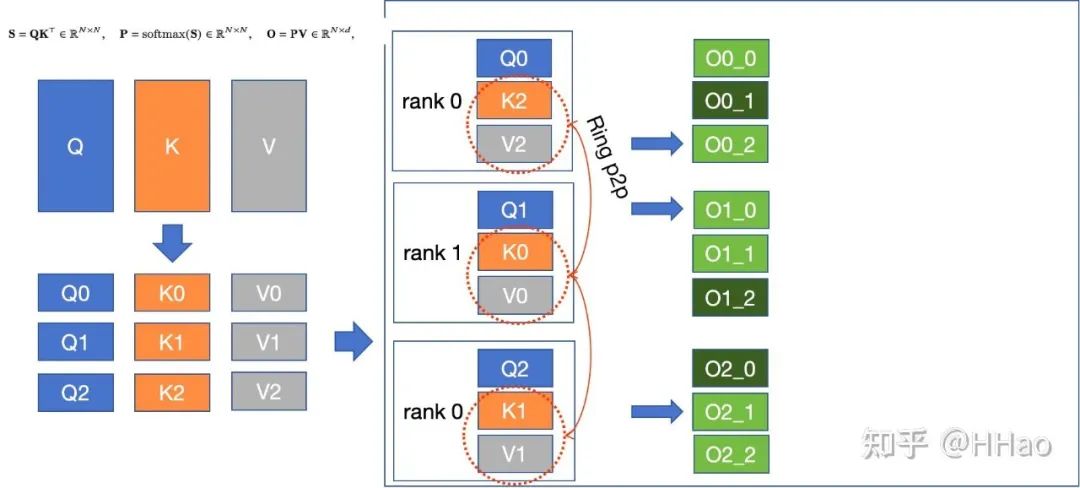
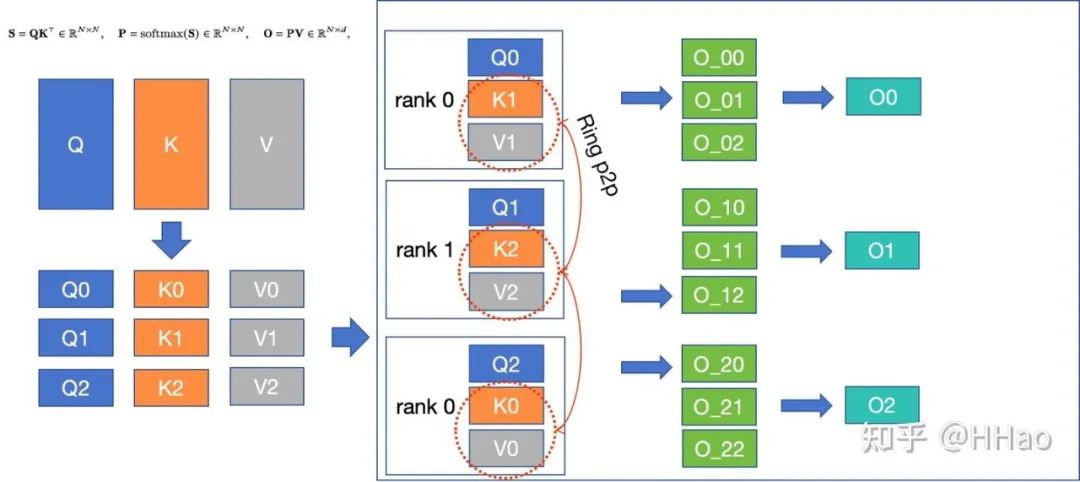
6.3.1 通信量
fwd+bwd 2(sp-1)次 P2P,每次传 kv/dk dv,通信量。

6.3.2 通信模式
P2P 和 Allreduce。
6.3.3 流量编排
通信次数多,单次流量中,最好编排到 HBD,不够就 leaf/spine switch。
07
专家并行(Expert parallelism)
针对 MoE 模型训练的特有的并行方式,对模型进行切分。
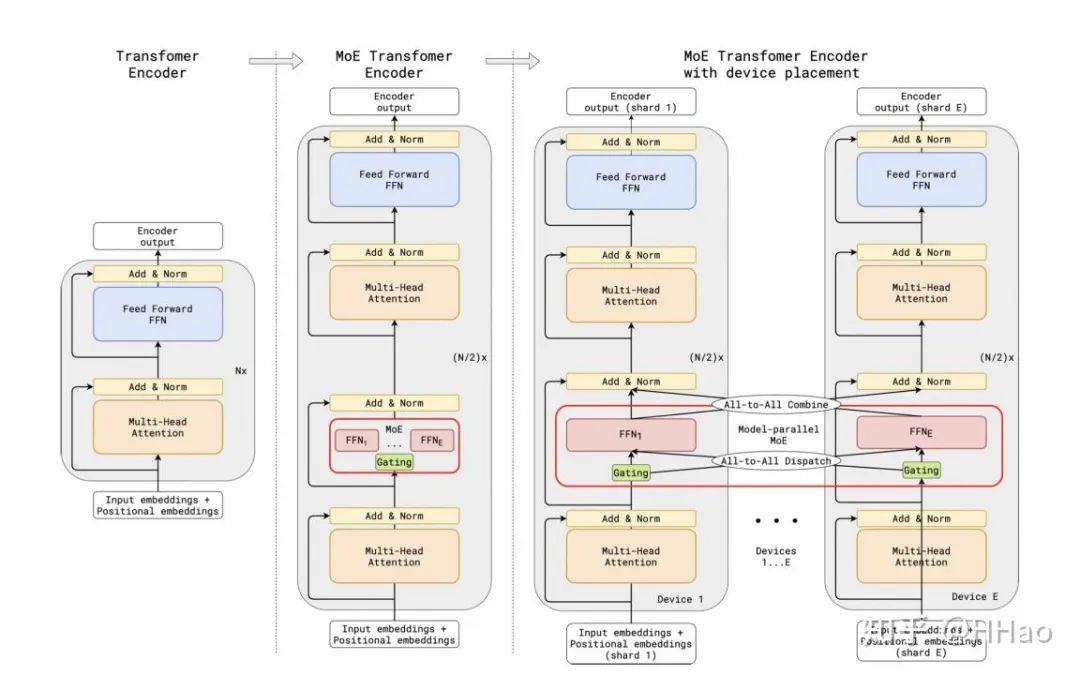
6.4.1 通信量
假设 EP 组内负载均衡能够做到极致,token 均分到每一个 EP 组 rank。前后向分别 2 次 all2all。
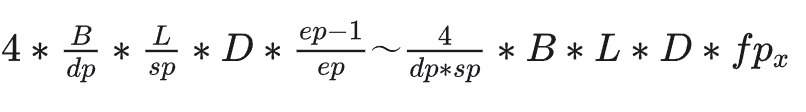
EP 和 TP 一起使用时会存在冗余的通信,可以使用 Group-wise 的 all2all 优化方式,将 TP 组内的 all2all 省略,转化成 TP 组内的 all gather。
6.4.2 通信模式
fwd/bwd 2 次 all2all。
6.4.3 流量编排
前后向时每专家层 2 次,需要 all2all,要求 bisetion 带宽,但量 group-wise 后相对 TP/SP 少,无 SP 时最好能编排到 HBD,有 SP 时可以编排到 leaf/spine switch。
08
总结
以华为 UB-mesh 论文中的数据为例子,该表的数据是来自于华为训练一个 2T 参数的 MoE 模型的流量统计(猜测此 2T 模型专家数较少,可能类似于 GPT4-2T 的模型,只有 16 专家,导致 EP 小,TP 大)。
我们根据此表可以得知华为的编排是:TP>SP>EP>PP>DP。
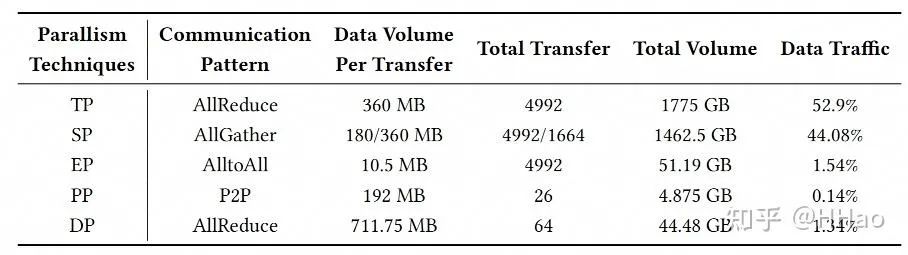
UB-Mesh 训练 MoE-2T 的流量分析
以上分析都是比较笼统且粗略的计算,具体模型还需具体分析,实现中对通信的优化/overlap 方式会导致通信量/编排存在变化。
比如 Deepseek v3 的 EP 实现中是 FP8 Dispatch + BF16 Combine,此时通信量计算不能一概而论。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)