Python实现NOA星雀优化算法优化卷积神经网络CNN分类模型项目实战
Python实现NOA星雀优化算法优化卷积神经网络CNN分类模型项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后关注获取。
1.项目背景
在当今信息爆炸的时代,图像识别技术已经成为众多领域不可或缺的一部分,如自动驾驶、医疗影像分析、安防监控等。卷积神经网络(CNN)作为深度学习中的一种重要模型,在图像处理和分类任务上展现了卓越的性能。然而,CNN模型的效果很大程度上依赖于其结构设计及超参数的选择,包括卷积核大小、层数、学习率等。传统的方法往往通过试错法或网格搜索来确定这些参数,这不仅耗时费力,而且难以找到全局最优解。因此,如何高效地优化CNN模型的超参数成为了一个亟待解决的问题。
为了解决上述挑战,本项目引入了一种基于自然界生物行为的优化算法——NOA星雀优化算法(Nature-inspired Optimization Algorithm, NOA)。NOA算法模仿了鸟类觅食的行为模式,利用群体智能进行空间搜索,以找到最优解。与传统的优化方法相比,NOA具有更高的灵活性和适应性,能够有效地应对复杂的多维优化问题。将NOA应用于CNN模型的超参数优化中,不仅可以显著提升模型训练效率,还能增强模型的泛化能力,提高分类准确性。此外,NOA算法的并行计算特性也使其非常适合大规模数据集上的应用,为实际问题提供更高效的解决方案。
本项目的目的是构建一个结合NOA优化算法的CNN分类模型框架,并验证其在不同图像数据集上的有效性。首先,我们将建立一个基础的CNN分类模型,然后使用NOA算法对其进行超参数优化。接下来,通过一系列实验对比优化前后模型的表现,评估NOA算法在提升CNN模型性能方面的潜力。我们希望通过本项目的研究,不仅能为图像分类任务提供一种新的优化方法,同时也希望探索如何更好地将自然启发式算法与深度学习模型相结合,为其他复杂问题的解决提供借鉴。最终,本项目的成果有望推动人工智能技术在更多领域的应用和发展,特别是那些需要高精度图像识别的场景。
本项目通过Python实现NOA星雀优化算法优化卷积神经网络CNN分类模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
|
编号 |
变量名称 |
描述 |
|
1 |
x1 |
|
|
2 |
x2 |
|
|
3 |
x3 |
|
|
4 |
x4 |
|
|
5 |
x5 |
|
|
6 |
x6 |
|
|
7 |
x7 |
|
|
8 |
x8 |
|
|
9 |
x9 |
|
|
10 |
x10 |
|
|
11 |
y |
因变量 |
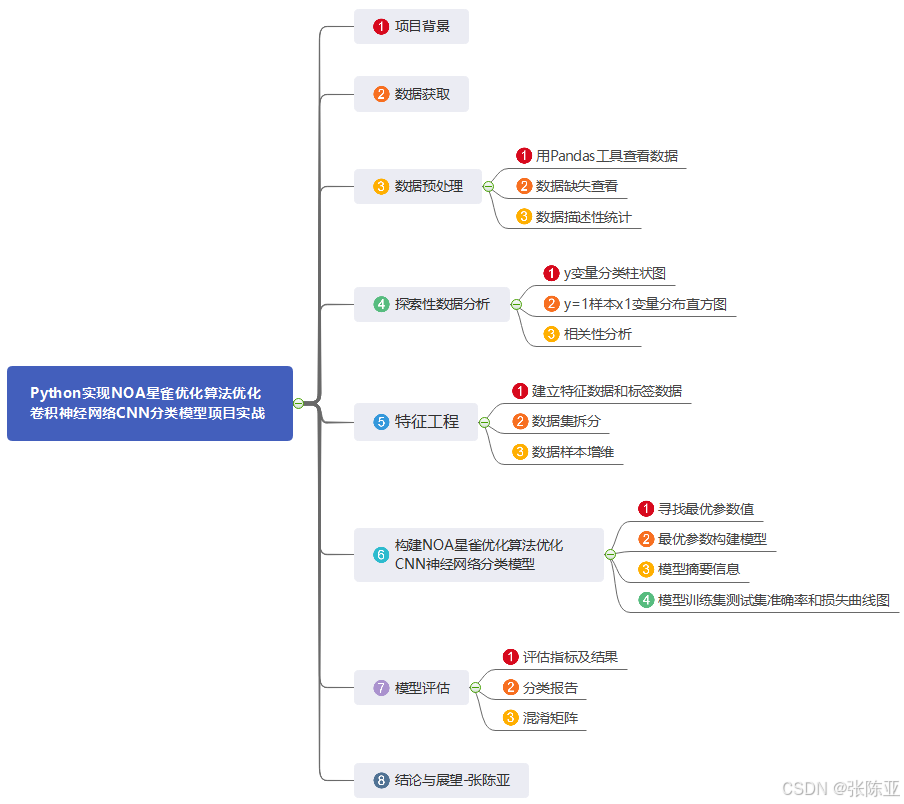
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
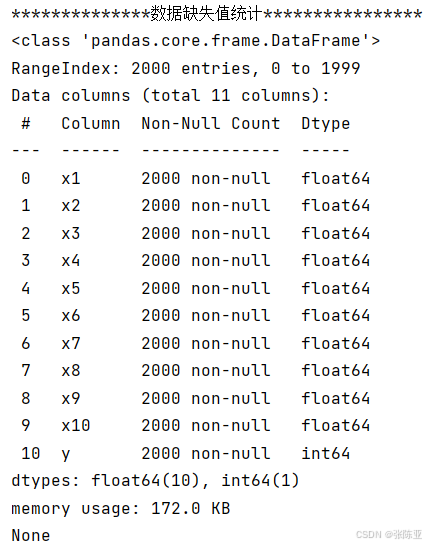
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
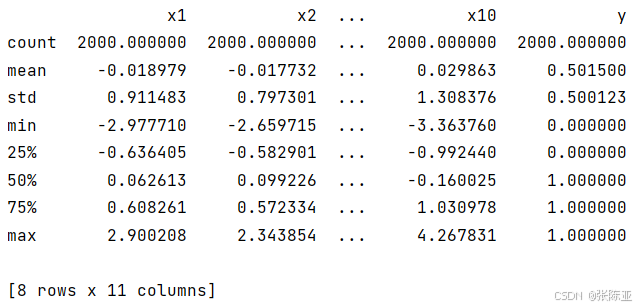
关键代码如下:

4.探索性数据分析
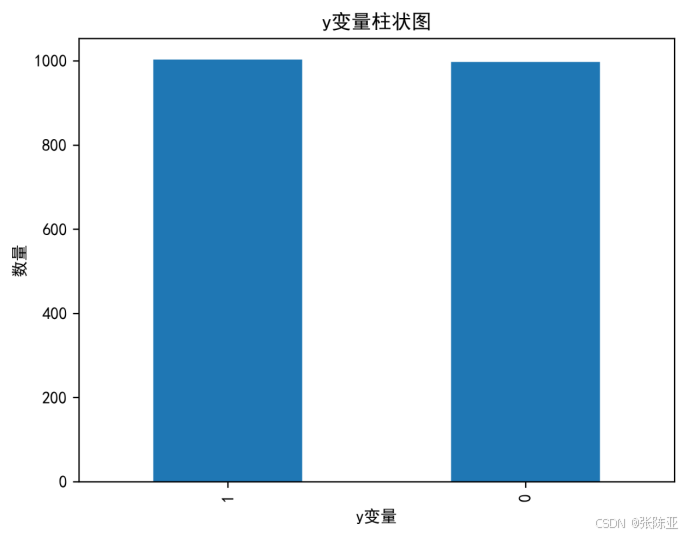
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
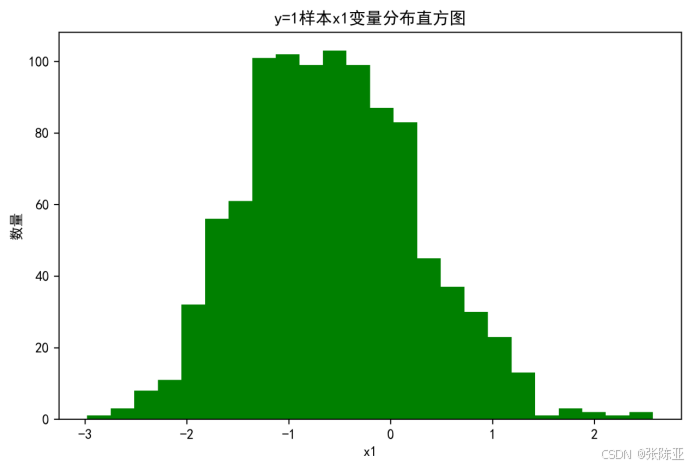
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
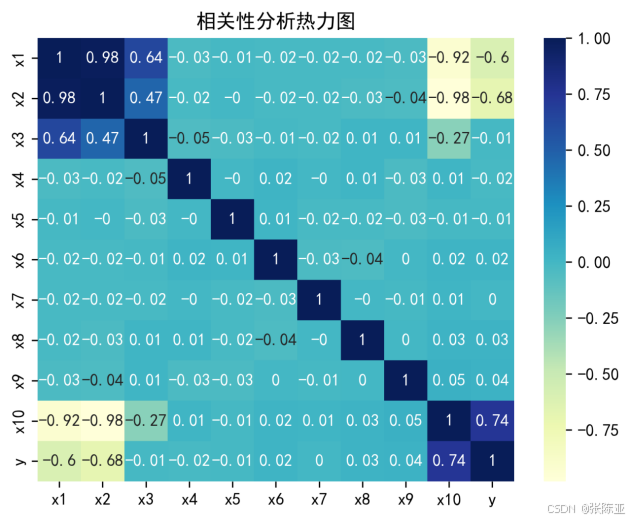
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%验证集进行划分,关键代码如下:

5.3 数据样本增维
为满足建模的需要,对特征样本进行增加一个维度,增维的关键代码如下:

6.构建NOA星雀优化算法优化CNN神经网络分类模型
主要通过Python实现NOA星雀优化算法优化CNN神经网络分类模型算法,用于目标分类。
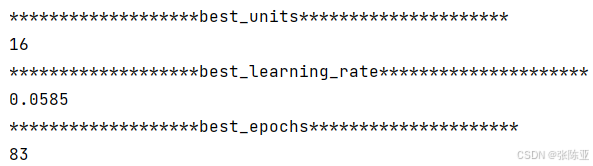
6.1 寻找最优参数值
最优参数值:
6.2 最优参数构建模型
这里通过最优参数构建分类模型。
|
模型名称 |
模型参数 |
|
CNN神经网络分类模型 |
units=best_units |
|
optimizer = tf.keras.optimizers.Adam(best_learning_rate) |
|
|
epochs=best_epochs |
6.3 模型摘要信息

6.4 模型训练集测试集准确率和损失曲线图
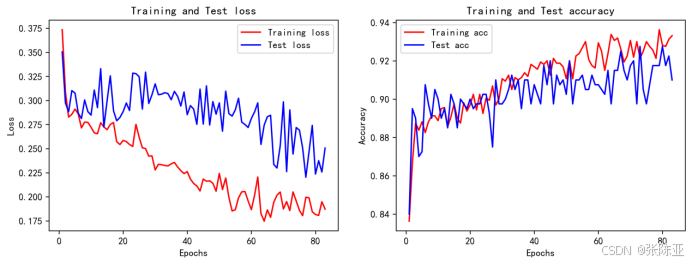
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
|
模型名称 |
指标名称 |
指标值 |
|
测试集 |
||
|
CNN神经网络分类模型 |
准确率 |
0.9100 |
|
查准率 |
0.8705 |
|
|
查全率 |
0.9653 |
|
|
F1分值 |
0.9155 |
|
从上表可以看出,F1分值为0.9155,说明NOA星雀优化算法优化的CNN神经网络模型效果良好。
关键代码如下:

7.2 分类报告
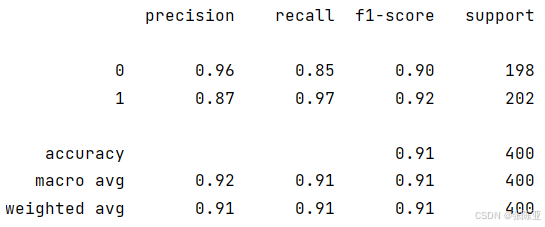
从上图可以看出,分类为0的F1分值为0.90;分类为1的F1分值为0.92。
7.3 混淆矩阵
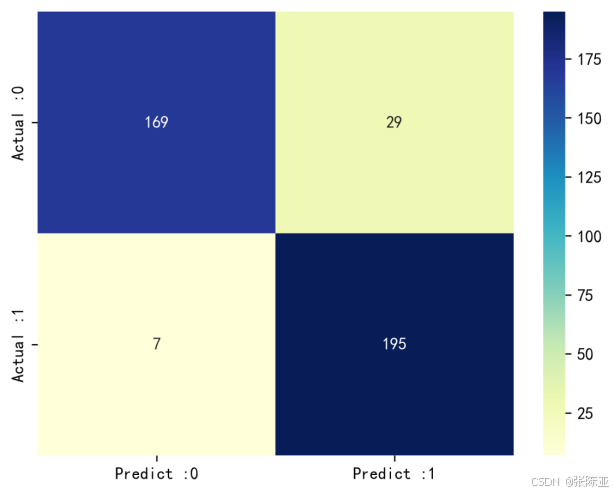
从上图可以看出,实际为0预测不为0的 有29个样本,实际为1预测不为1的 有7个样本,模型效果良好。
8.结论与展望
综上所述,本文采用了通过NOA星雀优化算法优化CNN神经网络分类算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的建模工作。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)