YOLOv12改进后发现精度比yolov8还低,所以改进了一个[YOLOv8+Unetv2]
YOLOv8+Unetv2在保持YOLOv8速度优势的同时,显著提升了小目标的检测精度。
一、YOLOv8+Unetv2的改进动机
Unetv2的引入是为了解决YOLOv12在细粒度分割和多尺度特征融合上的不足。Unetv2的跳跃连接和多尺度特征提取能力可以增强YOLOv8的特征表达能力,尤其是在小目标和密集场景中。
二、U-Net v2论文解读
- 核心创新点
- 通过Hadamard乘积(逐元素相乘)实现多级特征融合,在跳跃连接中同时注入高层语义信息和低层细节特征
- 提出双向特征增强机制:向下传播时用高层特征增强低层特征的语义性,向上传播时用低层特征细化高层特征的细节
- 技术实现
- 保持U-Net的编码器-解码器基础架构
- 每个层次的特征都会与相邻层次的特征进行交互: a) 高层特征通过下采样与低层特征进行Hadamard乘积 b) 低层特征通过上采样与高层特征进行Hadamard乘积
- 优势特点
- 兼容任意编码器-解码器架构
- 在保持计算效率的同时提升分割精度
- 在皮肤病变分割和息肉分割任务中表现优异
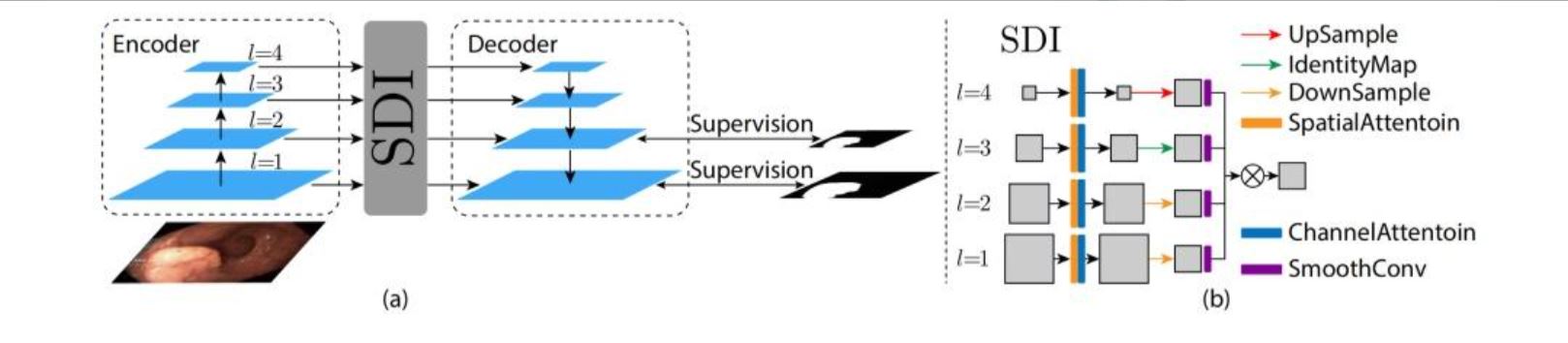
网络结构
import os.path
import warnings
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import math
__all__ = ['pvt_v2_b0', 'pvt_v2_b1', 'pvt_v2_b2', 'pvt_v2_b3', 'pvt_v2_b4', 'pvt_v2_b5']
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class BasicConv2d(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_planes, out_planes,
kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, bias=False)
self.bn = nn.BatchNorm2d(out_planes)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
class Encoder(nn.Module):
def __init__(self, pretrain_path):
super().__init__()
self.backbone = pvt_v2_b2()
if pretrain_path is None:
warnings.warn('please provide the pretrained pvt model. Not using pretrained model.')
elif not os.path.isfile(pretrain_path):
warnings.warn(f'path: {pretrain_path} does not exists. Not using pretrained model.')
else:
print(f"using pretrained file: {pretrain_path}")
save_model = torch.load(pretrain_path)
model_dict = self.backbone.state_dict()
state_dict = {k: v for k, v in save_model.items() if k in model_dict.keys()}
model_dict.update(state_dict)
self.backbone.load_state_dict(model_dict)
def forward(self, x):
f1, f2, f3, f4 = self.backbone(x) # (x: 3, 352, 352)
return f1, f2, f3, f4
class SDI(nn.Module):
def __init__(self, channel):
super().__init__()
self.convs = nn.ModuleList(
[nn.Conv2d(channel, channel, kernel_size=3, stride=1, padding=1) for _ in range(4)])
def forward(self, xs, anchor):
ans = torch.ones_like(anchor)
target_size = anchor.shape[-1]
for i, x in enumerate(xs):
if x.shape[-1] > target_size:
x = F.adaptive_avg_pool2d(x, (target_size, target_size))
elif x.shape[-1] < target_size:
x = F.interpolate(x, size=(target_size, target_size),
mode='bilinear', align_corners=True)
ans = ans * self.convs[i](x)
return ans
class UNetV2(nn.Module):
"""
use SpatialAtt + ChannelAtt
"""
def __init__(self, channel=3, n_classes=1, deep_supervision=True, pretrained_path=None):
super().__init__()
self.deep_supervision = deep_supervision
self.encoder = Encoder(pretrained_path)
self.ca_1 = ChannelAttention(64)
self.sa_1 = SpatialAttention()
self.ca_2 = ChannelAttention(128)
self.sa_2 = SpatialAttention()
self.ca_3 = ChannelAttention(320)
self.sa_3 = SpatialAttention()
self.ca_4 = ChannelAttention(512)
self.sa_4 = SpatialAttention()
self.Translayer_1 = BasicConv2d(64, channel, 1)
self.Translayer_2 = BasicConv2d(128, channel, 1)
self.Translayer_3 = BasicConv2d(320, channel, 1)
self.Translayer_4 = BasicConv2d(512, channel, 1)
self.sdi_1 = SDI(channel)
self.sdi_2 = SDI(channel)
self.sdi_3 = SDI(channel)
self.sdi_4 = SDI(channel)
self.seg_outs = nn.ModuleList([
nn.Conv2d(channel, n_classes, 1, 1) for _ in range(4)])
self.deconv2 = nn.ConvTranspose2d(channel, channel, kernel_size=4, stride=2, padding=1,
bias=False)
self.deconv3 = nn.ConvTranspose2d(channel, channel, kernel_size=4, stride=2,
padding=1, bias=False)
self.deconv4 = nn.ConvTranspose2d(channel, channel, kernel_size=4, stride=2,
padding=1, bias=False)
self.deconv5 = nn.ConvTranspose2d(channel, channel, kernel_size=4, stride=2,
padding=1, bias=False)
self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def forward(self, x):
seg_outs = []
f1, f2, f3, f4 = self.encoder(x)
f1 = self.ca_1(f1) * f1
f1 = self.sa_1(f1) * f1
f1 = self.Translayer_1(f1)
f2 = self.ca_2(f2) * f2
f2 = self.sa_2(f2) * f2
f2 = self.Translayer_2(f2)
f3 = self.ca_3(f3) * f3
f3 = self.sa_3(f3) * f3
f3 = self.Translayer_3(f3)
f4 = self.ca_4(f4) * f4
f4 = self.sa_4(f4) * f4
f4 = self.Translayer_4(f4)
f41 = self.sdi_4([f1, f2, f3, f4], f4)
f31 = self.sdi_3([f1, f2, f3, f4], f3)
f21 = self.sdi_2([f1, f2, f3, f4], f2)
f11 = self.sdi_1([f1, f2, f3, f4], f1)
seg_outs.append(self.seg_outs[0](f41))
y = self.deconv2(f41) + f31
seg_outs.append(self.seg_outs[1](y))
y = self.deconv3(y) + f21
seg_outs.append(self.seg_outs[2](y))
y = self.deconv4(y) + f11
seg_outs.append(self.seg_outs[3](y))
for i, o in enumerate(seg_outs):
seg_outs[i] = F.interpolate(o, scale_factor=4, mode='bilinear')
if self.deep_supervision:
return seg_outs[::-1]
else:
return seg_outs[-1]
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.LayerNorm(embed_dim)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class PyramidVisionTransformerImpr(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1]):
super().__init__()
self.num_classes = num_classes
self.depths = depths
# patch_embed
self.patch_embed1 = OverlapPatchEmbed(img_size=img_size, patch_size=7, stride=4, in_chans=in_chans,
embed_dim=embed_dims[0])
self.patch_embed2 = OverlapPatchEmbed(img_size=img_size // 4, patch_size=3, stride=2, in_chans=embed_dims[0],
embed_dim=embed_dims[1])
self.patch_embed3 = OverlapPatchEmbed(img_size=img_size // 8, patch_size=3, stride=2, in_chans=embed_dims[1],
embed_dim=embed_dims[2])
self.patch_embed4 = OverlapPatchEmbed(img_size=img_size // 16, patch_size=3, stride=2, in_chans=embed_dims[2],
embed_dim=embed_dims[3])
# transformer encoder
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
self.block1 = nn.ModuleList([Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[0])
for i in range(depths[0])])
self.norm1 = norm_layer(embed_dims[0])
cur += depths[0]
self.block2 = nn.ModuleList([Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[1])
for i in range(depths[1])])
self.norm2 = norm_layer(embed_dims[1])
cur += depths[1]
self.block3 = nn.ModuleList([Block(
dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[2])
for i in range(depths[2])])
self.norm3 = norm_layer(embed_dims[2])
cur += depths[2]
self.block4 = nn.ModuleList([Block(
dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[3])
for i in range(depths[3])])
self.norm4 = norm_layer(embed_dims[3])
# classification head
# self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
self.width_list = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def init_weights(self, pretrained=None):
if isinstance(pretrained, str):
logger = 1
# load_checkpoint(self, pretrained, map_location='cpu', strict=False, logger=logger)
def reset_drop_path(self, drop_path_rate):
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(self.depths))]
cur = 0
for i in range(self.depths[0]):
self.block1[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[0]
for i in range(self.depths[1]):
self.block2[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[1]
for i in range(self.depths[2]):
self.block3[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[2]
for i in range(self.depths[3]):
self.block4[i].drop_path.drop_prob = dpr[cur + i]
def freeze_patch_emb(self):
self.patch_embed1.requires_grad = False
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed1', 'pos_embed2', 'pos_embed3', 'pos_embed4', 'cls_token'} # has pos_embed may be better
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
# def _get_pos_embed(self, pos_embed, patch_embed, H, W):
# if H * W == self.patch_embed1.num_patches:
# return pos_embed
# else:
# return F.interpolate(
# pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
# size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def forward_features(self, x):
B = x.shape[0]
outs = []
# stage 1
x, H, W = self.patch_embed1(x)
for i, blk in enumerate(self.block1):
x = blk(x, H, W)
x = self.norm1(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# stage 2
x, H, W = self.patch_embed2(x)
for i, blk in enumerate(self.block2):
x = blk(x, H, W)
x = self.norm2(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# stage 3
x, H, W = self.patch_embed3(x)
for i, blk in enumerate(self.block3):
x = blk(x, H, W)
x = self.norm3(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# stage 4
x, H, W = self.patch_embed4(x)
for i, blk in enumerate(self.block4):
x = blk(x, H, W)
x = self.norm4(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
return outs
# return x.mean(dim=1)
def forward(self, x):
x = self.forward_features(x)
# x = self.head(x)
return x
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
class pvt_v2_b0(PyramidVisionTransformerImpr):
def __init__(self, **kwargs):
super(pvt_v2_b0, self).__init__(
patch_size=4, embed_dims=[32, 64, 160, 256], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4],
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class pvt_v2_b1(PyramidVisionTransformerImpr):
def __init__(self, **kwargs):
super(pvt_v2_b1, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4],
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class pvt_v2_b2(PyramidVisionTransformerImpr):
def __init__(self, **kwargs):
super(pvt_v2_b2, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4],
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class pvt_v2_b3(PyramidVisionTransformerImpr):
def __init__(self, **kwargs):
super(pvt_v2_b3, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4],
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class pvt_v2_b4(PyramidVisionTransformerImpr):
def __init__(self, **kwargs):
super(pvt_v2_b4, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4],
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
class pvt_v2_b5(PyramidVisionTransformerImpr):
def __init__(self, **kwargs):
super(pvt_v2_b5, self).__init__(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[4, 4, 4, 4],
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 6, 40, 3], sr_ratios=[8, 4, 2, 1],
drop_rate=0.0, drop_path_rate=0.1)
三、YOLOv8+Unetv2的核心改进点
Unetv2替换YOLOv8主干网络:
1.在ultralytics/nn/modules/ 文件下穿件Python文件UNetv2.py ,将以上面的代码复制到文件里面。
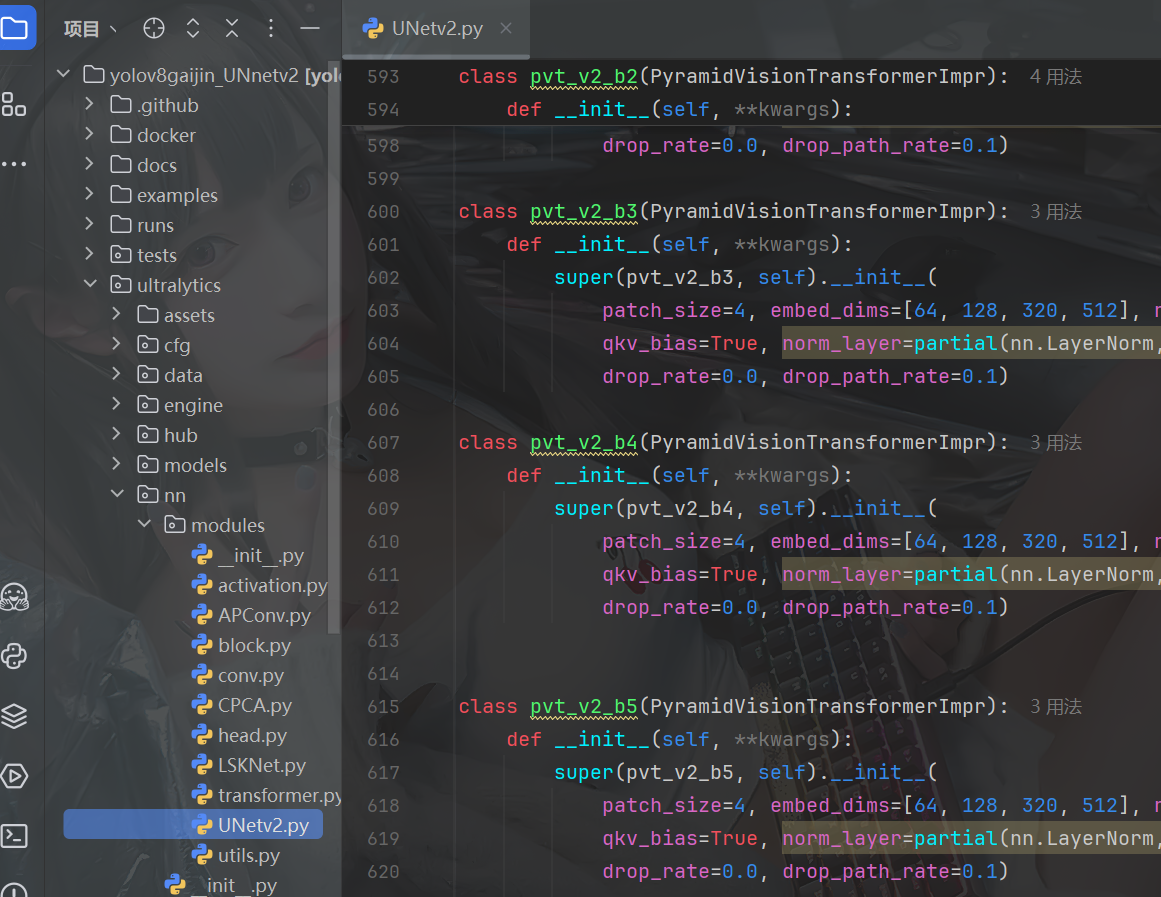
2. 在ultralytics/nn/modules/__init__.py 文件里面加入:
from .UNetv2 import *
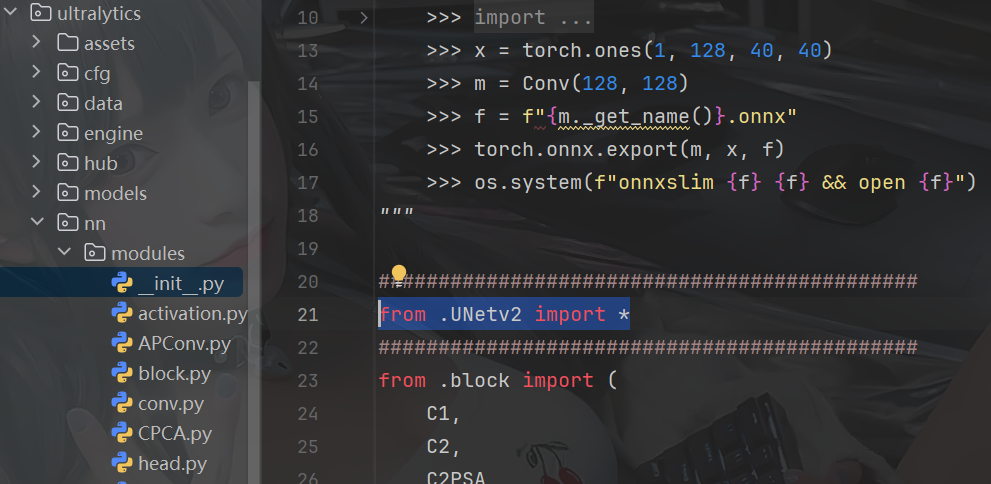
3.在ultralytics/nn/tasks.py 文件里面加入以下语句,当然你也可以只将模块加到from ultralytics.nn.modules import() 里面啦。
from ultralytics.nn.modules.UNetv2 import *
4. 修改task.py文件里面的代码
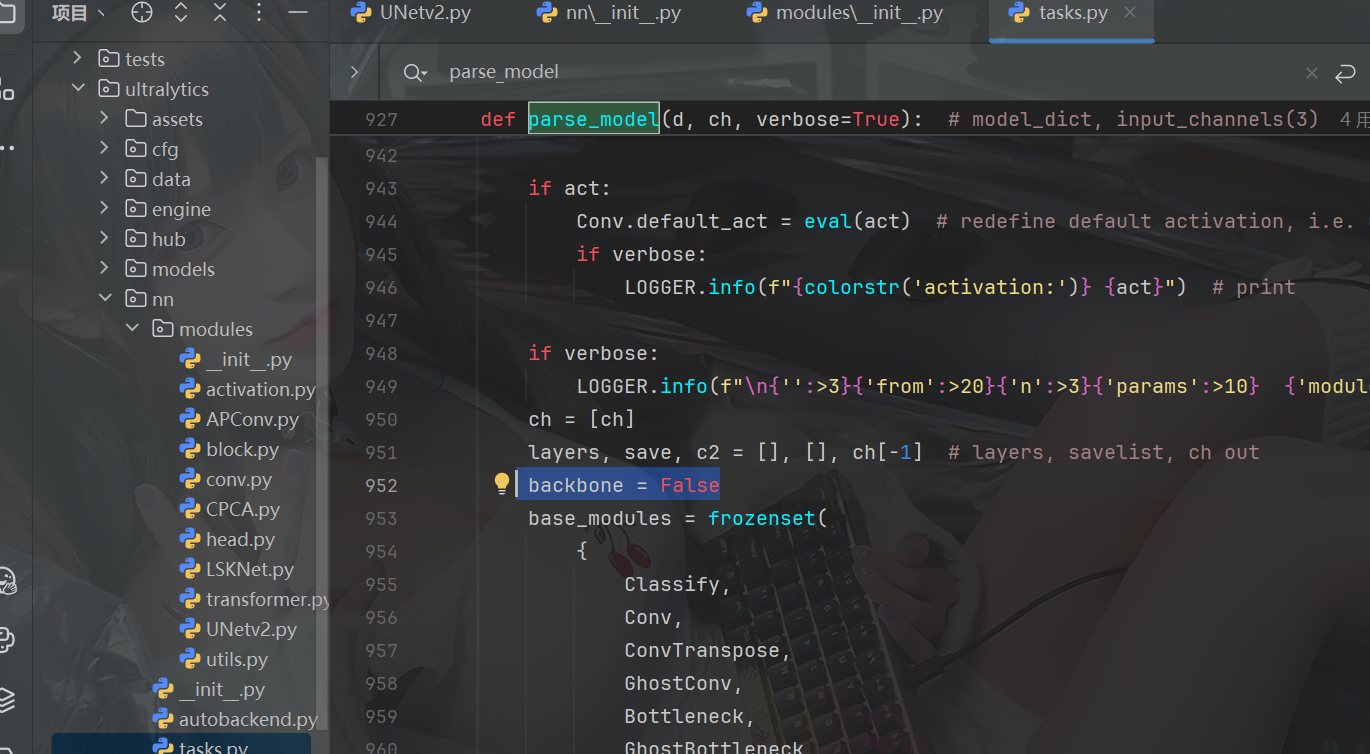
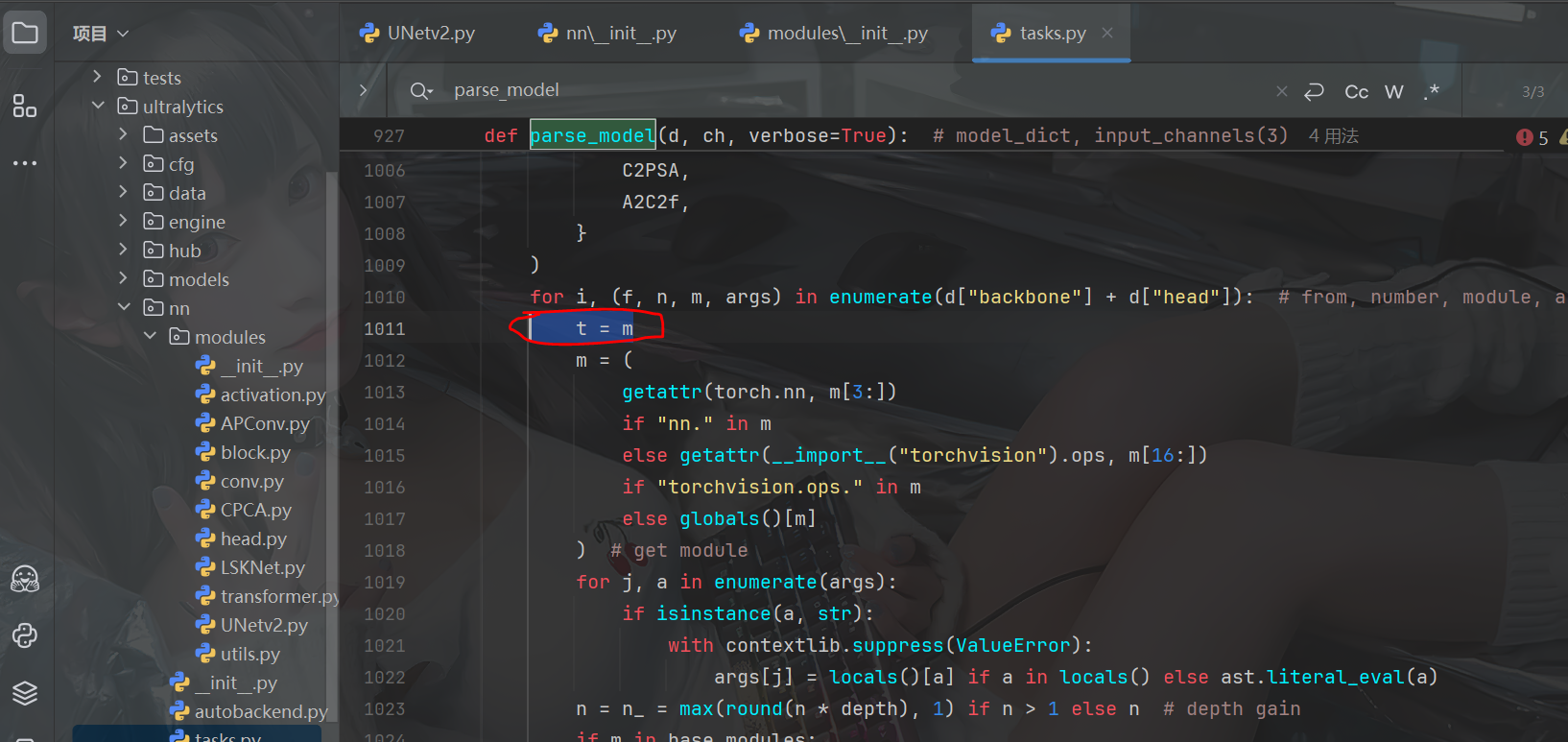
4.1.1 找到parse_model 函数,在以下的位置里面加入代码:
backbone = False 与 t=m
4.1.2 在此函数下的条件句里添加代码
elif m in {pvt_v2_b0, pvt_v2_b1, pvt_v2_b2, pvt_v2_b3, pvt_v2_b4, pvt_v2_b5}:
m = m(*args)
c2 = m.width_list
backbone = True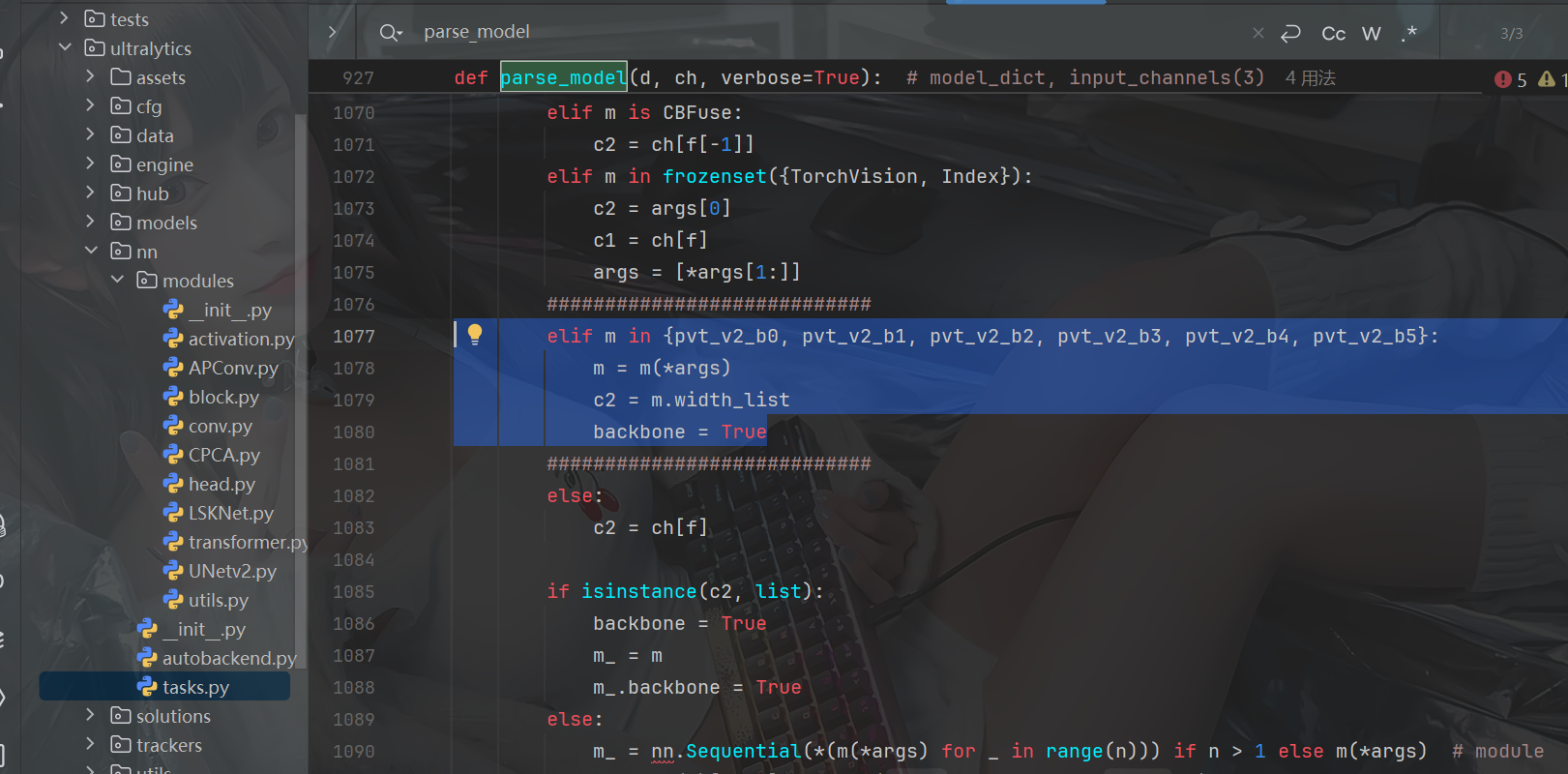
4.1.3 在此函数下修改以下位置代码如图(博主的是已修改过的)所示
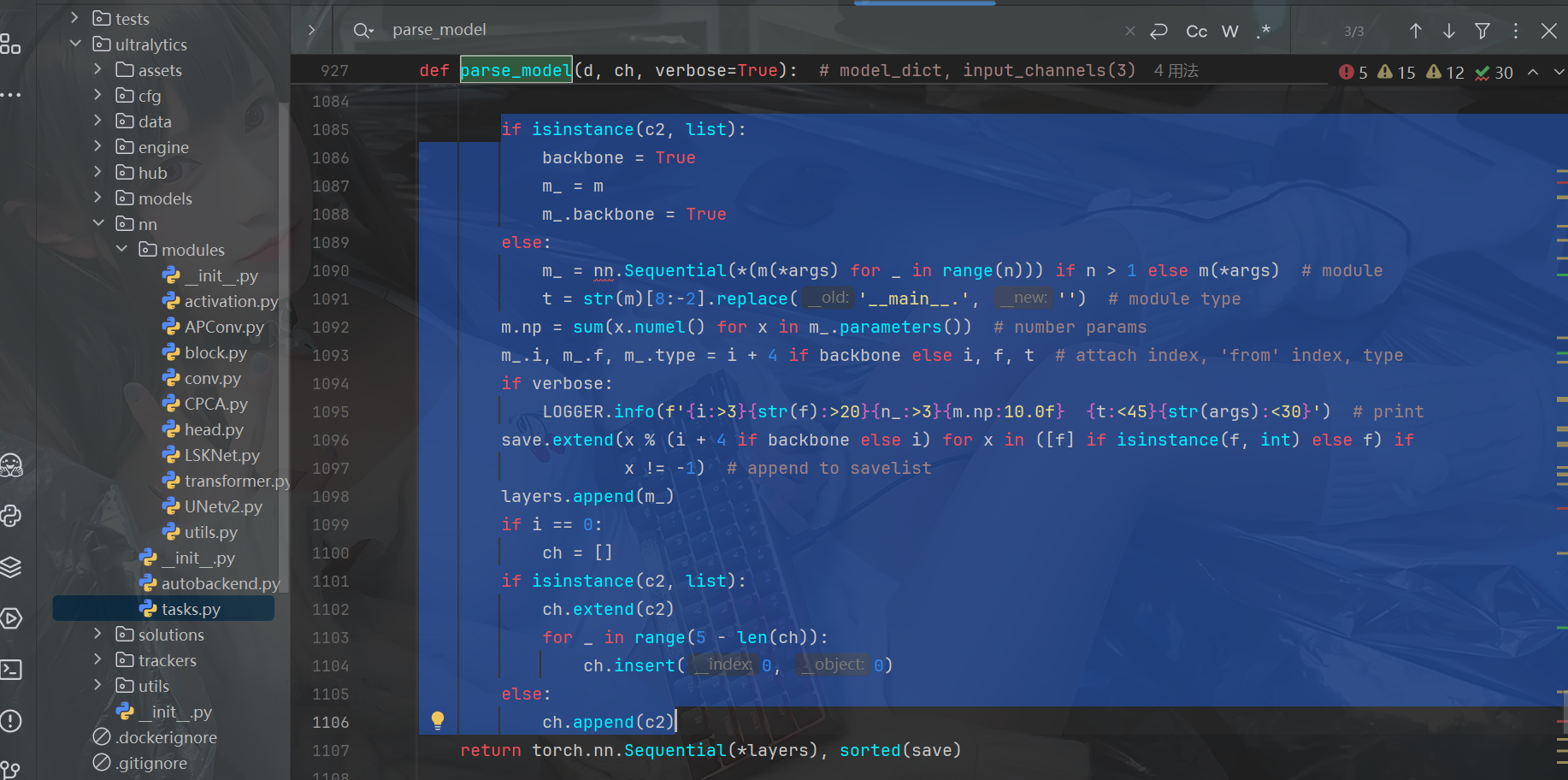
修改后代码:
if isinstance(c2, list):
backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if backbone else i, f, t # attach index, 'from' index, type
if verbose:
LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
save.extend(x % (i + 4 if backbone else i) for x in ([f] if isinstance(f, int) else f) if
x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)4.2 找到函数(注意是整的函数,return x结束)并修改(博主已经修改过啦)
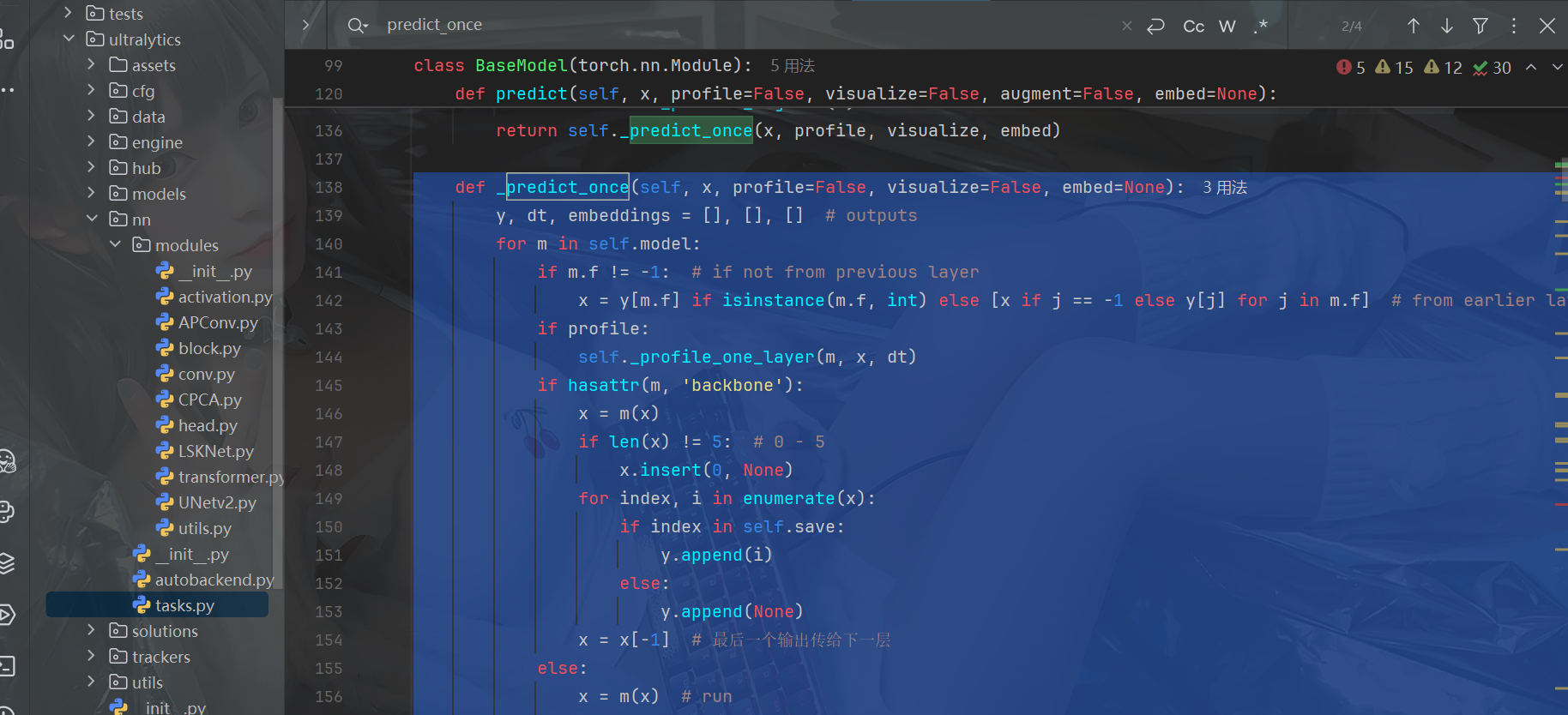
修改后代:
def _predict_once(self, x, profile=False, visualize=False, embed=None):
y, dt, embeddings = [], [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
if len(x) != 5: # 0 - 5
x.insert(0, None)
for index, i in enumerate(x):
if index in self.save:
y.append(i)
else:
y.append(None)
x = x[-1] # 最后一个输出传给下一层
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
return x4.3 保存代码后,当然要修改.yaml 文件啦
# YOLOv12 🚀, AGPL-3.0 license
# YOLOv12 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov12n.yaml' will call yolov12.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 465 layers, 2,603,056 parameters, 2,603,040 gradients, 6.7 GFLOPs
s: [0.50, 0.50, 1024] # summary: 465 layers, 9,285,632 parameters, 9,285,616 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 501 layers, 20,201,216 parameters, 20,201,200 gradients, 68.1 GFLOPs
l: [1.00, 1.00, 512] # summary: 831 layers, 26,454,880 parameters, 26,454,864 gradients, 89.7 GFLOPs
x: [1.00, 1.50, 512] # summary: 831 layers, 59,216,928 parameters, 59,216,912 gradients, 200.3 GFLOPs
# YOLO12n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, pvt_v2_b1, []] # 4
# YOLO12n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C2f, [512, False, -1]] # 7
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C2f, [256, False, -1]] # 10
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 7], 1, Concat, [1]] # cat head P4
- [-1, 2, C2f, [512, False, -1]] # 13
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 4], 1, Concat, [1]] # cat head P5
- [-1, 2, C2f, [1024, True]] # 16 (P5/32-large)
- [[10, 13, 16], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.3.1 啰嗦一句:博主这里加入了P2检测头,加入小目标检测头能够提升小目标检测精度(博主是检测红外小目标滴)。
如果加入检测头,其他代码都不动,只需要修改.yaml 文件(修改自己的检测种类nc: 5)。
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLOv8 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolov8
# Task docs: https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 5 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 129 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPS
s: [0.33, 0.50, 1024] # YOLOv8s summary: 129 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPS
m: [0.67, 0.75, 768] # YOLOv8m summary: 169 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPS
l: [1.00, 1.00, 512] # YOLOv8l summary: 209 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPS
x: [1.00, 1.25, 512] # YOLOv8x summary: 209 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPS
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, pvt_v2_b1, []] # 4
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 3], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C2f, [512]] # 7
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 2], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C2f, [256]] # 10
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 1], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C2f, [256]] # 13
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P4
- [-1, 2, C2f, [512]] # 16
- [ -1, 1, Conv, [ 256, 3, 2 ] ]
- [ [ -1, 7 ], 1, Concat, [ 1 ] ] # cat head P4
- [ -1, 2, C2f, [ 512 ] ] # 19
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 4], 1, Concat, [1]] # cat head P5
- [-1, 2, C2f, [1024]] # 22
- [[13, 16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
4.4 直接训练自己的数据集(运行结果如图)
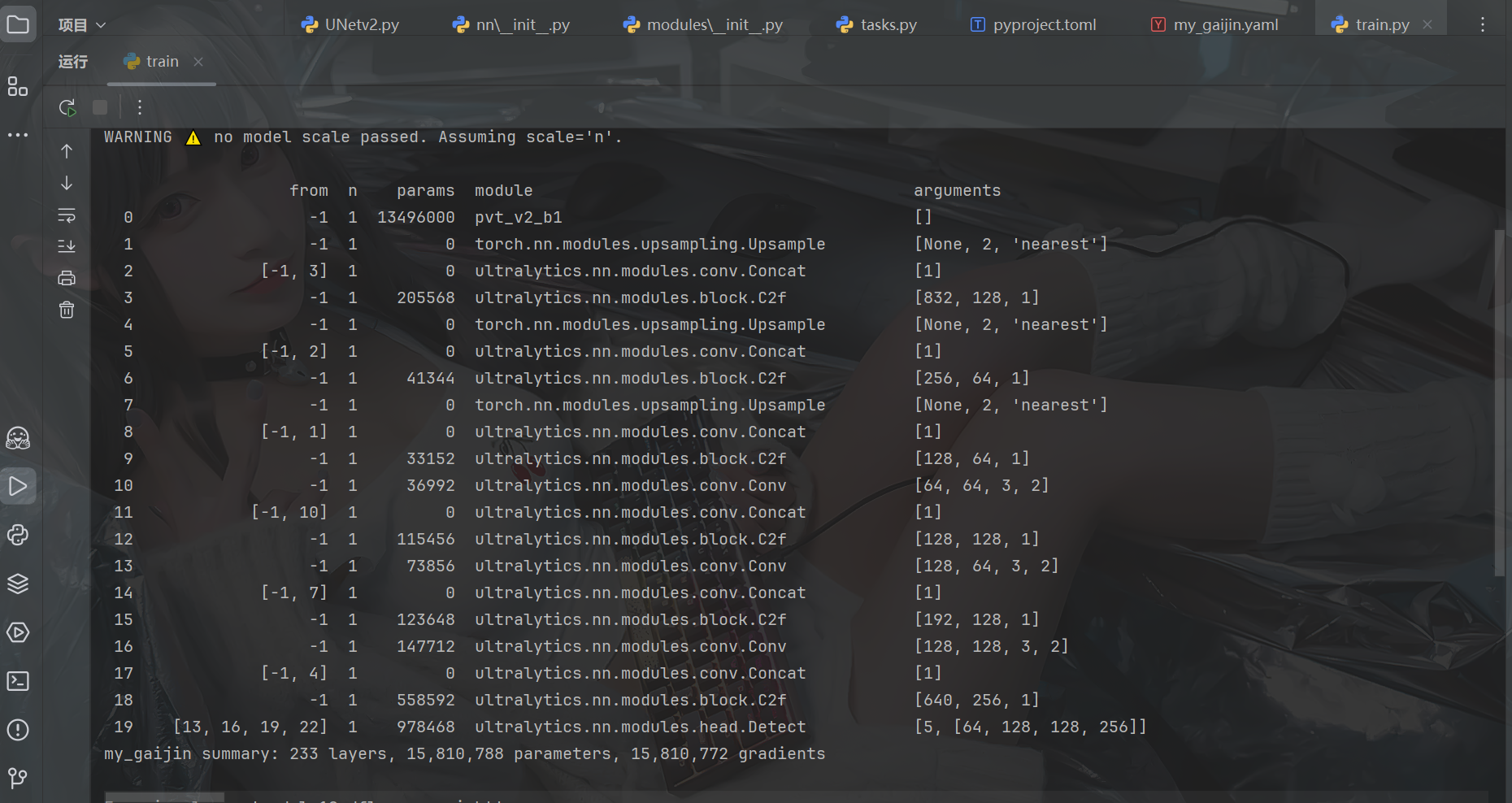
YOLOv8+Unetv2在保持YOLOv8速度优势的同时,显著提升了小目标的检测精度。与YOLOv12相比,改进后的模型在密集场景中表现更稳定。
【博主修将损失函数换为WIOU,精度提升了3%,后面再加入注意力机制再去尝试。】

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)