31 C 语言字符处理函数详解:isdigit、isxdigit、islower、isupper、isascii、toascii、tolower、toupper
本文深入解析了 C 语言中常用的字符处理函数,包括 isdigit、isxdigit、islower、isupper、isascii、toascii、tolower、toupper。通过详细的功能说明、参数类型、返回值类型、注意事项、示例程序,帮助读者全面理解这些函数的使用场景与限制。
1 isdigit() 函数
1.1 函数原型
#include <ctype.h>
int isdigit(int c);1.2 功能说明
isdigit() 函数用于检查传入的整数参数是否为 ASCII 编码的十进制数字字符('0' 到 '9',对应 ASCII 值 48 到 57)。
- 参数:
- c 表示要检查的字符,以 int 形式传递(通常是 char 类型转换而来的 ASCII 码值)。
- 返回值:
- 若 c 是数字字符('0' - '9'),返回非零值(通常是 1,表示真)。
- 若 c 不是数字字符,返回 0(表示假)。
1.3 注意事项
- 头文件依赖:
- 使用 isdigit() 函数前,必须包含 <ctype.h> 头文件,否则编译器可能无法识别该函数,导致编译错误或链接失败。
- 参数范围限制:
- 虽然函数参数类型为 int,但实际应传递 unsigned char 类型的值或 EOF(通常用于文件操作结束标志)。
- 如果传入的值超出 unsigned char 范围(0 - 255)或 EOF,函数的行为是未定义的(可能导致程序崩溃或返回错误结果)。
- 例如:直接传递负的 char 值(如 -1)或大于 255 的值是危险的。
- 区域设置依赖:
- isdigit() 的行为受区域设置(locale)影响,但在默认的 "C" 区域设置中,仅识别 ASCII 十进制数字字符('0' - '9')。
- 如果程序依赖其他区域设置(如非 ASCII 编码),可能需要使用其他函数或手动处理。
1.4 应用场景
- 输入验证:确保用户输入的敏感信息(如密码、账号)仅包含数字,避免非法字符导致程序异常。
- 字符串处理:从混合字符串(如 "订单号: 12345")中提取或统计数字字符,便于后续处理(如金额计算、ID 解析)。
- 数据清洗:在日志分析或数据预处理时,移除非数字字符(如特殊符号),保留有效数字以提升数据质量。
- 词法分析:在编译器开发中,识别代码中的数字常量(如 int a = 42;),为语法分析阶段提供基础。
1.5 示例程序
#include <stdio.h>
#include <ctype.h> // 引入 ctype.h 头文件以使用 isdigit 函数
int main()
{
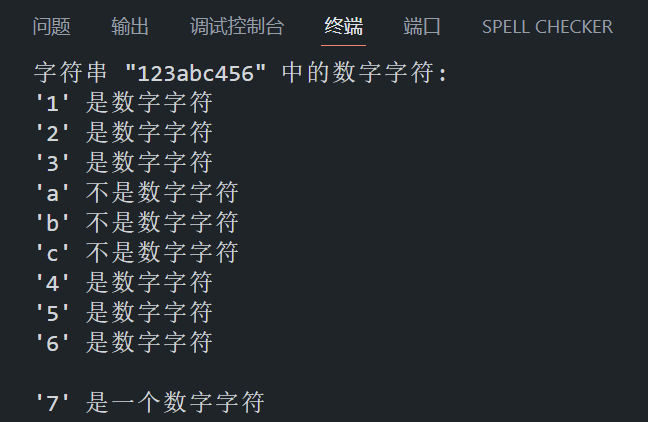
char str[] = "123abc456"; // 包含数字字符的字符串
printf("字符串 \"%s\" 中的数字字符:\n", str);
for (int i = 0; str[i] != '\0'; i++)
{
if (isdigit(str[i]))
{
printf("'%c' 是数字字符\n", str[i]);
}
else
{
printf("'%c' 不是数字字符\n", str[i]);
}
}
// 检查单个字符
char ch = '7';
if (isdigit(ch))
{
printf("\n'%c' 是一个数字字符\n", ch);
}
else
{
printf("\n'%c' 不是一个数字字符\n", ch);
}
return 0;
}程序在 VS Code 中的运行结果如下所示:
2 isxdigit() 函数
2.1 函数原型
#include <ctype.h>
int isxdigit(int c);2.2 功能说明
isxdigit() 函数用于检查传入的整数参数是否为 ASCII 编码的十六进制数字字符('0' - '9'、'A' - 'F' 或 'a' - 'f',对应 ASCII 值 48 - 57、65 - 70、97 - 102)。
-
参数:
-
c 表示要检查的字符,以 int 形式传递(通常是 char 类型转换而来的 ASCII 码值)。
-
-
返回值:
- 若 c 是十六进制数字字符('0' - '9'、'A' - 'F' 或 'a' - 'f'),返回非零值(通常是 1,表示真)。
- 若 c 不是十六进制数字字符,返回 0(表示假)。
2.3 注意事项
-
头文件依赖:
-
使用 isxdigit() 函数前,必须包含 <ctype.h> 头文件,否则编译器可能无法识别该函数,导致编译错误或链接失败。
-
-
参数范围限制:
- 虽然函数参数类型为 int,但实际应传递 unsigned char 类型的值或 EOF(通常用于文件操作结束标志)。
- 如果传入的值超出 unsigned char 范围(0 - 255)或 EOF,函数的行为是未定义的(可能导致程序崩溃或返回错误结果)。
- 例如:直接传递负的 char 值(如 -1)或大于 255 的值是危险的。
-
区域设置依赖:
- isxdigit() 的行为受区域设置(locale)影响,但在默认的 "C" 区域设置中,仅识别 ASCII 十六进制数字字符('0' - '9'、'A' - 'F'、'a' - 'f')。
- 如果程序依赖其他区域设置(如非 ASCII 编码),可能需要使用其他函数或手动处理。
2.4 应用场景
- 输入验证:确保用户输入的十六进制值(如颜色代码、内存地址)仅包含合法字符('0' - '9'、'A' - 'F' 或 'a' - 'f'),避免非法字符导致程序异常。
- 字符串处理:从混合字符串(如 "MAC 地址: 00:1A:2B:3C:4D:5E")中提取或验证十六进制字符,便于后续处理(如网络协议解析)。
- 数据转换:在将十六进制字符串转换为数值(如 "1A3F" 转换为整数)前,验证每个字符的合法性。
- 日志分析:在日志中识别十六进制格式的标识符或错误代码,便于自动化分析。
- 编译器开发:在词法分析阶段识别十六进制常量(如 0xFF 或 0x1a3),为语法分析提供基础。
2.5 示例程序
#include <stdio.h>
#include <ctype.h> // 引入 ctype.h 头文件以使用 isxdigit 函数
int main()
{
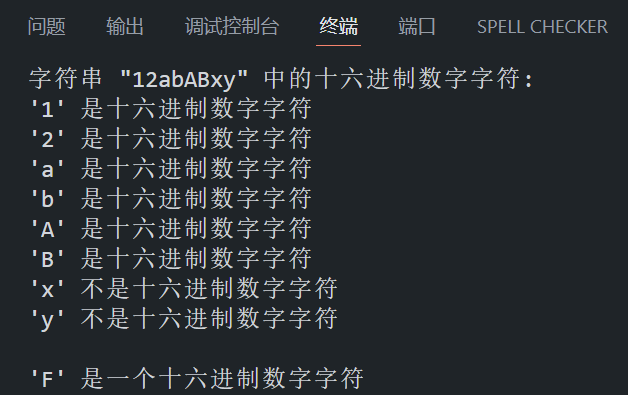
char str[] = "12abABxy"; // 包含十六进制数字字符的字符串
printf("字符串 \"%s\" 中的十六进制数字字符:\n", str);
for (int i = 0; str[i] != '\0'; i++)
{
if (isxdigit(str[i]))
{
printf("'%c' 是十六进制数字字符\n", str[i]);
}
else
{
printf("'%c' 不是十六进制数字字符\n", str[i]);
}
}
// 检查单个字符
char ch = 'F';
if (isxdigit(ch))
{
printf("\n'%c' 是一个十六进制数字字符\n", ch);
}
else
{
printf("\n'%c' 不是一个十六进制数字字符\n", ch);
}
return 0;
}程序在 VS Code 中的运行结果如下所示:
3 islower() 函数
3.1 函数原型
#include <ctype.h>
int islower(int c);3.2 功能说明
islower() 函数用于检查传入的整数参数是否为 ASCII 编码的小写字母字符('a' - 'z',对应 ASCII 值 97 - 122)。
- 参数:
- c 表示要检查的字符,以 int 形式传递(通常是 char 类型转换而来的 ASCII 码值)。
- 返回值:
- 若 c 是小写字母字符('a' - 'z'),返回非零值(通常是 1,表示真)。
- 若 c 不是小写字母字符,返回 0(表示假)。
3.3 注意事项
-
头文件依赖:
-
使用 islower() 函数前,必须包含 <ctype.h> 头文件,否则编译器可能无法识别该函数,导致编译错误或链接失败。
-
-
参数范围限制:
- 虽然函数参数类型为 int,但实际应传递 unsigned char 类型的值或 EOF(通常用于文件操作结束标志)。
- 如果传入的值超出 unsigned char 范围(0 - 255)或 EOF,函数的行为是未定义的(可能导致程序崩溃或返回错误结果)。
- 例如:直接传递负的 char 值(如 -1)或大于 255 的值是危险的。
-
区域设置依赖:
- islower() 的行为受区域设置(locale)影响,但在默认的 "C" 区域设置中,仅识别 ASCII 小写字母字符('a' - 'z')。
- 如果程序依赖其他区域设置(如非 ASCII 编码或特定语言环境),可能需要使用其他函数或手动处理。
3.4 应用场景
- 输入验证:确保用户输入的文本仅包含合法的小写字母(如用户名、密码规则),避免非法字符导致程序异常或不符合要求。
- 字符串处理:从混合字符串(如 "Hello World")中提取或验证小写字母,便于后续处理(如大小写转换、统计小写字母数量)。
- 文本分析:在自然语言处理或文本挖掘中,识别小写字母以分析文本格式或统计特征。
- 格式化输出:在将文本转换为特定格式(如统一小写)前,验证每个字符是否为小写字母。
- 编译器开发或代码解析:在词法分析阶段识别标识符或关键字的小写形式(如变量名、函数名),为语法分析提供基础。
3.5 示例程序
#include <stdio.h>
#include <ctype.h> // 引入 ctype.h 头文件以使用 islower() 函数
int main()
{
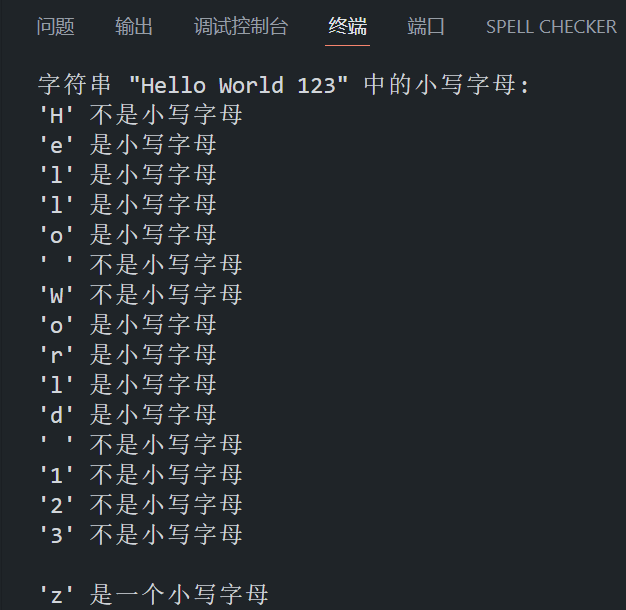
char str[] = "Hello World 123"; // 包含大小写字母和数字的字符串
printf("字符串 \"%s\" 中的小写字母:\n", str);
for (int i = 0; str[i] != '\0'; i++)
{
if (islower(str[i]))
{
printf("'%c' 是小写字母\n", str[i]);
}
else
{
printf("'%c' 不是小写字母\n", str[i]);
}
}
// 检查单个字符
char ch = 'z';
if (islower(ch))
{
printf("\n'%c' 是一个小写字母\n", ch);
}
else
{
printf("\n'%c' 不是一个小写字母\n", ch);
}
return 0;
}程序在 VS Code 中的运行结果如下所示:
4 isupper() 函数
4.1 函数原型
#include <ctype.h>
int isupper(int c);4.2 功能说明
isupper() 函数用于检查传入的整数参数是否为 ASCII 编码的大写字母字符('A' - 'Z',对应 ASCII 值 65 - 90)。
- 参数:
- c 表示要检查的字符,以 int 形式传递(通常是 char 类型转换而来的 ASCII 码值)。
- 返回值:
- 若 c 是大写字母字符('A' - 'Z'),返回非零值(通常是 1,表示真)。
- 若 c 不是大写字母字符,返回 0(表示假)。
4.3 注意事项
-
头文件依赖:
-
使用 isupper() 函数前,必须包含 <ctype.h> 头文件,否则编译器可能无法识别该函数,导致编译错误或链接失败。
-
-
参数范围限制:
- 虽然函数参数类型为 int,但实际应传递 unsigned char 类型的值或 EOF(通常用于文件操作结束标志)。
- 如果传入的值超出 unsigned char 范围(0 - 255)或 EOF,函数的行为是未定义的(可能导致程序崩溃或返回错误结果)。
- 例如:直接传递负的 char 值(如 -1)或大于 255 的值是危险的。
-
区域设置依赖:
- isupper() 的行为受区域设置(locale)影响,但在默认的 "C" 区域设置中,仅识别 ASCII 大写字母字符('A' - 'Z')。
- 如果程序依赖其他区域设置(如非 ASCII 编码或特定语言环境),可能需要使用其他函数或手动处理。
4.4 应用场景
- 输入验证:确保用户输入的文本仅包含合法的大写字母(如缩写、代码标识符),避免非法字符导致程序异常或不符合要求。
- 字符串处理:从混合字符串(如 "Hello World")中提取或验证大写字母,便于后续处理(如大小写转换、统计大写字母数量)。
- 文本格式化:在将文本转换为特定格式(如统一大写)前,验证每个字符是否为大写字母。
- 代码解析或编译器开发:在词法分析阶段识别标识符或关键字的大写形式(如宏定义、常量名),为语法分析提供基础。
- 数据清洗:在日志分析或数据预处理时,移除非大写字母字符(如特殊符号),保留有效大写字母以提升数据质量。
4.5 示例程序
#include <stdio.h>
#include <ctype.h> // 引入 ctype.h 头文件以使用 isupper 函数
int main()
{
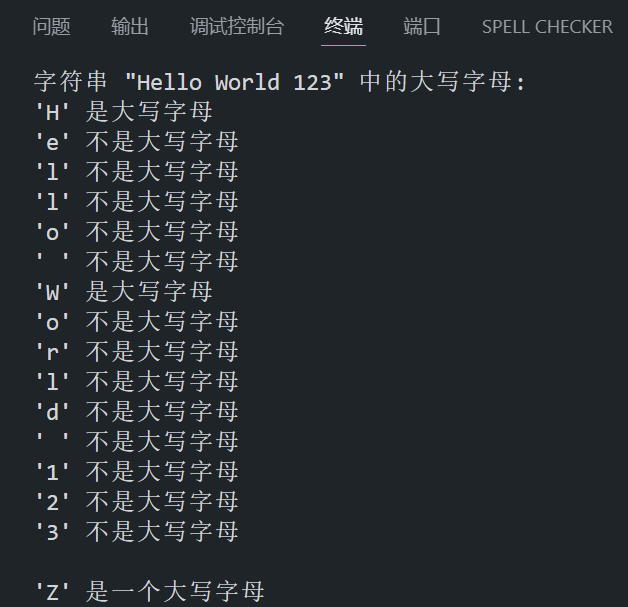
char str[] = "Hello World 123"; // 包含大小写字母和数字的字符串
printf("字符串 \"%s\" 中的大写字母:\n", str);
for (int i = 0; str[i] != '\0'; i++)
{
if (isupper(str[i]))
{
printf("'%c' 是大写字母\n", str[i]);
}
else
{
printf("'%c' 不是大写字母\n", str[i]);
}
}
// 检查单个字符
char ch = 'Z';
if (isupper(ch))
{
printf("\n'%c' 是一个大写字母\n", ch);
}
else
{
printf("\n'%c' 不是一个大写字母\n", ch);
}
return 0;
}程序在 VS Code 中的运行结果如下所示:
5 isascii() 函数
5.1 函数原型
#include <ctype.h>
int isascii(int c);5.2 功能说明
isascii() 函数用于检查传入的整数参数是否为 ASCII 编码的字符(即值在 0 到 127 范围内)。
- 参数:
- c 表示要检查的字符,以 int 形式传递(通常是 char 类型转换而来的 ASCII 码值)。
- 返回值:
- 若 c 是 ASCII 字符(0 - 127),返回非零值(通常是 1,表示真)。
- 若 c 不是 ASCII 字符,返回 0(表示假)。
5.3 注意事项
- 头文件依赖:
- 使用 isascii() 函数前,必须包含 <ctype.h> 头文件,否则编译器可能无法识别该函数,导致编译错误或链接失败。
- 参数范围限制:
- 虽然函数参数类型为 int,但实际应传递 unsigned char 类型的值或 EOF(通常用于文件操作结束标志)。
- 如果传入的值超出 unsigned char 范围(0 - 255)或 EOF,函数的行为是未定义的(但 isascii() 本身仅检查 0 - 127 范围,超出此范围直接返回 0)。
- 例如:直接传递负的 char 值(如 -1)或大于 127 的值时,函数会返回 0。
- 区域设置依赖:
- isascii() 的行为不受区域设置(locale)影响,因为它仅检查数值范围(0 - 127),与字符的语义无关。
- 无论程序运行在何种区域设置下,该函数的行为都是一致的。
5.4 应用场景
- 输入验证:确保用户输入或外部数据源(如文件、网络)提供的字符是 ASCII 编码,避免非 ASCII 字符导致的兼容性问题。
- 协议处理:在处理网络协议或文件格式时,验证数据是否仅包含 ASCII 字符(如 HTTP 头、SMTP 命令)。
- 字符串过滤:从混合字符串中移除非 ASCII 字符(如 Unicode 扩展字符),保留纯 ASCII 文本。
- 兼容性处理:在需要将数据传输到仅支持 ASCII 的系统或设备时,预先验证数据的合法性。
- 日志分析:在日志中过滤或标记非 ASCII 字符,便于后续分析或问题排查。
5.5 示例程序
#include <stdio.h>
#include <ctype.h> // 引入 ctype.h 头文件以使用 isascii 函数
int main()
{
// 测试一些字符
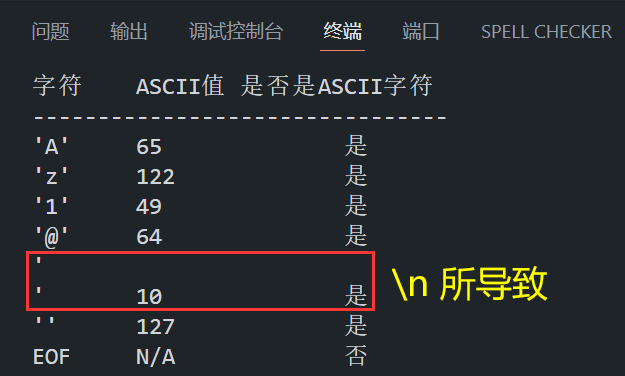
char test_chars[] = {'A', 'z', '1', '@', '\n', '\177', EOF};
// 177 是八进制表示的 DEL 字符
// EOF 表示文件结束符 值为 -1
printf("字符\tASCII值\t是否是ASCII字符\n");
printf("--------------------------------\n");
for (int i = 0; test_chars[i] != EOF; i++)
{
int c = test_chars[i];
printf("'%c'\t%d\t\t", c, c);
if (isascii(c))
{
printf("是\n");
}
else
{
printf("否\n");
}
}
// 测试 EOF
printf("EOF\tN/A\t\t");
if (isascii(EOF))
{
printf("是\n");
}
else
{
printf("否\n");
}
return 0;
}程序在 VS Code 中的运行结果如下所示:
6 toascii() 函数
6.1 函数原型
#include <ctype.h>
int toascii(int c);6.2 功能说明
toascii() 函数用于将传入的整数参数强制转换为 ASCII 编码的字符(即截断为 0 到 127 范围内的值)。
-
参数:
-
c 表示要转换的字符,以 int 形式传递(通常是 char 类型转换而来的 ASCII 码值)。
-
-
返回值:
-
返回 c 的低 7 位(即 c & 0x7F【对应二进制为 0111 1111】),确保结果在 0 到 127 范围内。
-
6.3 注意事项
-
头文件依赖:
-
使用 toascii() 函数前,必须包含 <ctype.h> 头文件,否则编译器可能无法识别该函数,导致编译错误或链接失败。
-
-
参数范围限制:
- 虽然函数参数类型为 int,但实际应传递 unsigned char 类型的值或 EOF(通常用于文件操作结束标志)。
- 如果传入的值超出 unsigned char 范围(0 - 255)或 EOF,函数的行为是明确的(返回 c & 0x7F),但需注意 EOF 通常为 -1,转换后会变成 127(即 DEL 字符)。
-
行为说明:
- toascii() 不会检查输入是否为合法字符,而是直接截断高位。
- 例如:toascii(200) 返回 200 & 0x7F = 72(即字符 'H')。
-
区域设置依赖:
- toascii() 的行为不受区域设置(locale)影响,因为它仅执行位操作,与字符的语义无关。
- 无论程序运行在何种区域设置下,该函数的行为都是一致的。
6.4 应用场景
- 数据截断:在需要将非 ASCII 字符转换为 ASCII 字符时(如日志记录、简单文本处理),直接截断高位。
- 兼容性处理:在需要将数据传输到仅支持 ASCII 的系统或设备时,预先截断非 ASCII 字符。
- 协议处理:在处理网络协议或文件格式时,确保数据仅包含 ASCII 字符(如 HTTP 头、SMTP 命令)。
- 简单加密/混淆:在简单的字符操作中,可能需要通过截断高位实现特定效果(但通常不推荐用于安全场景)。
6.5 示例程序
#include <stdio.h>
#include <ctype.h> // 引入 ctype.h 头文件以使用 toascii 函数
int main()
{
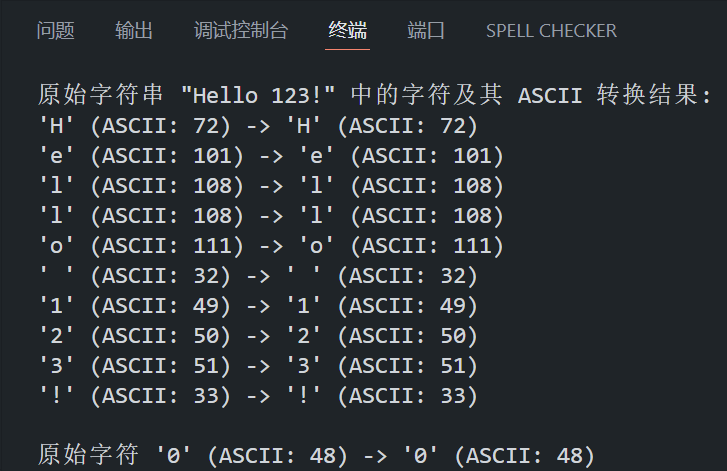
char str[] = "Hello 123!"; // 测试字符串
printf("原始字符串 \"%s\" 中的字符及其 ASCII 转换结果:\n", str);
for (int i = 0; str[i] != '\0'; i++)
{
int original = str[i]; // 获取原始字符
int converted = toascii(original); // 转换为 ASCII 字符
// 使用三元运算符 (c >= 32 && c <= 126) ? c : ' ' 确保非可显示字符(如控制字符)以空格形式输出,避免乱码。
printf("'%c' (ASCII: %d) -> ", (original >= 32 && original <= 126) ? original : ' ', original);
printf("'%c' (ASCII: %d)\n", (converted >= 32 && converted <= 126) ? converted : ' ', converted);
}
// 检查单个字符
char ch = '0';
int converted_ch = toascii(ch);
printf("\n原始字符 '%c' (ASCII: %d) -> ", (ch >= 32 && ch <= 126) ? ch : ' ', ch);
printf("'%c' (ASCII: %d)\n", (converted_ch >= 32 && converted_ch <= 126) ? converted_ch : ' ', converted_ch);
return 0;
}程序在 VS Code 中的运行结果如下所示:
7 tolower() 函数
7.1 函数原型
#include <ctype.h>
int tolower(int c);7.2 功能说明
tolower() 函数用于将传入的大写字母字符转换为对应的小写字母字符。如果传入的不是大写字母字符,则直接返回原字符。
-
参数:
-
c 表示要转换的字符,以 int 形式传递(通常是 char 类型转换而来的 ASCII 码值)。
-
-
返回值:
- 如果 c 是大写字母('A' 到 'Z'),返回对应的小写字母('a' 到 'z')。
- 如果 c 不是大写字母,返回 c 本身。
7.3 注意事项
-
头文件依赖:
-
使用 tolower() 函数前,必须包含 <ctype.h> 头文件,否则编译器可能无法识别该函数,导致编译错误或链接失败。
-
-
参数范围限制:
- 虽然函数参数类型为 int,但实际应传递 unsigned char 类型的值或 EOF(通常用于文件操作结束标志)。
- 如果传入的值超出 unsigned char 范围(0 - 255)或 EOF,函数的行为是未定义的。
-
区域设置依赖:
- tolower() 的行为可能受区域设置(locale)影响。在默认的 "C" 区域设置下,仅处理 ASCII 字符('A' - 'Z')。
- 在其他区域设置下,可能支持非 ASCII 字母的大小写转换(如带重音符号的字母)。
-
非字母处理:
- 如果传入的不是大写字母(如数字、符号、小写字母),函数直接返回原字符。
7.4 应用场景
- 文本规范化:在需要统一文本大小写时(如用户名、搜索关键词),将大写字母转换为小写。
- 数据清洗:在处理用户输入或外部数据时,消除大小写差异(如字符串比较、哈希计算)。
- 协议处理:在需要严格小写的协议中(如 HTTP 头字段名),确保数据格式正确。
- 国际化支持:在支持多语言的程序中,结合区域设置处理非 ASCII 字母的大小写转换。
7.5 示例程序
#include <stdio.h>
#include <ctype.h> // 引入 ctype.h 头文件以使用 tolower 函数
int main()
{
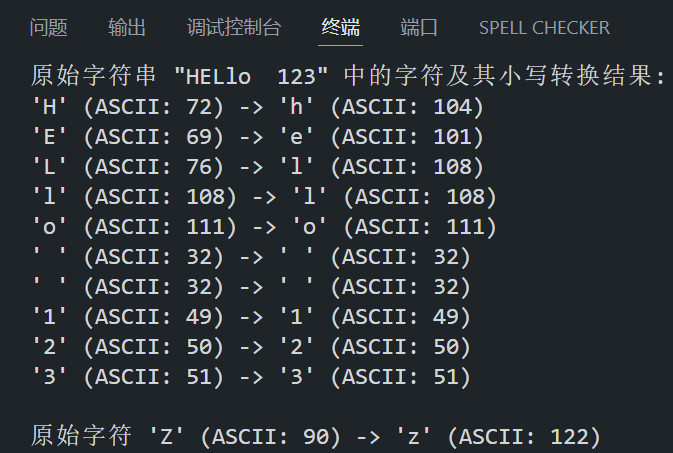
char str[] = "HELlo 123"; // 测试字符串
printf("原始字符串 \"%s\" 中的字符及其小写转换结果:\n", str);
for (int i = 0; str[i] != '\0'; i++)
{
int original = str[i]; // 获取字符的 ASCII 值
int converted = tolower(original); // 转换为小写
// 使用三元运算符 (c >= 32 && c <= 126) ? c : ' ' 确保非可显示字符(如控制字符)以空格形式输出,避免乱码。
printf("'%c' (ASCII: %d) -> ", (original >= 32 && original <= 126) ? original : ' ', original);
printf("'%c' (ASCII: %d)\n", (converted >= 32 && converted <= 126) ? converted : ' ', converted);
}
// 检查单个字符
char ch = 'Z';
int converted_ch = tolower(ch);
printf("\n原始字符 '%c' (ASCII: %d) -> ",(ch >= 32 && ch <= 126) ? ch : ' ', ch);
printf("'%c' (ASCII: %d)\n", (converted_ch >= 32 && converted_ch <= 126) ? converted_ch : ' ', converted_ch);
return 0;
}程序在 VS Code 中的运行结果如下所示:
8 toupper() 函数
8.1 函数原型
#include <ctype.h>
int toupper(int c);8.2 功能说明
toupper() 函数用于将传入的小写字母字符转换为对应的大写字母字符。如果传入的不是小写字母字符,则直接返回原字符。
-
参数:
-
c 表示要转换的字符,以 int 形式传递(通常是 char 类型转换而来的 ASCII 码值)。
-
-
返回值:
- 如果 c 是小写字母('a' 到 'z'),返回对应的大写字母('A' 到 'Z')。
- 如果 c 不是小写字母,返回 c 本身。
8.3 注意事项
-
头文件依赖:
-
使用 toupper() 函数前,必须包含 <ctype.h> 头文件,否则编译器可能无法识别该函数,导致编译错误或链接失败。
-
-
参数范围限制:
- 虽然函数参数类型为 int,但实际应传递 unsigned char 类型的值或 EOF(通常用于文件操作结束标志)。
- 如果传入的值超出 unsigned char 范围(0 - 255)或 EOF,函数的行为是未定义的。
-
区域设置依赖:
- toupper() 的行为可能受区域设置(locale)影响。在默认的 "C" 区域设置下,仅处理 ASCII 字符('a' - 'z')。
- 在其他区域设置下,可能支持非 ASCII 字母的大小写转换(如带重音符号的字母)。
-
非字母处理:
- 如果传入的不是小写字母(如数字、符号、大写字母),函数直接返回原字符。
8.4 应用场景
- 文本规范化:在需要统一文本大小写时(如用户名、搜索关键词),将小写字母转换为大写。
- 数据清洗:在处理用户输入或外部数据时,消除大小写差异(如字符串比较、哈希计算)。
- 协议处理:在需要严格大写的协议中(如 HTTP 头字段名),确保数据格式正确。
- 国际化支持:在支持多语言的程序中,结合区域设置处理非 ASCII 字母的大小写转换。
8.5 示例程序
#include <stdio.h>
#include <ctype.h> // 引入 ctype.h 头文件以使用 toupper 函数
int main()
{
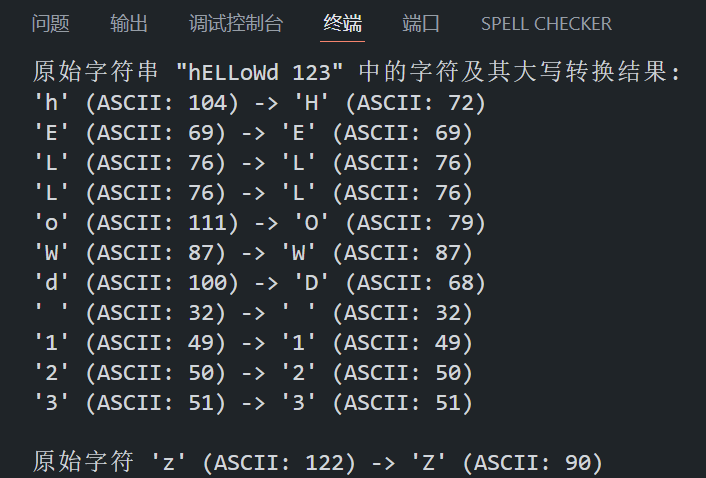
char str[] = "hELLoWd 123"; // 包含大小写字母、符号和数字的字符串
printf("原始字符串 \"%s\" 中的字符及其大写转换结果:\n", str);
for (int i = 0; str[i] != '\0'; i++)
{
int original = str[i]; // 获取原始字符
int converted = toupper(original);// 转换为 ASCII 字符
// 使用三元运算符 (c >= 32 && c <= 126) ? c : ' ' 确保非可显示字符(如控制字符)以空格形式输出,避免乱码。
printf("'%c' (ASCII: %d) -> ", (original >= 32 && original <= 126) ? original : ' ', original);
printf("'%c' (ASCII: %d)\n", (converted >= 32 && converted <= 126) ? converted : ' ', converted);
}
// 检查单个字符
char ch = 'z';
int converted_ch = toupper(ch);
printf("\n原始字符 '%c' (ASCII: %d) -> ", (ch >= 32 && ch <= 126) ? ch : ' ', ch);
printf("'%c' (ASCII: %d)\n", (converted_ch >= 32 && converted_ch <= 126) ? converted_ch : ' ', converted_ch);
return 0;
}程序在 VS Code 中的运行结果如下所示:
9 字符处理函数总结
| 函数名 | 功能描述 | 输入类型 | 返回值类型 | 返回值说明 |
|---|---|---|---|---|
| isdigit | 检查字符是否为十进制数字(0-9) | int(字符的 ASCII 值) | int | 非零值(真)如果字符是数字,否则 0(假) |
| isxdigit | 检查字符是否为十六进制数字(0-9, a-f, A-F) | int(字符的 ASCII 值) | int | 非零值(真)如果字符是十六进制数字,否则 0(假) |
| islower | 检查字符是否为小写字母(a-z) | int(字符的 ASCII 值) | int | 非零值(真)如果字符是小写字母,否则 0(假) |
| isupper | 检查字符是否为大写字母(A-Z) | int(字符的 ASCII 值) | int | 非零值(真)如果字符是大写字母,否则 0(假) |
| isascii | 检查字符是否为 ASCII 字符(0-127) | int(字符的 ASCII 值) | int | 非零值(真)如果字符是 ASCII 字符,否则 0(假) |
| toascii | 将字符转换为 ASCII 字符(如果它是非 ASCII 字符,则截断为低 7 位) | int(字符的 ASCII 值) | int | 转换后的 ASCII 字符值 |
| tolower | 将大写字母转换为小写字母(如果字符不是大写字母,则返回原字符) | int(字符的 ASCII 值) | int | 转换后的小写字母值或原字符值 |
| toupper | 将小写字母转换为大写字母(如果字符不是小写字母,则返回原字符) | int(字符的 ASCII 值) | int | 转换后的大写字母值或原字符值 |
- 这些函数都定义在 <ctype.h> 头文件中。
- 输入参数通常是字符的 ASCII 值(即 int 类型),但通常通过传递字符(如 'a')来隐式转换。
- 返回值类型为 int,通常用于布尔判断(非零为真,0 为假),但 toascii、tolower 和 toupper 返回的是实际的字符值。
- toascii 函数在某些实现中可能不是标准的一部分,或者其行为可能因实现而异。在大多数现代系统中,更常见的是直接处理字符而不进行截断。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)