【AI论文】ProRL:延长的强化学习扩展了大型语言模型的推理边界
摘要:本研究挑战了强化学习(RL)仅放大语言模型已有能力的观点,提出通过Prolonged RL(ProRL)训练可发现全新推理策略。ProRL方法整合KL散度控制、策略重置和多样化任务,在16,000 GPU小时的训练后,模型在数学、代码等任务上pass@1准确率提升14.7%-54.8%,特别解决了基础模型完全失败的场景。研究表明RL能持续扩展推理边界,其效果取决于基础模型能力和训练时长。虽然
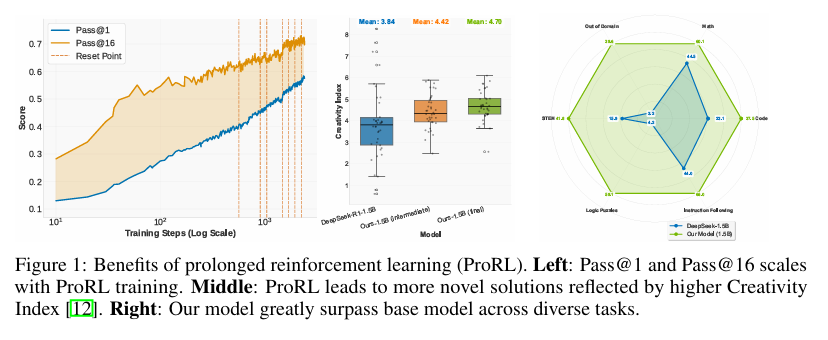
摘要:以推理为中心的语言模型的最新进展突显了强化学习(RL)作为一种将模型与可验证的奖励对齐的有前景的方法。 然而,RL是否真正扩展了模型的推理能力,还是仅仅放大了基础模型分布中已经存在的高回报输出,以及不断扩展RL计算是否能够可靠地提高推理性能,这些问题仍然存在争议。 在这项工作中,我们通过证明延长的RL(ProRL)训练可以发现基础模型无法访问的新颖推理策略,即使在广泛的采样下也是如此,从而挑战了流行的假设。 我们介绍了一种新的训练方法ProRL,该方法结合了KL散度控制、参考策略重置和一系列不同的任务。 我们的实证分析表明,在广泛的pass@k评估中,RL训练的模型始终优于基础模型,包括基础模型无论尝试次数多少都完全失败的场景。 我们进一步表明,推理边界的改进与基础模型的任务能力和训练持续时间密切相关,这表明强化学习可以随着时间的推移探索和填充新的解决方案空间区域。 这些发现为RL在语言模型中有意义地扩展推理边界的条件提供了新的见解,并为未来长视野RL推理的工作奠定了基础。 我们发布了模型权重以支持进一步的研究:Github。Huggingface链接:Paper page,论文链接:2505.24864
研究背景和目的
研究背景
近年来,以推理为中心的语言模型在人工智能领域取得了显著进展,其中最具代表性的是OpenAI的O1和DeepSeek的R1等模型。这些模型通过扩展测试时间计算(test-time computation),实现了长链思维(Chain-of-Thought, CoT)和复杂的推理行为,从而在数学问题求解、代码生成等复杂任务上取得了显著提升。在这一过程中,强化学习(Reinforcement Learning, RL)成为了开发高级推理能力的关键技术。RL通过优化可验证的客观奖励,而非学习到的奖励模型,来减轻奖励黑客(reward hacking)的风险,并更紧密地与正确的推理过程对齐。
然而,关于RL是否真正扩展了语言模型的推理能力,还是仅仅放大了基础模型分布中已经存在的高回报输出,学术界存在广泛争议。一些研究认为,RL训练的模型并没有获得超出基础模型的新推理能力,其性能提升主要源于对已有解决方案的采样效率优化。此外,RL训练的计算需求巨大,且训练过程中容易出现熵坍缩(entropy collapse)和不稳定等问题,这也限制了RL在推理任务中的广泛应用。
研究目的
本研究旨在挑战上述流行假设,通过引入一种名为Prolonged Reinforcement Learning (ProRL) 的新型训练方法,证明延长的RL训练能够发现基础模型无法访问的新颖推理策略。具体目标包括:
- 验证RL对推理能力的扩展作用:通过实证分析,证明RL训练的模型在广泛的任务评估中优于基础模型,尤其是在基础模型完全失败的场景下。
- 探索ProRL训练方法的有效性:通过结合KL散度控制、参考策略重置和多样化的任务套件,开发一种稳定的长时间RL训练方法。
- 分析推理边界的改进与任务能力和训练时间的关系:揭示基础模型的任务能力和训练持续时间对推理边界改进的影响。
- 为未来长视野RL推理研究奠定基础:通过发布模型权重,支持进一步的研究,并探索RL在更广泛推理任务中的应用潜力。
研究方法
1. ProRL训练方法
本研究引入了ProRL训练方法,该方法包含以下关键组件:
- KL散度控制:在RL目标函数中加入KL散度惩罚项,以保持当前策略与参考策略之间的相似性,防止策略过早收敛到局部最优解。
- 参考策略重置:定期重置参考策略,并重新初始化优化器状态,以避免策略在长时间训练过程中发生漂移,保持训练的稳定性。
- 多样化任务套件:构建了一个包含136K个问题的多样化训练数据集,涵盖数学、代码、STEM、逻辑谜题和指令跟随等多个领域,以鼓励模型在广泛的推理任务中进行泛化。
2. 模型架构与训练设置
本研究基于NVIDIA的DeepSeek-R1-Distill-Qwen-1.5B模型进行开发,通过ProRL训练方法得到了Nemotron-Research-Reasoning-Qwen-1.5B模型。训练过程中使用了Group Relative Policy Optimization (GRPO)算法,并设置了高采样温度以鼓励探索。训练在48个NVIDIA H100-80GB节点上进行,总GPU小时数约为16,000小时。
3. 评估方法
本研究在多个基准测试集上对模型进行了评估,包括数学、代码、STEM推理和指令跟随等任务。评估指标包括pass@1和pass@k(k=16, 128等),用于衡量模型在不同采样次数下的性能。此外,还使用了创造力指数(Creativity Index)来量化模型推理轨迹的新颖性。
研究结果
1. 推理能力的显著提升
实验结果表明,ProRL训练的Nemotron-Research-Reasoning-Qwen-1.5B模型在多个任务上显著优于基础模型DeepSeek-R1-Distill-Qwen-1.5B。具体而言,在数学、代码、STEM推理和指令跟随等任务上,ProRL模型的pass@1准确率分别提升了14.7%、13.9%、25.1%和18.1%。此外,在逻辑谜题任务上,ProRL模型实现了54.8%的性能提升,甚至在某些任务上达到了100%的通过率。
2. 推理边界的扩展
通过对比基础模型和ProRL模型在不同任务上的表现,研究发现ProRL训练能够显著扩展模型的推理边界。特别是在基础模型初始表现较差的任务上,ProRL训练带来的性能提升最为显著。这表明ProRL能够探索并填充新的解决方案空间区域,从而发现基础模型无法访问的新颖推理策略。
3. 创造力指数的提升
创造力指数分析表明,ProRL训练的模型在推理轨迹上表现出更高的新颖性。随着训练时间的延长,模型的创造力指数逐渐增加,表明模型在推理过程中生成了更多与预训练语料库重叠度较低的新颖解决方案。
4. 持续训练的有效性
实验还发现,ProRL训练在超过2000个训练步骤后仍然能够带来持续的性能提升。这表明通过延长RL训练时间,模型可以不断探索和优化新的推理策略,从而实现推理能力的持续提升。
研究局限
尽管本研究取得了显著成果,但仍存在以下局限性:
- 计算资源需求巨大:ProRL训练需要大量的计算资源,这对于资源有限的小型组织或研究人员来说可能是一个障碍。
- 可扩展性担忧:虽然本研究在1.5B参数模型上取得了成功,但ProRL方法在更大规模模型上的可扩展性仍需进一步验证。
- 训练过程复杂性:ProRL训练需要定期重置参考策略和优化器参数,这增加了训练过程的复杂性,并可能导致结果的不一致性。
- 任务范围有限:尽管训练数据集涵盖了多个领域,但仍无法代表所有可能的推理任务。因此,模型在某些未见过的任务上的表现仍需进一步验证。
未来研究方向
基于本研究的结果和局限性,未来研究可以从以下几个方面展开:
- 优化计算资源利用:探索更高效的RL训练算法和硬件加速技术,以降低ProRL训练的计算成本。
- 验证可扩展性:在更大规模的模型上验证ProRL方法的有效性,并探索其在不同模型架构和参数规模下的适用性。
- 简化训练过程:研究如何简化ProRL训练过程,减少人为干预和参数调整的需求,提高训练的稳定性和可重复性。
- 拓展任务范围:构建更广泛、更多样化的训练数据集,以涵盖更多类型的推理任务,并评估模型在这些任务上的泛化能力。
- 结合其他技术:探索将ProRL与其他先进技术(如迁移学习、元学习等)相结合的可能性,以进一步提升模型的推理能力和泛化性能。
- 伦理和社会影响研究:随着推理能力的不断提升,语言模型在各个领域的应用将越来越广泛。因此,未来研究还应关注这些模型的伦理和社会影响,确保其安全、可靠地服务于人类社会。
结论
本研究通过引入ProRL训练方法,证明了延长的RL训练能够显著扩展语言模型的推理边界,并发现基础模型无法访问的新颖推理策略。实验结果表明,ProRL训练的模型在多个任务上取得了显著的性能提升,并表现出更高的创造力指数。尽管存在计算资源需求巨大、可扩展性担忧等局限性,但本研究为未来长视野RL推理研究奠定了坚实基础,并为语言模型在更广泛推理任务中的应用提供了新的思路和方法。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)