数据可视化期末基础
数据可视化是指将抽象数据转换为直观图形的过程,通过图表、图形等视觉元素来表达数据。在大数据时代,各行业产生的数据量巨大,传统以表格呈现数据的方法已难以高效传达信息。数据可视化利用人类对图形的直观感知,将复杂数据转化为易于理解的图形和图表,帮助用户更快速地获取信息。核心意义:可视化使数据更加直观,降低理解门槛,人们能更容易发现数据中的模式和趋势。通过图形呈现,观察者可以快速抓住数据的重点,深入挖掘背
目录
★2. 格式塔(Gestalt)原则:接近原则、相似原则、闭合原则、连续原则
★2. 标签云、文档散、主题河流、文本流、故事流、文本弧、单词树、短语网络、星系视 图、主题地貌,掌握各图形所表达含义
Matplotlib (Mathematical Plotting Library 数学绘图库)
10. 树图、矩形树图、堆叠面积图、气泡图、茎叶图、密度图,掌握其含义
第一章 数据可视化概述
1. 可视化背景、目的、意义
(1)背景
随着信息技术和互联网的发展,数据呈现出爆炸式增长,尤其是进入大数据时代后,数据来源复杂多样(如传感器数据、网络日志、社交媒体、金融交易、医疗记录等)。这些庞大的数据量为决策、科研、商业分析等提供了巨大的资源,但也带来了数据理解与分析的挑战:
-
数据量巨大(Volume)
-
类型多样(Variety)
-
更新速度快(Velocity)
-
真实性问题(Veracity)
传统的数据分析手段已难以应对如此庞杂的数据,因此需要借助数据可视化技术来直观呈现数据的模式、趋势和异常,帮助人们更高效地洞察数据价值。
(2)目的
-
简化复杂数据
将复杂的、多维度的数据通过图形化手段简化成易理解的图表、图形或交互式界面。 -
辅助分析与决策
通过图形直观展现数据关系,帮助决策者快速把握整体趋势与细节,支持科学决策。 -
发现规律与异常
通过动态、交互式的可视化手段,有助于发现隐藏在数据背后的模式、关联性和异常点。 -
提升沟通效率
图形化表达可以帮助非专业人员理解复杂数据,提高数据交流的效率和准确性。
(3)意义
-
提高数据理解能力
-
促进跨领域沟通协作
-
增强决策的科学性与准确性
-
在科研、商业、教育、医疗等多个领域有广泛应用
-
是数据科学、大数据分析、人工智能等领域的重要组成部分
2. 大数据分析过程、可视化过程
(1)大数据分析过程(可按5个步骤理解)
| 步骤 | 内容描述 |
|---|---|
| 1. 数据采集 | 通过各种传感器、日志、网络、设备收集原始数据 |
| 2. 数据预处理 | 数据清洗、缺失值处理、格式转换、特征提取 |
| 3. 数据存储与管理 | 使用数据库、分布式存储系统(如Hadoop、Spark、NoSQL等)存储数据 |
| 4. 数据分析 | 采用统计分析、机器学习、深度学习等技术对数据建模分析 |
| 5. 数据可视化与应用 | 将分析结果通过图形化方式展示,支持实际应用和决策 |
(2)可视化过程(可以按以下流程掌握)
| 步骤 | 内容描述 |
|---|---|
| 1. 明确可视化目标 | 明确可视化的受众与目的(展示趋势?对比差异?找异常?) |
| 2. 数据准备 | 数据清洗、整理、结构化,确保数据质量 |
| 3. 选择合适图形 | 根据数据类型与分析目的选择(柱状图、折线图、散点图、热力图、地图等) |
| 4. 设计与美化 | 颜色搭配、标签清晰、图例合理,提升可读性 |
| 5. 交互设计(如需) | 提供筛选、缩放、联动等交互功能 |
| 6. 发布与应用 | 将可视化结果应用到报告、决策支持系统、仪表盘等 |
小结一句话
数据可视化是把复杂的数据“看得见、看得懂、看得出问题”,是大数据分析的重要环节。
★(3)大数据分析过程与可视化过程的关系
数据可视化既是大数据分析过程中的最后一个核心环节,同时又有自己独立的可视化技术流程。
| 大数据分析 | 可视化的介入位置 |
|---|---|
| 数据预处理后 | 做好数据准备,规范格式 |
| 分析建模后 | 将模型结果、指标、趋势做可视化展示 |
| 决策前 | 通过可视化帮助分析结论,更直观、更容易决策 |
第二章 数据可视化基础
1. 视觉感知的处理过程
视觉感知(Visual Perception)是数据可视化的基础。人通过视觉系统感知外界信息,在观察可视化图形时,主要经历以下几个处理过程:
| 阶段 | 说明 |
|---|---|
| 低层次处理(预注意阶段) | - 快速、自动地处理图形的基本特征,如颜色、位置、大小、方向等- 无需有意识的思考,数百毫秒内完成- 例如:一眼看出哪个柱子最高 |
| 中层次处理 | - 对多个视觉元素进行组织与分组- 依靠大脑已有经验和模式识别能力,例如 Gestalt 原则 |
| 高层次处理(认知阶段) | - 理解图形传达的含义,结合背景知识做出分析与决策- 需要有意识的思考和理解 |
小结一句话
总结一句话:视觉感知过程决定了可视化设计时应优先利用人类低层次快速处理能力,提升信息传达效率。
★2. 格式塔(Gestalt)原则:接近原则、相似原则、闭合原则、连续原则
格式塔(Gestalt)心理学研究人类如何自然地把复杂图形组织成有意义的整体。数据可视化中常用以下四个原则来优化图形设计:
| 原则 | 解释 | 示例 |
|---|---|---|
| 接近原则(Proximity) | 彼此接近的图形元素会被看作一组 | 将相关的数据点或图例放在一起,便于用户快速识别组别 |
| 相似原则(Similarity) | 形状、颜色、大小相似的元素被认为是同类 | 用相同颜色表示相同类别,辅助分类信息传达 |
| 闭合原则(Closure) | 人脑倾向于把不完整的图形自动补全成完整形状 | 当图形不完整时,观众依然能感知整体形状 |
| 连续原则(Continuity) | 视觉上连贯的线条或路径容易被看作一个整体 | 折线图中连续的趋势线容易被跟随感知 |
小结一句话
总结一句话:格式塔原则帮助可视化设计更自然、更易读、更有逻辑。
★3. 可视化编码、标记、视觉通道
(1)可视化编码(Visual Encoding)
可视化编码是指将数据映射成图形属性的过程。不同类型的数据适用不同的编码方式。
| 数据类型 | 常用编码方式 |
|---|---|
| 分类数据 | 颜色、形状、标记 |
| 数值数据 | 位置、长度、面积、颜色深浅 |
| 顺序数据 | 颜色渐变、大小渐变 |
(2)标记(Marks)
标记是图形的基本元素,不同的标记承载不同数据含义。常见标记有:
| 标记类型 | 示例 |
|---|---|
| 点(Points) | 散点图 |
| 线(Lines) | 折线图 |
| 区域(Areas) | 面积图、热力图 |
| 矩形(Bars) | 柱状图 |
| 文本(Text) | 标签、标题、坐标轴 |
(3)视觉通道(Visual Channels)
视觉通道是指图形的可视属性,用于表达数据的不同维度。合理利用视觉通道有助于提高图形的表达力。
| 视觉通道 | 说明 |
|---|---|
| 位置(Position) | 空间位置最容易被精确感知,最有效 |
| 长度(Length) | 如柱状图的柱高 |
| 方向(Orientation) | 如箭头方向 |
| 颜色(Color) | 分类、顺序信息 |
| 形状(Shape) | 分类信息 |
| 大小(Size) | 表示数量、强度 |
| 纹理(Texture) | 辅助区分不同区域 |
| 饱和度(Saturation) | 强调、区分 |
小结一句话
总结一句话:好的可视化要合理选择标记与视觉通道,充分利用人眼对不同视觉编码的敏感度。
第三章 文本数据可视化
★1. 大数据中文本可视化的基本流程
文本数据具有非结构化、维度高、语义复杂的特点。在大数据环境下,对文本数据进行可视化一般遵循以下流程:
| 步骤 | 说明 |
|---|---|
| 文本采集 | 从社交媒体、新闻、论文、评论、论坛等多渠道获取原始文本数据 |
| 文本预处理 | 去噪音、分词、去停用词、词形还原、拼写纠正等,规范化文本格式 |
| 特征提取 | 提取关键词、主题、情感、实体等特征,转换为可分析的数据结构(如词频矩阵、TF-IDF、主题模型等) |
| 降维与建模 | 通过聚类、主题建模(如LDA)、情感分析、词嵌入(如Word2Vec)等手段对高维数据进行建模 |
| 可视化呈现 | 选择合适的图形化方式展示文本分析结果,帮助理解语义结构、主题分布和情感趋势 |
| 交互与分析 | 提供筛选、钻取、时间序列分析等交互手段,支持更深入的洞察 |
小结一句话
总结一句话:文本可视化的核心是把原始文本通过预处理、建模、抽象,最后转化成可理解、可操作的图形。
★2. 标签云、文档散、主题河流、文本流、故事流、文本弧、单词树、短语网络、星系视 图、主题地貌,掌握各图形所表达含义
2. 各类文本可视化图形及其含义
(1)标签云(Word Cloud)
-
核心含义:用词的字体大小、颜色、粗细表示词频或权重
-
适用场景:快速展示文本中关键词的重要性和出现频率
-
优点:直观易懂,快速呈现高频词
-
缺点:无法体现词与词之间的语义关系
-
图形编码方式:词频 → 字体属性
-
标记(Mark):文字
-
视觉通道(Visual Channel):大小、颜色、粗细、位置
(2)文档散(Document Scatter)
-
核心含义:将文档或段落降维(如用 PCA、t-SNE 等),在二维或三维空间中按相似性散布
-
适用场景:展示文档之间的语义相似性和分布结构
-
优点:能发现聚类、异常文档、主题分布
-
缺点:降维方法可能存在信息损失
-
图形编码方式:相似性 → 空间位置
-
标记(Mark):点
-
视觉通道(Visual Channel):位置、颜色、大小、形状
(3)主题河流(Theme River)
-
核心含义:以河流状展示随时间演化的主题权重变化
-
适用场景:展示主题随时间变化的趋势与交替情况
-
优点:清晰反映主题演化
-
缺点:过多主题会造成视觉混乱
-
图形编码方式:时间 → X轴位置,主题权重 → 带宽
-
标记(Mark):面积带(区域)
-
视觉通道(Visual Channel):位置、长度(宽度)、颜色
(4)文本流(Text Flow)
-
核心含义:文本随时间或逻辑顺序的流动路径,可看作是主题河流的延伸
-
适用场景:呈现文本信息流动和事件发展过程
-
优点:适合故事线或事件追踪
-
图形编码方式:事件顺序 → 路径走势
-
标记(Mark):路径曲线
-
视觉通道(Visual Channel):位置、方向、颜色、粗细
(5)故事流(Story Flow)
-
核心含义:突出不同故事线之间的交叉、并行和发展轨迹
-
适用场景:分析复杂新闻、多线叙事、多方观点互动的文本
-
优点:能够突出不同故事主体的演进和交互
-
图形编码方式:故事线 → 曲线路径
-
标记(Mark):路径线、节点
-
视觉通道(Visual Channel):位置、颜色、弯曲程度、粗细
(6)文本弧(Text Arc)
-
核心含义:将文本内容沿弧形展开,同时展示词频、词序与共现关系
-
适用场景:展示全文结构、词语分布及其关系
-
优点:同时兼顾词序与频次
-
缺点:不适合文本量极大时使用
-
图形编码方式:词序 → 弧形位置,词频 → 字体大小
-
标记(Mark):文字、弧线
-
视觉通道(Visual Channel):位置(弧长)、大小、颜色、弯曲度
(7)单词树(Word Tree)
-
核心含义:以某个词为根节点,展示其后续(或前序)高频搭配词语
-
适用场景:分析短语搭配、固定表达模式、词汇使用习惯
-
优点:可观察关键词的常见用法与语法搭配
-
图形编码方式:搭配关系 → 树状结构
-
标记(Mark):节点、连线
-
视觉通道(Visual Channel):位置(层级)、文字大小、连线粗细、颜色
(8)短语网络(Phrase Network)
-
核心含义:通过网络图展现词语或短语之间的共现关系或语义联系
-
适用场景:发现关键词之间的关联性与语义网络结构
-
优点:适合挖掘潜在主题与语义场
-
图形编码方式:共现关系 → 边连接,词频 → 节点属性
-
标记(Mark):节点、边
-
视觉通道(Visual Channel):位置、连接、节点大小、颜色、边粗细
(9)星系视图(Galaxy View)
-
核心含义:将文档或主题看作星系中星体,依语义距离排列形成簇状结构
-
适用场景:展现大规模文本主题分布与聚类关系
-
优点:直观展示复杂语义空间结构
-
缺点:计算复杂度高,交互难度大
-
图形编码方式:语义距离 → 空间位置
-
标记(Mark):点、星体
-
视觉通道(Visual Channel):位置、颜色、大小、亮度
(10)主题地貌(Topic Landscape)
-
核心含义:用地形图的高低起伏表示不同主题的权重与重要性
-
适用场景:展示主题空间结构、重要性、密集度
-
优点:视觉效果直观、有层次感,适合宏观把握主题格局
-
图形编码方式:权重 → 高度
-
标记(Mark):表面网格、地形曲面
-
视觉通道(Visual Channel):高度、颜色、阴影、纹理
小结一句话
文本数据可视化的重点在于:抽取合适的特征,选对可视化方法,帮助理解复杂语义结构。
Matplotlib (Mathematical Plotting Library 数学绘图库)
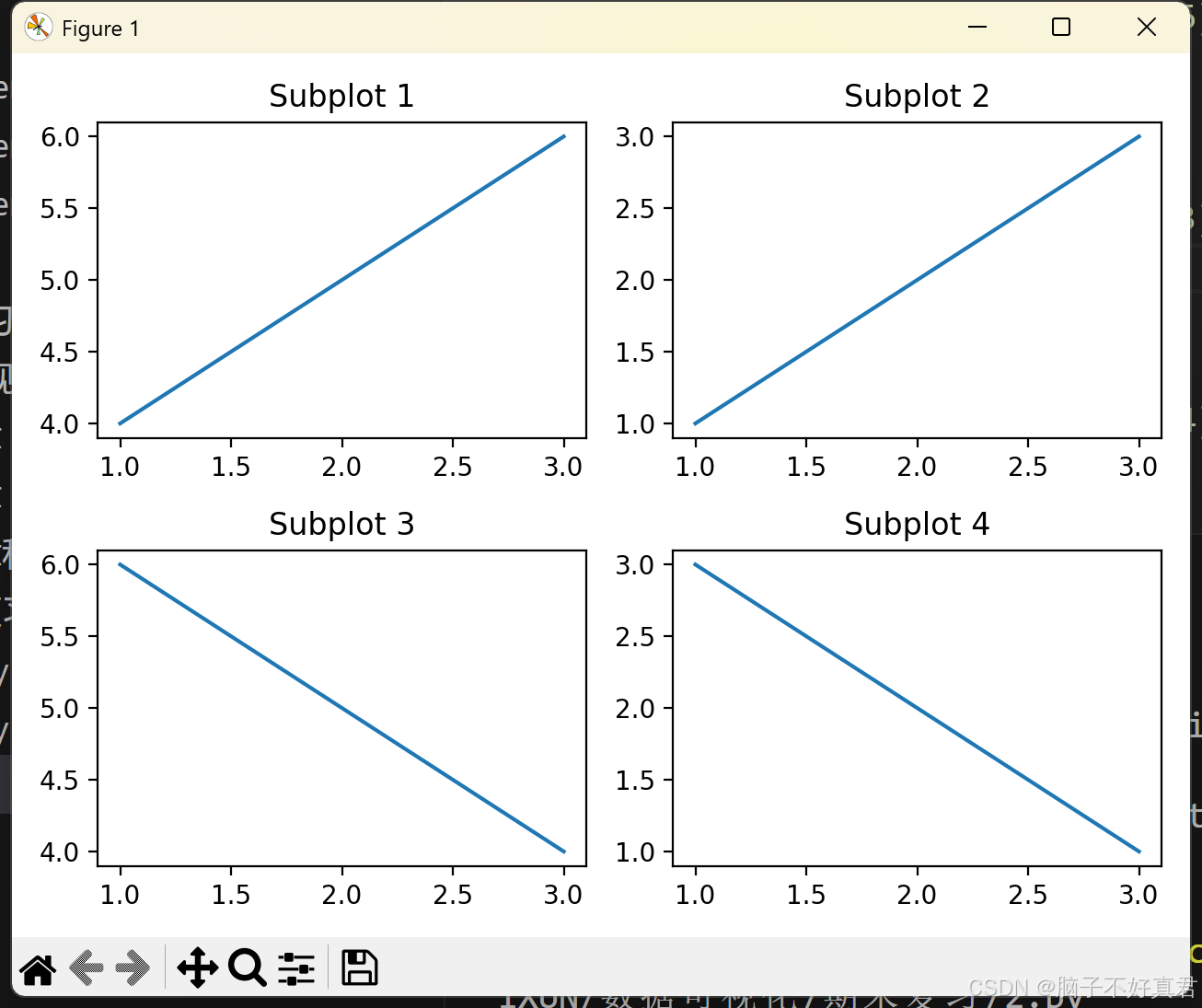
1. 子图的绘制方法(subplot)
功能:在一个窗口中画多张图
import matplotlib.pyplot as plt
# 创建2行2列的子图
plt.subplot(2, 2, 1)
plt.plot([1, 2, 3], [4, 5, 6])
plt.title("Subplot 1")
plt.subplot(2, 2, 2)
plt.plot([1, 2, 3], [1, 2, 3])
plt.title("Subplot 2")
plt.subplot(2, 2, 3)
plt.plot([1, 2, 3], [6, 5, 4])
plt.title("Subplot 3")
plt.subplot(2, 2, 4)
plt.plot([1, 2, 3], [3, 2, 1])
plt.title("Subplot 4")
plt.tight_layout() # 避免标题重叠
plt.show()
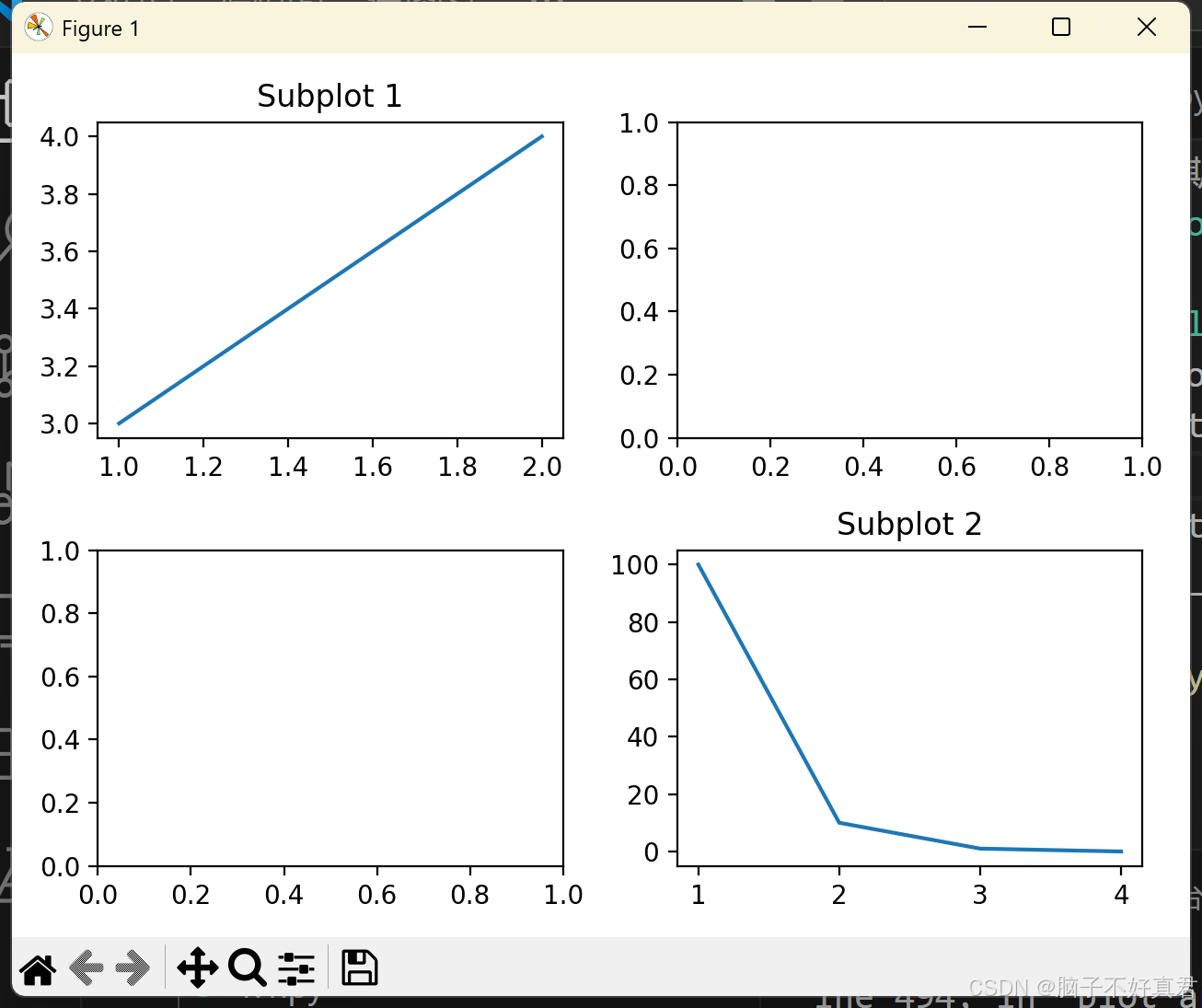
plt.subplots()
import matplotlib.pyplot as plt
fig, axs = plt.subplots(2, 2)
axs[0, 0].plot([1, 2], [3, 4])
axs[0, 0].set_title("Subplot 1")
axs[1,1].plot([1,2,3,4],[100,10,1,0])
axs[1,1].set_title("Subplot 2")
plt.tight_layout()
plt.show()
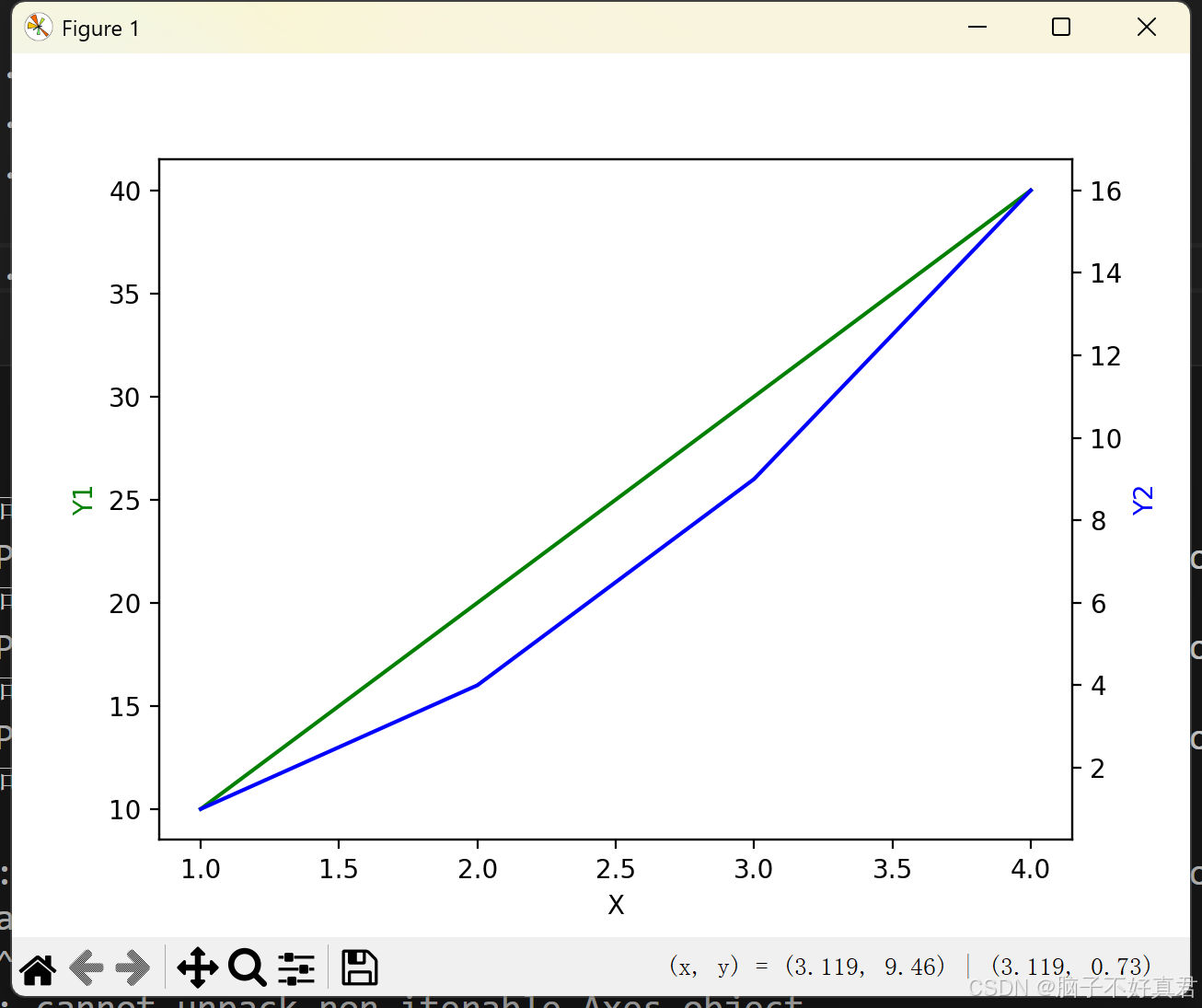
2. 双轴图的绘制方法(twinx)
import matplotlib.pyplot as plt
x = [1, 2, 3, 4]
y1 = [10, 20, 30, 40]
y2 = [1, 4, 9, 16]
fig, ax1 = plt.subplots()
ax2 = ax1.twinx() # 共享x轴
ax1.plot(x, y1, 'g-') # 绿色实线('g-')
ax2.plot(x, y2, 'b-') # 蓝色实线('b-')
ax1.set_xlabel("X")
ax1.set_ylabel("Y1", color='g')
ax2.set_ylabel("Y2", color='b')
plt.show()
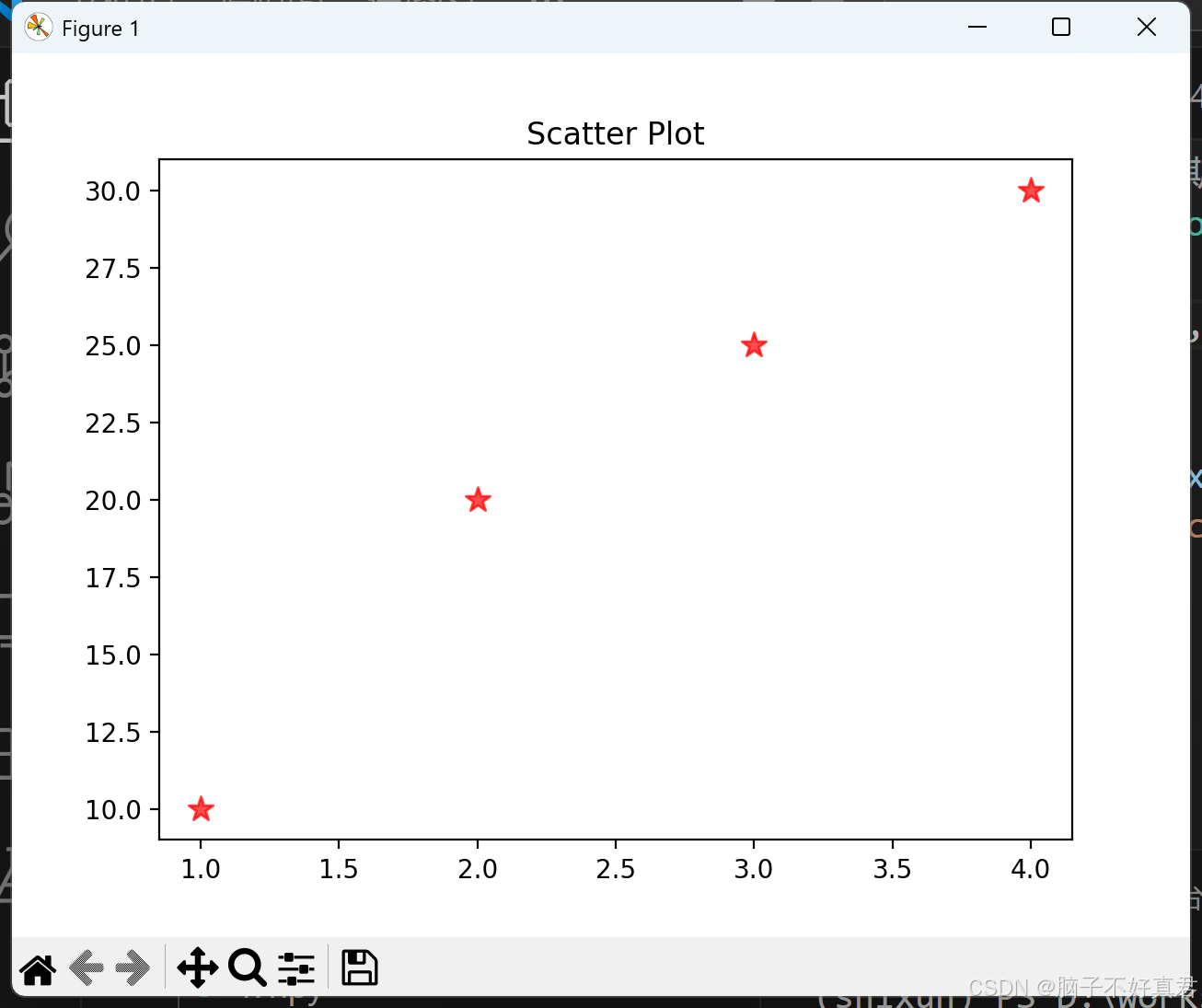
3. 散点图的绘制方法及属性
import matplotlib.pyplot as plt
x = [1, 2, 3, 4]
y = [10, 20, 25, 30]
plt.scatter(x, y, s=100, c='red', marker='*', alpha=0.7)
plt.title("Scatter Plot")
plt.show()
-
s: 点的大小
-
c: 颜色
-
marker: 形状
-
alpha: 透明度
4. 折线图的绘制方法及属性
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 7, 11]
plt.plot(x, y, linestyle='--', color='b', marker='o', linewidth=2)
plt.title("Line Plot")
plt.show()
-
linestyle: 线型
'-' '--' '-.' ':' -
marker: 点型
o s ^ * -
linewidth: 线宽
5. 柱状图
普通柱状图
import matplotlib.pyplot as plt
x = ['A', 'B', 'C']
y = [10, 20, 15]
plt.bar(x, y, color='skyblue')
plt.show()
多组柱状图(调整水平位置)
import numpy as np
import matplotlib.pyplot as plt
labels = ['A', 'B', 'C']
men = [20, 35, 30]
women = [25, 32, 34]
x = np.arange(len(labels)) # 自动生成与分类数量相同的一组横坐标位置
width = 0.35
plt.bar(x - width/2, men, width, label='Men', color='skyblue') # x + width/2 → 控制柱子的横坐标位置
plt.bar(x + width/2, women, width, label='Women', color='pink') # width → 控制每根柱子的宽度
plt.legend()
plt.xticks(x, labels) # 把数字位置映射回你真正想显示的分类名称
plt.show()
堆叠柱状图
import matplotlib.pyplot as plt
import numpy as np
labels = ['A', 'B', 'C']
men = [20, 35, 30]
women = [25, 32, 34]
x = np.arange(len(labels))
width = 0.35
plt.bar(x, men, width)
plt.bar(x, women, width, bottom=men) # 注意bottom=men
plt.show()
水平柱状图
import matplotlib.pyplot as plt
x = ['A', 'B', 'C']
y = [10, 20, 15]
plt.barh(x, y)
plt.show()
6. 直方图(连续型数据)
import numpy as np
import matplotlib.pyplot as plt
data = np.random.randn(1000) # 生成 1000 个符合标准正态分布(均值0、方差1)的随机数
plt.hist(data, bins=20, color='green', edgecolor='black')
plt.show()
-
bins: 分组数量
-
edgecolor: 边界颜色
plt.hist(data, bins=20, color='green', edgecolor='black')
参数 含义 data要可视化的数据(1000个随机数) bins=20把数据范围划分成 20 个等宽区间(即 20 个柱子) color='green'填充柱子的颜色是绿色 edgecolor='black'每个柱子的边界线颜色是黑色,增强可读性
7. 饼图
import matplotlib.pyplot as plt
labels = ['A', 'B', 'C', 'D']
sizes = [15, 30, 45, 10] # 每个扇区的数值,表示占比的绝对值(实际绘图时会自动转换成百分比)
plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=90, explode=[0, 0.1, 0, 0])
plt.axis('equal') # 保证饼图是圆的
plt.show()
-
labels: 标签
-
autopct: 显示百分比
-
startangle: 旋转角度
-
explode: 突出显示某部分
| 参数 | 作用 | 备注 |
|---|---|---|
sizes |
数据序列 | 扇区大小 |
labels=labels |
扇区标签 | A/B/C/D |
autopct='%1.1f%%' |
显示百分比格式 | 保留 1 位小数,例如 15.0% |
startangle=90 |
起始角度 | 从 90 度开始绘制(即从正上方顺时针开始) |
explode=[0, 0.1, 0, 0] |
突出某一扇区 | 把第 2 个扇区 (B) 往外移 0.1 单位(高亮效果) |
环状图
import matplotlib.pyplot as plt
labels = ['A', 'B', 'C', 'D']
sizes = [15, 30, 45, 10]
plt.pie(sizes, labels=labels, wedgeprops={'width':0.4})
plt.show()
| 参数 | 作用 |
|---|---|
sizes |
控制扇区大小 |
labels=labels |
设置每个扇区的名称 |
wedgeprops={'width':0.4} |
控制扇区宽度,形成环形效果 |
8. 颜色
颜色缩写:
-
r= red -
g= green -
b= blue -
y= yellow -
c= cyan -
m= magenta -
k= black -
w= white
plt.plot(x, y, color='r')
9. 箱型图与提琴图
箱型图(Box Plot)
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(100)
plt.boxplot(data)
plt.show()展示中位数、四分位数、异常值。
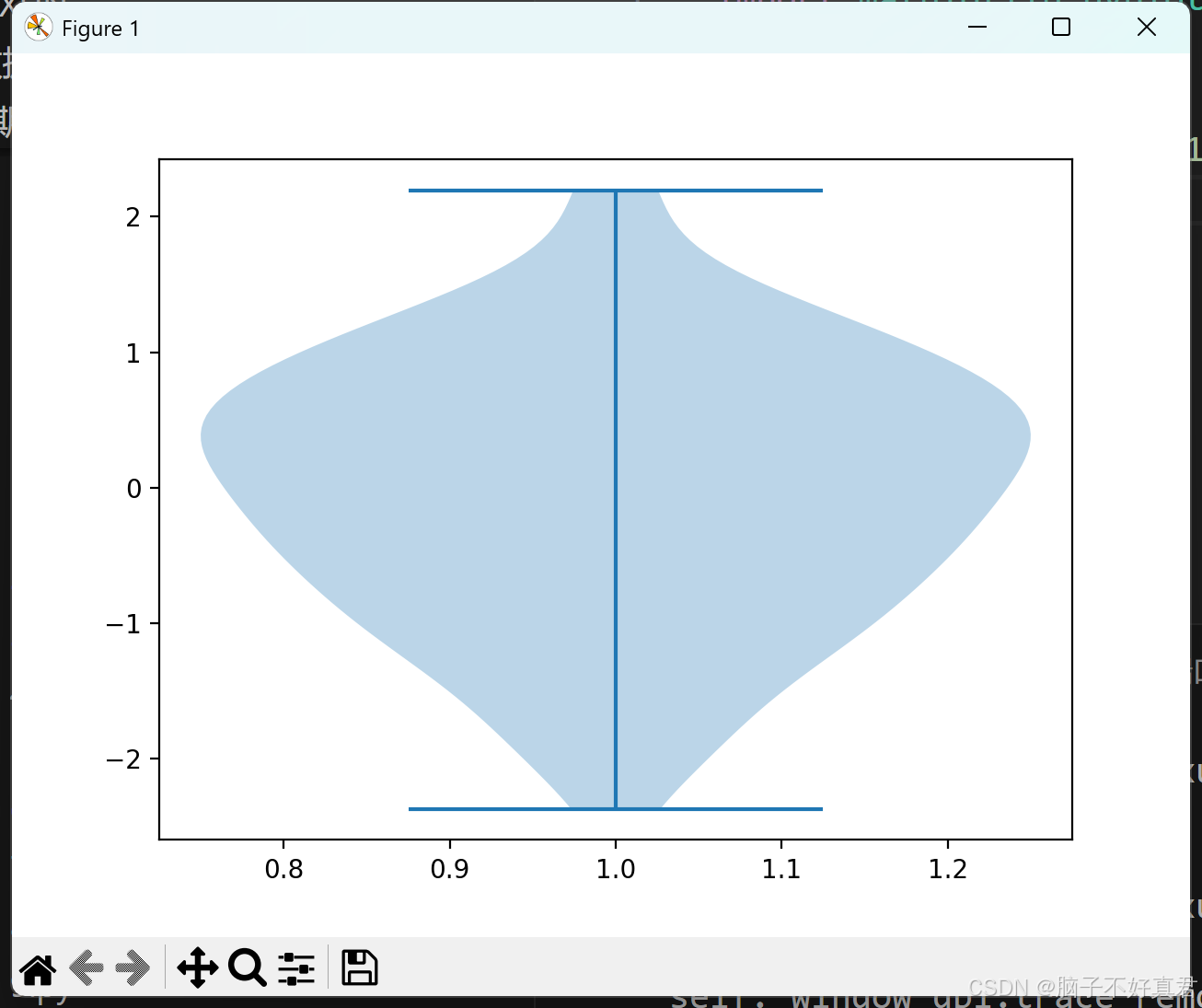
提琴图(Violin Plot)
import matplotlib.pyplot as plt
import numpy as np
data = np.random.randn(100)
plt.violinplot(data)
plt.show()
结合了箱型图和核密度估计,显示数据分布形状。
10. 树图、矩形树图、堆叠面积图、气泡图、茎叶图、密度图,掌握其含义
1. 树图(TreeMap)
-
含义:
用矩形面积表示各部分在整体中的占比,层级结构清晰可见。 -
适用场景:
资源分配、市场份额、文件系统空间占用等可视化。
2. 矩形树图(其实就是树图的另一种叫法)
-
含义:
与树图本质相同,也是用矩形块表现层次和占比。 -
适用场景:
强调分类层次和各类别权重。
3. 堆叠面积图(Stacked Area Chart)
-
含义:
通过多层累加的面积展示各部分随时间或序列变化的贡献与总量。 -
适用场景:
多类别时间序列变化趋势分析(如收入结构随年份变化)。
4. 气泡图(Bubble Chart)
-
含义:
在散点图基础上,用气泡大小表示第三个变量。 -
适用场景:
三维数据关系展示(如GDP-人口-寿命关系)。
5. 茎叶图(Stem-and-Leaf Plot)
-
含义:
将数据按数位分解,兼顾列表与分布信息,展示数据集中趋势和离散程度。 -
适用场景:
小样本数据分布快速展示。
6. 密度图(Density Plot)
-
含义:
使用平滑曲线表示数据的概率分布,通常是直方图的平滑替代。 -
适用场景:
观察数据的集中程度、峰值、分布形态。
公式写法
1.核心语法格式
r'$ 公式内容 $'
| 组成部分 | 作用 |
|---|---|
r'' |
原生字符串,防止 \ 出现转义 |
$...$ |
表示数学公式区域 |
| 公式内容 | 按照 LaTeX 语法编写公式 |
2.使用位置
| 场景 | 示例 |
|---|---|
| 标题 | plt.title(r'$公式$') |
| x轴标签 | plt.xlabel(r'$公式$') |
| y轴标签 | plt.ylabel(r'$公式$') |
| 注释 | plt.text(x, y, r'$公式$') |
3.常用公式写法
import matplotlib.pyplot as plt
from matplotlib import rcParams
# 全局设置字体为 SimHei(黑体),适合支持绝大多数中文
rcParams['font.family'] = 'SimHei'
plt.figure(figsize=(6, 8))
plt.text(0.1, 0.9, r'希腊字母: $\alpha, \beta, \gamma, \pi, \sigma$', fontsize=12)
plt.text(0.1, 0.8, r'上标: $x^2 + y^2 = z^2$', fontsize=12)
plt.text(0.1, 0.7, r'下标: $a_{ij}$', fontsize=12)
plt.text(0.1, 0.6, r'分数: $\frac{a}{b}$', fontsize=12)
plt.text(0.1, 0.5, r'求和: $\sum_{i=1}^n x_i$', fontsize=12)
plt.text(0.1, 0.4, r'平方根: $\sqrt{x}$', fontsize=12)
plt.text(0.1, 0.3, r'综合公式: $y = \alpha + \beta x + \epsilon$', fontsize=12)
plt.axis('off')
plt.show()


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)