Python实现P-PSO优化算法优化随机森林分类模型项目实战
Python实现P-PSO优化算法优化随机森林分类模型项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后关注获取。
1.项目背景
Phasor Particle Swarm Optimization (P-PSO) 是一种基于传统粒子群优化(Particle Swarm Optimization, PSO)算法的改进版本,旨在解决一些在使用原始PSO处理复杂或高维优化问题时可能遇到的局限性。PSO是一种模拟鸟群觅食行为的群体智能优化算法,广泛应用于函数优化、神经网络训练、模糊系统控制等领域。
随着机器学习技术的快速发展,随机森林分类模型因其强大的泛化能力、对噪声数据的鲁棒性以及处理高维数据的能力,在分类任务中得到了广泛应用。然而,随机森林的性能高度依赖于超参数的选择,如树的数量、最大深度、分裂标准等。不合理的超参数配置可能导致模型欠拟合或过拟合,从而影响分类效果。因此,如何高效地优化随机森林的超参数成为提升其性能的关键问题之一。
传统的超参数优化方法(如网格搜索和随机搜索)虽然简单易用,但在面对高维搜索空间时往往效率低下,难以在有限时间内找到最优解。近年来,基于群体智能的优化算法(如粒子群优化PSO)因其高效的全局搜索能力和自适应调整机制,逐渐被应用于机器学习模型的超参数优化中。特别是改进版的P-PSO算法,通过引入动态权重和局部搜索策略,进一步提升了优化精度和收敛速度,为随机森林的超参数优化提供了新的解决方案。
P-PSO通过引入“相量”概念来增强标准PSO的能力,这使得算法能够在搜索空间中更有效地导航,并有助于克服原版PSO中常见的早熟收敛问题。在P-PSO中,每个粒子不仅有位置和速度,还被赋予了一个相量表示。这个相量可以看作是粒子在复数平面上的一个旋转因子,它影响着粒子的移动方向和速度更新规则。通过这种方式,P-PSO能够实现更加精细的搜索过程,提高了找到全局最优解的可能性。总之,Phasor Particle Swarm Optimization是一种创新的优化技术,它利用了相量的概念以提高粒子群优化算法的性能,使其更适合解决复杂的优化问题。
本项目旨在利用Python实现P-PSO优化算法,并将其应用于随机森林分类模型的超参数优化中。通过结合P-PSO的全局搜索能力和随机森林的强大分类能力,我们期望能够在多种分类任务中取得更高的准确率和更优的模型性能。同时,该项目不仅验证了P-PSO算法在实际应用中的有效性,也为其他机器学习模型的超参数优化提供了参考模板,具有重要的理论意义和实践价值。
本项目通过Python实现P-PSO优化算法优化随机森林分类模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
|
编号 |
变量名称 |
描述 |
|
1 |
x1 |
|
|
2 |
x2 |
|
|
3 |
x3 |
|
|
4 |
x4 |
|
|
5 |
x5 |
|
|
6 |
x6 |
|
|
7 |
x7 |
|
|
8 |
x8 |
|
|
9 |
x9 |
|
|
10 |
x10 |
|
|
11 |
y |
因变量 |
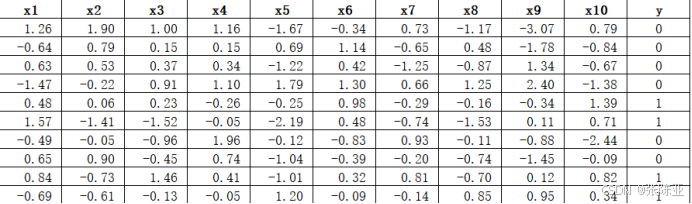
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
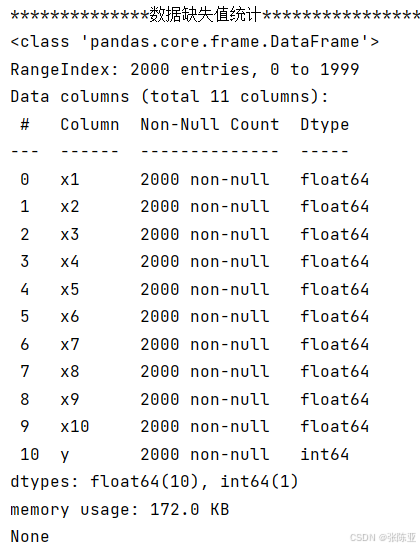
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

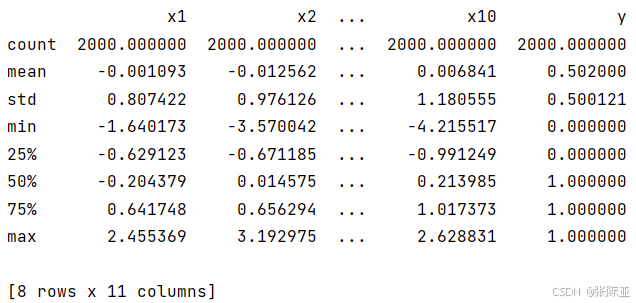
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
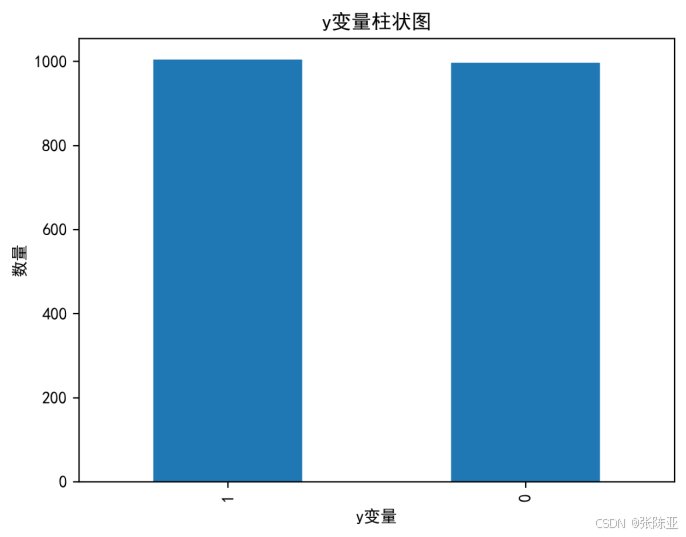
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
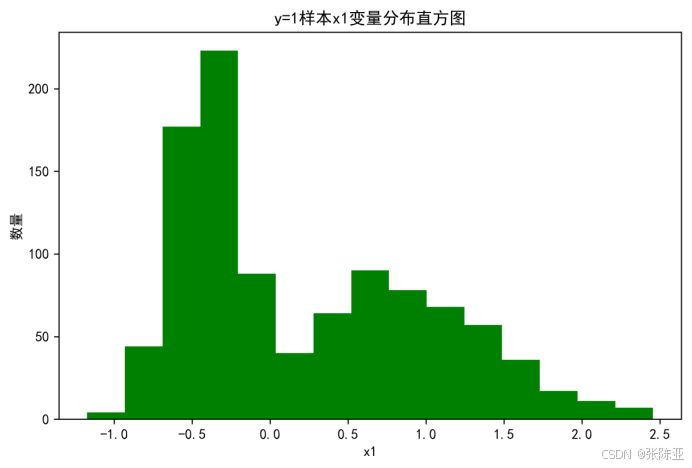
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
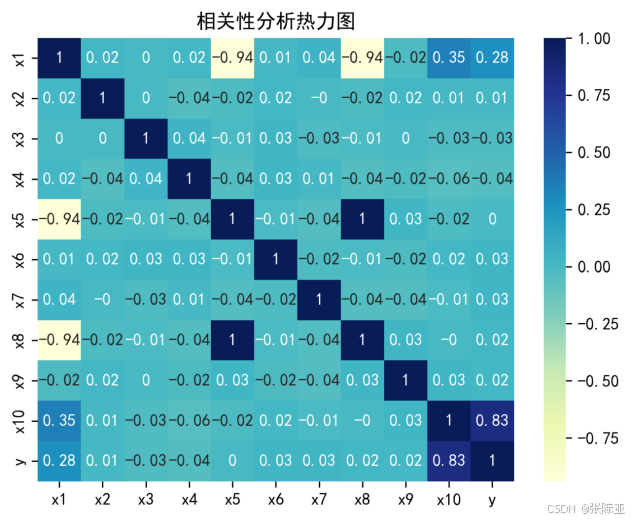
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%验证集进行划分,关键代码如下:

6.构建P-PSO优化算法优化随机森林分类模型
主要通过Python实现P-PSO优化算法优化随机森林分类模型算法,用于目标分类。
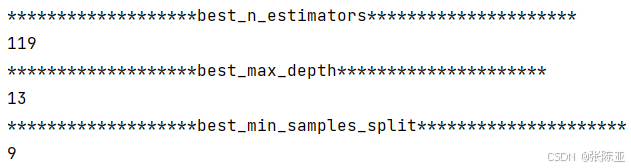
6.1 寻找最优参数值
最优参数值:
6.2 最优参数构建模型
这里通过最优参数构建分类模型。
|
模型名称 |
模型参数 |
|
随机森林分类模型 |
n_estimators=best_n_estimators |
|
max_depth=best_max_depth |
|
|
min_samples_split=best_min_samples_split |
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
|
模型名称 |
指标名称 |
指标值 |
|
测试集 |
||
|
随机森林分类模型 |
准确率 |
0.9550 |
|
查准率 |
0.9269 |
|
|
查全率 |
0.9902 |
|
|
F1分值 |
0.9575 |
|
从上表可以看出,F1分值为0.9575,说明P-PSO优化算法优化的随机森林分类模型效果良好。
关键代码如下:

7.2 分类报告
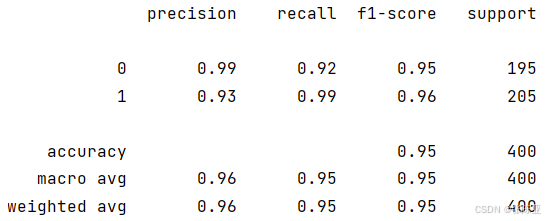
从上图可以看出,分类为0的F1分值为0.95;分类为1的F1分值为0.96。
7.3 混淆矩阵
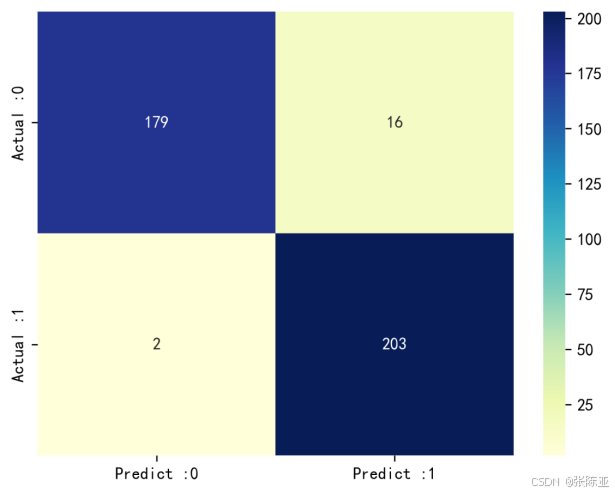
从上图可以看出,实际为0预测不为0的 有16个样本,实际为1预测不为1的 有2个样本,模型效果良好。
8.结论与展望
综上所述,本文采用了通过P-PSO优化算法优化随机森林分类算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的建模工作。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)