Python实现P-PSO优化算法优化XGBoost回归模型项目实战
摘要:本项目提出基于P-PSO算法优化XGBoost回归模型的方法,通过改进粒子群算法实现自动调参。使用包含10个特征的2000条数据进行实验,经80/20数据集划分后,模型取得0.843的R方值,均方误差4597.35,表明预测效果良好。项目完整展示了从数据预处理、特征分析到模型构建评估的全流程,提供了Python实现代码和数据,为复杂回归问题提供了高效解决方案,可应用于金融预测、工业优化等领域
说明:这是一个机器学习实战项目(附带数据+代码+文档),如需数据+代码+文档可以直接到文章最后关注获取。

1.项目背景
在大数据和人工智能技术快速发展的背景下,回归分析作为预测建模的核心工具,在金融预测、能源管理、工业优化等领域具有广泛的应用价值。XGBoost作为一种基于梯度提升决策树(GBDT)的高效机器学习算法,以其出色的性能和灵活性成为解决复杂回归问题的重要选择。然而,XGBoost模型的性能高度依赖于超参数的合理配置,而手动调参不仅效率低下,还难以应对高维、非线性的超参数空间。因此,如何通过自动化方法高效优化XGBoost模型的超参数,成为提升其预测精度的关键。
粒子群优化算法(PSO)是一种基于群体智能的优化算法,因其简单易实现、全局搜索能力强等特点,被广泛应用于各类优化问题中。然而,标准PSO算法在处理复杂的高维优化问题时容易陷入局部最优解,导致优化效果受限。为此,改进型P-PSO算法通过引入自适应权重调整策略和扰动机制,能够有效平衡全局探索与局部开发能力,从而更好地应对XGBoost模型中超参数优化的挑战。将P-PSO算法与XGBoost结合,不仅可以显著提升模型的回归性能,还能降低人工调参的时间成本。
本项目旨在通过Python实现P-PSO优化算法,对XGBoost回归模型的超参数进行自动化调优,并应用于实际数据集进行验证。通过对比实验,评估P-PSO优化算法相较于传统网格搜索和随机搜索方法的优势,为解决复杂回归问题提供一种高效、可靠的解决方案。同时,该项目也为进一步探索智能优化算法与机器学习模型的结合提供了实践参考和技术支持。
本项目通过Python实现P-PSO优化算法优化XGBoost回归模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
|
编号 |
变量名称 |
描述 |
|
1 |
x1 |
|
|
2 |
x2 |
|
|
3 |
x3 |
|
|
4 |
x4 |
|
|
5 |
x5 |
|
|
6 |
x6 |
|
|
7 |
x7 |
|
|
8 |
x8 |
|
|
9 |
x9 |
|
|
10 |
x10 |
|
|
11 |
y |
因变量 |
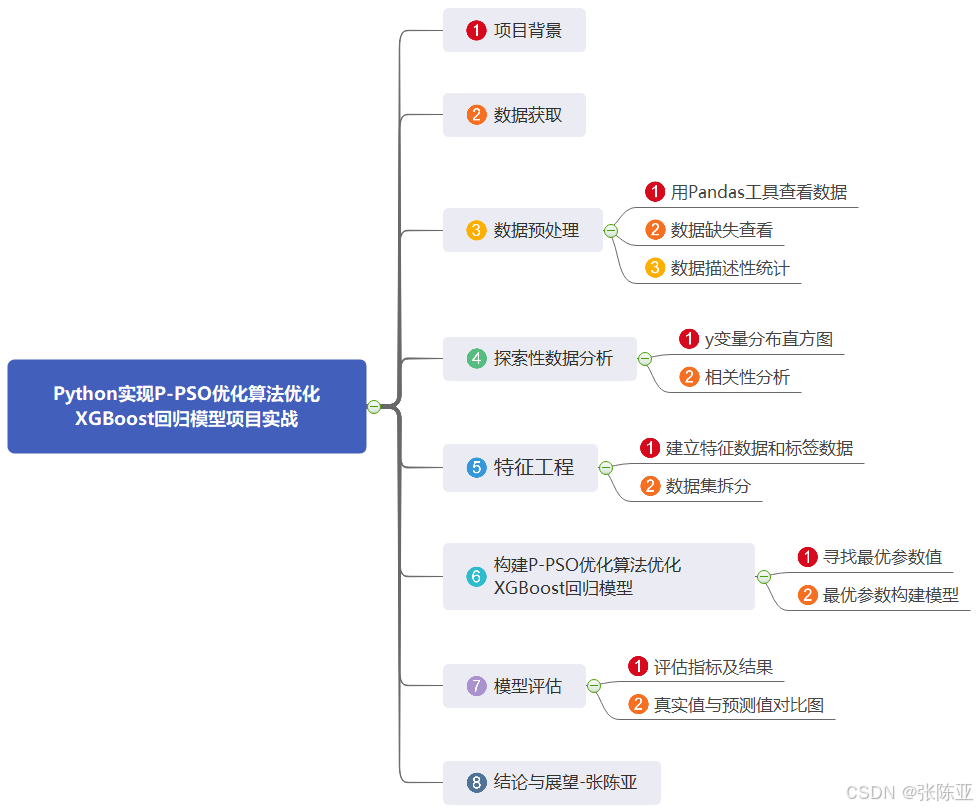
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

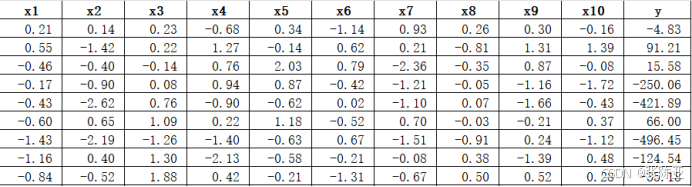
3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

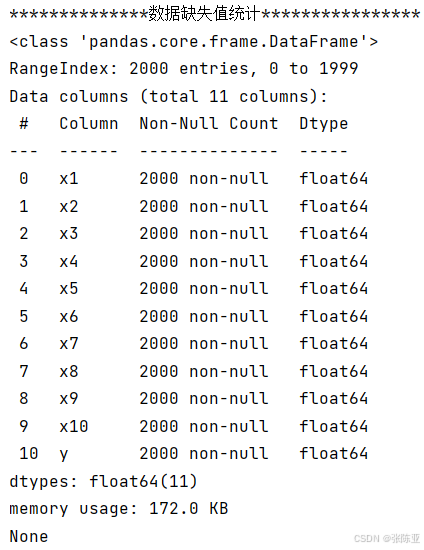
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
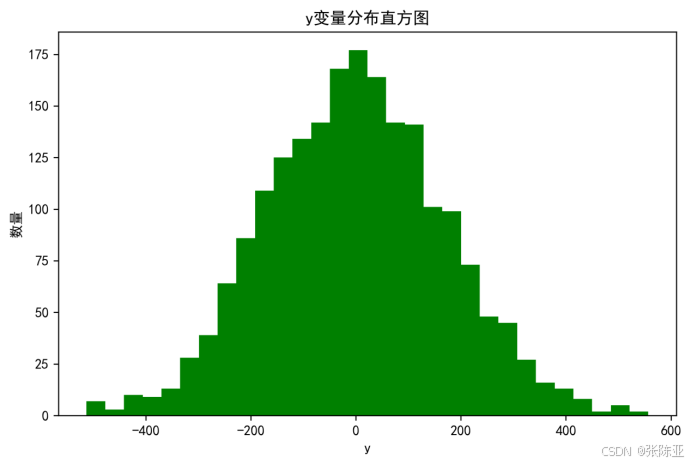
4.1 y变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.2 相关性分析
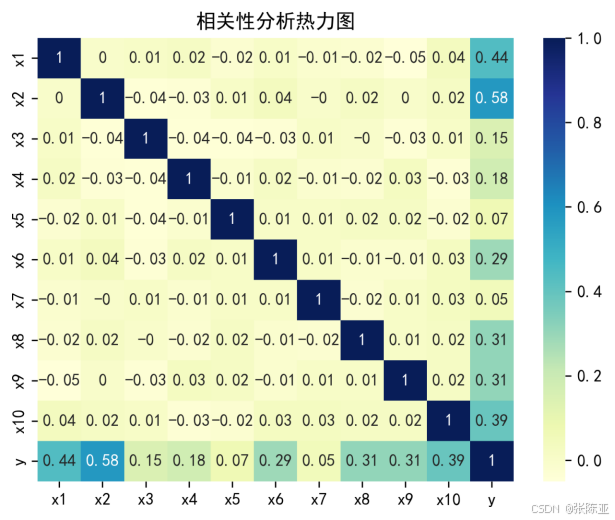
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6.构建P-PSO优化算法优化XGBoost回归模型
主要使用通过P-PSO优化算法优化XGBoost回归模型,用于目标回归。
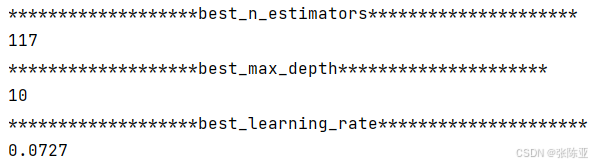
6.1 寻找最优参数值
最优参数值:
6.2 最优参数构建模型
|
编号 |
模型名称 |
参数 |
|
1 |
XGBoost回归模型 |
n_estimators=best_n_estimators |
|
2 |
max_depth=best_max_depth |
|
|
3 |
learning_rate=best_learning_rate |
7.模型评估
7.1评估指标及结果
评估指标主要包括R方、均方误差、解释性方差、绝对误差等等。
|
模型名称 |
指标名称 |
指标值 |
|
测试集 |
||
|
XGBoost回归模型 |
R方 |
0.843 |
|
均方误差 |
4597.3528 |
|
|
解释方差分 |
0.8435 |
|
|
绝对误差 |
53.8055 |
|
从上表可以看出,R方分值为0.843,说明模型效果良好。
关键代码如下:

7.2 真实值与预测值对比图
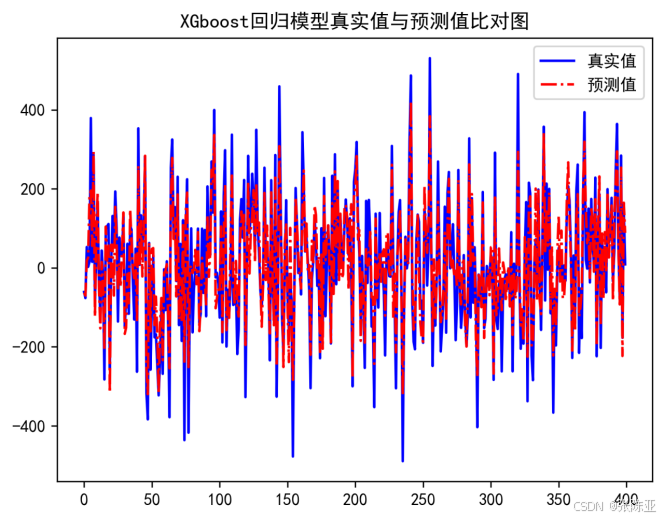
从上图可以看出真实值和预测值波动基本一致,模型效果良好。
8.结论与展望
综上所述,本文采用了Python实现P-PSO优化算法优化XGBoost回归算法来构建回归模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 28
28 0
0- 0



 已为社区贡献66条内容
已为社区贡献66条内容

所有评论(0)