深度学习面试必会之常见激活函数
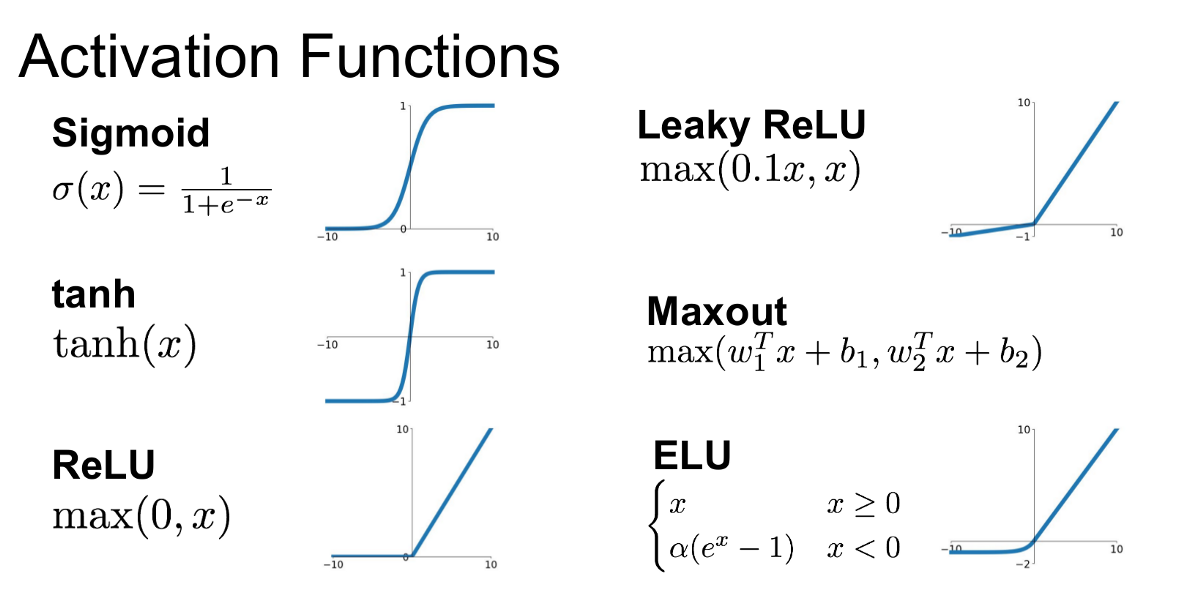
以下是常见激活函数的简介,包括它们的典型应用场景、优缺点,以及基于 NumPy 的 Python 实现。
1. Sigmoid
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
-
常用于:二分类模型输出层;早期的多层感知机隐藏层。
-
优点:
-
输出范围 (0,1),天然可解释为概率。
-
平滑可导,数学性质好。
-
-
缺点:
-
梯度在极端输入时饱和,易导致梯度消失。
-
输出非零中心化,可能导致优化收敛变慢。
-
2. ReLU (Rectified Linear Unit)
import numpy as np
def relu(x):
return np.maximum(0, x)
-
常用于:几乎所有深度卷积网络和多层感知机中间层。
-
优点:
-
计算简单、收敛快。
-
部分输入梯度恒定,缓解梯度消失。
-
-
缺点:
-
“死亡 ReLU”问题:部分神经元若始终输出 0,梯度为 0,无法恢复。
-
3. Tanh
import numpy as np
def tanh(x):
return np.tanh(x)
-
常用于:隐藏层(尤其在 RNN、LSTM 中常见)。
-
优点:
-
输出范围 (−1,1),零中心化,有利于梯度更新。
-
相比 Sigmoid,梯度范围更大。
-
-
缺点:
-
极端输入仍然会饱和,存在梯度消失。
-
4. Leaky ReLU
import numpy as np
def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)
-
常用于:替代 ReLU,减轻“死亡 ReLU”问题。
-
优点:
-
负区间保留小斜率,神经元不易完全“死亡”。
-
计算开销与 ReLU 相近。
-
-
缺点:
-
负斜率系数需调参;若选取不当,可能效果不佳。
-
5. Swish
import numpy as np
def swish(x):
return x * sigmoid(x) # 需先定义 sigmoid
-
常用于:最新深度网络(如 EfficientNet)、轻量级网络改进。
-
优点:
-
平滑、非单调, empirically 在很多任务上优于 ReLU。
-
保留小于 0 的信息,有助于信息流动。
-
-
缺点:
-
计算量比 ReLU 略大(含一次 Sigmoid 调用)。
-
在某些小模型上收益有限,不如 ReLU 简洁稳定。
-
在上面的基础上,新增 SiLU(也就是 Swish-1)及其他常见激活函数:
6. SiLU (Sigmoid Linear Unit)
import numpy as np
def silu(x):
return x / (1 + np.exp(-x))
-
常用于:与 Swish 等价,在最新网络中也常见(如 MobileNetV3 等)。
-
优点:
-
平滑、非单调,使信息更易传播。
-
对小负值保留一定信息。
-
-
缺点:
-
计算量比 ReLU 略大。
-
在某些场景与 Swish 区别不明显,易混淆。
-
7. ELU (Exponential Linear Unit)
import numpy as np
def elu(x, alpha=1.0):
return np.where(x > 0, x, alpha * (np.exp(x) - 1))
-
常用于:深层网络中的隐藏层,尤其在 BatchNorm 之后。
-
优点:
-
负区间有非零输出,减少“死亡神经元”。
-
输出均值更接近 0,收敛速度更快。
-
-
缺点:
-
计算涉及指数,开销高于 ReLU。
-
需调参 α。
-
8. Softplus
import numpy as np
def softplus(x):
return np.log1p(np.exp(x)) # 等价于 log(1 + e^x)
-
常用于:替代 ReLU,提供平滑近似;在生成模型输出层中有时使用。
-
优点:
-
平滑可导,可避免 ReLU 的不连续点。
-
输出始终 >0,稳定。
-
-
缺点:
-
计算开销比 ReLU 大不少。
-
对大负值,指数计算可能数值下溢。
-
9. GELU (Gaussian Error Linear Unit)
import numpy as np
from math import sqrt
def gelu(x):
return 0.5 * x * (1 + np.erf(x / sqrt(2)))
-
常用于:Transformer 系列(如 BERT、GPT);深度 NLP 网络。
-
优点:
-
结合了随机性和非线性,效果通常优于 ReLU/Swish。
-
-
缺点:
-
计算更复杂,含误差函数;推理速度相对慢。
-
10. Softmax
import numpy as np
def softmax(x, axis=-1):
ex = np.exp(x - np.max(x, axis=axis, keepdims=True))
return ex / np.sum(ex, axis=axis, keepdims=True)
-
常用于:多分类模型的输出层,将 logits 转为概率分布。
-
优点:
-
输出可直接作为类别概率;直观且与交叉熵损失配合良好。
-
-
缺点:
-
容易造成数值溢出/下溢,需加减 max 做数值稳定处理(如上实现)。
-
全局归一化对大向量计算量较大。
-
小结:
-
极简高效:ReLU、Leaky ReLU
-
平滑非单调:Swish/SiLU、ELU、Softplus、GELU
-
输出概率:Sigmoid(二分类)、Softmax(多分类)
-
RNN 推荐:tanh
-
实战调参:可根据模型深度、硬件开销与非线性需求选用以上激活函数。
参考:
ChatGPT

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)