【小白入门】YOLO11网络架构|各模块分析|损失函数
注:此文仅为博主学习YOLO11所记个人笔记,文末有参考文章,侵删。
阅读本文最好具备机器学习相关基础知识,比如了解基础神经网络、损失函数。
文章目录
YOLO11
一、对比与改进
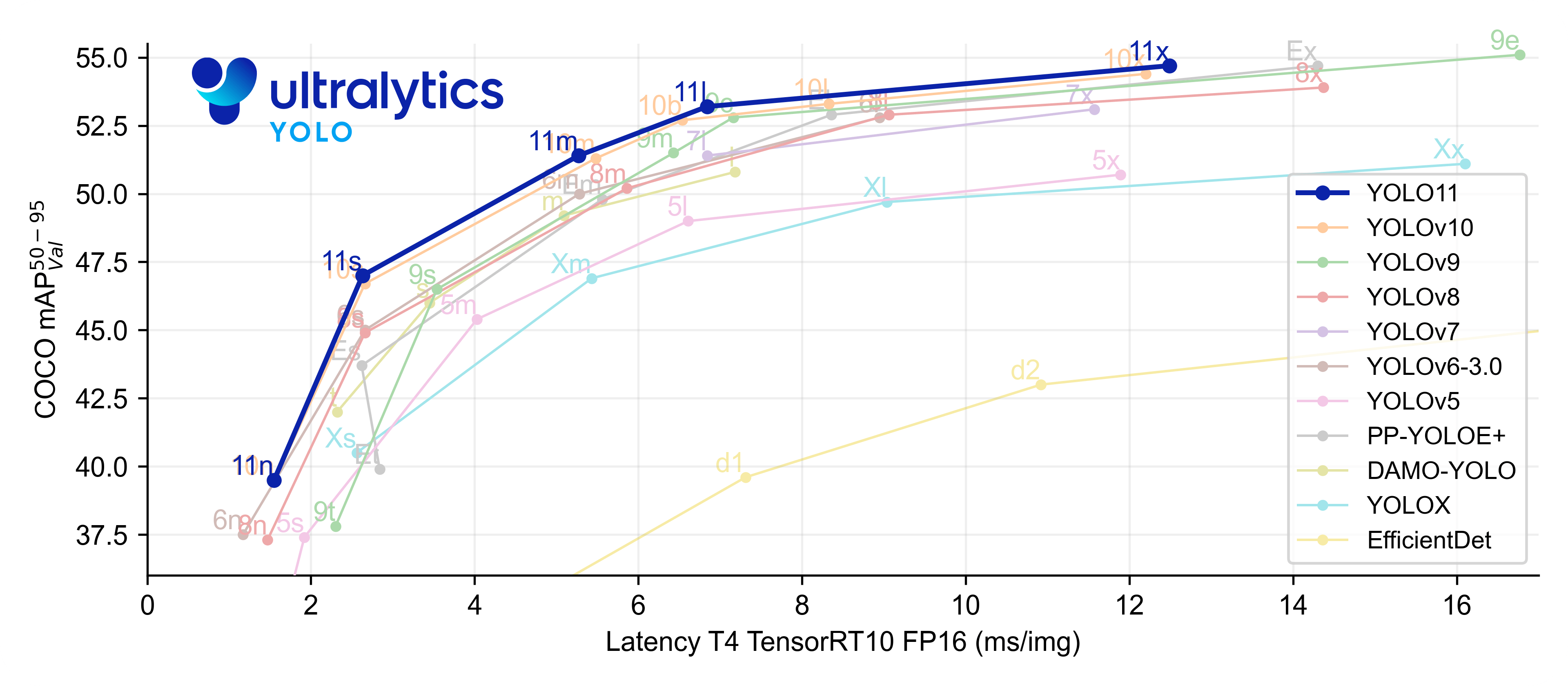
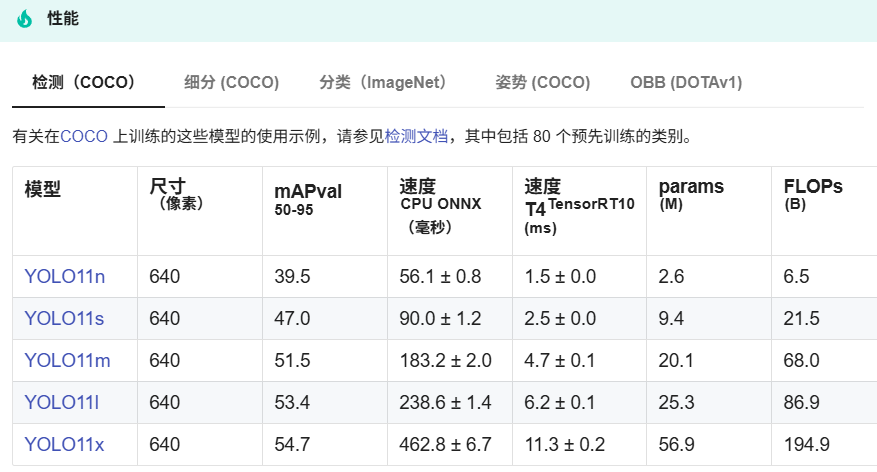
- 增强的特征提取:改进了骨干和颈部架构,增强了特征提取能力,提高了物体检测的精确度。
- 优化的效率和速度:更快的处理速度,保持准确性和性能之间的平衡。
- 更高的准确性与更少的参数:YOLO11m在COCO数据集上实现了更高的均值平均精度(mAP),同时使用比YOLOv8m少22%的参数,使其在不妥协准确性的情况下更加计算高效。
- 环境适应性强:在多种环境中部署,包括边缘设备、云平台以及支持NVIDIA GPU的系统。
- 支持广泛的任务:物体检测、实例分割、图像分类、姿态估计和旋转目标检测(OBB)
二、指标
| predict\actual | 1 | 0 |
|---|---|---|
| 1 | TP(true positive) | FP(false positive) |
| 0 | FN(false negative) | TN(true negative) |
精确率(Precision): P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP (预测正确的正例/预测所有的正例)
召回率(Recall): R = T P T P + F N R=\frac{TP}{TP+FN} R=TP+FNTP (预测正确的正例/实际所有的正例)
均值平均精度(mAP)
均值平均精度(mean Average Precision,mAP):综合考虑了精确率(Precision)和召回率(Recall)的表现。
计算步骤:
- 对每个类别,计算不同置信度阈值下的精确率(Precision)和召回率(Recall)。
- 绘制 Precision-Recall 曲线。
- 计算曲线下的面积,得到该类别的平均精确率(AP)。
- 对所有类别的 AP 取平均值,得到 mAP。
平均精确率(Average Precision,AP):
平滑曲线下的面积: A P = ∫ 0 1 P ( r ) d r AP=\int_0^1 P(r) \, dr AP=∫01P(r)dr
离散形式: 1 N pos ∑ k = 1 n P ( k ) ⋅ rel ( k ) \frac{1}{N_{\text{pos}}} \sum_{k=1}^n P(k) \cdot \text{rel}(k) Npos1∑k=1nP(k)⋅rel(k)
N p o s N_{pos} Npos:所有正样本的个数, r e l ( k ) rel(k) rel(k):第 k k k个样本是否是正样本(1/0)
公式:
m A P = 1 N ∑ i = 1 N A P i ( N :类别个数) mAP=\frac{1}{N} \sum_{i=1}^N AP_i(N:类别个数) mAP=N1i=1∑NAPi(N:类别个数)
并交比(IoU)
并交比(Intersection over Union, IoU) :用于衡量两个区域重叠程度的指标。
评估预测框(Prediction)与真实框(Ground Truth)的匹配精度。
定义为预测区域(Prediction)与真实区域(Ground Truth)的交集面积与并集面积的比值。
计算步骤:
预测框坐标: ( x 1 , y 1 , x 2 , y 2 ) (x_1,y_1,x_2,y_2) (x1,y1,x2,y2)
真实框坐标: ( x 1 ′ , y 1 ′ , x 2 ′ , y 2 ′ ) (x_1^′,y_1^′,x_2^′,y_2^′) (x1′,y1′,x2′,y2′)
1.计算交集面积:
Intersection = max ( 0 , min ( x 2 , x 2 ′ ) − max ( x 1 , x 1 ′ ) ) × max ( 0 , min ( y 2 , y 2 ′ ) − max ( y 1 , y 1 ′ ) ) \begin{aligned} \text{Intersection} &= \max(0, \min(x_2, x_2') - \max(x_1, x_1')) \\ &\quad \times \max(0, \min(y_2, y_2') - \max(y_1, y_1')) \end{aligned} Intersection=max(0,min(x2,x2′)−max(x1,x1′))×max(0,min(y2,y2′)−max(y1,y1′))
2.计算并集面积: 预测框面积 + 真实框面积 - 交集面积
Union = ( x 2 − x 1 ) ( y 2 − y 1 ) + ( x 2 ′ − x 1 ′ ) ( y 2 ′ − y 1 ′ ) − Intersection \text{Union} = (x_2 - x_1)(y_2 - y_1) + (x_2' - x_1')(y_2' - y_1') - \text{Intersection} Union=(x2−x1)(y2−y1)+(x2′−x1′)(y2′−y1′)−Intersection
3.计算 IoU:
IoU = Intersection Union (范围 [0, 1]) \text{IoU} = \frac{\text{Intersection}}{\text{Union}} \quad \text{(范围 [0, 1])} IoU=UnionIntersection(范围 [0, 1])
三、网络架构和各模块介绍
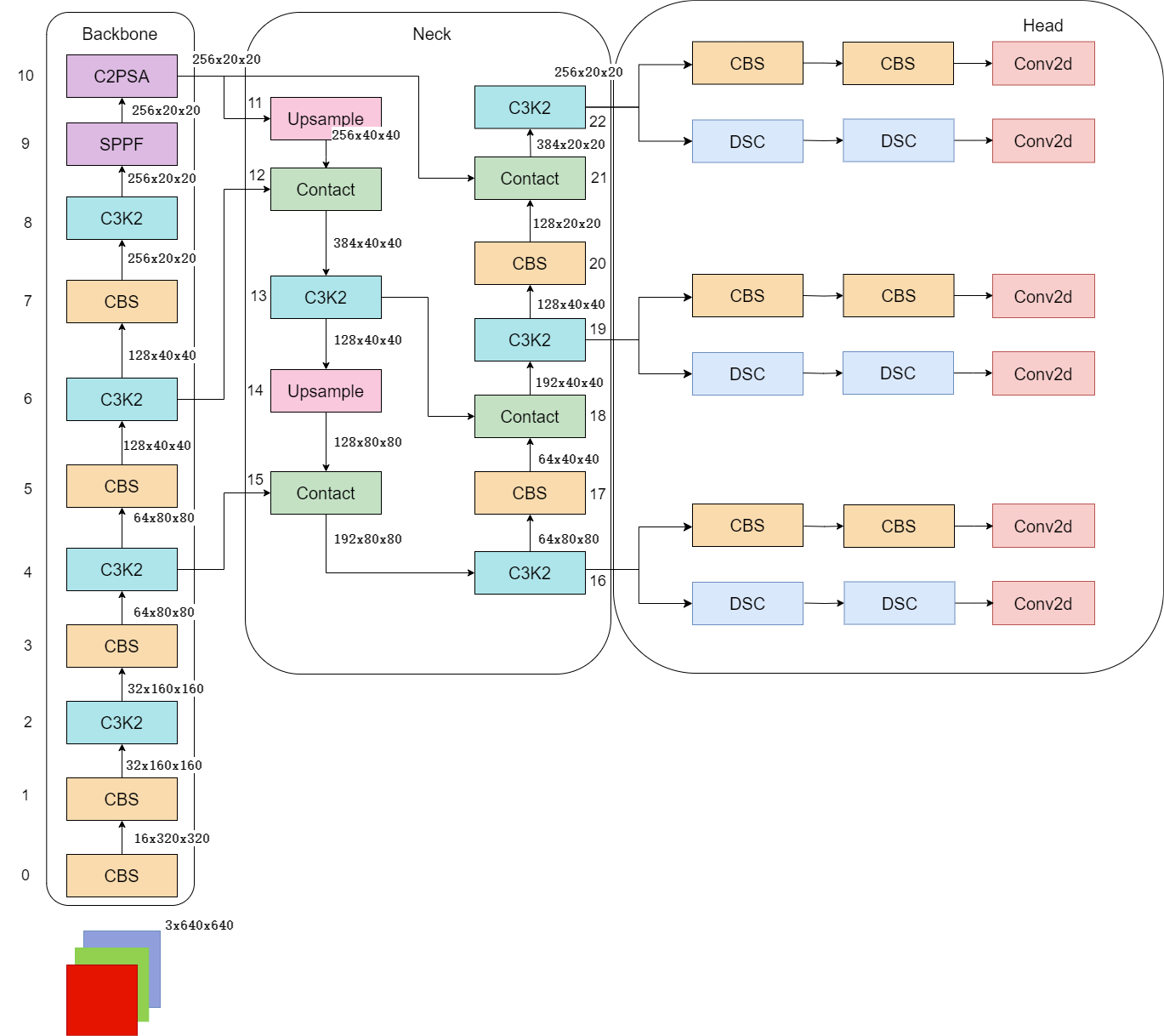
变化:
- 相比较于YOLOv8模型,其将CF2模块改成C3K2,同时在SPPF模块后面添加了一个C2PSA模块。
- 将YOLOv10的head思想引入到YOLO11的head中,使用深度可分离的方法,减少冗余计算,提高效率。
1.CBS模块
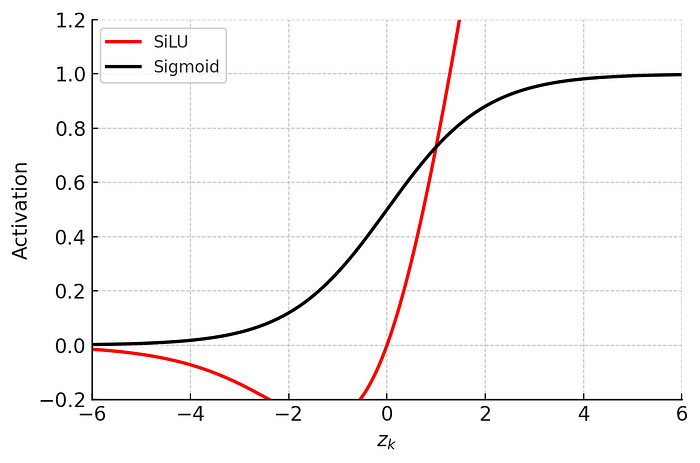
CBS:Conv + BN +SiLU
该块被命名为Conv块,通过2D卷积层,然后是2D批归一化层,最后是SiLU激活函数。
Silu激活函数:
BN:Batch Normalization(批归一化)
对每一批(batch)输入数据进行归一化处理,使其均值(mean)为0、方差(variance)为1,避免内部协变量偏移(Internal Covariate Shift),加速模型收敛。
公式:
1.输入数据: x ∈ R B × C × H × W ( B = 批大小, C = 通道数, H = 高度, W = 宽度) x \in \mathbb{R}^{B \times C \times H \times W}(B=批大小,C=通道数,H=高度,W=宽度) x∈RB×C×H×W(B=批大小,C=通道数,H=高度,W=宽度)
2.对每个通道 c c c 独立计算均值和方差:
μ c = 1 B ⋅ H ⋅ W ∑ b = 1 B ∑ h = 1 H ∑ w = 1 W x b , c , h , w , σ c 2 = 1 B ⋅ H ⋅ W ∑ b = 1 B ∑ h = 1 H ∑ w = 1 W ( x b , c , h , w − μ c ) 2 \mu_c = \frac{1}{B \cdot H \cdot W} \sum_{b=1}^{B} \sum_{h=1}^{H} \sum_{w=1}^{W} x_{b,c,h,w}, \sigma_c^2 = \frac{1}{B \cdot H \cdot W} \sum_{b=1}^{B} \sum_{h=1}^{H} \sum_{w=1}^{W} (x_{b,c,h,w} - \mu_c)^2 μc=B⋅H⋅W1b=1∑Bh=1∑Hw=1∑Wxb,c,h,w,σc2=B⋅H⋅W1b=1∑Bh=1∑Hw=1∑W(xb,c,h,w−μc)2
3.标准化: ϵ \epsilon ϵ 为极小常数(如 1e-5),防止除零。
x ^ b , c , h , w = x b , c , h , w − μ c σ c 2 + ϵ \hat{x}_{b,c,h,w} = \frac{x_{b,c,h,w} - \mu_c}{\sqrt{\sigma_c^2 + \epsilon}} x^b,c,h,w=σc2+ϵxb,c,h,w−μc
4.可学习的缩放与偏移: γ c \gamma_c γc(缩放)和 β c \beta_c βc(偏移)为可训练参数,每个通道独立。
y b , c , h , w = γ c ⋅ x ^ b , c , h , w + β c y_{b,c,h,w} = \gamma_c \cdot \hat{x}_{b,c,h,w} + \beta_c yb,c,h,w=γc⋅x^b,c,h,w+βc
γ γ γ 和 β β β 的本质:是模型对标准化分布的“修正参数”,赋予网络在标准化基础上自由调整分布形态的能力。
缩放参数 γ γ γ(Gamma):调整归一化后的数据的方差(分布宽度)。
- 若 γ γ γ>1:放大特征幅度,增强某些重要特征的贡献。
- 若 γ γ γ<1:缩小特征幅度,抑制噪声或冗余特征。
偏移参数 β β β(Beta):调整归一化后的数据的均值(分布中心)。
- 若 β β β>0:将分布向右平移,保留正向激活的优势。
- 若 β β β<0:将分布向左平移,适应负向激活的需求。
网络架构图: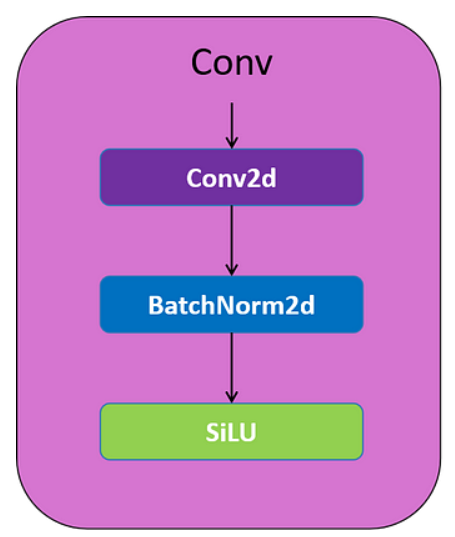
实现代码:
# conv.py
class Conv(nn.Module):
"""标准卷积块(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # 默认激活函数SiLu
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
# 定义卷积层 conv
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
# 定义批量归一化层 bn
self.bn = nn.BatchNorm2d(c2)
# 根据act参数确定激活函数
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
# 对输入特征图x进行处理先卷积,再归一化,再激活函数
return self.act(self.bn(self.conv(x)))
autopad(k, p, d):根据k、d的值,自动填充p的值,即padding加边。
stride=1时:输出特征图尺寸与输入相同(即H_out = H_in)。stride>1时:填充值适配下采样需求(如s=2时精确减半分辨率)。
在网络架构中:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- 输入:
-1表示来自前一层的输出,这里是初始为输入图像。 - 重复:
1 - 模块:标准卷积层。
- 参数:
[64, 3, 2]对应(c2, k, s)(输出通道、卷积核大小、步长)。- 输出通道:
64*0.25=16(width=0.25) - 卷积核 :
3x3 - 步长
2(下采样到1/2分辨率)
- 输出通道:
- 输出分辨率:
P1/2(输入尺寸的1/2)。
P1/2的含义:表示特征图的层级(Stage)和相对输入图像的下采样比例。
P1:表示这是第 1 个阶段的输出特征图(Stage 1)。
/2:表示当前特征图的分辨率是输入图像的 1/2(即下采样 2 倍)。(例如,输入图像大小为640x640,则P1/2的特征图大小为320x320。)
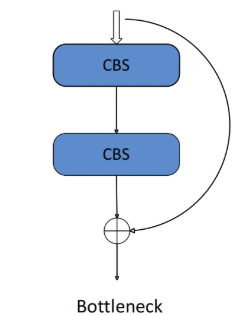
2.Bottleneck模块
先减少通道数(降维),然后再增加通道数。使总参数量减少,减少计算量。
标准瓶颈块结构(Bottleneck):两个卷积层+(可选)跳转连接(Shortcut),减少计算量并保持梯度流动。
网络架构图:
实现代码:
# block.py
class Bottleneck(nn.Module):
"""标准瓶颈块"""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e) # 隐藏层通道数
# 第一个卷积 cv1:一般降维
self.cv1 = Conv(c1, c_, k[0], 1)
# 第二个卷积 cv2:恢复原始维度
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
# 当输入输出通道数一致启用跳转连接
self.add = shortcut and c1 == c2
def forward(self, x):
# 如果true启用跳转连接
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
BottleneckCSP 模块
跨阶段部分网络(CSP)结构。将特征图分为两部分,一部分通过一系列瓶颈层,另一部分直接连接到输出,增强梯度多样性并减少计算量。
网络架构:
Identity or Conv:恒等映射(Identity)或卷积(Conv)操作。源代码:
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
- Identity:当
c1 == c_且cv2是简单的通道对齐(无实际计算需求)。- Conv:当
c1 != c_或需要特征变换时(如降维、升维)。
代码实现:
# block.py
class BottleneckCSP(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # 隐藏通道数
self.cv1 = Conv(c1, c_, 1, 1) # 分支1的初始卷积
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False) # 分支2的初始卷积
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False) # 分支1的末端卷积
self.cv4 = Conv(2 * c_, c2, 1, 1) # 合并后的输出卷积
self.bn = nn.BatchNorm2d(2 * c_) # 合并后特征归一化
self.act = nn.SiLU() # 激活函数
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n))) # 定义包含n个瓶颈层的序列 m
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x))) # 分支1:经过Bottleneck堆叠
y2 = self.cv2(x) # 分支2:直接卷积
# 合并:cat([y1, y2]) → BN → SiLU → cv4
return self.cv4(self.act(self.bn(torch.cat((y1, y2), 1))))
3.C3K2模块(C2f)
C2F:跨阶段部分聚焦,CSP-Focus。包含一个CBS块,将输出分成两半(其中通道被划分),它们通过一系列’n’瓶颈层进行处理,最后将每个层输出与最后的CBS块相连。这有助于增强特征图连接,而无需冗余信息。
C3K2:处理主干不同阶段的特征提取。继承于C2F模块。
CSP 瓶颈的一个更快更高效的变体,使用两个卷积层代替一个大的卷积层,从而加快了特征提取的速度。
当c3k这个参数为FALSE的时候,C3K2模块就是C2F模块,也就是说它的Bottleneck是普通的Bottleneck;反之当它为TRUE的时候,将Bottleneck模块替换成C3k模块。
网络架构:C2f和C3K2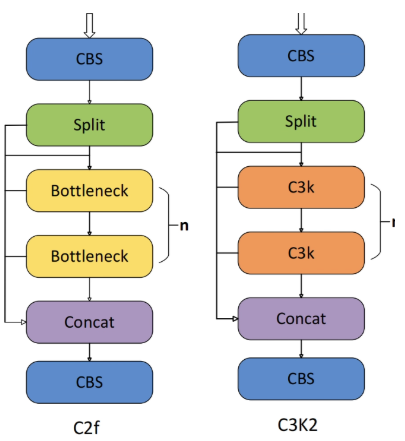
代码实现:
# block.py
class C3k2(C2f):
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(
# c3k==true 用C3k模块,false用Bottleneck模块
C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n)
)
class C2f(nn.Module):
"""用2个卷积层实现更快的CSP瓶颈"""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__()
self.c = int(c2 * e) # 隐藏通道数
# 两阶段卷积
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 将输入特征图通道数扩展为两倍,为后续分割做准备
self.cv2 = Conv((2 + n) * self.c, c2, 1) # 融合多分支特征(原始特征 + n 个 Bottleneck 的输出)
# 瓶颈块
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1)) # 将cv1的输出沿通道维度分成两部分得到y[0] 和 y[1]
y.extend(m(y[-1]) for m in self.m) # 对y的最后一个张量依次通过n个Bottleneck
# 最终 y 包含 2 + n 个张量
return self.cv2(torch.cat(y, 1)) # 沿通道维度拼接所有特征后通过cv2
在网络架构中:
scales:
# [depth, width, max_channels]
n: [0.50, 0.25, 1024]
...
# [from, repeats, module, args]
- [-1, 2, C3k2, [256, False, 0.25]] # 2
- 输入:
-1(第 1 层的输出)。 - 重复:
2*0.50=1次(因depth=0.5缩放)。 - 参数:
[256, False, 0.25]对应(c2, c3k, e)- 输出通道:
256*0.25=64(因width=0.25) c3k=False:不使用C3k模块,而是使用Bottleneck。e=0.25:隐藏层通道扩展因子为 0.25(hidden_channels = c2 * e = 256 * 0.25 = 64)。
- 输出通道:
- 输出分辨率:与输入相同。
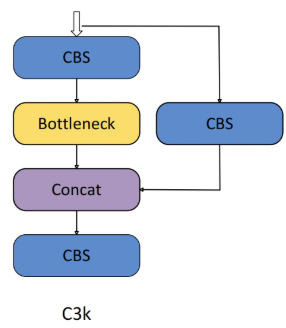
C3k模块(C3)
C3k 是一个更灵活的瓶颈模块,允许自定义核大小。继承于C3模块。
对于提取图像中更详细的特征非常有用。
网络架构:
代码实现:
# block.py
class C3k(C3):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # 隐藏层通道数
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n))) # 构建包含一系列瓶颈层的序列
# self.m = nn.Sequential(*(RepBottleneck(...)):可选的模块初始化方式,表示可以使用RepBottleneck(可重参数化的瓶颈模块)重参数化:
- 训练阶段:使用多分支复杂结构(如并联的 3x3 卷积、1x1 卷积 + BN)。
- 推理阶段:将多分支合并为单个卷积层,保持输出一致但速度更快。
RepBottleneck:训练更慢但推理更快。
- 训练时:多分支结构增强特征提取能力。
- 推理时:合并为单分支,减少计算量,提升速度。
class C3(nn.Module):
"""用3个卷积层的CSP瓶颈"""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__()
c_ = int(c2 * e) # 隐藏层通道数
self.cv1 = Conv(c1, c_, 1, 1) # 分支1:经过n瓶颈
self.cv2 = Conv(c1, c_, 1, 1) # 分支2
self.cv3 = Conv(2 * c_, c2, 1) # 合并分支后进行卷积
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
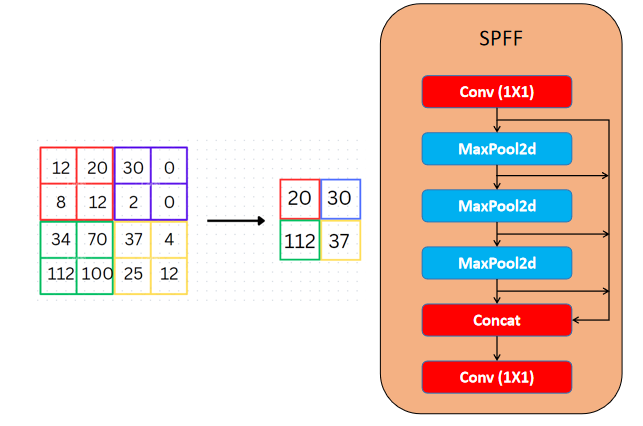
4.SPPF模块
SPPF(Spatial Pyramid Pooling Fast,快速空间金字塔池化):旨在以不同的尺度汇集图像不同区域的特征,将不同尺度的特征图通过多级池化融合,增强模型对多尺度目标的感知能力,特别是小物体。
使用多个最大池化操作(具有不同的内核大小)来聚合多尺度上下文信息。
网络架构图:
代码实现:
# block.py
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
"""
This module is equivalent to SPP(k=(5, 9, 13)).
"""
super().__init__()
c_ = c1 // 2 # 隐藏层通道数
self.cv1 = Conv(c1, c_, 1, 1) # 降维
self.cv2 = Conv(c_ * 4, c2, 1, 1) # 升维+融合
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) # 多级池化
def forward(self, x):
y = [self.cv1(x)]
y.extend(self.m(y[-1]) for _ in range(3))
return self.cv2(torch.cat(y, 1))
多级池化(
self.m):使用固定大小的池化核重复堆叠,模拟更大感受野,而计算量更少。源代码:
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
y1 = 5×5池化y2 = 5×5池化(y1)→ 等效9×9感受野y3 = 5×5池化(y2)→ 等效13×13感受野
padding=k // 2:保持输入和输出的空间尺寸不变,避免因尺寸收缩丢失边缘信息。
在网络架构中:
- [-1, 1, SPPF, [1024, 5]] # 9
- 输入:
-1(前一层的输出)。 - 重复:
1 - 参数:
[1024, 5]对应(c2, k)- 输出通道:
1024*0.25=256(因width=0.25) - 池化核大小
5x5。
- 输出通道:
- 输出分辨率:与输入相同。
5.C2PSA模块
C2PSA(跨阶段部分空间注意力):引入了注意力机制,通过强调特征图中的空间相关性,提高了模型对图像中重要区域的关注度。
扩展了C2f,引入PSA( Position-Sensitive Attention)块。
选择性地添加残差结构(shortcut)以优化梯度传播和网络训练效果。
使用FFN 可以将输入特征映射到更高维的空间,捕获输入特征的复杂非线性关系,允许模型学习更丰富的特征表示。
网络架构图:

代码实现:
# block.py
class C2PSA(nn.Module):
"""
这个模块本质上与PSA模块相同,但经过重构,允许堆叠更多PSABlock模块。
"""
def __init__(self, c1, c2, n=1, e=0.5):
super().__init__()
assert c1 == c2 # 检查输入通道数 c1 和输出通道数 c2 是否相等
self.c = int(c1 * e) # 隐藏层通道数
self.cv1 = Conv(c1, 2 * self.c, 1, 1) # 1x1 cv1:将输入特征图通道扩展为两倍,为后续分割做准备(split)
self.cv2 = Conv(2 * self.c, c1, 1) # 1x1 cv2:融合双分支特征(原始分支 + 注意力分支)
# 注意力模块
self.m = nn.Sequential(*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n))) #由 n 个 PSABlock 组成的序列,每个块处理 self.c 通道的输入
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1) # 通道分割为两部分
b = self.m(b) # 对分支b进行n次PSABlock处理
return self.cv2(torch.cat((a, b), 1)) # 拼接后融合
assert c1 == c2:断言代码,强制检查某个条件是否为真。检查输入通道数c1和输出通道数c2是否相等。
C2PSA模块要求输入和输出的通道数 必须相同(即c1 == c2)。类似的:残差网络(ResNet)要求跳转连接(shortcut)和主分支的输出通道相同,否则需要
1x1卷积调整维度。
在网络架构中:
- [-1, 2, C2PSA, [1024]] # 10
- 输入:
-1(前一层的输出)。 - 重复:
2*0.50=1次(因depth=0.5缩放)。 - 参数:
[1024]对应c2输出通道1024*0.25=256(因width=0.25) - 输出分辨率:与输入相同。
PSA模块
PSABlock:结合注意力机制(Attention)与卷积前馈网络(FFN)的轻量级特征增强模块。
- 通过注意力机制(
Attention)建模全局特征关系。 - 通过卷积前馈网络(
FFN)补充局部细节。 - 残差连接:可选是否使用跳跃连接(
shortcut)稳定训练并缓解梯度消失。
代码实现:
class PSABlock(nn.Module):
def __init__(self, c, attn_ratio=0.5, num_heads=4, shortcut=True) -> None:
'''
初始化参数:
c:输入/输出通道数(保持维度一致),
attn_ratio:注意力机制中键值对通道的压缩比例,
num_heads:多头注意力的头数,
shortcut:是否启用残差连接。
'''
super().__init__()
self.attn = Attention(c, attn_ratio=attn_ratio, num_heads=num_heads) # 注意力层
self.ffn = nn.Sequential(Conv(c, c * 2, 1), Conv(c * 2, c, 1, act=False)) # 前馈网络
self.add = shortcut
def forward(self, x):
x = x + self.attn(x) if self.add else self.attn(x) # 注意力分支 + 残差
x = x + self.ffn(x) if self.add else self.ffn(x) # FFN分支 + 残差
return x
Attention模块
具体代码细节此处不细讲。
Attention模块: 基于卷积的多头自注意力模块。
功能:对输入特征图进行空间-通道混合注意力计算。
实现:Attention(c, attn_ratio, num_heads)
- 通道分割:按
attn_ratio将输入通道分为Query和Key/Value。 - 多头注意力:将特征图划分为
num_heads组,分别计算注意力权重。 - 特征融合:加权聚合全局上下文信息。
输出:与输入同维度的增强特征。
FFN模块
FFN:卷积前馈网络。
提供非线性变换能力,增强局部特征表达。
结构:Conv(c → 2c → c)
- 第一层:1×1卷积扩展通道(
c → 2c),通常搭配激活函数(如SiLU)。 - 第二层:1×1卷积压缩通道(
2c → c),无激活函数(act=False)。
代码实现:self.ffn = nn.Sequential(Conv(c, c * 2, 1), Conv(c * 2, c, 1, act=False))
四、网络架构各部位介绍
1.head:检测和多尺度预测
YOLO11使用多尺度预测头来检测不同大小的物体。头部使用由backbone和neck生成的特征图输出三种不同尺度(低、中、高)的检测框。
检测头从三个特征图(通常来自P3、P4和P5)输出预测,对应于图像中的不同粒度级别。这种方法确保了小物体被更精细地检测到(P3),而较大的物体被更高级别的特征捕获(P5)。
网络架构图:
检测和分类的卷积是解耦的(decoupled)。

与YOLOv8的区别:YOLO11在head部分的cls分支上使用深度可分离卷积,降低计算量。
耦合头(Coupled Head)和解耦头(Decoupled Head):区别在于如何处理分类(Class)和回归(Box)任务的特征学习。
(分类关注语义,回归关注位置)

代码实现:
ch:输入通道数列表(如 [256, 512, 1024] 对应不同尺度的特征图)。
c2:回归分支的中间通道数(用于边界框预测)。
c3:分类分支的中间通道数(用于类别预测)。
# head.py->class Detect
self.cv2 = nn.ModuleList(
nn.Sequential(
Conv(x, c2, 3), # 特征提取:调整通道数 [x → c2]
Conv(c2, c2, 3), # 进一步特征细化 [c2 → c2]
nn.Conv2d(c2, 4 * self.reg_max, 1) # 输出回归参数 [c2 → 4*reg_max]
) for x in ch
) # 回归分支
self.cv3 = nn.ModuleList(
nn.Sequential(
nn.Sequential(
DWConv(x, x, 3), # 深度可分离卷积 [x → x]
Conv(x, c3, 1) # 通道扩展 [x → c3]
),
nn.Sequential(
DWConv(c3, c3, 3), # 二次空间特征提取 [c3 → c3]
Conv(c3, c3, 1) # 通道调整 [c3 → c3]
),
nn.Conv2d(c3, self.nc, 1), # 分类输出 [c3 → nc]
) for x in ch
) # 分类分支
self.cv2 回归分支分析
两阶段卷积:先通过两次 Conv 提取高质量特征,再映射到高维回归参数。
离散化输出:将连续回归问题转化为分类问题,提升小目标检测精度。
- 形状:
[B, 4 * self.reg_max, H, W](B:Batch Size(批量大小),H,W:特征图的高度和宽度) - 含义:
4对应边界框的四个偏移量(中心点x/y、宽度w、高度h)。self.reg_max表示每个偏移量的离散化概率分布(如用Softmax转换为16个区间的概率)。- 后续通过
Distribution Focal Loss学习偏移量的概率分布,再积分得到最终坐标。
self.cv3分类分支分析
深度可分离卷积:减少计算量,保留空间信息(适合分类任务)。
先保持输入通道(DWConv),再扩展至 c3。
最终使用1×1卷积压缩到类别数,轻量化输出,避免冗余计算。
- 形状:
[B, self.nc, H, W] - 含义:每个空间位置输出
self.nc维向量,表示各类别的得分。
DWConv代码实现:
DWConv:深度可分离卷积。执行深度可分离卷积,其中每个输入通道单独进行卷积。
class DWConv(Conv):
"""Depth-wise convolution."""
def __init__(self, c1, c2, k=1, s=1, d=1, act=True):
# 将 groups 参数设置为 c1 和 c2 的最大公约数,从而实现按通道分组卷积
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), d=d, act=act)
分割头部(
Segment)、姿态估计头部(Pose)均继承自Detect,这里不赘述。
其余网络架构中的
backbone和neck部分,博主学累了或许后续会补充= =
关于YOLO11官方配置文件.yaml文件详解可以看这篇文章:
2. YOLO11网络结构详细解析(以n版本为例)_yolov11网络结构图-CSDN博客
五、损失函数
Loss 计算包括 2 个分支: 分类和回归分支。
- 分类分支依然采用 BCE Loss。
- 回归分支使用了 Distribution Focal Loss(DFL Reg_max默认为16)+ CIoU Loss。
1.分类损失(Class Loss)
衡量预测类别与真实类别的差异。
- 使用二元交叉熵损失(BCE Loss)。
- 对每个锚点(Anchor)的多标签分类独立计算。
公式:二元交叉熵损失(BCE Loss)
L class = − ∑ i = 1 N ( y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ) L_{\text{class}} = -\sum_{i=1}^{N} \left( y_i \log(p_i) + (1-y_i) \log(1-p_i) \right) Lclass=−i=1∑N(yilog(pi)+(1−yi)log(1−pi))
- y i y_i yi: 真实标签 (0或1)
- p i p_i pi: 预测概率 (sigmoid输出)
2.边界框回归损失(Box Loss)
优化预测框的位置和尺寸。
- Distribution Focal Loss (DFL):将边界框偏移量(中心点x/y、宽/高)建模为离散化概率分布(
reg_max区间),通过Softmax和积分得到连续值。 - CIoU Loss:考虑重叠区域、中心点距离和宽高比。
DFL公式:
L DFL = − ∑ k = 1 reg_max ( y k log ( p k ) + ( 1 − y k ) log ( 1 − p k ) ) L_{\text{DFL}} = -\sum_{k=1}^{\text{reg\_max}} \left( y_k \log(p_k) + (1-y_k) \log(1-p_k) \right) LDFL=−k=1∑reg_max(yklog(pk)+(1−yk)log(1−pk))
- y k y_k yk: 目标分布 (如高斯分布)
- p k p_k pk: 预测分布 (softmax归一化)
CIoU:return iou - (rho2 / c2 + v * alpha)
将两个框最小能包住它们的“外接矩形”称为“convex box”,用它的宽和高来改进IoU的计算。
- GIoU在 IoU 基础上根据“外接矩形”对空白区域进行惩罚,从而在没有交集时训练效果更好。
- DloU还会计算两个框中心点之间的距离,与外接矩形对角线距离比较,用距离来惩罚。
- CIoU在 DIoU 的基础上再加上长宽比等因素,进一步提高回归精度。
参考文章
超详细!YOLO11模型架构详解、性能对比_yolov11-CSDN博客
2. YOLO11网络结构详细解析(以n版本为例)_yolov11网络结构图-CSDN博客
《双模态检测系列 一》一文看懂YOLO11(系列进化史+网络结构+源码目录)_yolov11多模态-CSDN博客
YOLO11全解析:从原理到实战,全流程体验下一代目标检测-CSDN博客
YOLO11 沉浸式讲解 YOLOV11网络结构以及代码剖析-CSDN博客
计算机视觉——YOLO11原理代码分块解读与模型基准对比测试_yolo11代码解析-CSDN博客
Ultralytics YOLO11 -Ultralytics YOLO 文档
YOLOv11小白的进击之路(六)创新YOLO的iou及损失函数时的源码分析_yolov11 iou-CSDN博客
计算机视觉——YOLO11原理代码分块解读与模型基准对比测试_yolo11代码解析-CSDN博客

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 62
62 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)