1.高光谱数据集深度学习分类和代码分析(实践代码)一
本文摘要: 本文实现了一个基于2D-CNN的高光谱图像分类模型,针对Salinas数据集进行农作物分类。主要流程包括:1)环境配置与随机种子固定;2)GPU选择与显存优化;3)数据加载与预处理,包括PCA降维至30维;4)3×3光谱-空间patch生成;5)数据划分与类别平衡处理;6)构建包含Conv-BN-MP层的CNN模型;7)训练评估与整图预测可视化。创新点在于采用PCA降维降低数据维度,通
下面是我的代码全流程
| # | 步骤 | 关键代码条目 | 说明 |
|---|---|---|---|
| 1 | 环境与随机种子 | import …; random.seed(42) |
引入依赖 + 固定随机性,确保可复现 |
| 2 | GPU 选择与显存策略 | tf.config.set_visible_devices(…) |
仅用 /GPU:1 并启用显存渐进分配 |
| 3 | 超参数与路径常量 | WINDOW_SIZE=3、NUM_COMPONENTS=30… |
统一管理 patch 尺寸、PCA 维数等 |
| 4 | 数据加载 | def load_data() |
读取 Salinas_corrected.mat & Salinas_gt.mat |
| 5 | PCA 光谱降维 | def apply_pca() |
**PCA 降到 30 维,降低噪声、保留主成分 |
| 6 | 生成光谱-空间 patch | def create_patches() |
对 3 × 3 窗加反射填充;暂时跳过背景标签 0 |
| 7 | 标签处理 & One-Hot | to_categorical(patch_labels, …) |
标签从 1…N → 0…N-1,转独热 |
| 8 | 训练/验证/测试划分 | train_test_split(…, stratify=…) |
三七分,再拆验证;保持类别分布 |
| 9 | 弱类过采样 | def oversampleWeakClasses() |
计算「最大类 / 当前类」倍率,随机复制少数类样本 |
| 10 | 数据增强 | def AugmentData() |
随机上下/左右翻 & ±30°旋转 |
| 11 | 2-D CNN 架构 | def build_model() |
32-64-128 Conv → BN → MP → GAP → Dense;Dropout ×2;Softmax |
| 12 | 训练、评估与整图预测 | model.fit(...);extract_patches() |
训练 ;评估 test_acc;滑窗预测整幅影像并 spectral.imshow() 可视化 |
| 13 | 精度优化方向 | 用 MNF 替代 PCA;添加注意力机制等 |
提升精度 |
一. 数据集说明:
Salinas 的高光谱图像数据集,一个广泛用于遥感和机器学习研究的经典高光谱数据集。这
个数据集由美国航空航天局(NASA)的 Airborne Visible/Infrared Imaging Spectrometer
(AVIRIS)传感器收集,包含多个农田区域的光谱数据。
Salinas 数据集中的一张典型图像包括多个波段,每个波段对应不同的光谱范围,反映了地
表不同类型的植被、土壤和其他物质的特性。这些图像常被用来进行分类任务,例如区分不
同类型的作物、土壤类型等。
二. 图像数据说明
-
高光谱图像的每个像素并不是一个单纯的数值,而是一个包含多个波段反射率的向量,也可以理解为“一个小型的光谱”:
如果图像尺寸是 (H=512, W=217, B=204),那么,每个像素的位置 (i, j) 对应一个 204 维的波段向量;也就是说,
每个像素其实是一个 204 维的光谱样本。所以,每个像素都可以视为一个训练样本,它的“特征”是波形(即 204 个波段的光谱值), 它的“标签”是该像素在 Salinas_gt.mat 中对应的类别值(1~16)。
| 术语 | 含义 |
|---|---|
| 一个像素 | 一条 204 维的光谱曲线,即一个样本 |
| 一个波段 | 所有像素在同一波长下的反射率图 |
| 标签 | 每个像素在 Salinas_gt 中的编号 |
| 背景像素(值为0) | 没有地物标记,暂用作训练样本 |
三. 逐步代码与逻辑解析
(我运行代码的环境:tensorflow-gpu 2.10.0, python 3.8.5, CUDA 最高支持 11.4)
1. 导入环境与固定随机种子
import numpy as np
import scipy
import scipy.io as sio
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Dropout, Flatten, BatchNormalization, GlobalAveragePooling2D
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
import random, os
import spectral
random.seed(42)
np.random.seed(42)
tf.random.set_seed(42)
- 意义:锁定随机数生成器,保证每次运行得到同一结果。
- 影响:网络权重初始化、数据增强随机旋转、oversample 随机洗牌都是确定性的。
2. GPU 选择与显存策略
gpu_device = "/GPU:1" # 指定 GPU 1
physical_devices = tf.config.list_physical_devices('GPU')
if len(physical_devices) > 1:
tf.config.set_visible_devices(physical_devices[1], 'GPU')
tf.config.experimental.set_memory_growth(physical_devices[1], True) # 启用显存增长
- 只占用第 2 块 GPU(索引 1),防止与其他任务抢资源。
- 开启 memory growth,TensorFlow 仅按需申请显存,避免一次性占满。
3. 全局超参数
WINDOW_SIZE = 3 # patch 宽/高
NUM_COMPONENTS = 30 # PCA 后保留的光谱维度
BATCH_SIZE = 64
EPOCHS = 100
LEARNING_RATE = 1e-3
- 窗口大小=3 ⇒ patch shape = 3×3×30。
- NUM_COMPONENTS=30 来源于经验:Salinas 原始波段 = 224,PCA 留 30 已涵盖 >99 % 信息。
- 其余为常规训练超参。
4. 数据加载
def load_data(data_path=DATA_PATH, label_path=LABEL_PATH):
data_cube = sio.loadmat(data_path)['salinas_corrected']
label_mat = sio.loadmat(label_path)['salinas_gt']
print("Data cube shape:", data_cube.shape)
print("Label matrix shape:", label_mat.shape)
return data_cube, label_mat
- 返回 (512, 217, 224) 的光谱立方体 & (512, 217) 标签矩阵。
- Salinas 数据共 16 个作物类别(标签 1–16,0 为背景),这次代码中暂时去掉了背景0标签样本。
5. PCA 光谱降维(本 Notebook 的主要改进处)
def apply_pca(cube, num_components=NUM_COMPONENTS):
h, w, b = cube.shape
# 将cube重新塑形为二维数组
reshaped = cube.reshape(-1, b)
scaler = StandardScaler()
reshaped = scaler.fit_transform(reshaped)
pca = PCA(n_components=num_components, whiten=True, random_state=42)
# 对reshaped进行PCA降维处理
pca_data = pca.fit_transform(reshaped)
# 将降维后的数据重新塑形为原始的形状
return pca_data.reshape(h, w, num_components)
- PCA降维,降低维度后重新调整为原始的形状。
6. 生成 patch
# 暂时去除label == 0 的背景
def create_patches(cube, labels, window=WINDOW_SIZE):
margin = window // 2
h, w, c = cube.shape
pad_cube = np.pad(cube, ((margin, margin), (margin, margin), (0,0)), mode='reflect')
pad_labels = np.pad(labels, ((margin, margin), (margin, margin)), mode='reflect')
patches, patch_labels = [], []
for i in range(margin, h + margin):
for j in range(margin, w + margin):
label = pad_labels[i, j]
if label == 0: # background
continue
patch = pad_cube[i-margin:i+margin+1, j-margin:j+margin+1, :]
patches.append(patch)
patch_labels.append(label)
return np.array(patches), np.array(patch_labels)
- 反射填充 解决边缘像素窗口不足问题。
- 得到
patches.shape = (N_samples, 3, 3, 30)。
7. 标签独热编码
y_cat = to_categorical(patch_labels, num_classes)
- 必须在 oversample / train_test_split 前完成,以便类别对齐。
8. 训练 / 验证 / 测试划分
TEST_RATIO = 0.1
VAL_RATIO = 0.1
X_train, X_temp, y_train, y_temp = train_test_split(
patches, y_cat, test_size=TEST_RATIO+VAL_RATIO, random_state=42, stratify=patch_labels)
# 再分出验证集和测试集
val_ratio_adjusted = VAL_RATIO / (TEST_RATIO + VAL_RATIO)
X_val, X_test, y_val, y_test = train_test_split(
X_temp, y_temp, test_size=val_ratio_adjusted, random_state=42,
stratify=np.argmax(y_temp, axis=1))
- 0.8/0.1/0.1 划分,stratify 保持每类比例不失衡。
9. 弱类过采样
def oversampleWeakClasses(X, y, seed=42):
#y是多标签数组,shape是 (样本数, 16),需要逐标签进行操作
uniqueLabels = np.unique(y)
maxCount = np.max([np.sum(y[:, i] == 1) for i in range(y.shape[1])])
labelInverseRatios = maxCount / np.array([np.sum(y[:, i] == 1) for i in range(y.shape[1])])
newX = []
newY = []
for i in range(y.shape[1]):
cX = X[y[:, i] == 1]
cY = y[y[:, i] == 1]
repeat_count = round(labelInverseRatios[i])
cX = cX.repeat(repeat_count, axis=0)
cY = cY.repeat(repeat_count, axis=0)
newX.append(cX)
newY.append(cY)
newX = np.concatenate(newX, axis=0)
newY = np.concatenate(newY, axis=0)
np.random.seed(seed)
rand_perm = np.random.permutation(newY.shape[0])
newX = newX[rand_perm, :]
newY = newY[rand_perm]
return newX, newY
- y 为独热矩阵:逐列统计,再复制少数类 patch → 新训练集更均衡。
- 后续需要优化:这种简单重复采样易引入过拟合。
10. 数据增强
def AugmentData(X_train):
for i in range(int(X_train.shape[0]/2)):
patch = X_train[i,:,:,:]
num = random.randint(0,2)
if (num == 0):
flipped_patch = np.flipud(patch)
if (num == 1):
flipped_patch = np.fliplr(patch)
if (num == 2):
no = random.randrange(-180,180,30)
flipped_patch = scipy.ndimage.interpolation.rotate(patch, no,axes=(1, 0),reshape=False, output=None, order=3, mode='constant', cval=0.0, prefilter=False)
patch2 = flipped_patch
X_train[i,:,:,:] = patch2
return X_train
- 对一半样本做随机翻转 / 30° 步进旋转,用
scipy.ndimage.rotate。 - 在高光谱场景中,类似于行拍数据。
11. 2D CNN 网络
model = Sequential([
Conv2D(32, (3,3), activation='relu', padding='same', input_shape=(3,3,30)),
BatchNormalization(),
Conv2D(64, (3,3), activation='relu', padding='same'),
BatchNormalization(),
MaxPooling2D((2,2)),
Dropout(0.3),
Conv2D(128, (3,3), activation='relu', padding='same'),
BatchNormalization(),
GlobalAveragePooling2D(), # 减少参数,保留全局特征
Dense(128, activation='relu'),
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
model.compile(optimizer=Adam(LEARNING_RATE),
loss='categorical_crossentropy',
metrics=['accuracy'])
- 卷积核全部 3 × 3:适配 3 × 3 patch。
- GAP 替换 Flatten:参数量骤减,过拟合风险降低。
12. 训练、评估与整幅预测
# Train
history = model.fit(X_train, y_train,
validation_data=(X_val,y_val),
epochs=EPOCHS, batch_size=BATCH_SIZE, shuffle=True)
test_loss, test_acc = model.evaluate(X_test, y_test, batch_size=BATCH_SIZE)
训练指标:
# 用测试集进行测试
test_loss, test_acc = model.evaluate(X_test, y_test, batch_size=BATCH_SIZE)
print(f"Test accuracy: {test_acc:.4f}, Test loss: {test_loss:.4f}")
测试指标: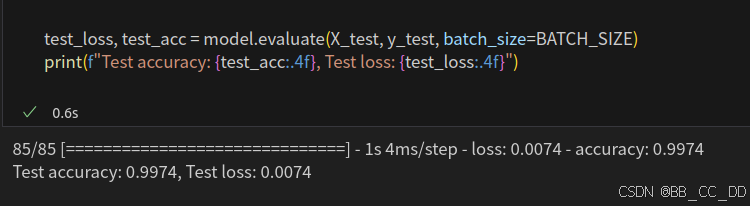
-
训练完成后:
- 用
extract_patches()对整张 Salinas 图像滑窗; - 批量
model.predict()→outputs; spectral.imshow(classes=outputs.astype(int))可视化分类图。
- 用
- 以下是运行结果,包含PCA到80维度的结果:(这次背景0类别不在训练集中)
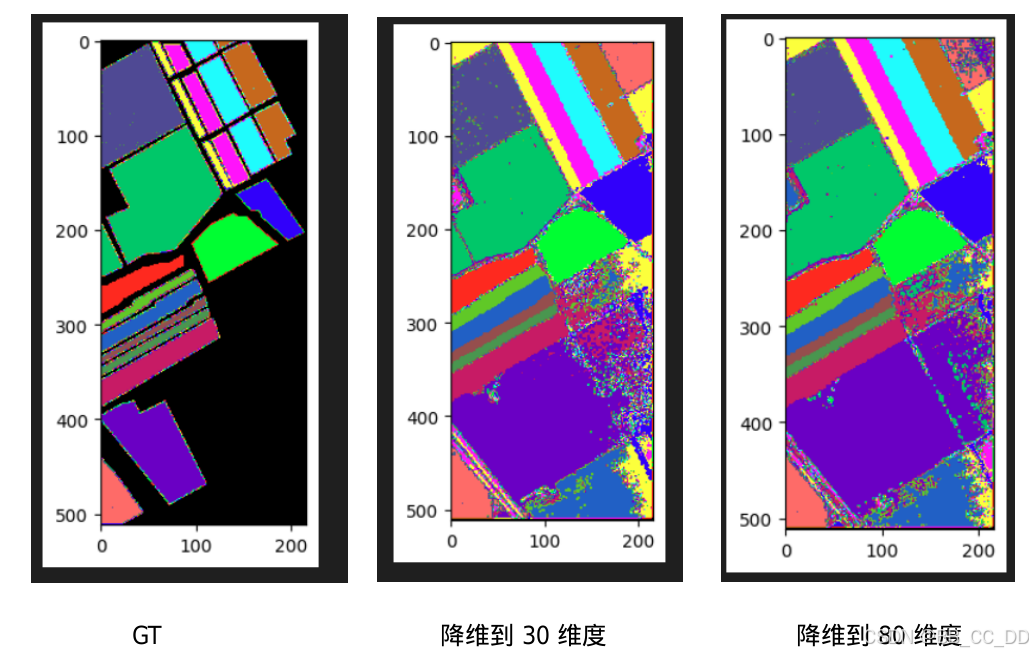 PCA降维到30和80的区别:
PCA降维到30和80的区别:
精度相对应提升了一些,但训练和推理时间都加长了,在精度和速度的平衡点,需要根据自己的项目进行调整。
13. 精度优化方向
- 1. 新增背景0类别数据,加入到数据集中用于训练。
- 2. 添加注意力机制:例如把 SE block 嵌入每个 Conv2D 后。
- 3. Class-Balanced Focal Loss:让模型在难分 & 弱类上加权,更快拉高 mIoU。
- 4. 用 MNF 替代 PCA:MNF先按噪声协方差做降噪再降维。
- 5. CutMix / MixUp 到 HSI:减少网络把同一 patch 视为绝对真值,减少过拟合。
- 6. 对输入先加一层 Conv3D,再走现有 2D:同时捕获光谱局部相关性。
- 7. CRF 全图细化:对预测 label 图用全连接 CRF。
<未完待续,持续更新中>
参考网址:
http://ch.whu.edu.cn/cn/supplement/4aaba617-5d57-4342-b0c5-913e564e332c
http://ch.whu.edu.cn/cn/article/id/301

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)