Vllm框架入门及本地私有化部署
·
企业级大模型部署推理管理工具
Part 1. Vllm 框架基础入门与本地私有化部署
一、大模型部署框架的核心需求与主流方案
对开源大模型而言,即使模型权重开源,仍需依赖框架实现运行与推理。当前业界普遍兼容 OpenAI API规范,因其可无缝集成各类SDK与客户端。衡量部署框架成熟度的关键指标之一,便是对该规范的支持程度。
主流框架对比
目前主流大模型部署框架包括 llama.cpp、Ollama 和 Vllm,其在 GitHub 上的 Stars 增长趋势如下: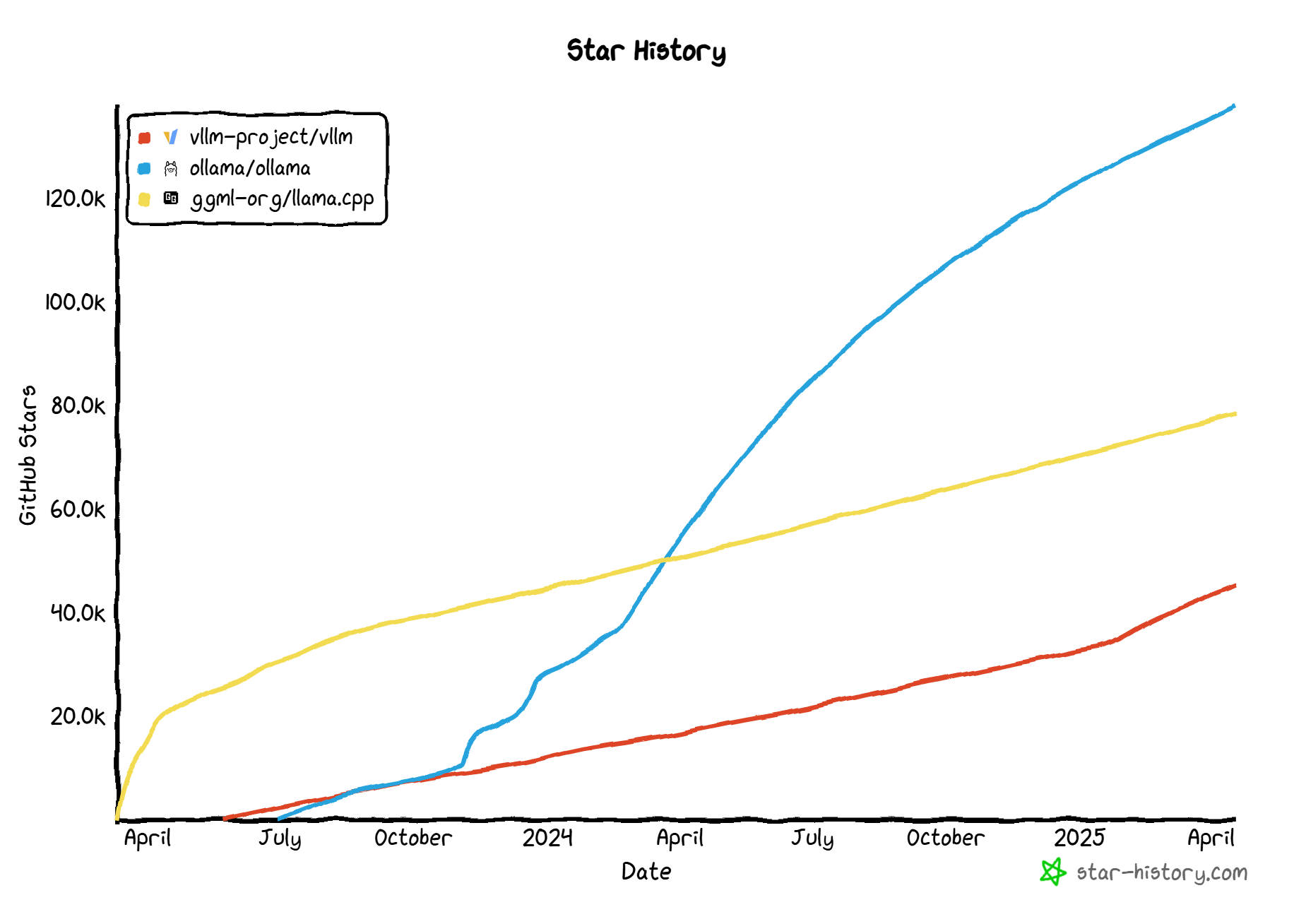
- llama.cpp:纯C/C++实现,无依赖,性能高但上手难度大,适合深度定制优化。
- Ollama:部署极简,支持多系统一键安装与单命令启动,原生兼容OpenAI API,门槛极低,适合快速验证。
- Vllm:聚焦性能与可扩展性,优化内存管理、批处理和张量并行,适用于生产环境高吞吐量场景。
二、Vllm 框架核心特性与适用场景
1. 框架定位与技术优势
Vllm 基于 PyTorch 构建,核心优化点包括:
- 高效内存管理:通过
PagedAttention算法优化KV cache,减少内存浪费。 - 持续批处理:支持异步处理与连续批处理,提升多并发请求吞吐量。
- 张量并行性:利用多GPU张量并行技术,突破单卡显存限制。
- 生产级特性:内置API密钥验证、请求校验等安全机制,兼容Hugging Face模型与OpenAI API规范。
基准测试显示,同等配置下 Vllm 吞吐量较传统推理库可提升一个数量级,尤其适合企业级生产环境。
2. 支持模型类型
- 纯文本模型:支持 Llama、Qwen、DeepSeek 等主流语言模型,完整列表见 官方文档。
- 多模态模型:支持文本、图像、视频、音频模态,当前版本(0.8.4)支持的部分模型如下:
| .py 文件 | 模型名称 | 描述 |
|---|---|---|
aya_vision.py |
aya-vision | Cohere 视觉-语言模型 |
llava.py |
LLaVA | 开源视觉-语言模型系列 |
qwen2_vl.py |
通义千问多模态 | 阿里通义千问视觉/音频版本 |
whisper.py |
whisper-large-v3 | OpenAI语音-文本模型 |
三、Linux 环境下 Vllm 私有化部署实践
1. 部署前提条件
- 操作系统:仅支持 Linux(推荐 Ubuntu 22.04),不支持 Windows。
- Python版本:需在 3.9 ~ 3.12 之间。
2. 环境搭建与框架安装
以 Ubuntu 22.04 + 4块3090显卡为例:
# 安装conda(若未安装)
conda --version # 检查版本,未安装则参考官方文档安装
# 创建Python虚拟环境(Python 3.12)
conda create --name vllm python=3.12
conda activate vllm
# 安装vllm
pip install vllm
pip show vllm # 验证安装版本
3. 模型权重下载与本地化
国内环境需通过 ModelScope镜像源 下载模型,以 DeepSeek-R1-Distill-Qwen-32B 为例:
# 安装ModelScope
pip install modelscope
# 下载模型(修改cache_dir为自定义路径)
from modelscope import snapshot_download
model_dir = snapshot_download(
'deepseek-ai/DeepSeek-R1-Distill-Qwen-32B',
cache_dir='/home/vllm',
revision='master'
)
下载完成后,模型权重存储于 cache_dir 指定路径。
四、Vllm 离线推理实战
1. 基础调用流程
from vllm import LLM, SamplingParams
# 初始化LLM(指定本地模型路径)
llm = LLM(
model="/home/vllm/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
trust_remote_code=True, # 加载非Hugging Face模型需开启
tensor_parallel_size=2, # 多GPU张量并行(根据显存调整)
max_model_len=4096
)
# 定义采样参数(推理模型需增加max_tokens)
sampling_params = SamplingParams(
max_tokens=8192,
temperature=0.6,
top_p=0.95
)
# 单条推理
outputs = llm.generate("你好,请问什么是卡布奇洛?", sampling_params=sampling_params)
for output in outputs:
print(f"生成结果:{output.outputs[0].text}")
# 批量推理
prompts = [
"帮我制定大模型学习路线",
"推荐几本大模型入门书籍"
]
outputs = llm.generate(prompts, sampling_params=sampling_params)
2. 推理模型格式化输出技巧
在 prompt 结尾添加 <|FunctionCallBegin|>\n(大模型思考结束标记),可区分推理过程与结果:
prompts = ["给我设计一个大模型学习计划<RichMediaReference>\n"]
outputs = llm.generate(prompts, sampling_params=sampling_params)
for output in outputs:
text = output.outputs[0].text
if "<|FunctionCallBegin|>" in text:
think, answer = text.split("superscript:")
print(f"思考:{think}\n回答:{answer}")
五、多机多卡与生产环境扩展
1. 多GPU显存优化
tensor_parallel_size:指定参与张量并行的GPU数量,用于拆分超大规模模型(如70B参数模型)。gpu_memory_utilization:控制单卡显存使用率(0~1),避免显存碎片化。
2. 远程开发环境配置(以Jupyter为例)
- 在服务器虚拟环境中安装依赖:
pip install ipykernel jupyter - 生成加密密码并配置Jupyter服务:
jupyter lab --generate-config # 修改jupyter_lab_config.py,配置IP、端口、密码等 - 启动服务并关联内核:
nohup jupyter lab --allow-root & python -m ipykernel install --user --name vllm - 本地浏览器通过SSH隧道访问服务器Jupyter服务。
六、总结与下一步
Vllm 凭借高性能、可扩展及生产级特性,成为企业落地大模型的首选框架之一。本文覆盖了从框架选型、环境搭建到离线推理的全流程,后续将进一步探讨 在线推理服务部署、多模态模型集成 及 性能压测优化 等进阶内容。
参考资源:
- Vllm 官方仓库:https://github.com/vllm-project/vllm
- ModelScope 模型库:https://www.modelscope.cn/home

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)