强化学习算法
并且采样的数据可以多次用来训练我们的policy网络,这样就解决了on policy训练效率太低的问题,但是有一点限制,就是这个参考策略不能和训练策略在同意情况下给出各种动作概率分布的差别太大。之前我们讲的每一步action的return,都累加它后面的reward,并且逐步衰减,但是这也是通过具体的采样得到的值。一个动作是可以对接下来的reward产生影响,但是它可能只影响接下来的几步,而且影响
强化学习的基础概念

强化学习概念如下:
一、环境enviroment,它有自己的规则
二、智能体agent,它观察环境,根据策略做出动作
三、动作action,对于超级玛丽来说,动作只能是向左、向右以及跳三个动作。
四、状态state,智能体根据当前的状态来做出决策。state里还有一个概念叫视野observation,因为有的agent视野并不是全视野,他只能看到整个游戏状态的一部分。但是在超级玛丽这个游戏里,我们认为state就等于observation。
五、奖励reward,当agent做出一个动作后·,环境给agent的奖励或者惩罚。比如当玛丽吃到一个金币,给10分。被怪物打死,扣100分。agent会尽可能让得到的reward之和最大。reward定义的好坏,很大程度上会影响模型的训练。
六、动作的选择空间Action Scope,比如{left,up,right}
七、Policy策略函数,输入为state,输出action的概率分布。一般用π表示
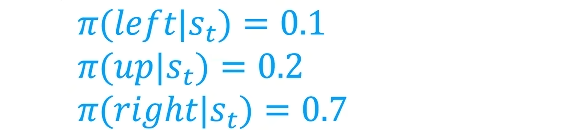
一般不是执行策略最高的策略,而是根据概率分布进行采样,原因有两点:
1、训练的时候让模型要探索各种动作的可能性,这样才能学到更好的策略
2、推理时让输出多样性也是非常有价值的,比如剪刀石头布,不能每次都是同样的动作
八、Trajectory轨迹:用τ表示,一连串状态和动作的序列。也被叫做episode或者ruleout。
比如游戏的初始状态为,agent做出动作
切换到,agent做出动作

九、回报Return:从当前时间点到游戏结束时的Reward累积和。
期望

期望:每个可能结果的概率与其结果值的乘积之和。
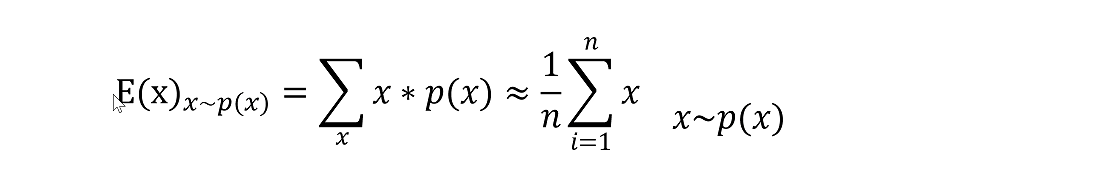
公式的意思:
表示随机变量
的期望值
是随机变量
取特定值
的概率
该公式表示期望值是所有可能值与其对应概率
的乘积之和。
强化学习的目标
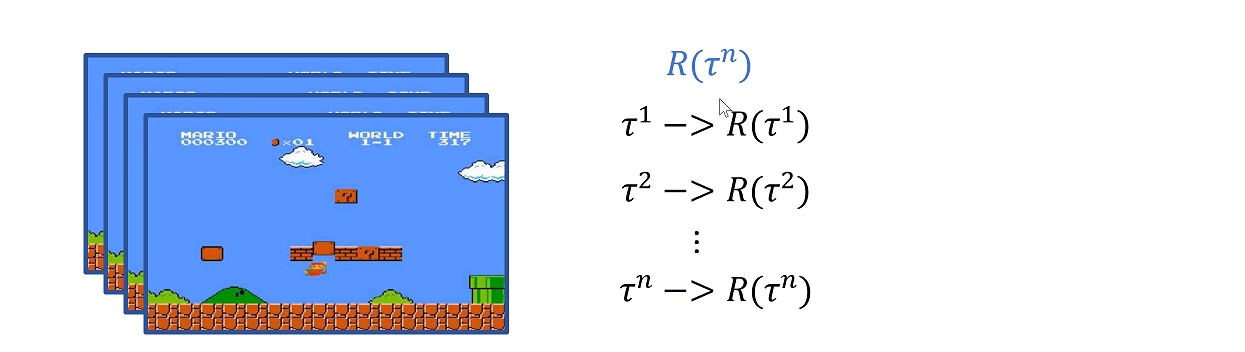
目标:训练一个Policy神经网络π,在所有状态s下,给出相应的Action,得到Reteurn的期望最大。
目标:训练一个Policy神经网络π,在所有的Trajectory中,得到Return的期望最大。
我们用公式来表示这个期望:
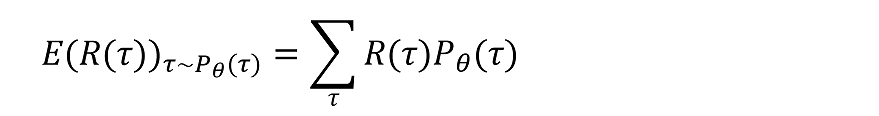
轨迹trajectory即τ,服从分布,
是我们要训练的策略网络里面的参数。
游戏的trajectory是由我们决策网络决定的,我们期望在神经网络参数的作用下,τ获得的return的期望尽可能大。按照期望的定义,它等于所有的τ获得的retrun乘以τ的概率的累加。
怎么让这个期望尽可能的大?
可以用梯度上升的办法,我们先计算梯度,我们只能改变神经网络的参数,不能改变环境给的reward。
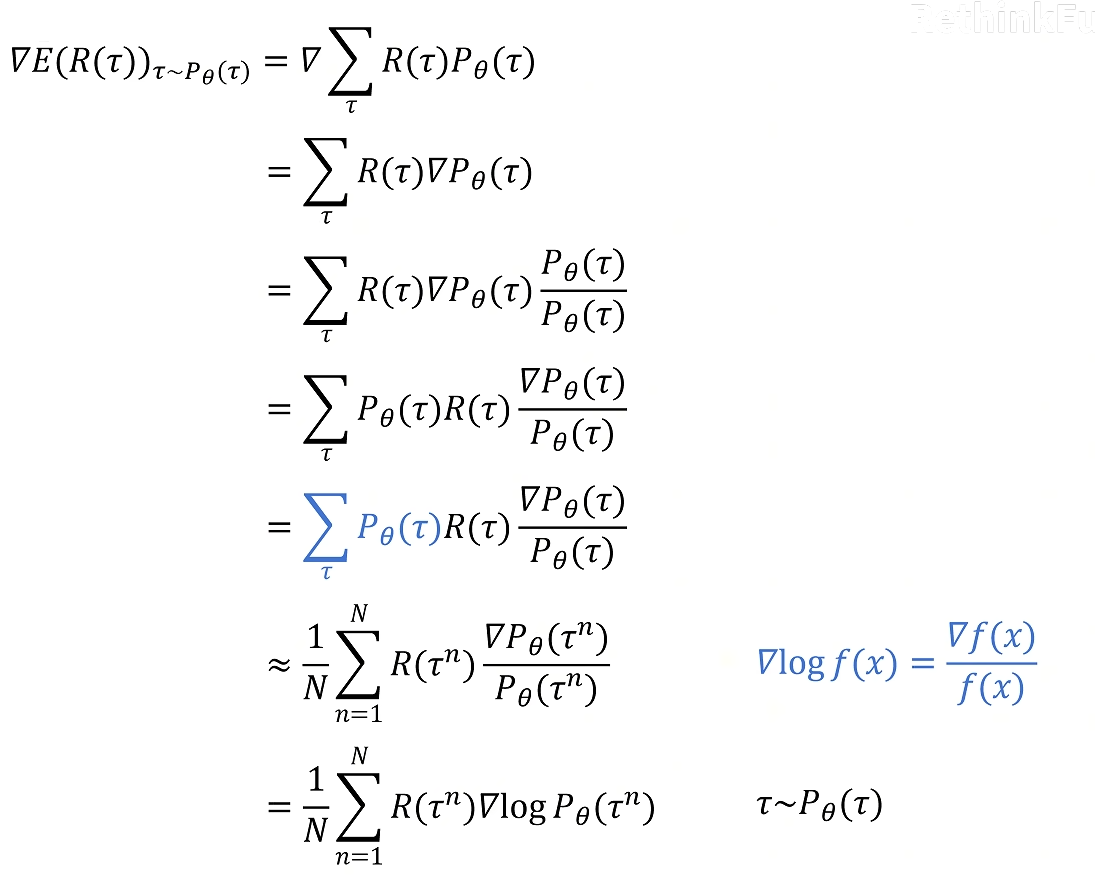
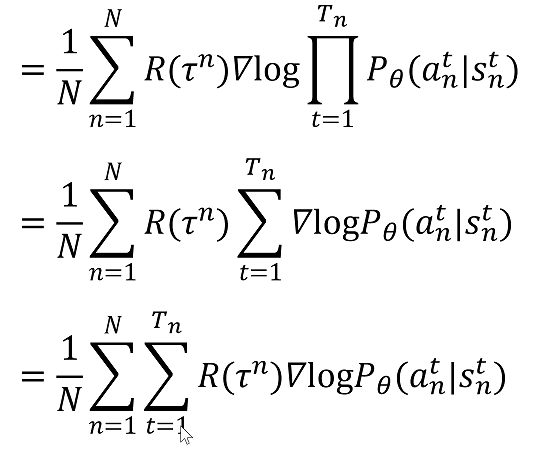
整理后的目标函数表达式如下:
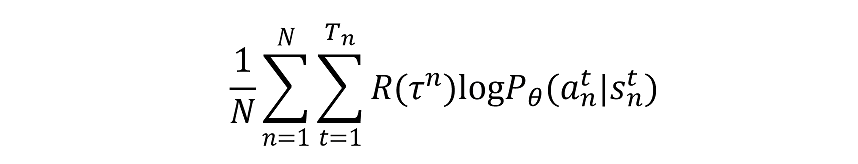
可以求出对所有可能的trajectory期望最大的梯度
用这个梯度乘以学习率去更新神经网络里面的参数,就是梯度策略算法Policy gradient。
那么实际我们应该怎样训练一个policy network呢?
首先我们定义loss函数,在需要最大化的目标函数前面加上负号,来让优化器最小化它。
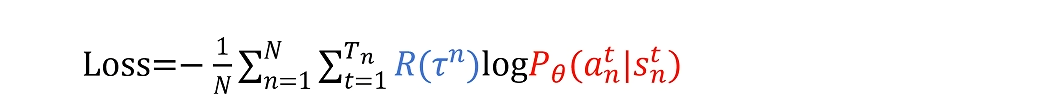
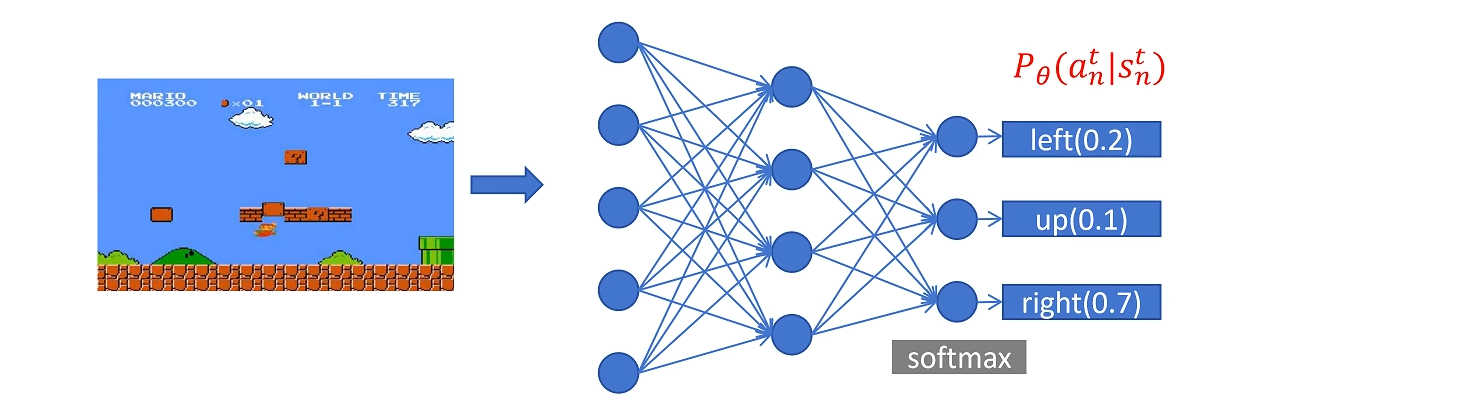
我们定义一个神经网络。输入就是当前的游戏画面也就是state,然后经过卷积神经网络的处理,最后输出层里面有三个神经元,经过softmax后代表三个动作的概率,这里的概率值就是loss函数里面红色的部分
然后我们让这个神经网络连续玩N场游戏。得到N个trajectory和最后的reward值。这里的reward值就是Loss公式里面蓝色的部分。
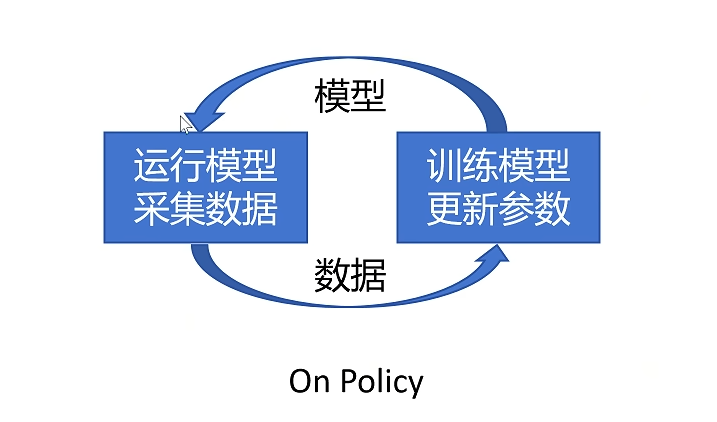
然后进行一个batch的训练,来更新policy神经网络。再玩N场游戏再训练一个batch,这样往复循环。这种更新策略叫做on policy。也就是采集数据用的policy和训练的policy是同一个。
这种策略有个缺点,就是大部分时间都在采集数据。训练非常慢,这也是PPO算法要解决的问题。
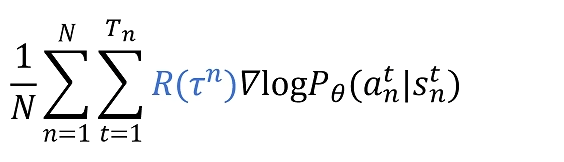 (目标函数)
(目标函数)
如果一个trajectory得到的reward是大于零的,那么就增加这个trajectory里面所有状态下采取当前action的概率。
如果一个trajectory得到的reward是小于零的,那么就减小这个trajectory里面所有状态下采取当前action的概率。
ps:注意!这里的action概率不是选取最大值!
但这明显是有改进空间:
第一点:就是我们是否可以增大或者减少在状态S下做动作A的概率,应该看做了这个动作之后到游戏结束累积的reward。而不是整个trajectory累积的reward,因为一个动作只能影响它后面的reward。
第二点是对第一点的修正。一个动作是可以对接下来的reward产生影响,但是它可能只影响接下来的几步,而且影响会逐步衰减,后面的reward更多的是由他当时的动作影响的。
争对这两点,我们修改公式:
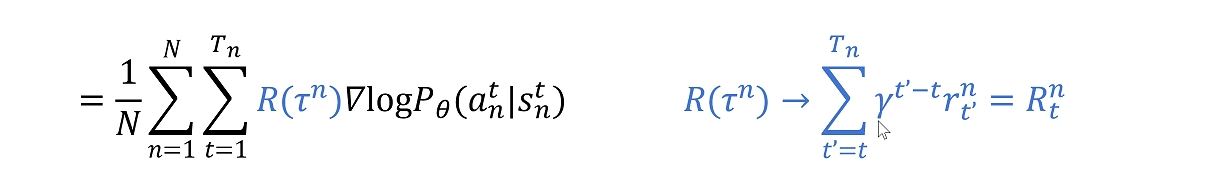
首先对reward的求和,不是对整个trajectory的reward进行求和。
而是从当前trajectory到结束时的reward进行求和。
蓝色公式描述了如何计算一条轨迹的总奖励
表示第
条轨迹的总时间步数
是衰减因子(折扣因子),用来权衡未来奖励的重要性(为了让动作对未来的影响没这么大,只会越来越小),
。
是在时间步
时,第n条轨迹获得的即时奖励
从时间步到
的所有未来奖励都被累加起来,计算从时间步
开始的总奖励
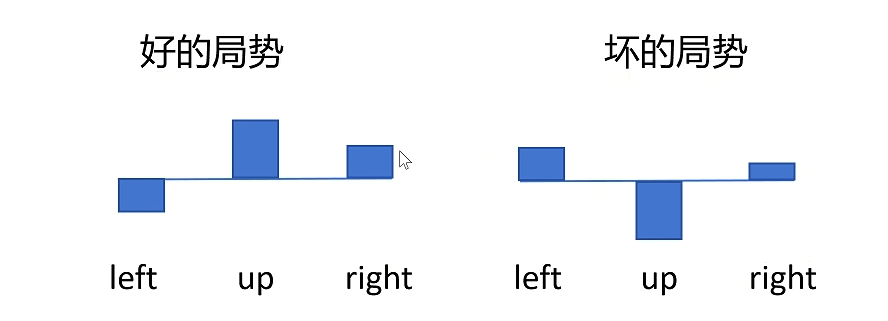
还有一种情况会影响我们算法的稳定性,那就是在好的局势下和坏的局势下的情况。比如在好的情况下,不论你做什么动作都能得到正的reward。相反在坏的情况下,不论你做什么动作都会得到负的reward。
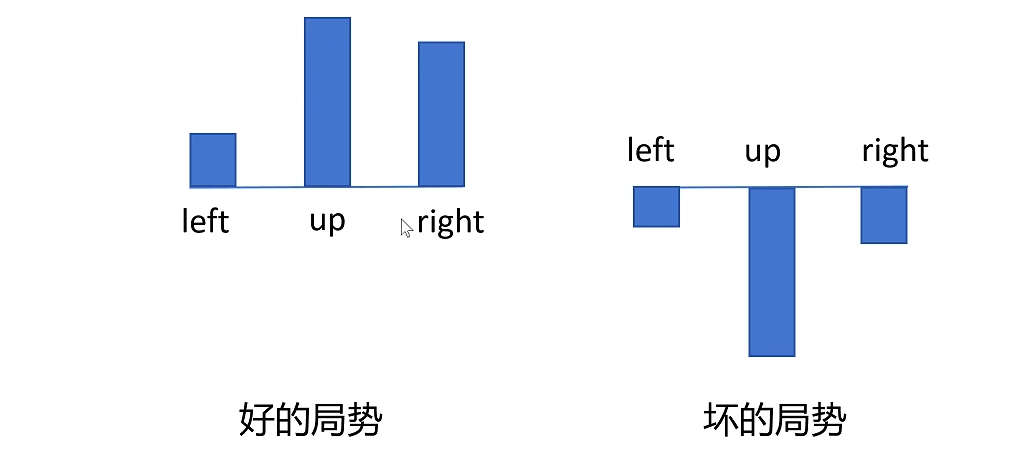
解决办法就是给所有动作的reward都减去一个baseline
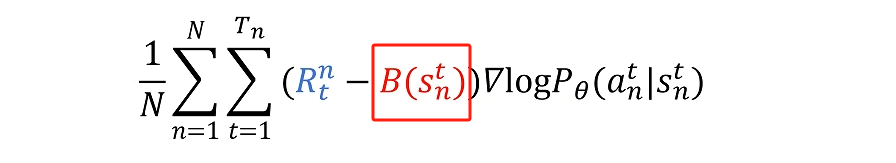
这个baseline也需要用神经网络来估算,即actor crtic算法。
critic网络它用来评估actor动作的好坏。就像个裁判员。
接下来需要了解一些概念:
第一个概念:动作价值函数Action-Value Function
之前我们讲的每一步action的return,都累加它后面的reward,并且逐步衰减,但是这也是通过具体的采样得到的值。具体的采样有个问题,就是需要无限多次才能准确反映当前action的好坏。如果每次都是只采样一次trajectory,方差很大,训练不稳定。
那有没有一个函数能估计一下这个action可以得到的return期望呢?
在state s下做出action a得到的回报期望,所以叫做动作价值函数。
第二个概念:状态价值函数State-Value Function
表示的是在状态s下,不论做任何动作得到的return的期望值,它表示状态价值函数
第三个概念:优势函数Advantage Function
表示在state s下做出action a,比其他动作能带来多少优势
它的公式就是动作价值函数减去状态价值函数
就是做出某一个具体动作得到的回报比这个状态期望的回报的差值,就表示了这个动作相对其它动作的优势。
故此,优势函数的定义有了。
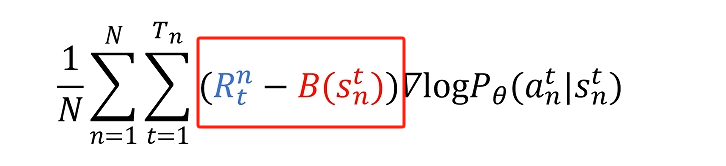
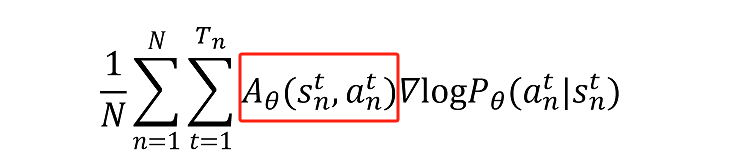
下一步就需要看怎么计算优势函数
动作价值函数
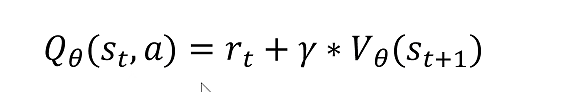
代入到优势函数
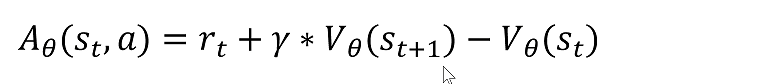
这样我们就由原来需要训练两个神经网络(拟合动作价值函数和状态价值函数)变成只需要训练一个代表状态价值的函数。
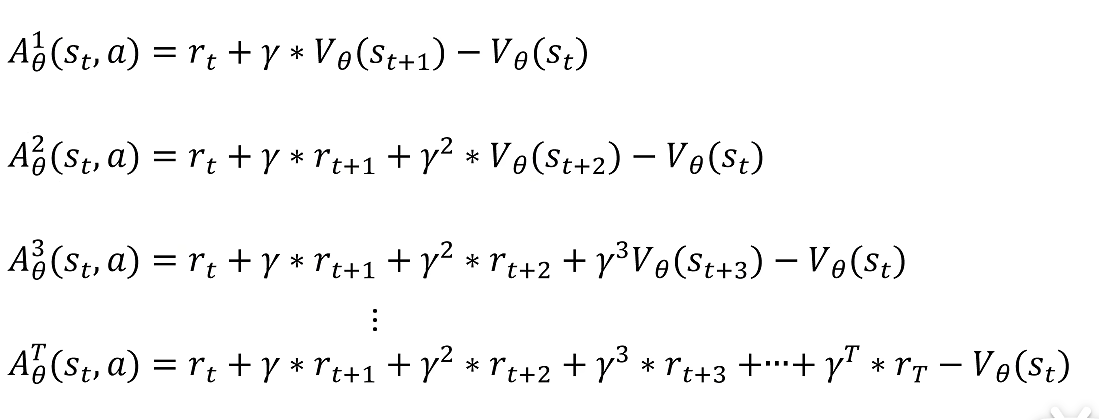
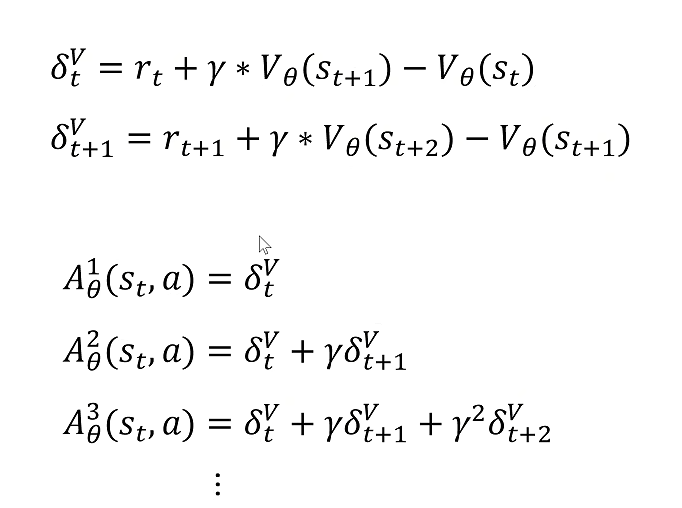
Generalized Advantage Estimation(GAE)
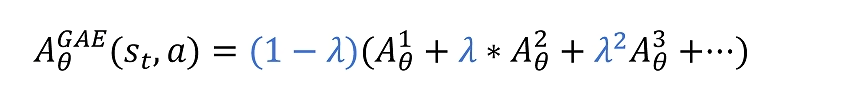
比如
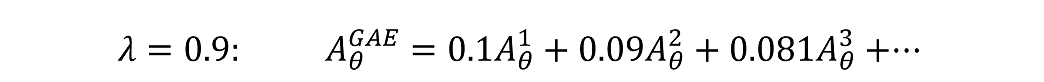
代入一下:
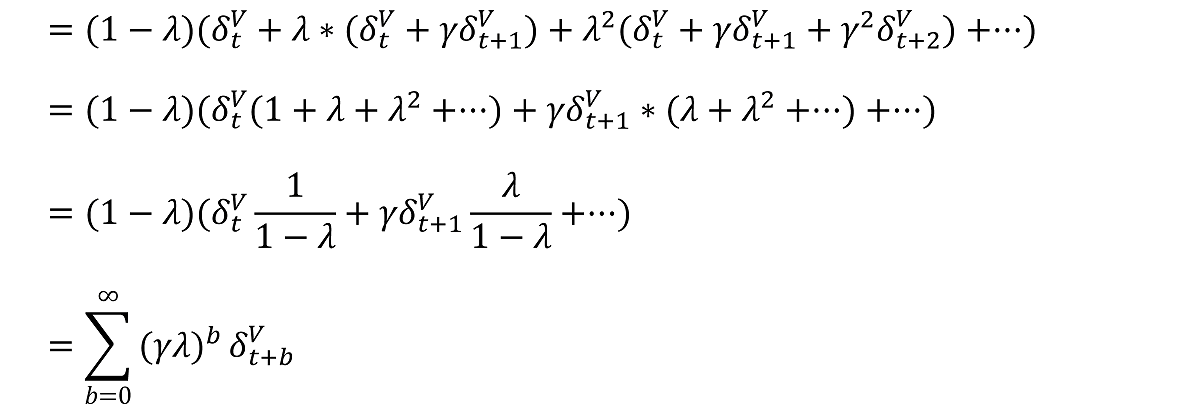
总结一下
通过这两个式子
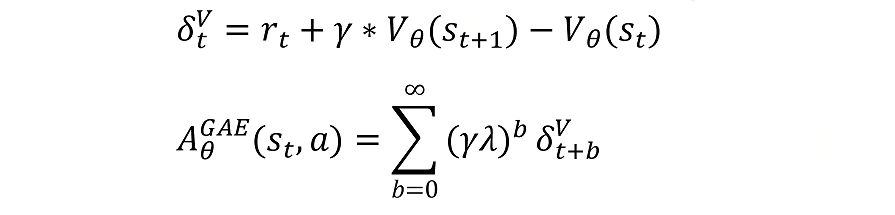
得到最后策略梯度的优化目标函数。
目的就是让这个函数的值越大越好
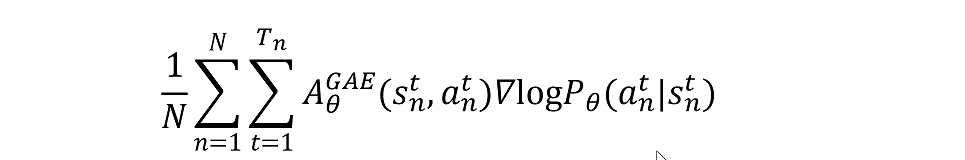
PPO
之前讲过on policy训练模式,采集数据用的策略和训练的策略是同一个,这样带来的问题是采集的数据只能用一次就需要丢弃。重新采集数据然后再进行训练,所以训练的速度非常慢。
off policy模式就是训练的模型和采集数据的模型不是同一个,并且采集的数据可以被用来多次训练,那就可以大大提高训练的速度。

举一个例子:
老师针对小明的表现表扬或批评小明。如果老师表扬小明,小明就加强老师表扬的行为;如果批评小明,小明就减少那个被老师批评的行为。这就是on policy的训练过程。因为老师表扬和批评的,以及小明调整的都是小明自己言行的policy。那对于其它同学呢?能根据老师表扬或者批评小明的言行而调整自己言行的policy吗?当然可以

同学们可以参考老师对小明的批评或者表扬来调整自己言行的policy,这就是off policy。
如果老师批评小明上课玩手机,如果有个女同学上课玩手机的概率比小明还多,那该女同学应该调整上课玩手机的行为比小明更多。
重要性采样Importance Sampling
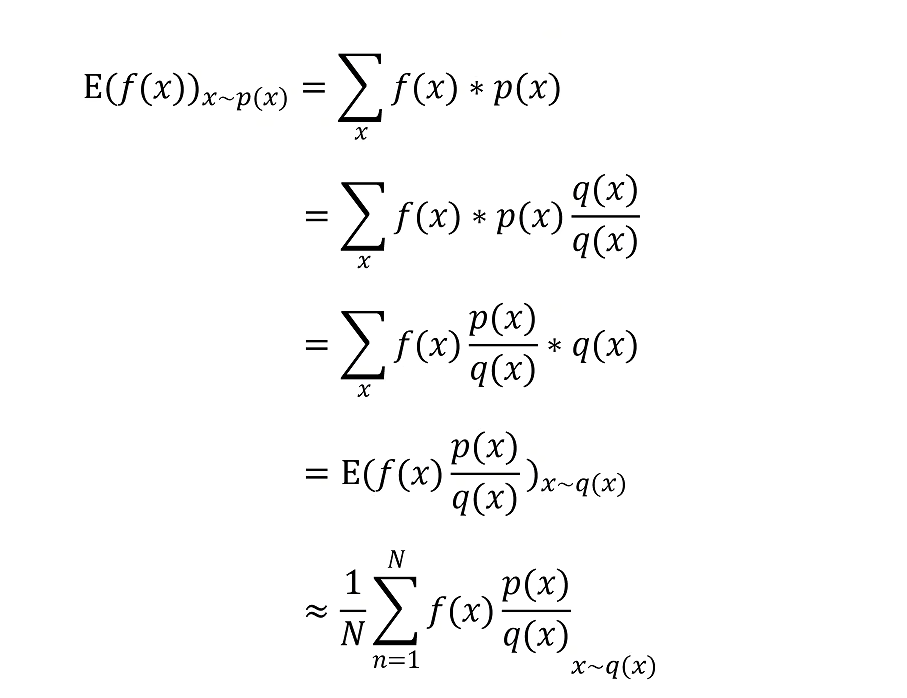
目标函数:
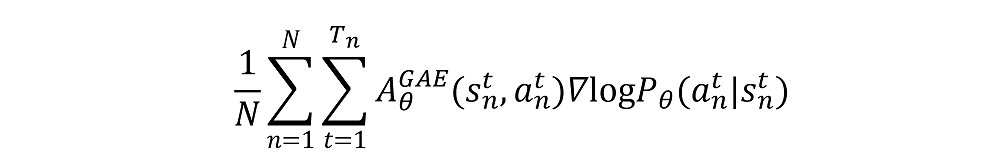
我们用重要性采样来更新目标函数的梯度公式:
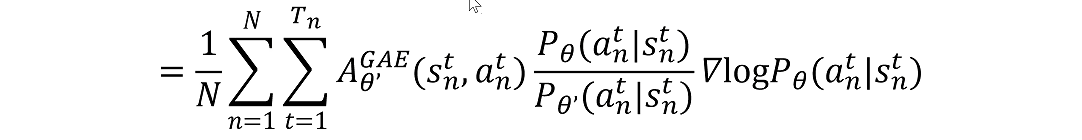
这样就可以把on policy的训练替换成off policy的训练。
用参考策略来采样,来计算优势函数
,然后用它来更新训练策略
这个公式可以理解为
是小明的策略,
是女同学的策略。优势函数
就是老师对小明的批评或者表扬。女同学不能直接用老师对小明言行的批评或者表扬来更新自己的言行准则。
比如小明上课玩手机,老师批评小明,小明上课玩手机10%.而女同学上课玩手机的概率是20%,那么女同学再更新自己玩手机这个行为时,强度应该是小明的两倍。

得到PPO算法的损失函数如下:
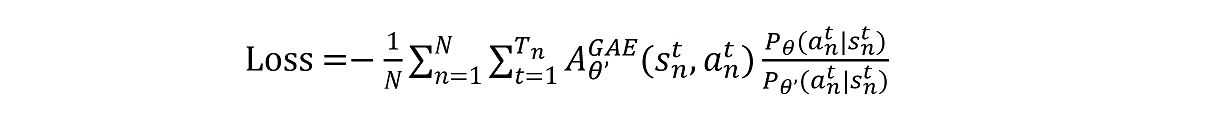
可以看到它是用参考策略来进行数据采样,计算优势函数
然后用训练的策略做某个动作的概率除以参考策略
做某个动作的概率来调整优势函数,这样我们就可以用参考策略来进行数据采样。并且采样的数据可以多次用来训练我们的policy网络,这样就解决了on policy训练效率太低的问题,但是有一点限制,就是这个参考策略不能和训练策略在同意情况下给出各种动作概率分布的差别太大。
比如,老师对和你差不多的学生进行批评,对你而言是有价值的。
就比如你成绩很好,老师对一个坏学生的批评对你意义不大
如何给我们的loss函数增加训练的策略不能和参考的策略分布相差太大?
第一种:加上 散度的约束。
散度的约束。
散度就是描述两个概率分布相似程度的量化指标。然后通过β来调整
散度约束的大小。
两个概率密度分布完全一致,则它们的散度为零;分布越不一致,
散度越大。
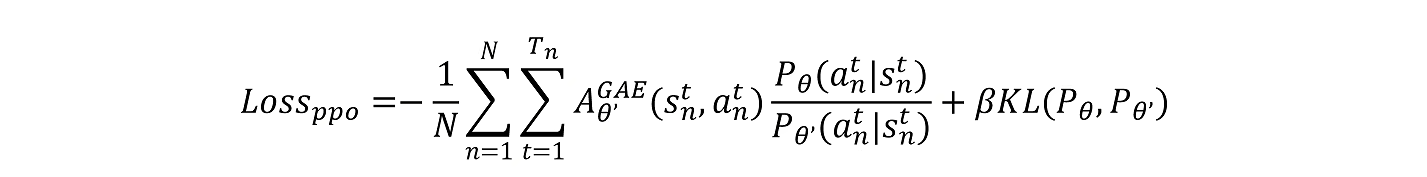
第二种:通过截断函数来替代散度
防止训练的策略和参考的策略偏差过大
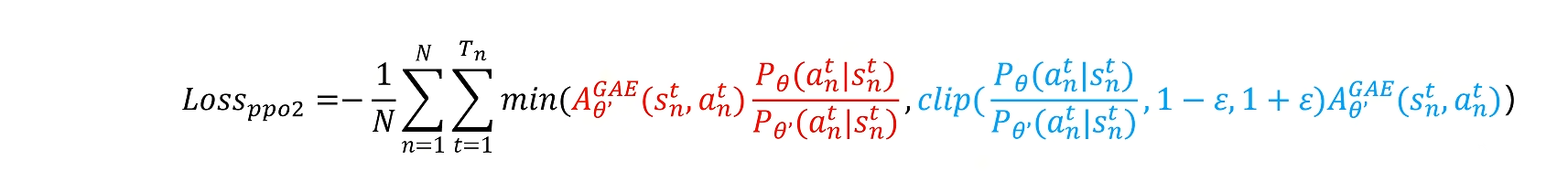
这个截断函数(剪辑函数)如何理解?
这个函数有三个部分。
如果的值,在
和
之间,那么就返回它本身的值。
如果的值小于
,就返回
如果的值大于
,就返回
这就限制了的概率值不能相差太大。
如果为2,
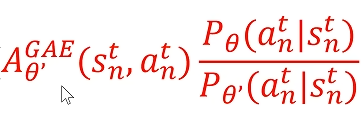 假如优势函数的值为正值,那么就应该调整
假如优势函数的值为正值,那么就应该调整尽可能的大。但是当
已经调整到足够大,是
的1.2倍了,那就不能再调整了。
同样如果优势函数为负值,就让尽可能小

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)